
Einführung
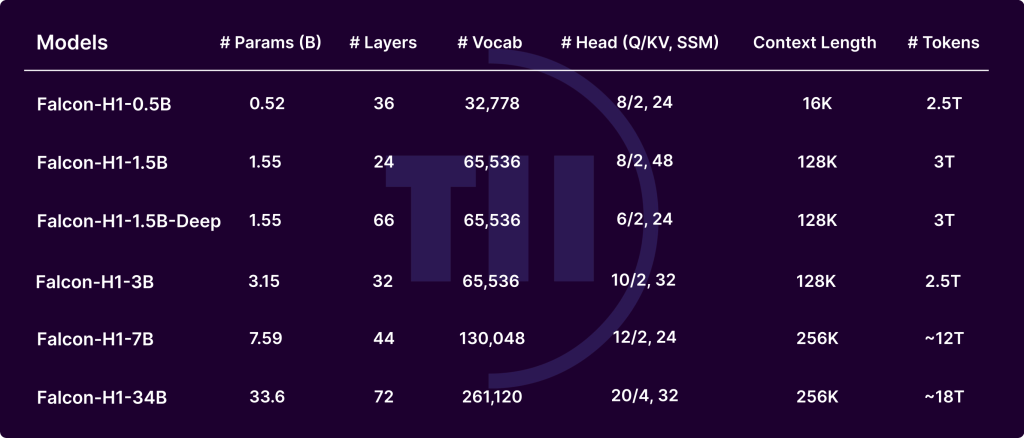
Die von The Know-how Innovation Institute (TII) entwickelte Falcon-H1-Serie markiert einen erheblichen Fortschritt in der Entwicklung von Großsprachenmodellen (LLMs). Durch die Integration transformatorischer Aufmerksamkeit in Mamba-basierte Zustandsraummodelle (SSMs) in einer hybriden parallelen Konfiguration erzielt Falcon-H1 außergewöhnliche Leistung, Gedächtniseffizienz und Skalierbarkeit. Falcon-H1-Modelle werden in mehreren Größen (0,5B bis 34B Parametern) und -versionen (Foundation, überwiesen und quantisiert) freigegeben.
Wichtige architektonische Innovationen
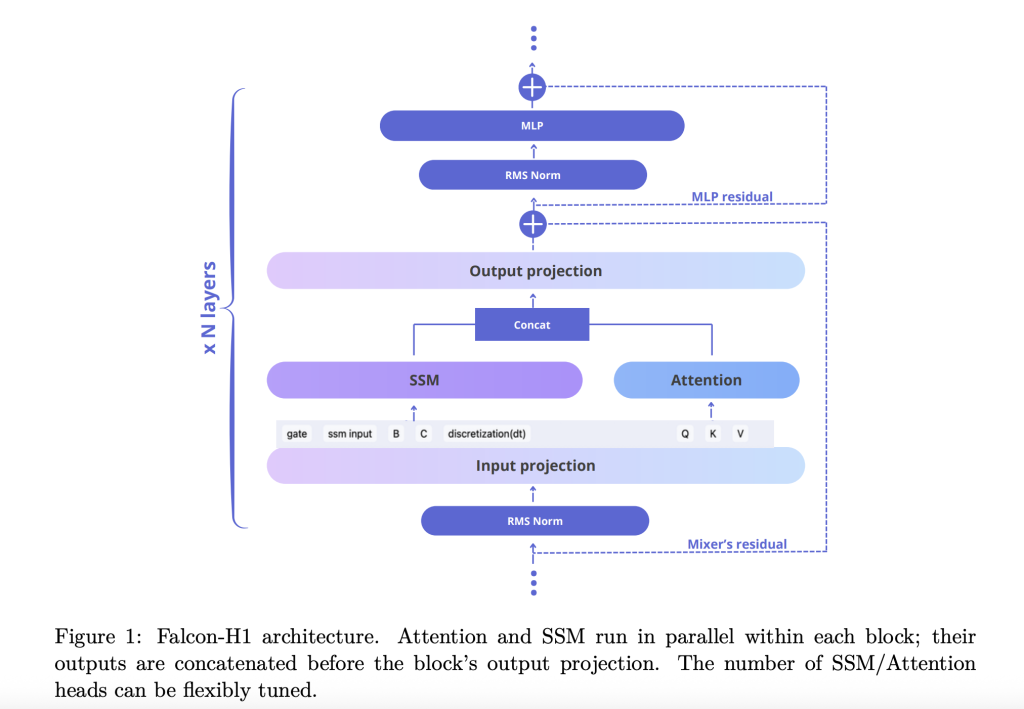
Der Technischer Bericht erklärt, wie Falcon-H1 einen Roman annimmt Parallele Hybridarchitektur Wo sowohl die Aufmerksamkeit als auch die SSM -Module gleichzeitig funktionieren und ihre Ausgaben vor der Projektion verkettet werden. Dieses Design weicht von der herkömmlichen sequentiellen Integration ab und bietet die Flexibilität, die Anzahl der Aufmerksamkeit und SSM -Kanäle unabhängig abzustimmen. Die Standardkonfiguration verwendet ein Verhältnis von 2: 1: 5 für SSM-, Aufmerksamkeits- und MLP -Kanäle, wobei sowohl die Effizienz als auch die Lerndynamik optimiert werden.
Um das Modell weiter zu verfeinern, untersucht Falcon-H1::
- Kanalzuweisung: Ablationen zeigen, dass die zunehmende Aufmerksamkeitskanäle die Leistung verschlechtern, während das Ausgleich von SSM und MLP robuste Gewinne erzielt.
- Blockkonfiguration: Die SA_M-Konfiguration (halbparallel mit Aufmerksamkeit und SSM Collectively-Läufe, gefolgt von MLP) führt am besten im Trainingsverlust und zur Recheneffizienz durch.
- Seilbasisfrequenz: Eine ungewöhnlich hohe Basisfrequenz von 10^11 in Rotationspositionseinbettungen (Seil) erwies sich als optimum und verbesserte die Generalisierung während des lang Kontext-Trainings.
- Kompromiss zwischen Breite: Experimente zeigen, dass tiefere Modelle unter festen Parameterbudgets breiter übertreffen. Falcon-H1-1.5b-tiefe (66 Ebenen) übertrifft viele 3B- und 7B-Modelle.
Tokenizer -Strategie
Falcon-H1 verwendet eine maßgeschneiderte Bytepaar-Kodierung (BPE) Tokenizer Suite mit Vokabulargrößen von 32K bis 261K. Zu den wichtigsten Designentscheidungen gehören:
- Ziffern- und Zeichensetzungspaltung: Empirisch verbessert die Leistung in Code und mehrsprachigen Einstellungen.
- Latex -Token -Injektion: Verbessert die Modellgenauigkeit bei mathematischen Benchmarks.
- Mehrsprachige Unterstützung: Deckt 18 Sprachen und Skalen auf 100+ ab, wobei optimierte Fruchtbarkeit und Bytes/Token -Metriken verwendet werden.
Vorab -Korpus- und Datenstrategie
Falcon-H1-Modelle werden auf bis zu 18-t-Token aus einem sorgfältig kuratierten 20T-Token-Korpus ausgebildet, der umfasst:
- Hochwertige Webdaten (gefilterte Fineweb)
- Mehrsprachige Datensätze: Widespread Crawl, Wikipedia, Arxiv, OpenSubtitel und kuratierte Ressourcen für 17 Sprachen
- Codekorpus: 67 Sprachen, verarbeitet über Minhash -Deduplizierung, Codebert -Qualitätsfilter und PII -Scrubbing
- Mathematikdatensätze: Math, GSM8K und hauseigene latexverstärkte Krabbel
- Synthetische Daten: Umgeschrieben von rohen Korpora mit verschiedenen LLMs sowie der QS im Lehrbuchstil aus 30.000 Wikipedia-basierten Themen
- Langkontextsequenzen: Verbessert durch Einfüll-, Neuordnung und synthetische Argumentationsaufgaben bis zu 256.000 Token
Trainingsinfrastruktur und Methodik
Das Coaching verwendete die maßgeschneiderte maximale Aktualisierungsparametrisierung (µP), wobei die sanfte Skalierung über die Modellgrößen hinweg unterstützt wird. Die Modelle verwenden fortgeschrittene Parallelitätsstrategien:
- Mixer Parallelism (MP) Und Kontextparallelität (CP): Verbessern Sie den Durchsatz für die lang Kontextverarbeitung
- Quantisierung: Veröffentlicht in Bfloat16- und 4-Bit-Varianten, um die Kantenbereitstellungen zu erleichtern
Bewertung und Leistung
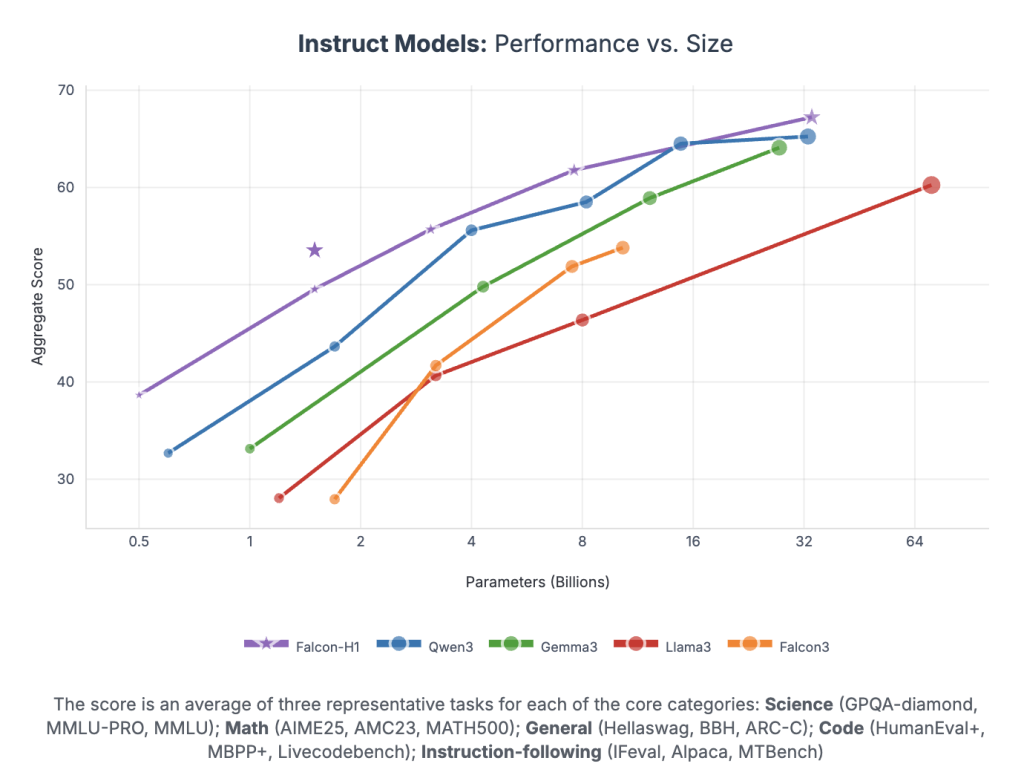
Falcon-H1 erzielt eine beispiellose Leistung professional Parameter:
- Falcon-H1-34b-Instruktur überschreitet oder passt 70B-Modelle wie Qwen2.5-72B und LAMA3.3-70B über Argumentation, Mathematik, Anweisungen und mehrsprachige Aufgaben über.
- Falcon-H1-1.5b-Deep Rivalen 7b – 10b Modelle
- Falcon-H1-0.5b liefert die 7B-Leistung der 2024-Ära-Leistung
Benchmarks überspannen MMLU-, GSM8K-, Humaneal- und Lengthy Context-Aufgaben. Die Modelle zeigen eine starke Ausrichtung über SFT und direkte Präferenzoptimierung (DPO).
Abschluss
Falcon-H1 legt einen neuen Customary für Open-Gewicht-LLMs fest, indem parallele Hybridarchitekturen, versatile Tokenisierung, effiziente Trainingsdynamik und robuste mehrsprachige Fähigkeiten integriert werden. Die strategische Kombination von SSM und Aufmerksamkeit ermöglicht eine unübertroffene Leistung innerhalb der praktischen Rechen- und Gedächtnisbudgets, was es sowohl für die Forschung als auch für den Einsatz in verschiedenen Umgebungen superb macht.
Schauen Sie sich das an Papier Und Fashions auf dem Umarmung des Gesichts. Fühlen Sie sich frei zu Weitere Anwendungen finden Sie in unserer Tutorials auf AI Agent und Agentic AI. Fühlen Sie sich auch frei, uns zu folgen Twitter Und vergessen Sie nicht, sich unserer anzuschließen 100k+ ml Subreddit und abonnieren Unser E-newsletter.

Michal Sutter ist ein Datenwissenschaftler bei einem Grasp of Science in Information Science von der College of Padova. Mit einer soliden Grundlage für statistische Analyse, maschinelles Lernen und Datentechnik setzt Michal aus, um komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.
