In der Welt der Massive Language Fashions (LLMs) ist Geschwindigkeit das einzige Merkmal, das zählt, sobald die Genauigkeit gelöst ist. Für einen Menschen ist es in Ordnung, eine Sekunde auf ein Suchergebnis zu warten. Wenn ein KI-Agent 10 aufeinanderfolgende Suchvorgänge durchführt, um eine komplexe Aufgabe zu lösen, führt eine Verzögerung von 1 Sekunde professional Suche zu einer Verzögerung von 10 Sekunden. Diese Latenz beeinträchtigt das Benutzererlebnis.
Exadas Suchmaschinen-Startup, das früher als Metaphor bekannt conflict, wurde gerade veröffentlicht Exa Instantaneous. Es handelt sich um ein Suchmodell, das darauf ausgelegt ist, KI-Agenten in den USA die weltweiten Webdaten bereitzustellen 200ms. Für Softwareentwickler und Datenwissenschaftler, die Retrieval-Augmented Technology (RAG)-Pipelines erstellen, wird dadurch der größte Engpass in Agenten-Workflows beseitigt.
Warum Latenz der Feind von RAG ist
Wenn Sie eine RAG-Anwendung erstellen, folgt Ihr System einer Schleife: Der Benutzer stellt eine Frage, Ihr System durchsucht das Internet nach Kontext und der LLM verarbeitet diesen Kontext. Wenn der Suchschritt dauert 700 ms Zu 1000 mswird die Gesamtzeit bis zum ersten Token langsam.
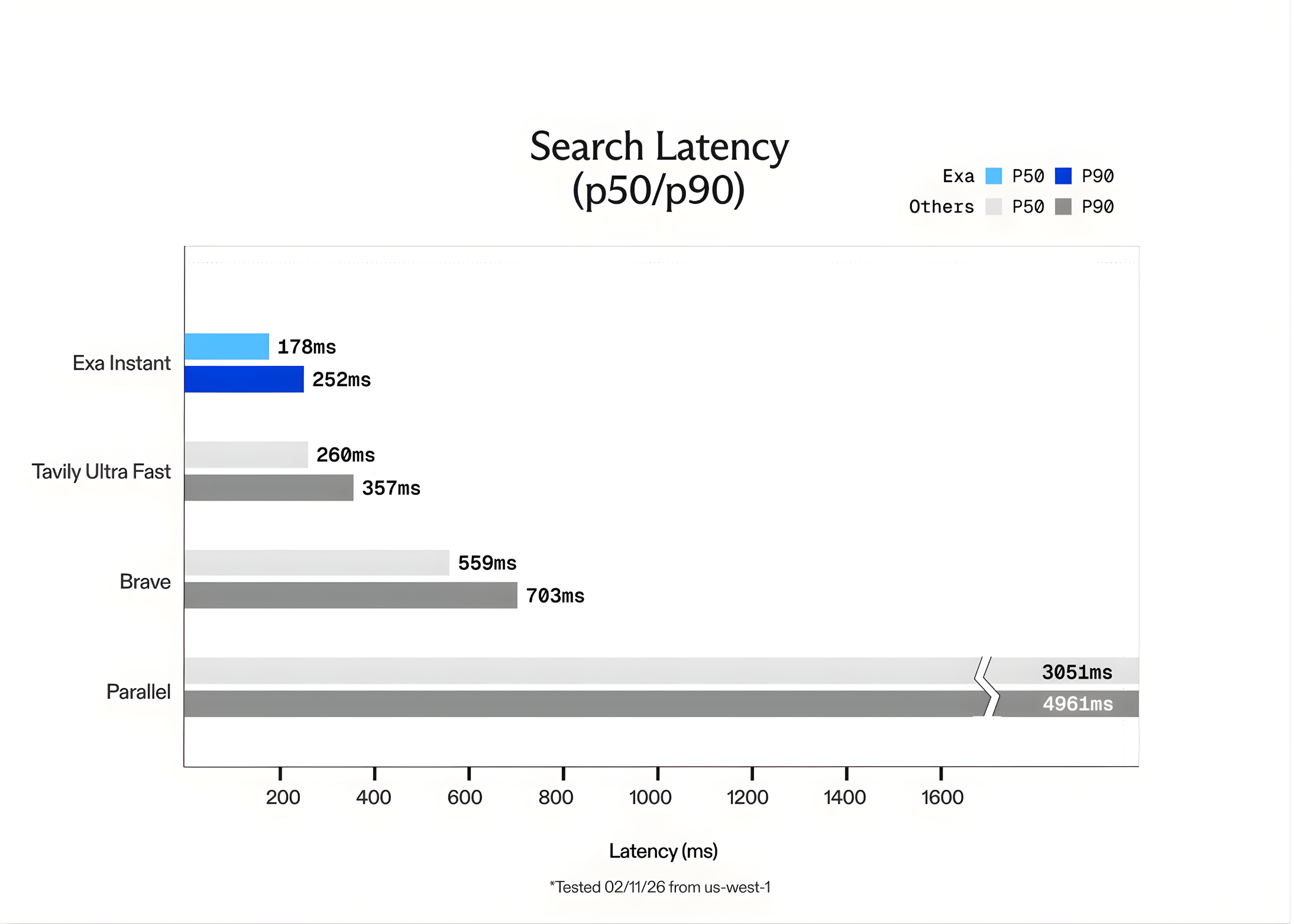
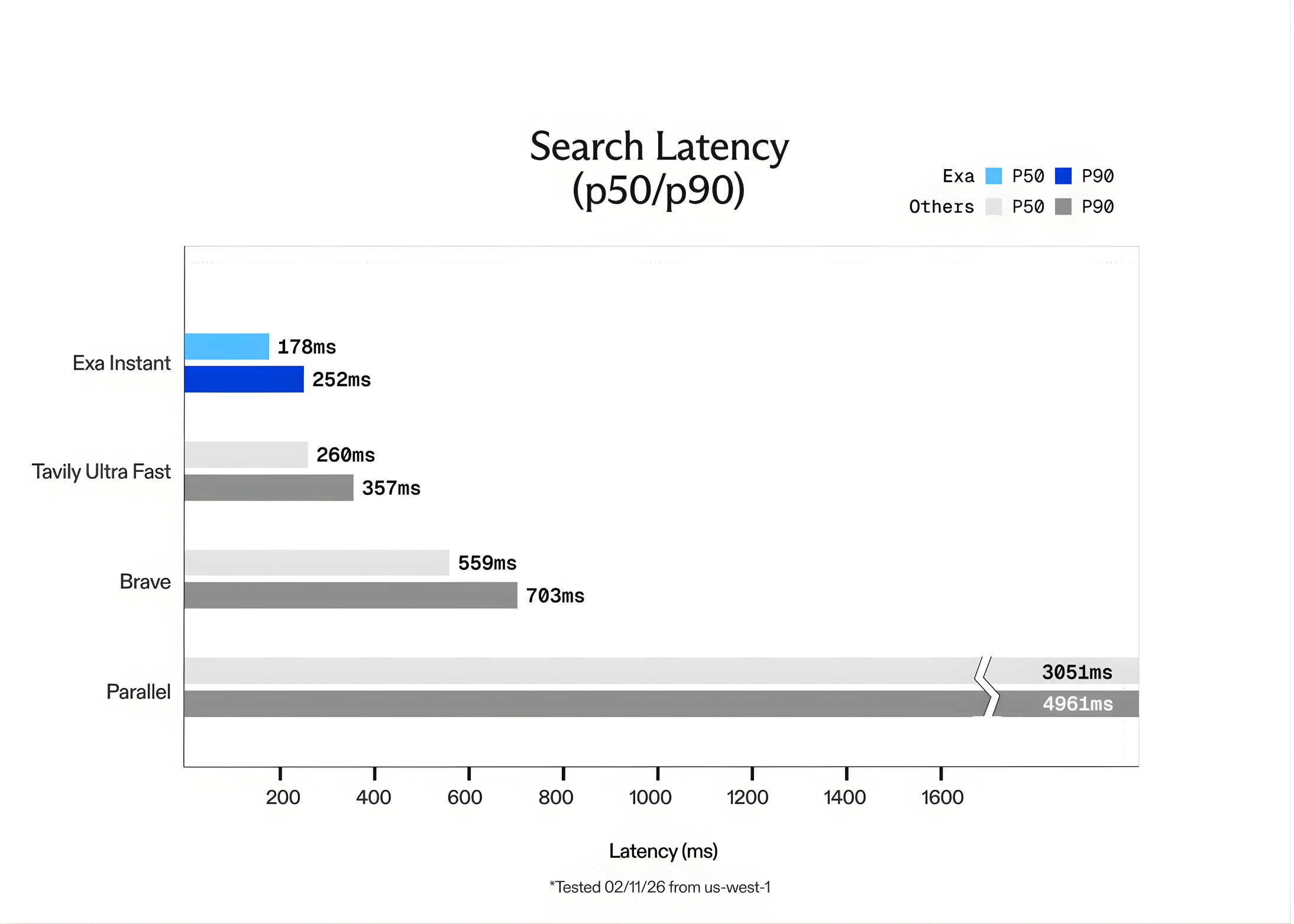
Exa Instantaneous liefert Ergebnisse mit einer Latenz dazwischen 100 ms Und 200ms. In Exams durchgeführt von der us-west-1 In der Area (Nordkalifornien) betrug die Netzwerklatenz ungefähr 50ms. Diese Geschwindigkeit ermöglicht es Agenten, mehrere Suchvorgänge in einem einzigen „Gedanken“-Prozess durchzuführen, ohne dass der Benutzer eine Verzögerung spürt.
Kein „Einpacken“ von Google mehr
Die meisten heute verfügbaren Such-APIs sind „Wrapper“. Sie senden eine Anfrage an eine herkömmliche Suchmaschine wie Google oder Bing, scannen die Ergebnisse und senden sie an Sie zurück. Dadurch entstehen zusätzliche Overhead-Ebenen.
Exa Instantaneous ist anders. Es basiert auf einem proprietären, durchgängigen neuronalen Such- und Abrufstapel. Anstelle passender Schlüsselwörter verwendet Exa Einbettungen Und Transformatoren um die Bedeutung einer Abfrage zu verstehen. Dieser neuronale Ansatz stellt sicher, dass die Ergebnisse für die Absicht der KI related sind und nicht nur für die spezifischen verwendeten Wörter. Da Exa den gesamten Stack vom Crawler bis zur Inferenz-Engine besitzt, kann es die Geschwindigkeit auf eine Weise optimieren, die mit „Wrapper“-APIs nicht möglich ist.
Benchmarking der Geschwindigkeit
Das Exa-Crew hat Exa Instantaneous mit anderen beliebten Optionen wie verglichen Tavily Ultraschnell Und Mutig. Um sicherzustellen, dass die Exams truthful waren und „zwischengespeicherte“ Ergebnisse vermieden wurden, verwendete das Crew das SealQA Datensatz abfragen. Sie fügten auch zufällige Wörter hinzu, die von generiert wurden GPT-5 zu jeder Abfrage, um die Suchmaschine zu zwingen, jedes Mal eine neue Suche durchzuführen.
Die Ergebnisse zeigten, dass Exa Instantaneous dem gewachsen ist 15x schneller als die Konkurrenz. Während Exa andere Modelle wie anbietet Exa Quick Und Exa Auto Für eine qualitativ hochwertigere Argumentation ist Exa Instantaneous die klare Wahl für Echtzeitanwendungen, bei denen jede Millisekunde zählt.
Preise und Entwicklerintegration
Der Übergang zu Exa Instantaneous ist einfach. Auf die API kann über zugegriffen werden Dashboard.exa.ai Plattform.
- Kosten: Der Preis für Exa Instantaneous liegt bei 5 $ professional 1.000 Anfragen.
- Kapazität: Es durchsucht den gleichen umfangreichen Index des Webs wie die leistungsstärkeren Modelle von Exa.
- Genauigkeit: Obwohl es auf Geschwindigkeit ausgelegt ist, behält es eine hohe Relevanz bei. Für die Suche nach spezialisierten Entitäten bietet Exa’s Webseiten Das Produkt bleibt der Goldstandard und erweist sich als solcher 20x bei komplexen Abfragen korrekter als Google.
Die API gibt saubere Inhalte zurück, die für LLMs bereit sind, sodass Entwickler keinen benutzerdefinierten Scraping- oder HTML-Reinigungscode schreiben müssen.
Wichtige Erkenntnisse
- Latenz von unter 200 ms für Echtzeitagenten: Exa Instantaneous ist für „agentische“ Arbeitsabläufe optimiert, bei denen Geschwindigkeit ein Engpass ist. Indem wir Ergebnisse in weniger als einem Jahr liefern 200ms (und Netzwerklatenz so niedrig wie 50ms) ermöglicht es KI-Agenten, mehrstufige Überlegungen und parallele Suchvorgänge durchzuführen, ohne die Verzögerung, die mit herkömmlichen Suchmaschinen einhergeht.
- Proprietärer Neural Stack vs. Wrapper„: Im Gegensatz zu vielen Such-APIs, die einfach Google oder Bing „umschließen“ (und mehr als 700 ms Mehraufwand verursachen), basiert Exa Instantaneous auf einer proprietären, durchgängigen neuronalen Suchmaschine. Es verwendet eine benutzerdefinierte transformatorbasierte Architektur zum Indizieren und Abrufen von Webdaten und bietet bis zu 15x schnellere Leistung als bestehende Alternativen wie Tavily oder Courageous.
- Kosteneffiziente Skalierung: Das Modell soll die Suche zu einem „primitiven“ und nicht zu einem teuren Luxus machen. Der Preis liegt bei 5 $ professional 1.000 Anfragen, sodass Entwickler in jedem Schritt des Denkprozesses eines Agenten Echtzeit-Websuchen integrieren können, ohne das Funds zu sprengen.
- Semantische Absicht über Schlüsselwörter: Exa Instantaneous-Hebel Einbettungen um der „Bedeutung“ einer Abfrage Vorrang vor exakten Wortübereinstimmungen zu geben. Dies ist besonders effektiv für RAG-Anwendungen (Retrieval-Augmented Technology), bei denen es wertvoller ist, „linkwürdigen“ Inhalt zu finden, der in den Kontext eines LLM passt, als einfache Schlüsselworttreffer.
- Optimiert für den LLM-Verbrauch: Die API bietet mehr als nur URLs; Es bietet sauberes, analysiertes HTML, Markdown und Token-effiziente Highlights. Dies reduziert den Bedarf an benutzerdefinierten Scraping-Skripten und minimiert die Anzahl der Token, die das LLM verarbeiten muss, was die gesamte Pipeline weiter beschleunigt.
Schauen Sie sich das an Technische Particulars. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
