Ein Workforce von Forschern der Meta -Actuality -Labors und der Carnegie Mellon College hat eingeführt MapanythingEine Finish-to-Finish-Transformatorarchitektur, die die faktorisierte metrische 3D-Szene-Geometrie direkt aus Bildern und optionalen Sensoreingängen zurückbaut. Mapanything wird unter Apache 2.0 mit vollem Trainings- und Benchmarking-Code veröffentlicht und rechnet über spezialisierte Pipelines hinaus, indem sie über 12 verschiedene 3D-Sichtaufgaben in einem einzigen Futtermittelpass unterstützt.

Warum ein universelles Modell für die 3D -Rekonstruktion?
Die bildbasierte 3D-Rekonstruktion stützte sich historisch auf fragmentierte Pipelines: Merkmalserkennung, Zwei-View-Pose-Schätzung, Bündelanpassung, Multi-View-Stereoanlage oder monokulare Tiefeninferenz. Diese modularen Lösungen erfordern zwar wirksam, erfordern zwar eine aufgabenspezifische Abstimmung, Optimierung und eine starke Nachbearbeitung.
Neuere transformatorbasierte Feed-Ahead-Modelle wie Dust3R, MAST3R und VGGT vereinfachen Teile dieser Pipeline, blieben jedoch begrenzt: Feste Anzahl von Ansichten, starre Kameraannahmen oder Abhängigkeit von gekoppelten Darstellungen, die eine teure Optimierung benötigten.
Mapanything überwindet diese Einschränkungen von:
- Akzeptieren 2.000 Eingangsbilder in einem einzigen Inferenzlauf.
- Flexibel mit Hilfsdaten wie z. Kameraintrinsik, Posen und Tiefenkarten.
- Produzieren Direkte metrische 3D -Rekonstruktionen ohne Bündelanpassung.
Die faktorisierte Szenenrepräsentation des Modells – die Strahlkarten, Tiefe, Posen und ein globaler Skalierungsfaktor – Modularität und Allgemeingültigkeit, die durch vorherige Ansätze unübertroffen sind, bereitstellen.
Architektur und Darstellung
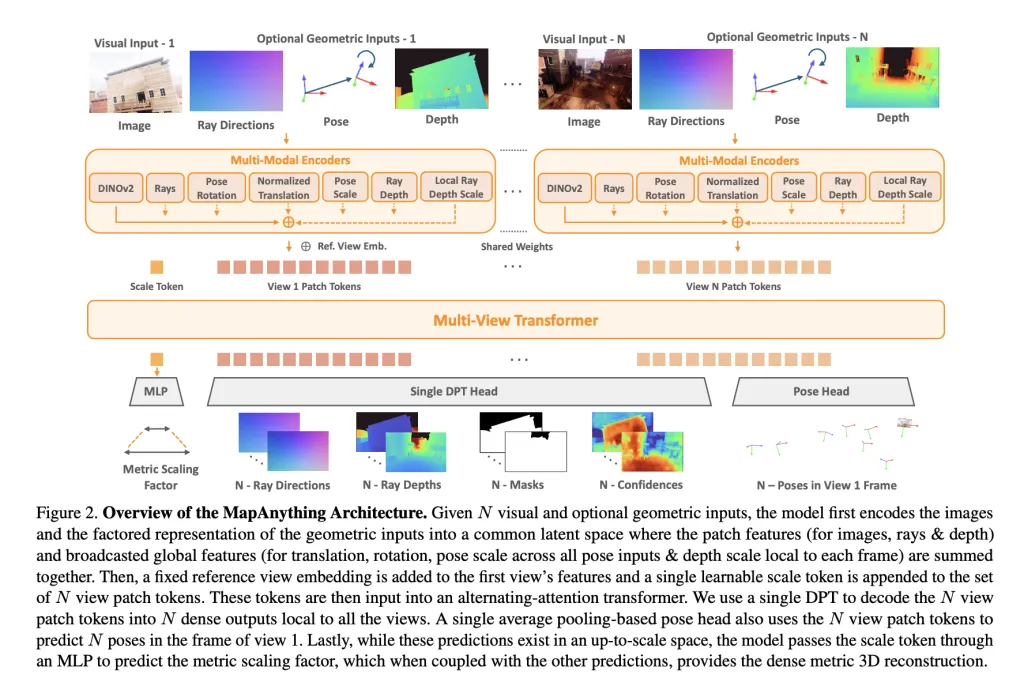
Im Kern verwendet Mapanything a Multi-View-Alternationsbekämpfungstransformator. Jedes Eingabebild ist codiert mit Dinov2 Vit-L Merkmale, während optionale Eingänge (Strahlen, Tiefe, Posen) über flache CNNs oder MLPs in denselben latenten Raum codiert werden. A Lernbarer Maßstabs -Token Ermöglicht die Metriknormalisierung über Ansichten hinweg.
Das Netzwerk gibt a aus berücksichtigte Darstellung:
- Per-View Strahlen Richtung (Kamera -Kalibrierung).
- Tiefe entlang von Strahlenvorhergesagt.
- Kamera posiert relativ zu einer Referenzansicht.
- Eine Single Metrischer Skalierungsfaktor Umwandlung lokaler Rekonstruktionen in einen world konsistenten Rahmen.
Diese explizite Faktorisierung vermeidet Redundanz, so dass dasselbe Modell die Schätzung der monokularen Tiefe, die Multi-View-Stereoanlage, die Struktur-FROM-Movement (SFM) oder die Tiefenabschluss ohne spezialisierte Köpfe verarbeiten kann.
Trainingsstrategie
Mapanything wurde über trainiert 13 verschiedene Datensätze Spannung in Innen-, Außen- und synthetischen Domänen, einschließlich BlendedMVs, Mapillary Planet-Scale-Tiefe, Scannet ++ und Tartanairv2. Zwei Varianten werden veröffentlicht:
- Apache 2.0 lizenziert Modell, das auf sechs Datensätzen trainiert wird.
- CC BY-NC-Modell Ausgebildet auf allen dreizehn Datensätzen für eine stärkere Leistung.
Zu den wichtigsten Schulungsstrategien gehören:
- Probabilistische Eingabeabbrecher: Während des Trainings sind geometrische Eingaben (Strahlen, Tiefe, Pose) mit unterschiedlichen Wahrscheinlichkeiten versorgt, die Robustheit über heterogene Konfigurationen hinweg ermöglichen.
- Kovisibilitätsbasierte Stichprobe: Stellen Sie sicher, dass die Eingabeansichten eine sinnvolle Überlappung haben und die Rekonstruktion bis zu 100+ Ansichten unterstützen.
- Faktorierte Verluste im Protokollraum: Tiefe, Skala und Pose werden unter Verwendung von skalierungsinvarianten und robusten Regressionsverlusten optimiert, um die Stabilität zu verbessern.
Das Coaching wurde an durchgeführt 64 H200 GPUs mit gemischter Präzision, Gradientenprüfung und Lehrplanplanung, Skalierung von 4 auf 24 Eingangsansichten.
Benchmarking -Ergebnisse
Multi-View-Dense Rekonstruktion
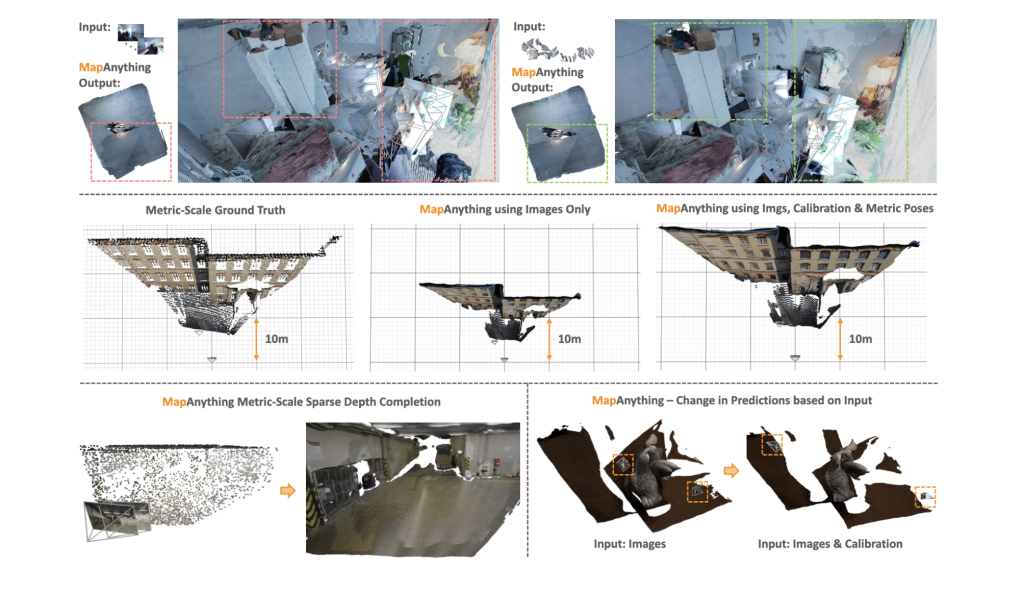
Auf ETH3D, Scannet ++ V2 und Tartanairv2-wb, Mapanything erreicht Stand der Technik (SOTA) Leistung über Punktmaps, Tiefe, Pose und Strahlenschätzung. Es übertrifft Baselines wie VGGT und POW3R, selbst wenn es nur auf Bilder beschränkt ist, und verbessert sich weiter mit Kalibrierung oder Pose Priors.
Zum Beispiel:
- Pointmap -relativer Fehler (rel) verbessert sich mit nur Bildern auf 0,16, verglichen mit 0,20 für VGGT.
- Mit Bildern + Intrinsics + Posen + Tiefe fällt der Fehler auf 0,01während er> 90% Inlierverhältnisse erzielt.
Zwei-View-Rekonstruktion
Gegen Dust3r, MAST3R und POW3R übertrifft Mapanything konsequent über Skalen-, Tiefen- und Posegenauigkeit. Bemerkenswerterweise erreicht es mit zusätzlichen Priors > 92% Inlierverhältnisse Bei Zwei-View-Aufgaben, die deutlich über frühere Feed-Ahead-Modelle hinausgehen.
Einzelansichtskalibrierung
Obwohl Mapanything nicht speziell für die Kalibrierung von Einzel im Bild ausgebildet wurde, erreicht er eine durchschnittlicher Winkelfehler von 1,18 °übertreffen Anycalib (2,01 °) und MOGE-2 (1,95 °).
Tiefenschätzung
Auf dem robusten MVD-Benchmark:
- Mapanything setzt neue SOTA für Multi-View-Metriktiefe Schätzung.
- Mit Hilfseingängen konkurrieren die Fehlerraten mit den Modellen der speziellen Tiefen wie MVSA und Metric3D V2.
Insgesamt bestätigen Benchmarks 2 × Verbesserung gegenüber früheren SOTA -Methoden In vielen Aufgaben validieren Sie die Vorteile eines einheitlichen Trainings.
Schlüsselbeiträge
Das Forschungsteam hebt vier Hauptbeiträge hervor:
- Einheitliches Vorwärtsmodell In der Lage, mehr als 12 Problemeinstellungen zu bearbeiten, von monokularer Tiefe bis hin zu SFM und Stereo.
- Faktorisierte Szenenrepräsentation Ermöglichen der explizite Trennung von Strahlen, Tiefe, Pose und metrischen Skala.
- Hochmoderne Leistung über verschiedene Benchmarks mit weniger Entlassungen und höherer Skalierbarkeit.
- Open-Supply-Veröffentlichung einschließlich Datenverarbeitung, Trainingsskripte, Benchmarks und vorbereiteten Gewichten unter Apache 2.0.
Abschluss
Mapanything legt einen neuen Benchmark in 3D -Sehvermögen fest, indem mehrere Rekonstruktionsaufgaben – SFM, Stereo, Tiefenschätzung und Kalibrierung – unter einem einzelnen Transformatormodell mit einer faktorisierten Szenenrepräsentation vereint sind. Es übertrifft nicht nur Spezialmethoden über Benchmarks hinweg, sondern passt sich auch nahtlos an heterogene Eingaben an, einschließlich Intrinsik, Posen und Tiefe. Mit Open-Supply-Code, vorgefertigten Modellen und Unterstützung für über 12 Aufgaben legt Mapanything die Grundlage für ein wirklich allgemeines 3D-Rekonstruktion zurück.
Schauen Sie sich das an PapierAnwesend Codes Und Projektseite. Fühlen Sie sich frei, unsere zu überprüfen Github -Seite für Tutorials, Codes und Notizbücher. Fühlen Sie sich auch frei, uns zu folgen Twitter Und vergessen Sie nicht, sich unserer anzuschließen 100k+ ml Subreddit und abonnieren Unser Publication.

Michal Sutter ist ein Datenwissenschaftler bei einem Grasp of Science in Knowledge Science von der College of Padova. Mit einer soliden Grundlage für statistische Analyse, maschinelles Lernen und Datentechnik setzt Michal aus, um komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.