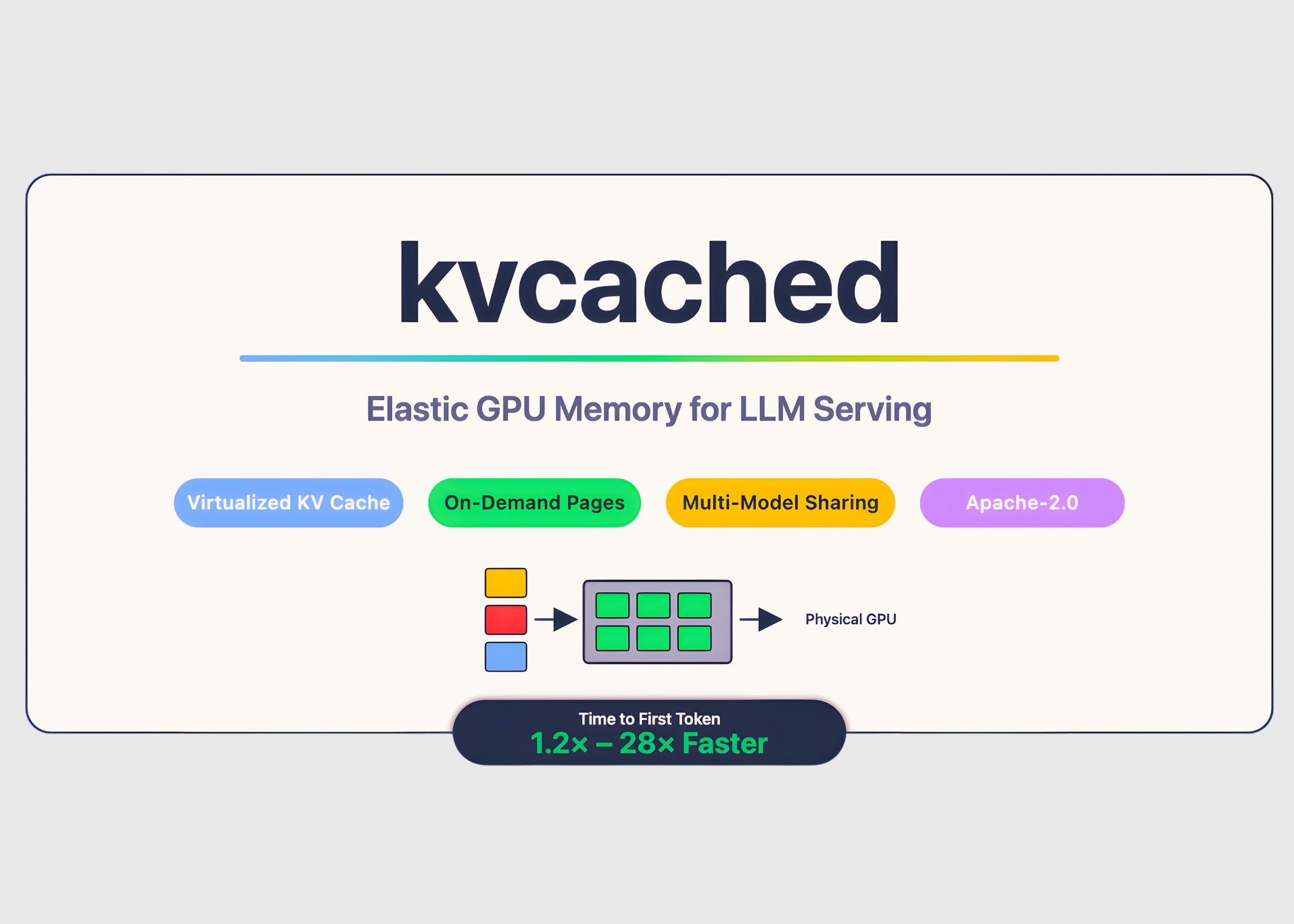
Bei der Bereitstellung großer Sprachmodelle wird häufig GPU-Speicher verschwendet, da Engines große statische KV-Cache-Bereiche professional Modell vorab reservieren, selbst wenn die Anforderungen stoßweise oder im Leerlauf sind. Treffen ‚kvcached‚, eine Bibliothek zur Aktivierung eines virtualisierten, elastischen KV-Cache für die LLM-Bereitstellung auf gemeinsam genutzten GPUs. kvcached wurde durch eine Forschung des Sky Computing Lab in Berkeley (College of California, Berkeley) in enger Zusammenarbeit mit der Rice College und der UCLA sowie mit wertvollem Enter von Mitarbeitern und Kollegen von NVIDIA, Intel Company und der Stanford College entwickelt. Es führt eine betriebssystemähnliche Abstraktion des virtuellen Speichers für den KV-Cache ein, die es Serving-Engines ermöglicht, zusammenhängende Reserven zu reservieren virtuell Zuerst Leerzeichen, dann nur die aktiven Teile mit zurück körperlich GPU-Seiten auf Anfrage. Diese Entkopplung erhöht die Speicherauslastung, reduziert Kaltstarts und ermöglicht mehreren Modellen die zeitliche und räumliche Nutzung eines Geräts ohne umfangreiche Engine-Neuschreibungen.
Welche kvcached-Änderungen?
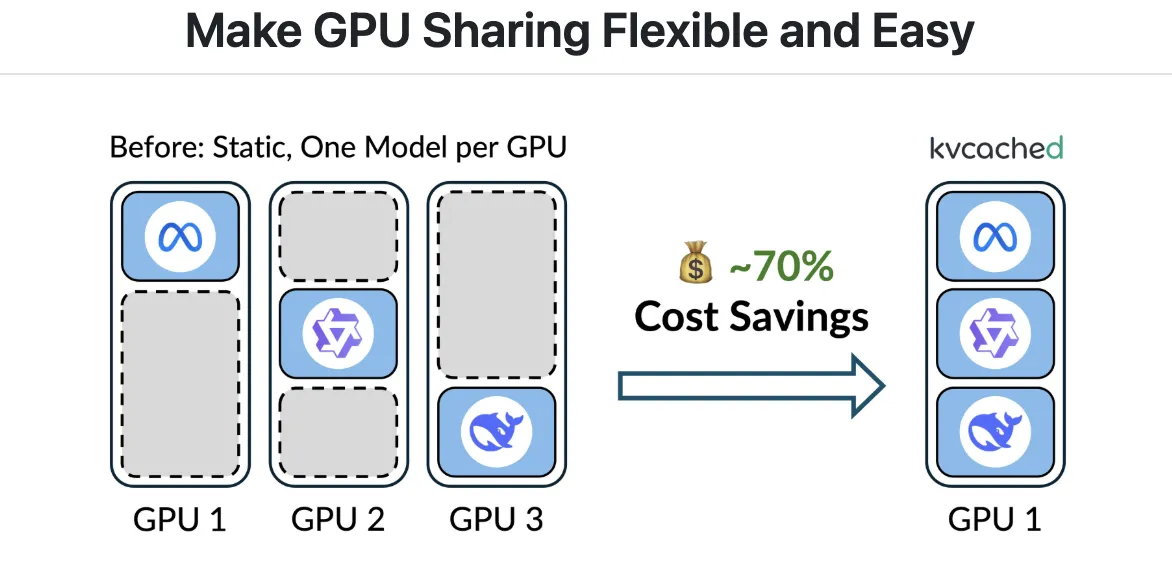
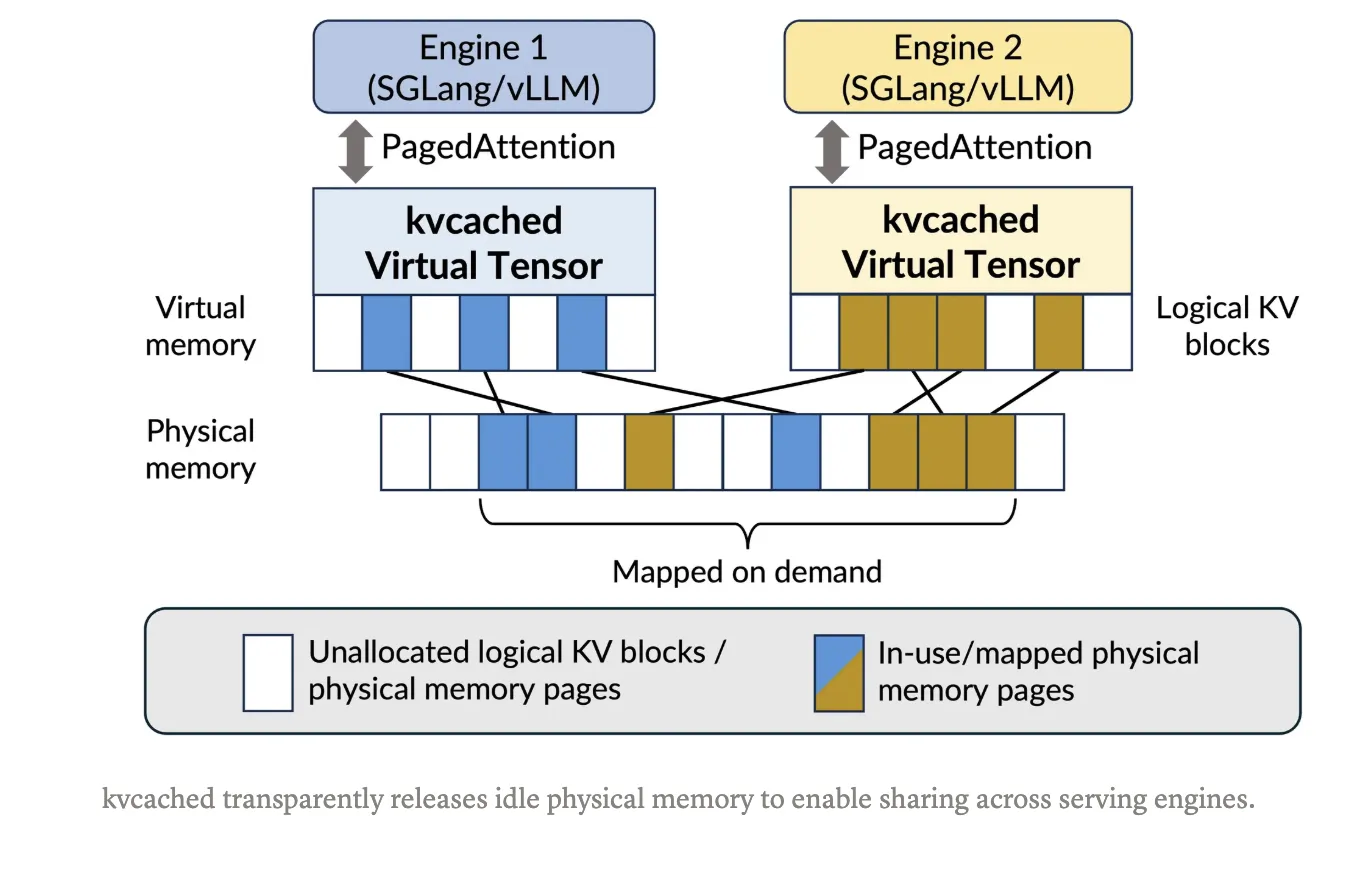
Mit kvcached erstellt eine Engine einen KV-Cache-Pool, der im virtuellen Adressraum zusammenhängend ist. Sobald Token eintreffen, ordnet die Bibliothek physische GPU-Seiten mithilfe von CUDA-APIs für den virtuellen Speicher langsam und mit feiner Granularität zu. Wenn Anforderungen abgeschlossen werden oder Modelle inaktiv werden, wird die Zuordnung der Seiten aufgehoben und sie kehren zu einem gemeinsamen Pool zurück, den andere am gleichen Standort befindliche Modelle sofort wiederverwenden können. Dadurch bleibt die einfache Zeigerarithmetik in Kerneln erhalten und es ist kein Paging professional Engine-Benutzerebene mehr erforderlich. Das Projekt zielt darauf ab SGLang Und vLLM Integration und wird unter der Apache 2.0-Lizenz veröffentlicht. Die Set up und ein Schnellstart mit einem Befehl sind im dokumentiert Git-Repository.
Wie wirkt es sich im großen Maßstab aus?
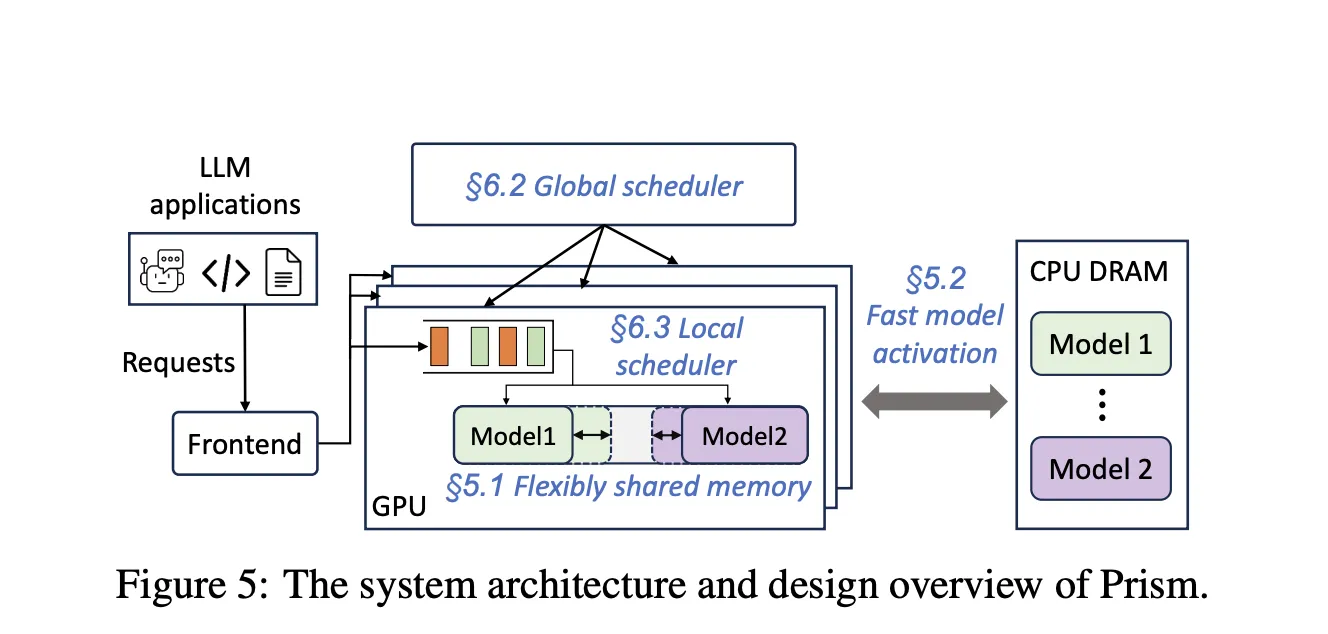
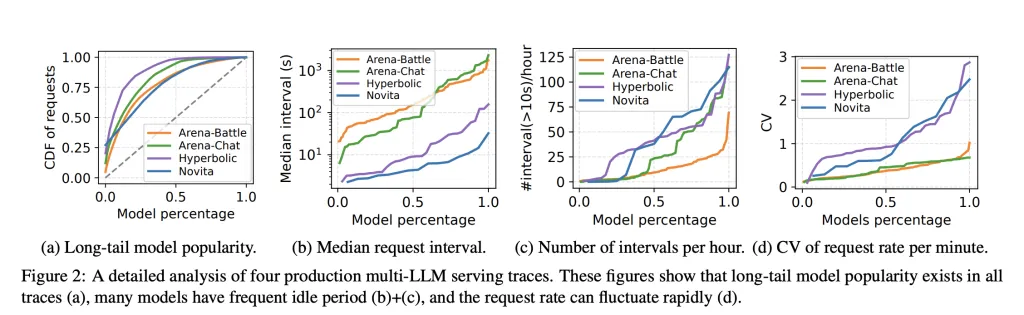
Produktions-Workloads beherbergen viele Modelle mit Lengthy-Tail-Site visitors und Spitzenausbrüchen. Durch statische Reservierungen wird der Speicher blockiert und die Zeit bis zum ersten Token verlangsamt, wenn Modelle aktiviert oder ausgetauscht werden müssen. Der Prisma Forschungsarbeit zeigt, dass eine Multi-LLM-Bereitstellung erforderlich ist Modellübergreifende Gedächtniskoordination zur Laufzeit, nicht nur die Berechnungsplanung. Prism implementiert die On-Demand-Zuordnung von physischen zu virtuellen Seiten sowie einen zweistufigen Planer und Berichte mehr als 2 Mal Kosteneinsparungen und 3,3 Mal Höhere TTFT-SLO-Erreichung im Vergleich zu früheren Systemen auf realen Spuren. kvcached konzentriert sich auf das Speicherkoordinationsprimitiv und stellt eine wiederverwendbare Komponente bereit, die diese Fähigkeit auf Mainstream-Engines überträgt.
Leistungssignale
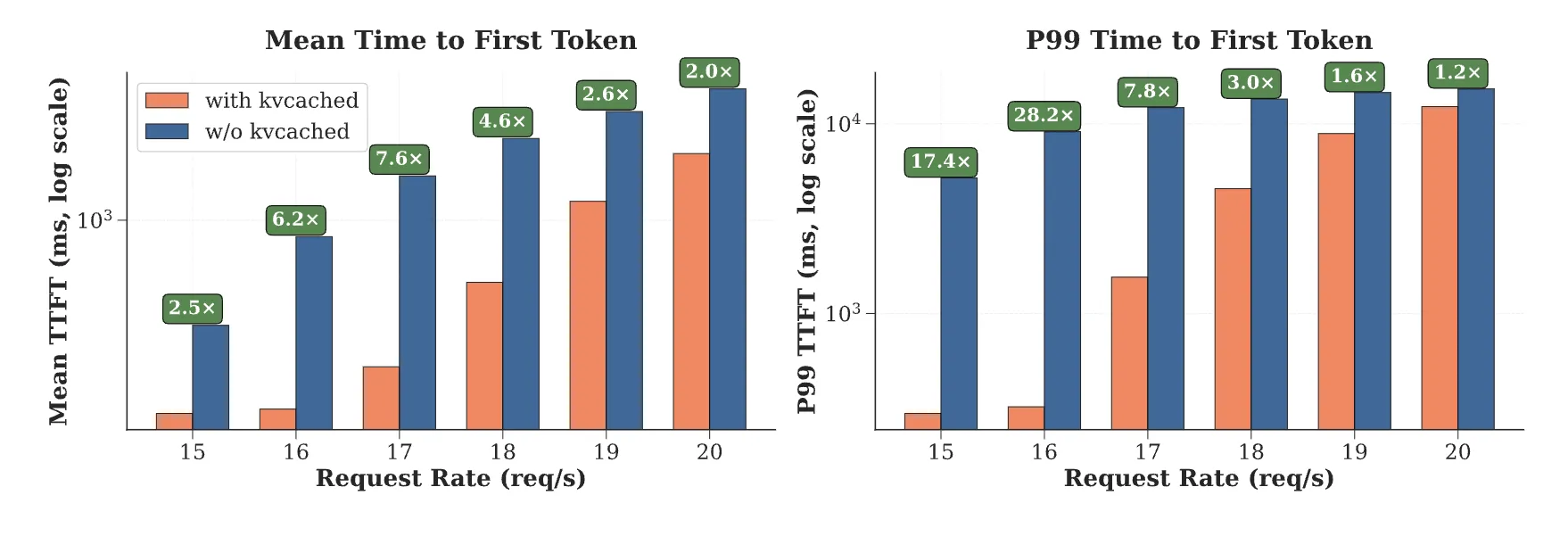
Das kvcached-Group berichtet 1,2-fach bis 28-fach Schneller Zeit bis zum ersten Token bei der Bereitstellung mehrerer Modelle aufgrund der sofortigen Wiederverwendung freigegebener Seiten und der Entfernung großer statischer Zuweisungen. Diese Zahlen stammen aus Multi-LLM-Szenarien, in denen Aktivierungslatenz und Speicherreserve die Endlatenz dominieren. Das Forschungsteam weist auf die Kompatibilität von kvcached mit SGLang und vLLM hin und beschreibt die elastische KV-Zuteilung als Kernmechanismus.
In welcher Beziehung steht es zur aktuellen Forschung?
Die jüngste Arbeit hat sich von der festen Partitionierung zu Methoden für die KV-Verwaltung entwickelt, die auf virtuellem Speicher basieren. Prisma erweitert die VMM-basierte Zuordnung auf Multi-LLM-Einstellungen mit modellübergreifender Koordination und Planung. Frühere Bemühungen wie vAchtung Erkunden Sie CUDA VMM für ein einzelnes Modell, um Fragmentierung ohne PagedAttention zu vermeiden. Der Bogen ist klar: Verwenden Sie virtuellen Speicher, um KV im virtuellen Raum zusammenhängend zu halten, und ordnen Sie dann physische Seiten elastisch zu, wenn sich die Arbeitslast entwickelt. kvcached verwirklicht diese Idee als Bibliothek, was die Übernahme in bestehende Engines vereinfacht.
Praktische Anwendungen für Entwickler
Colocation über Modelle hinweg: Engines können mehrere kleine oder mittlere Modelle auf einem Gerät zusammenfassen. Wenn ein Modell in den Leerlauf geht, werden seine KV-Seiten schnell freigegeben und ein anderes Modell kann seinen Arbeitssatz ohne Neustart erweitern. Dies reduziert die Blockierung des Leitungskopfes während Bursts und verbessert die TTFT-SLO-Erreichung.
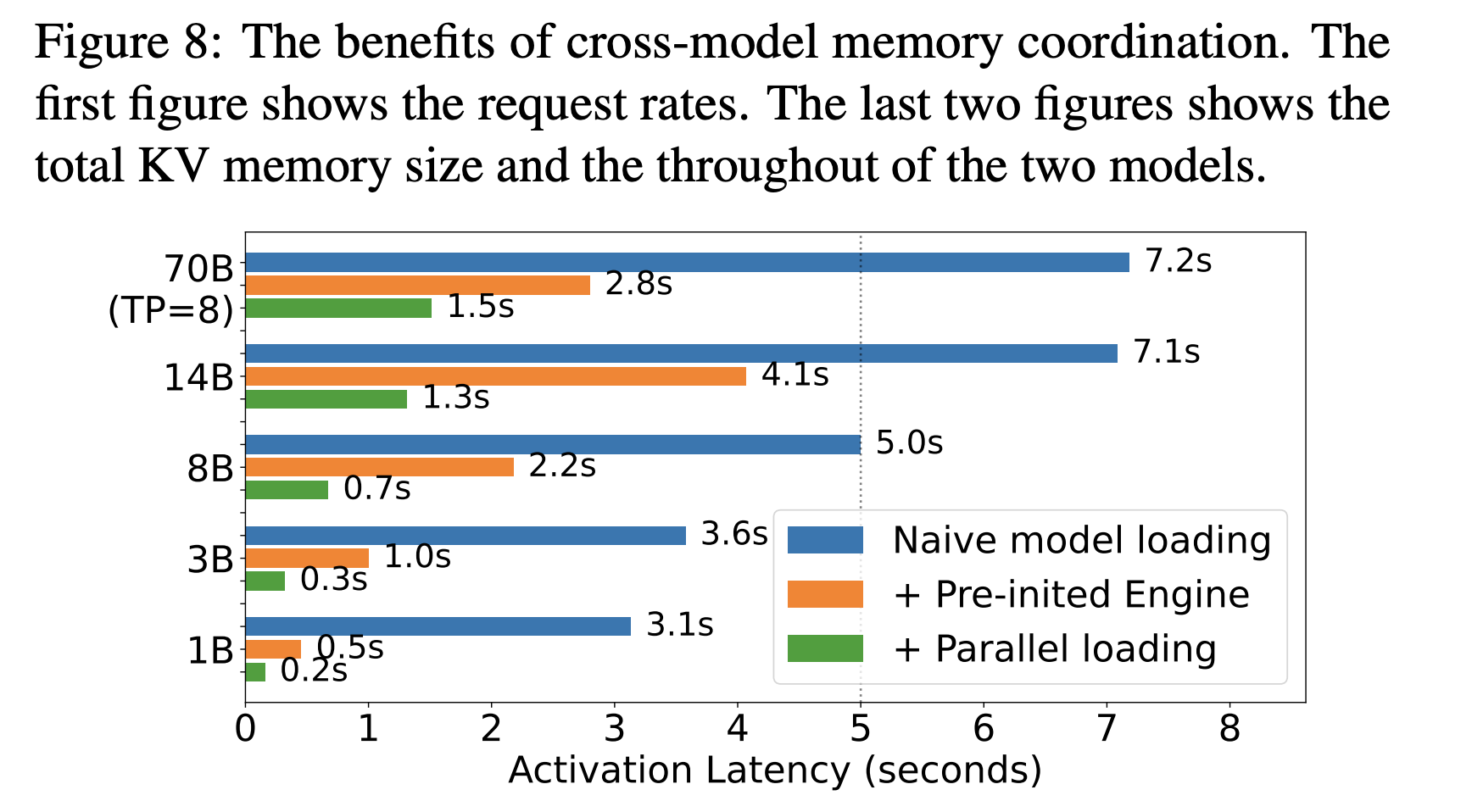
Aktivierungsverhalten: Prism meldet Aktivierungszeiten von ca 0,7 Sekunden für ein 8B Modell und ungefähr 1,5 Sekunden für ein 70B Modell mit Streaming-Aktivierung. kvcached profitiert von ähnlichen Prinzipien, da virtuelle Reservierungen es Engines ermöglichen, Adressbereiche im Voraus vorzubereiten und dann Seiten zuzuordnen, sobald Token eintreffen.
Autoskalierung für serverloses LLM: Durch die feinkörnige Seitenzuordnung ist es möglich, Replikate häufiger zu skalieren und kalte Modelle in einem warmen Zustand mit minimalem Speicherbedarf auszuführen. Dies ermöglicht engere Autoskalierungsschleifen und verringert den Explosionsradius von Hotspots.
Entladen und zukünftige Arbeit. Virtueller Speicher öffnet die Tür zur KV-Auslagerung auf Host-Speicher oder NVMe, wenn das Zugriffsmuster dies zulässt. NVIDIAs aktueller Leitfaden über verwalteten Speicher für KV-Offload auf Systemen der GH200-Klasse zeigt, wie einheitliche Adressräume die Kapazität bei akzeptablem Overhead erweitern können. Die kvcached-Betreuer diskutieren auch Offload- und Komprimierungsanweisungen in öffentlichen Threads. Überprüfen Sie Durchsatz und Latenz in Ihrer eigenen Pipeline, da Zugriffsort und PCIe-Topologie starke Auswirkungen haben.
Wichtige Erkenntnisse
- kvcached virtualisiert den KV-Cache mithilfe des virtuellen GPU-Speichers, Engines reservieren zusammenhängenden virtuellen Speicherplatz und ordnen physische Seiten bei Bedarf zu und ermöglichen so eine elastische Zuweisung und Rückgewinnung unter dynamischen Lasten.
- Es lässt sich in gängige Inferenz-Engines integrieren, insbesondere SGLang und vLLM, und wird unter Apache 2.0 veröffentlicht, wodurch die Einführung und Änderung für Produktions-Serving-Stacks einfach ist.
- Öffentliche Benchmarks berichten von einer 1,2- bis 28-mal schnelleren Zeit bis zum ersten Token bei der Bereitstellung mehrerer Modelle aufgrund der sofortigen Wiederverwendung freigegebener KV-Seiten und der Entfernung großer statischer Reservierungen.
- Prism zeigt, dass die modellübergreifende Speicherkoordination, die über On-Demand-Mapping und zweistufige Planung implementiert wird, zu mehr als zweifachen Kosteneinsparungen und einer 3,3-mal höheren TTFT-SLO-Erreichung bei realen Spuren führt. Kvcached stellt das Speicherprimitiv bereit, das Mainstream-Engines wiederverwenden können.
- Für Cluster, die viele Modelle mit stoßartigem Lengthy-Tail-Verkehr hosten, ermöglicht der virtualisierte KV-Cache eine sichere Colocation, schnellere Aktivierung und eine engere automatische Skalierung, wobei in der Prism-Bewertung eine Aktivierung von etwa 0,7 Sekunden für ein 8B-Modell und 1,5 Sekunden für ein 70B-Modell gemeldet wurde.
kvcached ist ein effektiver Ansatz zur GPU-Speichervirtualisierung für die LLM-Bereitstellung, kein vollständiges Betriebssystem, und Klarheit ist wichtig. Die Bibliothek reserviert virtuellen Adressraum für den KV-Cache und ordnet dann physische Seiten bei Bedarf zu, was eine elastische gemeinsame Nutzung zwischen Modellen mit minimalen Engine-Änderungen ermöglicht. Dies steht im Einklang mit Beweisen dafür, dass modellübergreifende Speicherkoordination für Workloads mit mehreren Modellen unerlässlich ist und die SLO-Erreichung und Kosten unter realen Spuren verbessert. Insgesamt verbessert kvcached die GPU-Speicherkoordination für die LLM-Bereitstellung, der Produktionswert hängt von der Validierung professional Cluster ab.
Schauen Sie sich das an GitHub-Repo, Papier 1, Papier 2 Und Technische Particulars. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Asif Razzaq ist CEO von Marktechpost Media Inc.. Als visionärer Unternehmer und Ingenieur setzt sich Asif dafür ein, das Potenzial der künstlichen Intelligenz für das soziale Wohl zu nutzen. Sein jüngstes Unterfangen ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch eine ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die sowohl technisch fundiert als auch für ein breites Publikum leicht verständlich ist. Die Plattform verfügt über mehr als 2 Millionen monatliche Aufrufe, was ihre Beliebtheit beim Publikum verdeutlicht.