Liquid AI hat LFM2.5 eingeführt, eine neue Technology kleiner Basismodelle, die auf der LFM2-Architektur basieren und sich auf Geräte- und Edge-Bereitstellungen konzentrieren. Die Modellfamilie umfasst LFM2.5-1.2B-Base und LFM2.5-1.2B-Instruct und erstreckt sich auf die Varianten Japanisch, Bildsprache und Audiosprache. Es wird als offene Gewichte auf Hugging Face freigegeben und über die LEAP-Plattform freigelegt.
Architektur- und Trainingsrezept
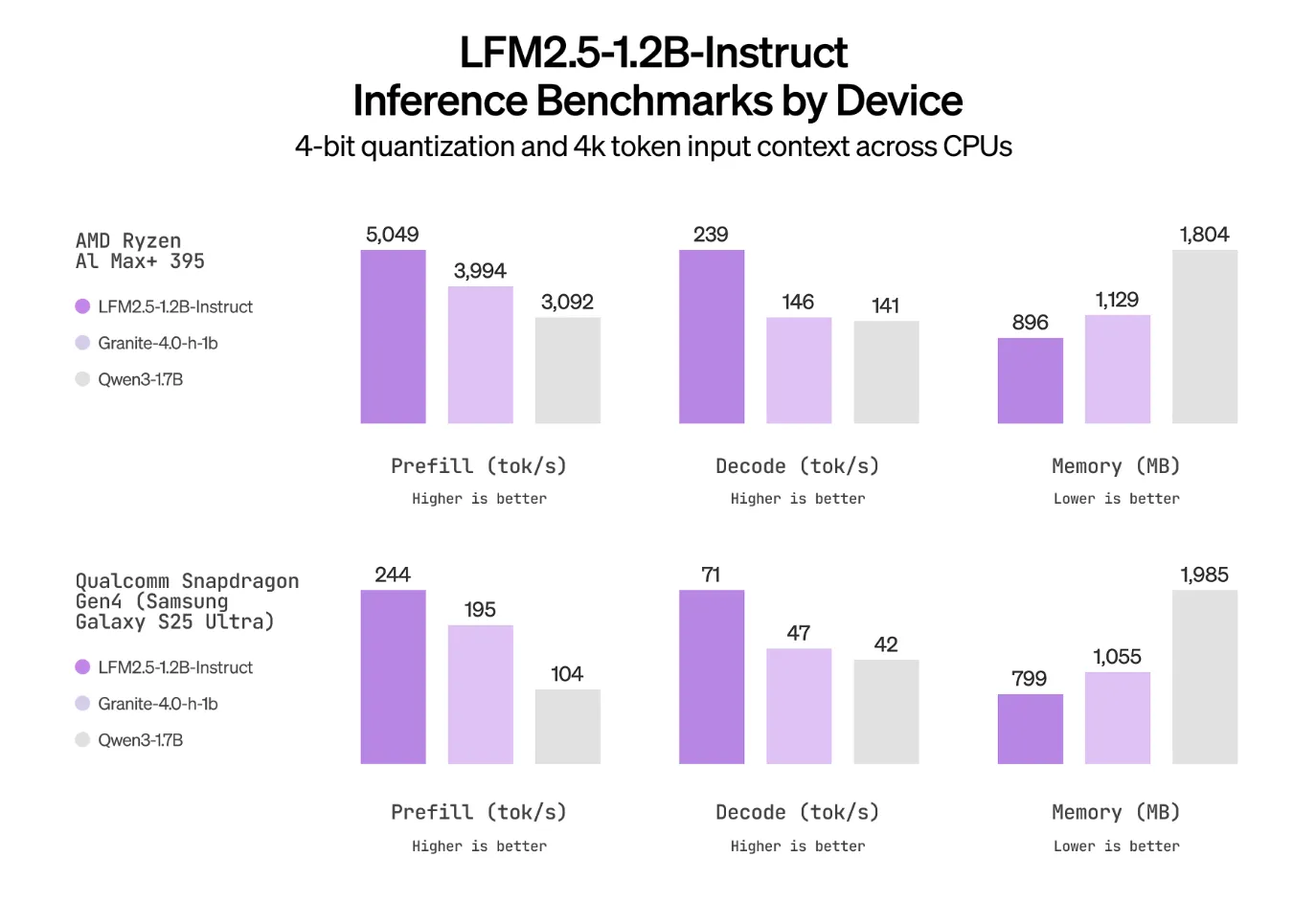
LFM2.5 behält die hybride LFM2-Architektur bei, die für schnelle und speichereffiziente Inferenz auf CPUs und NPUs entwickelt wurde, und skaliert die Daten- und Publish-Coaching-Pipeline. Das Vortraining für das 1,2-Milliarden-Parameter-Spine wird von 10T- auf 28T-Tokens erweitert. Die Anweisungsvariante erhält dann eine überwachte Feinabstimmung, Präferenzausrichtung und groß angelegtes mehrstufiges Verstärkungslernen, das sich auf die Befolgung von Anweisungen, die Verwendung von Werkzeugen, Mathematik und Wissensbegründung konzentriert.
Textmodellleistung im Maßstab einer Milliarde
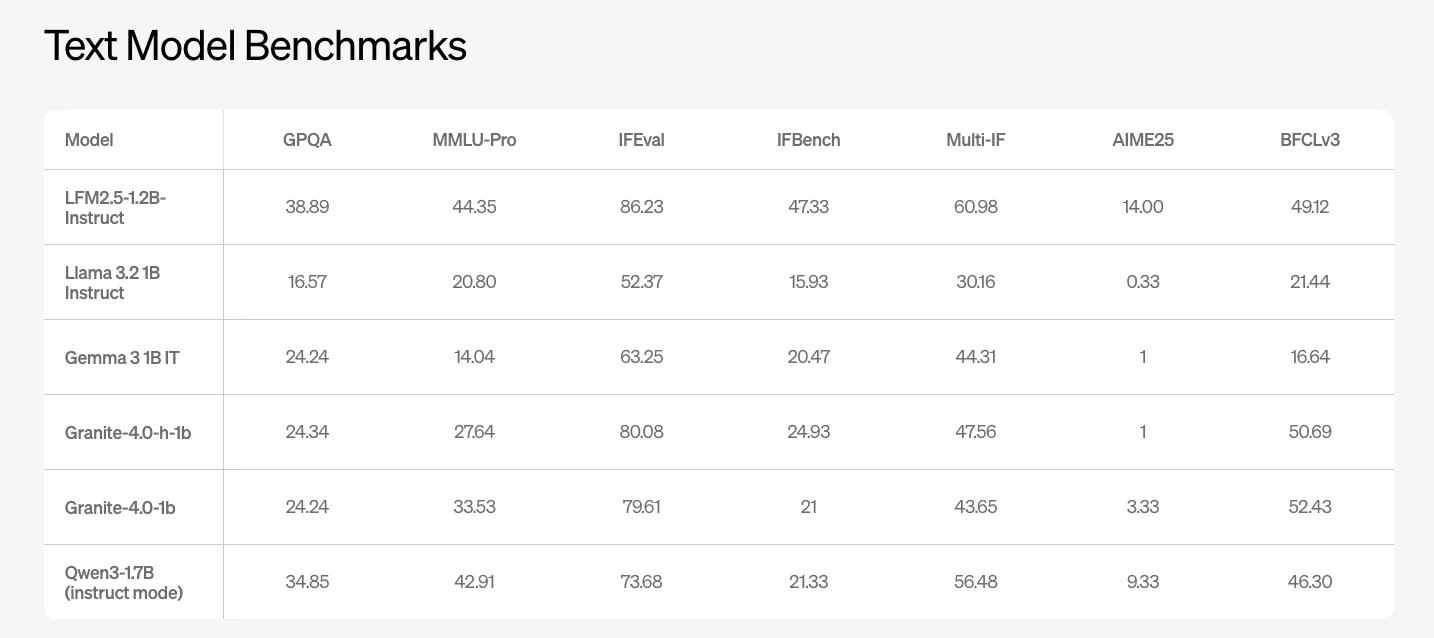
LFM2.5-1.2B-Instruct ist das wichtigste allgemeine Textmodell. Das Liquid AI-Crew meldet Benchmark-Ergebnisse für GPQA, MMLU Professional, IFEval, IFBench und mehrere Funktionsaufruf- und Codierungssuiten. Das Modell erreicht 38,89 bei GPQA und 44,35 bei MMLU Professional. Konkurrierende offene Modelle der 1B-Klasse wie Llama-3.2-1B Instruct und Gemma-3-1B IT schneiden bei diesen Kennzahlen deutlich schlechter ab.
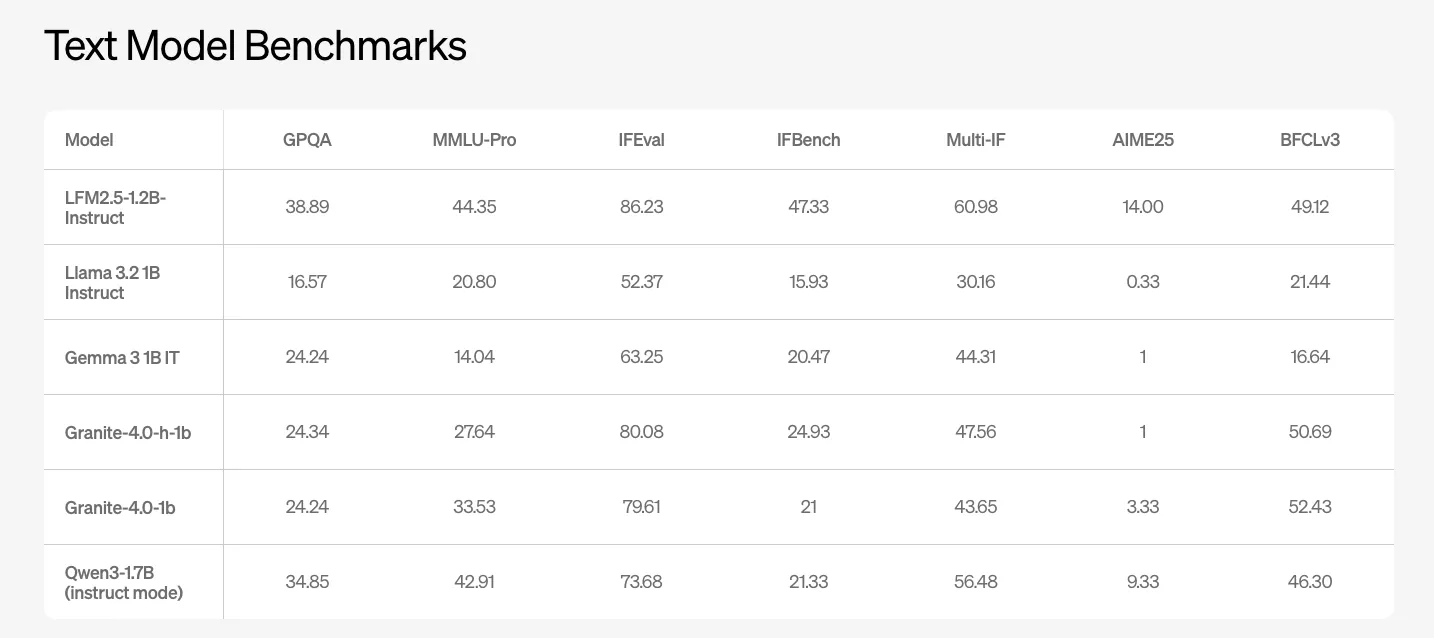
Bei IFEval und IFBench, die auf mehrstufige Befehlsverfolgung und Funktionsaufrufqualität abzielen, meldet LFM2.5-1.2B-Instruct 86,23 und 47,33. Diese Werte liegen über den anderen Basiswerten der 1B-Klasse in der obigen Liquid AI-Tabelle.
Japanisch optimierte Variante
LFM2.5-1.2B-JP ist ein für Japanisch optimiertes Textmodell, das vom gleichen Spine abgeleitet ist. Es zielt auf Aufgaben wie JMMLU, M-IFEval auf Japanisch und GSM8K auf Japanisch ab. Dieser Prüfpunkt übertrifft das allgemeine Unterrichtsmodell für japanische Aufgaben und konkurriert mit oder übertrifft andere kleine mehrsprachige Modelle wie Qwen3-1.7B, Llama 3.2-1B Unterricht und Gemma 3-1B IT bei diesen lokalisierten Benchmarks.
Imaginative and prescient-Sprachmodell für multimodale Edge-Workloads
LFM2.5-VL-1.6B ist das aktualisierte Imaginative and prescient-Sprachmodell der Serie. Es nutzt LFM2.5-1.2B-Base als Sprachrückgrat und fügt einen Imaginative and prescient Tower für das Bildverständnis hinzu. Das Modell ist auf eine Reihe von Benchmarks für visuelles Denken und OCR abgestimmt, darunter MMStar, MM IFEval, BLINK, InfoVQA, OCRBench v2, RealWorldQA, MMMU und mehrsprachiges MMBench. LFM2.5-VL-1.6B verbessert die meisten Metriken gegenüber dem vorherigen LFM2-VL-1.6B und ist für reale Aufgaben wie das Verstehen von Dokumenten, das Lesen von Benutzeroberflächen und die Argumentation mehrerer Bilder unter Randeinschränkungen gedacht.
Audio-Sprachmodell mit nativer Sprachgenerierung
LFM2.5-Audio-1.5B ist ein natives Audiosprachenmodell, das sowohl Textual content- als auch Audioein- und -ausgänge unterstützt. Es wird als Audio-zu-Audio-Modell präsentiert und verwendet einen Audio-Detokenizer, der bei gleicher Präzision auf eingeschränkter {Hardware} achtmal schneller als der vorherige Mimi-basierte Detokenizer ist.
Das Modell unterstützt zwei Hauptgenerierungsmodi. Die interleaved-Generierung ist für Echtzeit-Speech-to-Speech-Konversationsagenten konzipiert, bei denen die Latenz vorherrscht. Die sequentielle Generierung zielt auf Aufgaben wie automatische Spracherkennung und Textual content-to-Speech ab und ermöglicht den Wechsel der generierten Modalität ohne Neuinitialisierung des Modells. Der Audio-Stack wird mit quantisierungsbewusstem Coaching bei niedriger Präzision trainiert, wodurch Metriken wie STOI und UTMOS nahe an der Basislinie mit voller Präzision bleiben und gleichzeitig die Bereitstellung auf Geräten mit begrenzter Rechenleistung ermöglicht werden.
Wichtige Erkenntnisse
- LFM2.5 ist eine Hybridmodellfamilie im Maßstab 1,2B, die auf der geräteoptimierten LFM2-Architektur basiert, mit den Varianten Base, Instruct, Japanese, Imaginative and prescient Language und Audio Language, die alle als offene Gewichte auf Hugging Face und LEAP veröffentlicht werden.
- Das Vortraining für LFM2.5 erstreckt sich von 10T- bis 28T-Tokens und das Instruct-Modell fügt überwachte Feinabstimmung, Präferenzausrichtung und groß angelegtes mehrstufiges Verstärkungslernen hinzu, wodurch die Qualität der Befehlsbefolgung und der Werkzeugnutzung über andere Basislinien der 1B-Klasse hinausgeht.
- LFM2.5-1.2B-Instruct liefert eine starke Textual content-Benchmark-Leistung auf der 1B-Skala und erreicht 38,89 bei GPQA und 44,35 bei MMLU Professional sowie führende Peer-Modelle wie Llama 3.2 1B Instruct, Gemma 3 1B IT und Granite 4.0 1B bei IFEval und IFBench.
- Die Familie umfasst spezialisierte multimodale und regionale Varianten, wobei LFM2.5-1.2B-JP in seiner Größenordnung hochmoderne Ergebnisse für japanische Benchmarks erzielt und LFM2.5-VL-1.6B und LFM2.5-Audio-1.5B Imaginative and prescient-Sprach- und native Audio-Sprach-Workloads für Edge-Agenten abdecken.
Schauen Sie sich das an Technische Particulars Und Modellgewichte. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Schauen Sie sich unsere neueste Model von an ai2025.deveine auf das Jahr 2025 ausgerichtete Analyseplattform, die Modelleinführungen, Benchmarks und Ökosystemaktivitäten in einen strukturierten Datensatz umwandelt, den Sie filtern, vergleichen und exportieren können
Der Beitrag Liquid AI veröffentlicht LFM2.5: eine kompakte KI-Modellfamilie für echte On-Gadget-Brokers erschien zuerst auf MarkTechPost.