
Transformer nutzen Aufmerksamkeit und Combination-of-Specialists, um Berechnungen zu skalieren, es fehlt ihnen jedoch immer noch eine native Möglichkeit zur Wissenssuche. Sie berechnen dieselben lokalen Muster immer wieder neu, was Tiefe und FLOPs verschwendet. Das neue Engram-Modul von DeepSeek zielt genau auf diese Lücke, indem es eine bedingte Speicherachse hinzufügt, die mit MoE zusammenarbeitet, anstatt es zu ersetzen.
Auf hohem Niveau modernisiert Engram klassische N-Gramm-Einbettungen und verwandelt sie in einen skalierbaren O(1)-Suchspeicher, der direkt an das Transformer-Spine angeschlossen wird. Das Ergebnis ist ein parametrisches Gedächtnis, das statische Muster wie gängige Phrasen und Entitäten speichert, während sich das Rückgrat auf härtere Argumente und Interaktionen über große Entfernungen konzentriert.
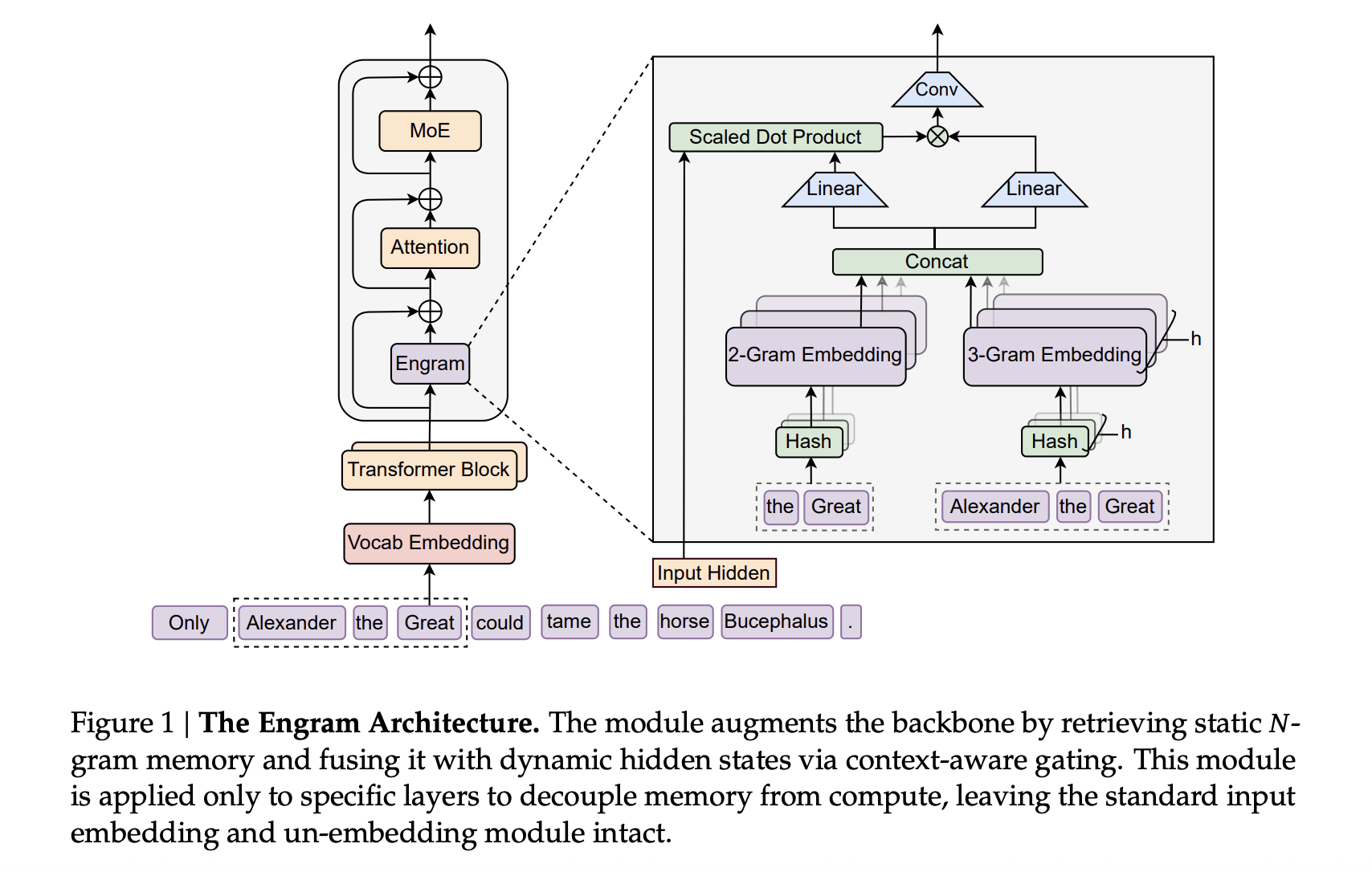
Wie Engram in einen DeepSeek-Transformer passt
Der vorgeschlagene Ansatz verwendet den DeepSeek V3-Tokenizer mit einem Vokabular von 128.000 und trainiert vorab auf 262B-Token. Das Rückgrat ist ein 30-Block-Transformator mit versteckter Größe 2560. Jeder Block verwendet Multi-Head Latent Consideration mit 32 Köpfen und verbindet sich mit Feed-Ahead-Netzwerken über Manifold Constrained Hyper Connections mit Expansionsrate 4. Die Optimierung nutzt den Muon-Optimierer.
Engram wird als spärliches Einbettungsmodul an dieses Rückgrat angehängt. Es besteht aus gehashten N-Gramm-Tabellen, mit Multi-Head-Hashing in Buckets mit Primzahlgröße, einer kleinen Tiefenfaltung über den N-Gramm-Kontext und einem kontextbewussten Gating-Skalar im Bereich von 0 bis 1, der steuert, wie viel der abgerufenen Einbettung in jeden Zweig injiziert wird.
In den Großmodellen nutzen Engram-27B und Engram-40B das gleiche Transformer-Grundgerüst wie MoE-27B. MoE-27B ersetzt den dichten Feed-Ahead durch DeepSeekMoE und nutzt 72 geroutete Experten und 2 gemeinsame Experten. Engram-27B reduziert die Zahl der weitergeleiteten Experten von 72 auf 55 und ordnet diese Parameter einem 5,7B großen Engram-Speicher zu, während die Gesamtparameter bei 26,7B bleiben. Das Engram-Modul verwendet N gleich {2,3}, 8 Engram-Köpfe, Dimension 1280 und wird auf den Schichten 2 und 15 eingefügt. Engram 40B erhöht den Engram-Speicher auf 18,5B Parameter, während die aktivierten Parameter unverändert bleiben.
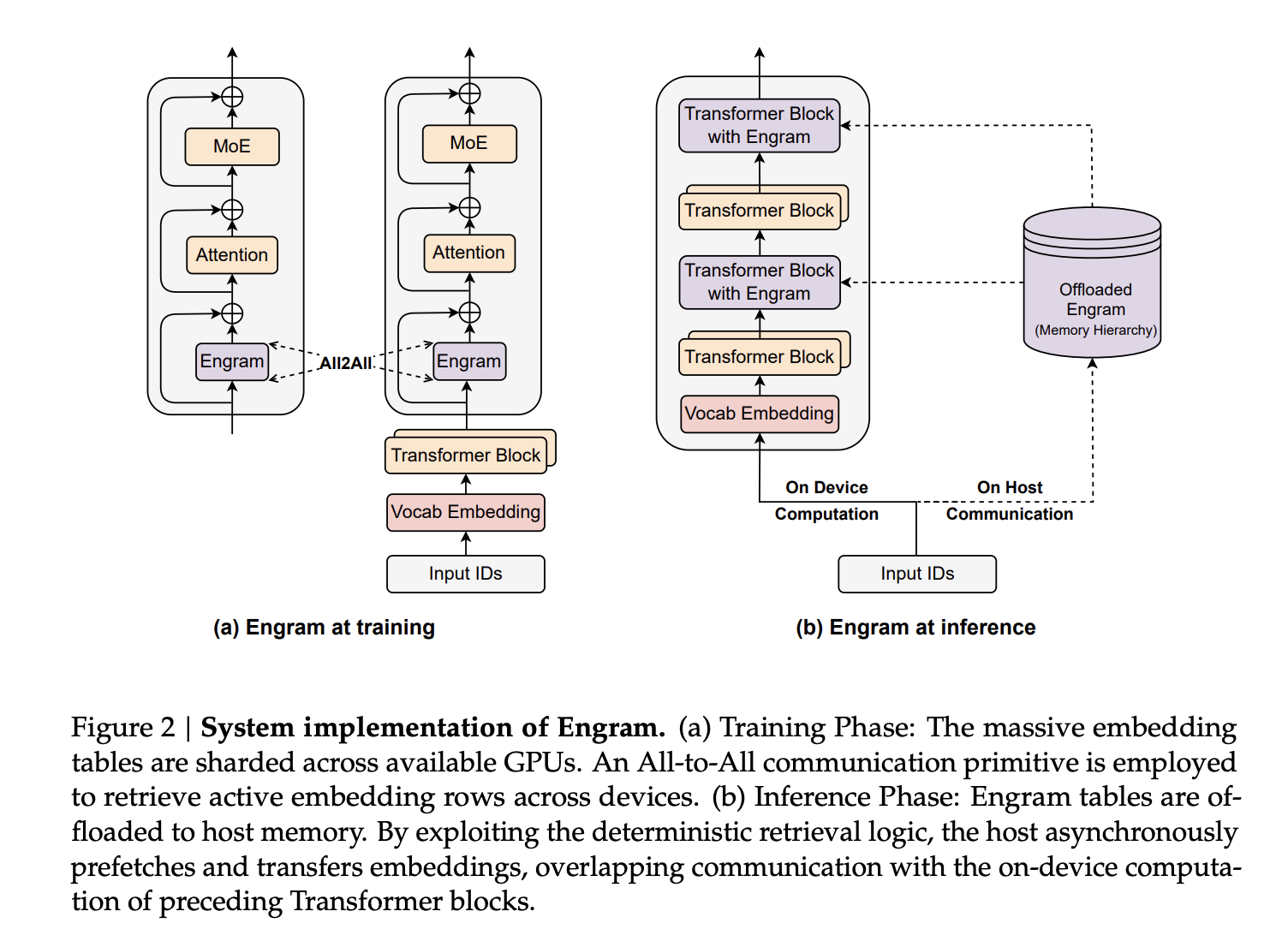
Sparsity-Zuteilung, ein zweiter Skalierungsknopf neben MoE
Die zentrale Entwurfsfrage besteht darin, wie das spärliche Parameterbudget zwischen weitergeleiteten Experten und bedingtem Speicher aufgeteilt werden kann. Das Forschungsteam formalisiert dies als Sparsity Allocation-Drawback, wobei das Allokationsverhältnis ρ als der Anteil inaktiver Parameter definiert ist, die MoE-Experten zugewiesen werden. Bei einem reinen MoE-Modell ist ρ gleich 1. Durch die Reduzierung von ρ werden Parameter von Experten in Engram-Slots neu zugewiesen.
Bei 5,7B- und 9,9B-Modellen im mittleren Maßstab ergibt das Sweepen von ρ eine klare U-förmige Kurve des Validierungsverlusts gegenüber dem Zuteilungsverhältnis. Engramm-Modelle stimmen mit der reinen MoE-Basislinie überein, selbst wenn ρ auf etwa 0,25 sinkt, was etwa halb so vielen gerouteten Experten entspricht. Das Optimum ergibt sich, wenn etwa 20 bis 25 Prozent des knappen Budgets für Engram bereitgestellt werden. Dieses Optimum ist über beide Rechenregime hinweg stabil, was auf eine robuste Trennung zwischen bedingter Berechnung und bedingtem Speicher bei fester Sparsity schließen lässt.
Das Forschungsteam untersuchte außerdem ein unendliches Speicherregime auf einem festen 3B-MoE-Spine, das für 100B-Tokens trainiert wurde. Sie skalieren die Engram-Tabelle von etwa 2,58e5 auf 1e7 Slots. Der Validierungsverlust folgt einem nahezu perfekten Potenzgesetz im Protokollspeicherbereich, was bedeutet, dass sich mehr bedingter Speicher ohne zusätzliche Rechenleistung auszahlt. Engram übertrifft bei gleichem Speicherbudget auch OverEncoding, eine weitere N-Gramm-Einbettungsmethode, die den Durchschnitt in die Vokabeleinbettung einbezieht.
Umfangreiche Ergebnisse vor dem Coaching
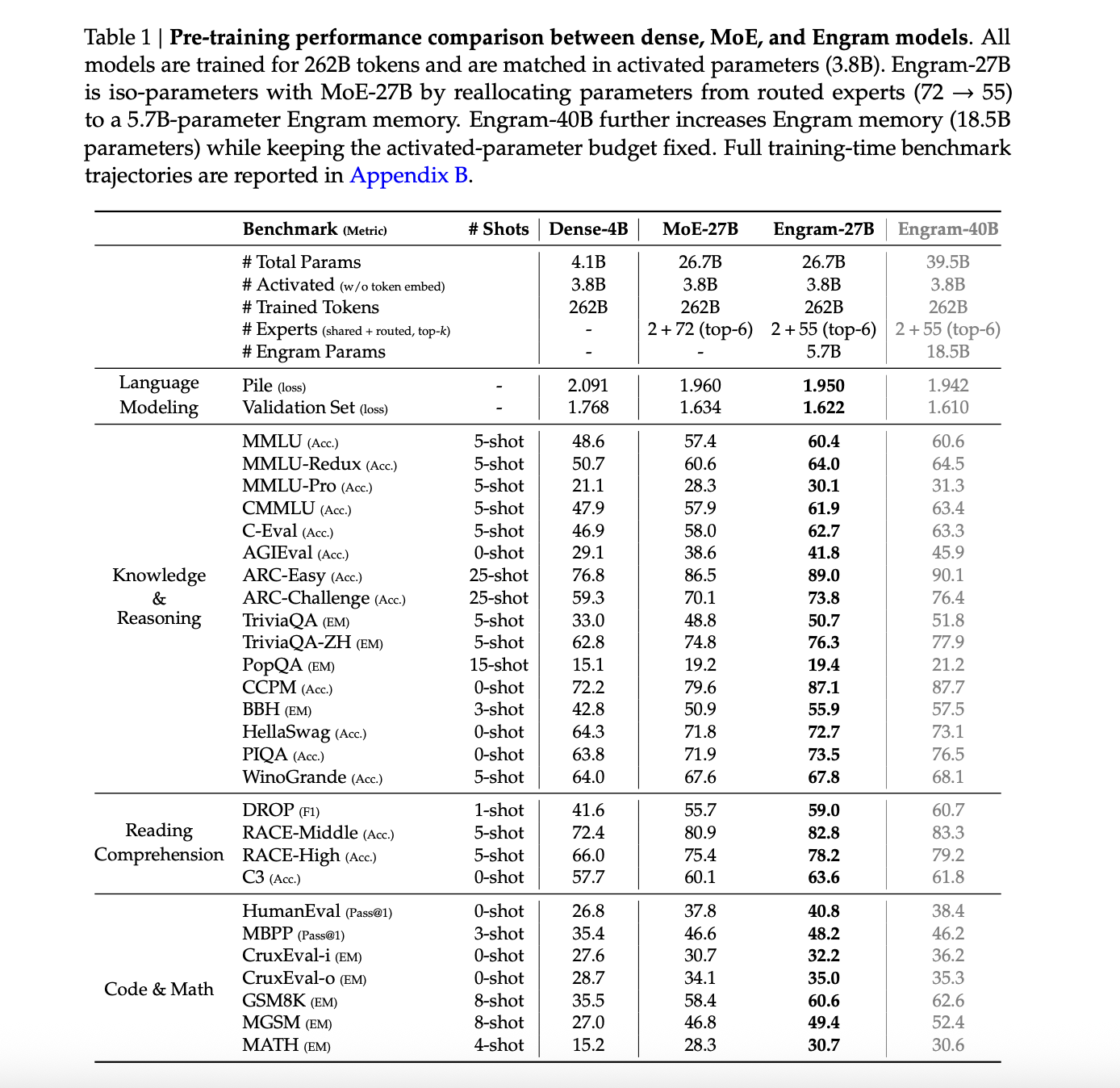
Der Hauptvergleich umfasst vier Modelle, die auf dem gleichen 262B-Token-Lehrplan trainiert wurden, mit in allen Fällen 3,8B aktivierten Parametern. Dies sind Dense 4B mit 4,1B Gesamtparametern, MoE 27B und Engram 27B mit 26,7B Gesamtparametern und Engram 40B mit 39,5B Gesamtparametern.
Beim The Pile-Testset beträgt der Sprachmodellierungsverlust 2,091 für MoE 27B, 1,960 für Engram 27B, 1,950 für die Engram 27B-Variante und 1,942 für Engram 40B. Der Verlust des dichten 4B-Pfahls wird nicht gemeldet. Der Validierungsverlust des intern gehaltenen Satzes sinkt von 1,768 für MoE 27B auf 1,634 für Engram 27B und auf 1,622 und 1,610 für die Engram-Varianten.
Bei Wissens- und Argumentations-Benchmarks verbessert sich Engram-27B kontinuierlich gegenüber MoE-27B. MMLU steigt von 57,4 auf 60,4, CMMLU von 57,9 auf 61,9 und C-Eval von 58,0 auf 62,7. ARC Problem steigt von 70,1 auf 73,8, BBH von 50,9 auf 55,9 und DROP F1 von 55,7 auf 59,0. Auch Code- und Mathematikaufgaben verbessern sich, beispielsweise HumanEval von 37,8 auf 40,8 und GSM8K von 58,4 auf 60,6.
Engram 40B treibt diese Zahlen in der Regel weiter in die Höhe, obwohl die Autoren anmerken, dass es bei 262B-Tokens wahrscheinlich untertrainiert ist, da sein Trainingsverlust gegen Ende des Vortrainings weiterhin von den Grundwerten abweicht.
Langes Kontextverhalten und mechanistische Effekte
Nach dem Vortraining erweitert das Forschungsteam das Kontextfenster mithilfe von YaRN auf 32.768 Token für 5.000 Schritte und verwendet dabei 30 Milliarden hochwertige lange Kontext-Token. Sie vergleichen MoE-27B und Engram-27B an Kontrollpunkten, die 41.000, 46.000 und 50.000 Schritten vor dem Coaching entsprechen.
Bei LongPPL und RULER im 32k-Kontext entspricht oder übertrifft Engram-27B MoE-27B unter drei Bedingungen. Mit etwa 82 Prozent der FLOPs vor dem Coaching entspricht Engram-27B bei 41.000 Schritten LongPPL und verbessert gleichzeitig die RULER-Genauigkeit, zum Beispiel Multi Question NIAH 99,6 gegenüber 73,0 und QA 44,0 gegenüber 34,5. Unter ISO-Verlust bei 46.000 und ISO-FLOPs bei 50.000 verbessert Engram 27B sowohl Ratlosigkeit als auch alle RULER-Kategorien, einschließlich VT und QA.
Die mechanistische Analyse verwendet LogitLens und Centered Kernel Alignment. Engrammvarianten zeigen eine geringere schichtweise KL-Divergenz zwischen Zwischenlogits und der endgültigen Vorhersage, insbesondere in frühen Blöcken, was bedeutet, dass Darstellungen früher vorhersagebereit sind. CKA-Ähnlichkeitskarten zeigen, dass flache Engram-Schichten am besten mit viel tieferen MoE-Schichten übereinstimmen. Beispielsweise ist Schicht 5 in Engram-27B etwa an Schicht 12 in der MoE-Grundlinie ausgerichtet. Zusammengenommen unterstützt dies die Ansicht, dass Engram die Modelltiefe effektiv erhöht, indem es die statische Rekonstruktion in den Speicher verlagert.
Ablationsstudien an einem 12-Schicht-3B-MoE-Modell mit 0,56B aktivierten Parametern fügen einen 1,6B-Engram-Speicher als Referenzkonfiguration hinzu, wobei N gleich {2,3} verwendet wird und Engram auf den Schichten 2 und 6 eingefügt wird. Das Durchziehen einer einzelnen Engram-Schicht über die Tiefe zeigt, dass eine frühe Einfügung auf Schicht 2 optimum ist. Die Komponentenablationen heben drei Schlüsselelemente hervor: Multi-Department-Integration, kontextbewusstes Gating und Tokenizer-Komprimierung.
Die Sensitivitätsanalyse zeigt, dass Faktenwissen stark von Engram abhängt, wobei TriviaQA auf etwa 29 Prozent seiner ursprünglichen Punktzahl sinkt, wenn Engram-Ausgaben bei der Inferenz unterdrückt werden, während Leseverständnisaufgaben etwa 81 bis 93 Prozent der Leistung beibehalten, beispielsweise C3 bei 93 Prozent.
Wichtige Erkenntnisse
- Engram fügt spärlichen LLMs eine bedingte Speicherachse hinzu, sodass häufige N-Gramm-Muster und -Entitäten über eine O(1)-Hash-Suche abgerufen werden, während sich die Transformer-Spine- und MoE-Experten auf dynamisches Denken und Abhängigkeiten über große Entfernungen konzentrieren.
- Unter einem festen Parameter und einem FLOPs-Price range verringert die Umverteilung von etwa 20 bis 25 Prozent der spärlichen Kapazität von MoE-Experten in den Engram-Speicher den Validierungsverlust, was zeigt, dass bedingter Speicher und bedingte Berechnungen sich ergänzen und nicht konkurrieren.
- Im groß angelegten Vortraining mit 262B-Tokens übertreffen Engram-27B und Engram-40B mit denselben aktivierten 3,8B-Parametern eine MoE-27B-Basislinie in Bezug auf Sprachmodellierung, Wissen, Argumentation, Code und mathematische Benchmarks, während die Transformer-Spine-Architektur unverändert bleibt.
- Die Erweiterung des langen Kontexts auf 32768 Token mithilfe von YaRN zeigt, dass Engram-27B mit LongPPL übereinstimmt oder es verbessert und die RULER-Werte deutlich verbessert, insbesondere Multi-Question-Needle in einem Haystack und Variablenverfolgung, selbst wenn es im Vergleich zu MoE-27B mit geringerer oder gleicher Rechenleistung trainiert wird.
Schauen Sie sich das an Papier Und GitHub-Repo. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Schauen Sie sich unsere neueste Model von an ai2025.deveine auf das Jahr 2025 ausgerichtete Analyseplattform, die Modelleinführungen, Benchmarks und Ökosystemaktivitäten in einen strukturierten Datensatz umwandelt, den Sie filtern, vergleichen und exportieren können.
Asif Razzaq ist CEO von Marktechpost Media Inc.. Als visionärer Unternehmer und Ingenieur setzt sich Asif dafür ein, das Potenzial der künstlichen Intelligenz für das soziale Wohl zu nutzen. Sein jüngstes Unterfangen ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch eine ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die sowohl technisch fundiert als auch für ein breites Publikum leicht verständlich ist. Die Plattform verfügt über mehr als 2 Millionen monatliche Aufrufe, was ihre Beliebtheit beim Publikum verdeutlicht.