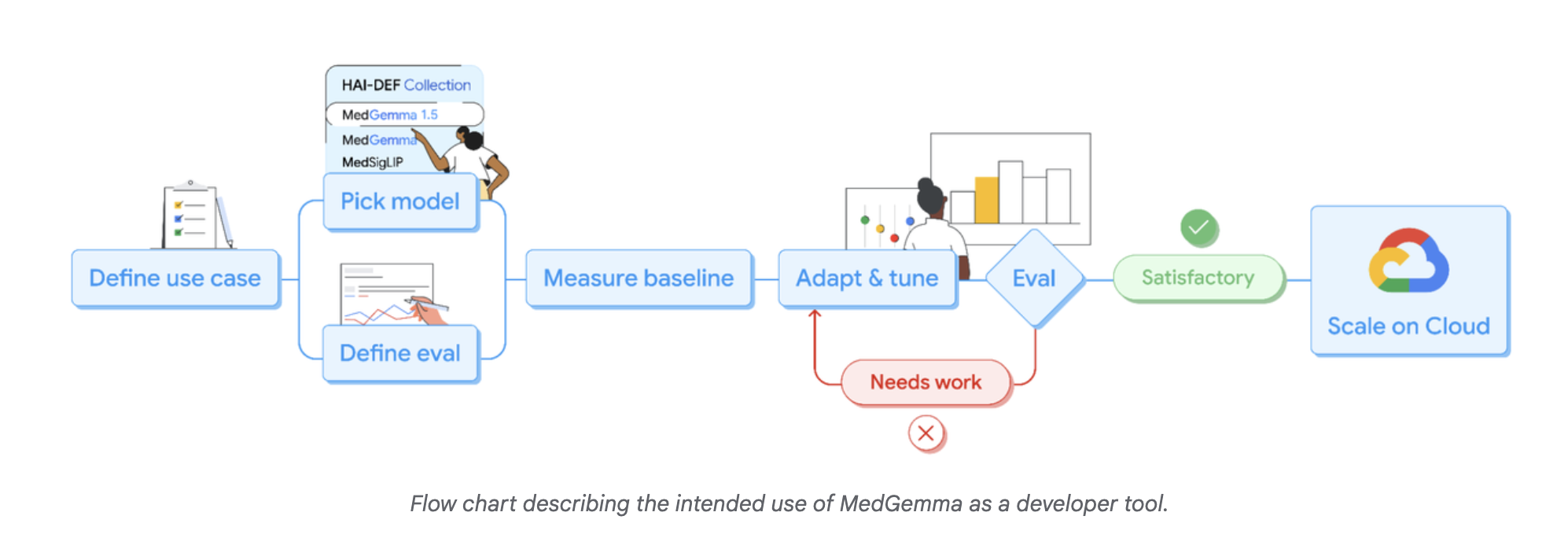
Google Analysis hat sein Angebot erweitert Well being AI Developer Foundations-Programm (HAI-DEF) mit der Veröffentlichung von MedGemma-1.5. Das Modell wird als offene Ausgangspunkte für Entwickler freigegeben, die medizinische Bildgebungs-, Textual content- und Sprachsysteme erstellen und diese dann an lokale Arbeitsabläufe und Vorschriften anpassen möchten.
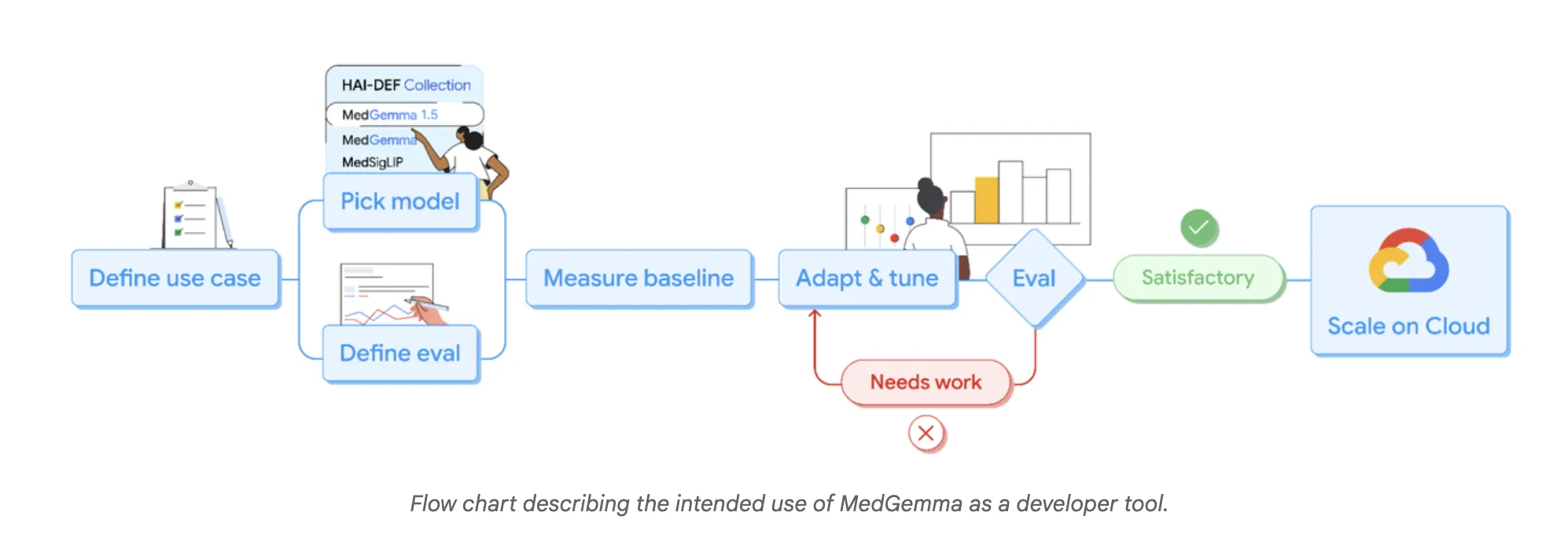
MedGemma 1.5, kleines multimodales Modell für echte klinische Daten
MedGemma ist eine Familie medizinischer generativer Modelle, die auf Gemma basieren. Die neue Model MedGemma-1.5-4B richtet sich an Entwickler, die ein kompaktes Modell benötigen, das dennoch echte klinische Daten verarbeiten kann. Das Vorgängermodell MedGemma-1-27B bleibt für anspruchsvollere, textintensive Anwendungsfälle verfügbar.
MedGemma-1.5-4B ist multimodal. Es akzeptiert Textual content, zweidimensionale Bilder, hochdimensionale Volumen und Pathologiebilder ganzer Objektträger. Das Modell ist Teil des Well being AI Developer Foundations-Programms und dient daher als Grundlage für die Feinabstimmung und nicht als fertiges Diagnosegerät.
Unterstützung für hochdimensionale CT, MRT und Pathologie
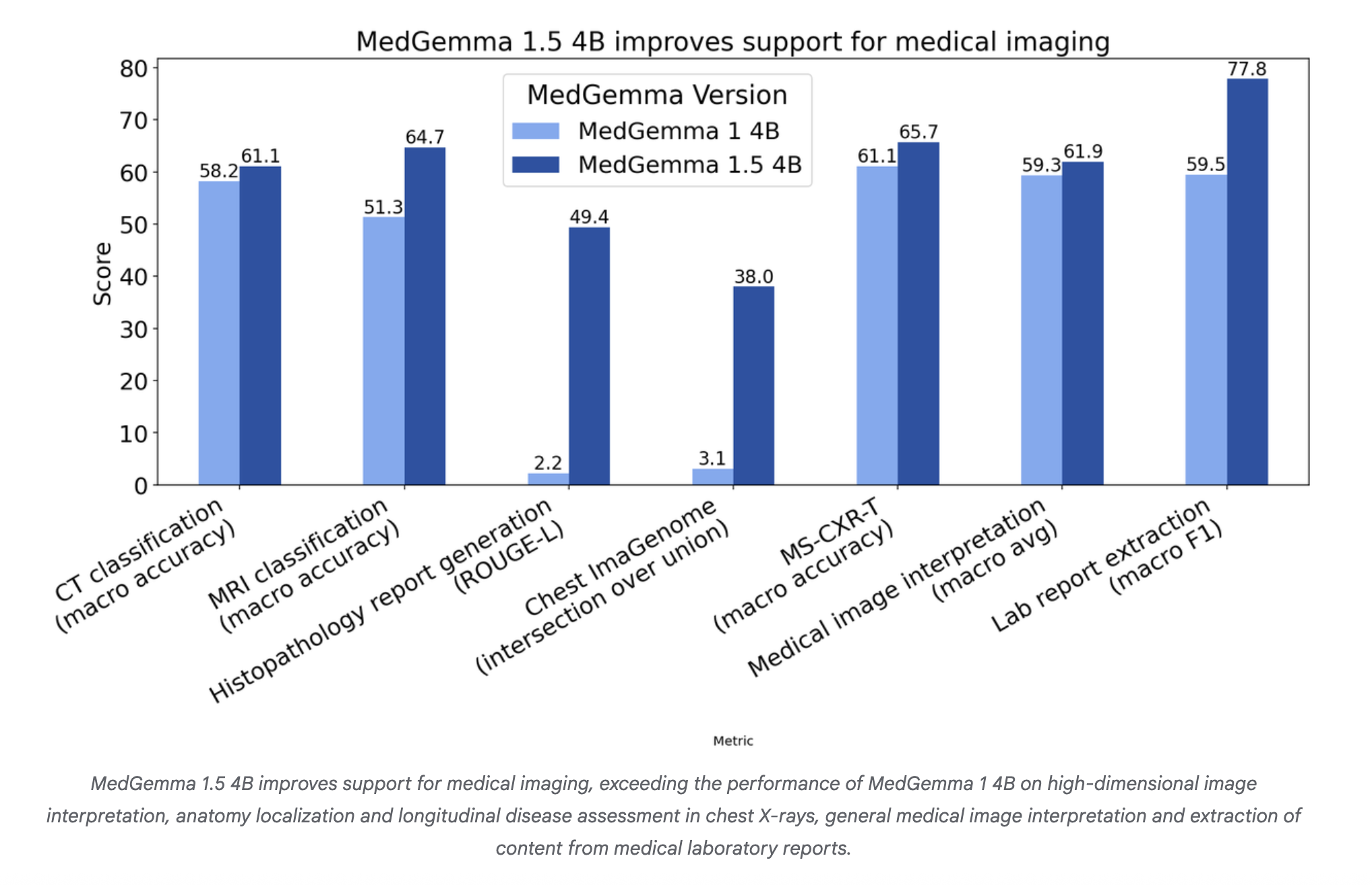
Eine wesentliche Änderung in MedGemma-1.5 ist die Unterstützung hochdimensionaler Bildgebung. Das Modell kann dreidimensionale CT- und MRT-Volumina als Schichtsätze zusammen mit einer Eingabeaufforderung in natürlicher Sprache verarbeiten. Es kann auch große histopathologische Objektträger verarbeiten, indem es die aus dem Objektträger extrahierten Patches bearbeitet.
Bei internen Benchmarks verbessert MedGemma-1.5 krankheitsbezogene CT-Befunde von 58 % auf 61 % Genauigkeit und MRT-Krankheitsbefunde von 51 % auf 65 % Genauigkeit, wenn es über die Ergebnisse gemittelt wird. Für die Histopathologie steigt der ROUGE-L-Rating bei einzelnen Objektträgerfällen von 0,02 auf 0,49. Dies entspricht dem ROUGE L-Rating von 0,498 des aufgabenspezifischen PolyPath-Modells.

Benchmarks für Bildgebung und Berichtsextraktion
MedGemma-1.5 verbessert außerdem mehrere Benchmarks, die den Produktionsabläufen näher kommen.
Beim Chest ImaGenome-Benchmark für die anatomische Lokalisierung in Röntgenaufnahmen des Brustkorbs verbessert es die Schnittmenge gegenüber der Vereinigung von 3 % auf 38 %. Beim MS-CXR-T-Benchmark für den Längsschnitt-Röntgenvergleich des Brustkorbs steigt die Makrogenauigkeit von 61 % auf 66 %.
Bei internen Einzelbild-Benchmarks, die Thoraxradiographie, Dermatologie, Histopathologie und Ophthalmologie abdecken, liegt die durchschnittliche Genauigkeit zwischen 59 % und 62 %. Dies sind einfache Einzelbildaufgaben, die als Plausibilitätsprüfungen während der Domänenanpassung nützlich sind.
MedGemma-1.5 zielt auch auf die Dokumentenextraktion ab. Bei medizinischen Laborberichten verbessert das Modell das Makro F1 von 60 % auf 78 %, wenn es Labortyp, -wert und -einheiten extrahiert. Für Entwickler bedeutet dies weniger benutzerdefiniertes regelbasiertes Parsen für halbstrukturierte PDF- oder Textberichte.
Auf Google Cloud bereitgestellte Anwendungen können jetzt direkt mit DICOM arbeiten, dem in der Radiologie verwendeten Standarddateiformat. Dadurch entfällt für viele Krankenhaussysteme die Notwendigkeit eines benutzerdefinierten Präprozessors.
Medizinische Textbegründung mit MedQA und EHRQA
MedGemma-1.5 ist nicht nur ein Bildgebungsmodell. Es verbessert auch die Grundleistung bei medizinischen Textaufgaben.
Bei MedQA, einem A number of-Alternative-Benchmark für die Beantwortung medizinischer Fragen, verbessert das 4B-Modell die Genauigkeit im Vergleich zum vorherigen MedGemma-1 von 64 % auf 69 %. Bei EHRQA, einem textbasierten Benchmark zur Beantwortung elektronischer Patientenakten, steigt die Genauigkeit von 68 % auf 90 %.
Diese Zahlen sind von Bedeutung, wenn Sie MedGemma-1.5 als Rückgrat für Instruments wie die Diagrammzusammenfassung, die Orientierung an Leitlinien oder die erweiterte Generierung von Daten über klinische Notizen hinweg verwenden möchten. Die Größe 4B hält die Feinabstimmung und die Servierkosten auf einem praktischen Niveau.
MedASR, ein domänenabgestimmtes Spracherkennungsmodell
Klinische Arbeitsabläufe enthalten eine große Menge diktierter Sprache. MedASR ist das neue medizinische automatisierte Spracherkennungsmodell, das zusammen mit MedGemma-1.5 veröffentlicht wurde.
MedASR verwendet eine Conformer-basierte Architektur, die vorab trainiert und für klinische Audiodaten fein abgestimmt ist. Es zielt auf Aufgaben wie das Diktieren von Röntgenaufnahmen des Brustkorbs, radiologische Berichte und allgemeine medizinische Notizen ab. Das Modell ist über denselben Well being AI Developer Foundations-Kanal auf Vertex AI und auf Hugging Face verfügbar.
In Auswertungen mit Whisper-large-v3, einem allgemeinen ASR-Modell, reduziert MedASR die Wortfehlerrate beim Röntgendiktat des Brustkorbs von 12,5 % auf 5,2 %. Das entspricht 58 % weniger Transkriptionsfehlern. Bei einem breiteren internen medizinischen Diktat-Benchmark erreicht MedASR eine Wortfehlerrate von 5,2 %, während Whisper-large-v3 28,2 % hat, was 82 % weniger Fehlern entspricht.
Wichtige Erkenntnisse
- MedGemma-1.5-4B ist ein kompaktes multimodales medizinisches Modell, das Textual content, 2D-Bilder, 3D-CT- und MRT-Volumina sowie die gesamte Objektträgerpathologie verarbeitet und im Rahmen des Well being AI Developer Foundations-Programms zur Anpassung an lokale Anwendungsfälle veröffentlicht wurde.
- Bei Bildgebungs-Benchmarks verbessert MedGemma-1.5 die CT-Erkrankungsbefunde von 58 % auf 61 %, die MRT-Erkrankungsbefunde von 51 % auf 65 % und die Histopathologie ROUGE-L von 0,02 auf 0,49, was der Leistung des PolyPath-Modells entspricht.
- Für nachgelagerte Aufgaben im klinischen Stil erhöht MedGemma-1.5 die Brust-ImaGenome-Schnittmenge über der Vereinigung von 3 % auf 38 %, die MS-CXR-T-Makrogenauigkeit von 61 % auf 66 % und das Laborbericht-Extraktionsmakro F1 von 60 % auf 78 %, während die Modellgröße bei 4B-Parametern bleibt.
- MedGemma-1.5 stärkt außerdem das Textdenken und erhöht die MedQA-Genauigkeit von 64 % auf 69 % und die EHRQA-Genauigkeit von 68 % auf 90 %, wodurch es sich als Rückgrat für Diagrammzusammenfassungs- und EHR-Fragen-Antwort-Systeme eignet.
- MedASR, ein Conformer-basiertes medizinisches ASR-Modell im selben Programm, senkt die Wortfehlerrate bei Röntgendiktaten des Brustkorbs von 12,5 % auf 5,2 % und bei einem breiten medizinischen Diktat-Benchmark von 28,2 % auf 5,2 % im Vergleich zu Whisper-large-v3 und bietet ein domänenabgestimmtes Sprach-Frontend für MedGemma-zentrierte Arbeitsabläufe.
Schauen Sie sich das an Modellgewichte Und Technische Particulars. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Der Beitrag Google AI veröffentlicht MedGemma-1.5: das neueste Replace seiner offenen medizinischen KI-Modelle für Entwickler erschien zuerst auf MarkTechPost.