
Während die Tech-Leute von den neuesten Llama-Kontrollpunkten besessen sind, wird in den Kellern der Rechenzentren ein viel erbitterterer Kampf ausgetragen. Da KI-Modelle auf Billionen von Parametern skaliert werden, sind die für ihr Coaching erforderlichen Cluster zu einigen der komplexesten – und fragilsten – Maschinen auf dem Planeten geworden.
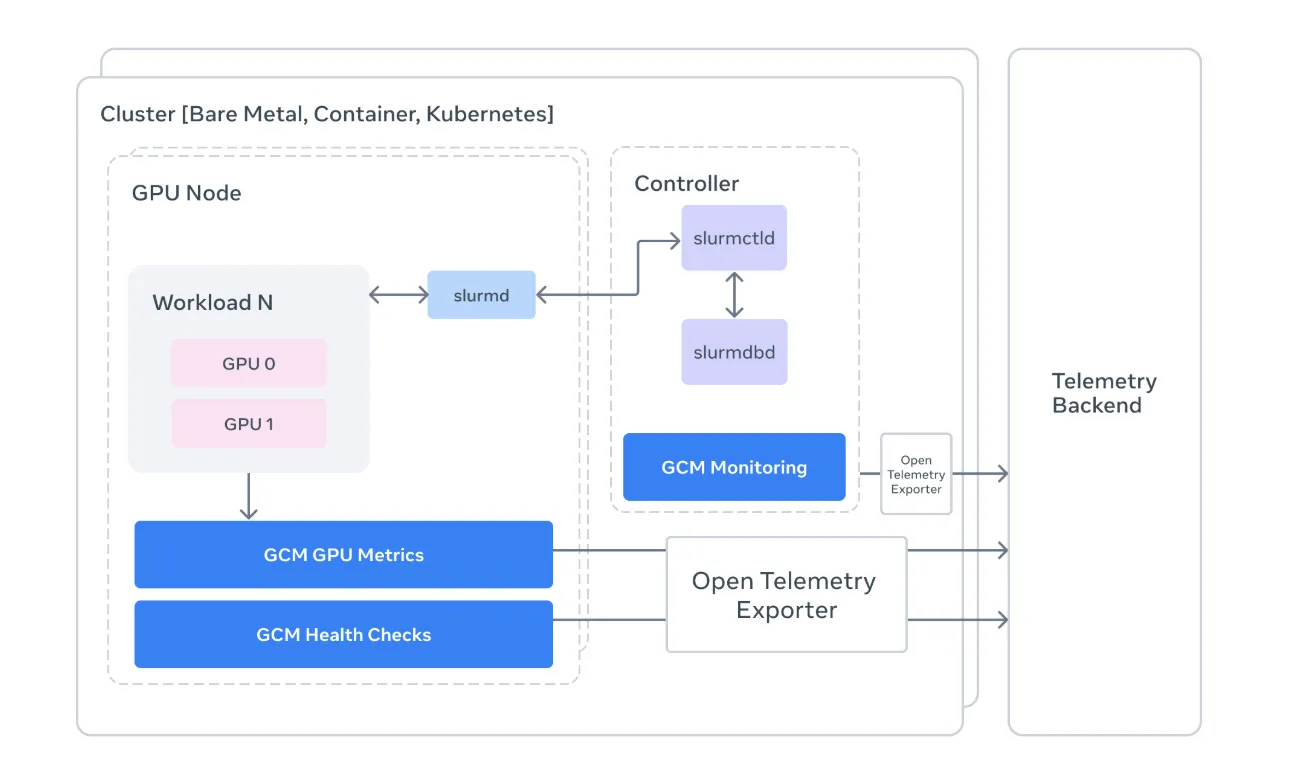
Das Meta AI Analysis-Staff wurde gerade veröffentlicht GCM (GPU-Cluster-Überwachung)ein spezielles Toolkit, das entwickelt wurde, um den „stillen Killer“ des KI-Fortschritts zu lösen: {Hardware}-Instabilität im großen Maßstab. GCM ist eine Blaupause für die Verwaltung des {Hardware}-zu-Software program-Handshakes im Excessive-Efficiency Computing (HPC).
Das Drawback: Wenn die „Commonplace“-Beobachtbarkeit nicht ausreicht
Wenn bei der herkömmlichen Webentwicklung ein Microservice hinterherhinkt, überprüfen Sie Ihr Dashboard und skalieren horizontal. Beim KI-Coaching gelten andere Regeln. Bei einer einzelnen GPU in einem 4.096-Karten-Cluster kann es zu einem „stillen Ausfall“ kommen, bei dem sie technisch gesehen „in Betrieb“ bleibt, aber ihre Leistung abnimmt, wodurch die Gradienten für den gesamten Trainingslauf effektiv vergiftet werden.
Commonplace-Überwachungstools sind oft zu anspruchsvoll, um diese Nuancen zu erfassen. Metas GCM fungiert als spezialisierte Brücke und verbindet die rohe {Hardware}-Telemetrie der NVIDIA-GPUs mit der Orchestrierungslogik des Clusters.
1. Überwachung nach dem „Slurm“-Prinzip
Für Entwickler: Slurm ist der allgegenwärtige (wenn auch gelegentlich frustrierende) Workload-Supervisor. GCM lässt sich direkt in Slurm integrieren, um eine kontextbezogene Überwachung zu ermöglichen.
- Zuordnung auf Jobebene: Anstatt einen generischen Anstieg des Stromverbrauchs zu beobachten, ermöglicht Ihnen GCM die Zuordnung von Kennzahlen zu bestimmten Messwerten Job-IDs.
- Statusverfolgung: Es ruft Daten ab
sacct,sinfoUndsqueueum eine Echtzeitkarte des Clusterzustands zu erstellen. Wenn ein Knoten als markiert istDRAINGCM hilft Ihnen zu verstehen Warum bevor es einem Forscher das Wochenende ruiniert.
2. Die „Prolog“- und „Epilog“-Strategie
Einer der technisch wichtigsten Teile des GCM-Frameworks ist seine Suite Gesundheitschecks. In einer HPC-Umgebung ist Timing alles. GCM nutzt zwei kritische Fenster:
- Prolog: Dabei handelt es sich um ausgeführte Skripte vor ein Job beginnt. GCM prüft, ob das InfiniBand-Netzwerk fehlerfrei ist und ob die GPUs tatsächlich erreichbar sind. Wenn ein Knoten eine Vorabprüfung nicht besteht, wird der Job umgeleitet, wodurch Stunden „toter“ Rechenzeit eingespart werden.
- Epilog: Diese laufen nach ein Job wird abgeschlossen. GCM verwendet dieses Fenster, um eine umfassende Diagnose durchzuführen NVIDIAs DCGM (Information Heart GPU Supervisor) um sicherzustellen, dass die {Hardware} beim schweren Heben nicht beschädigt wurde.
3. Telemetrie und die OTLP-Brücke
Für Entwickler und KI-Forscher, die ihre Rechenbudgets rechtfertigen müssen, GCMs Telemetrieprozessor ist der Star der Present. Es wandelt rohe Clusterdaten in um OpenTelemetry (OTLP) Formate.
Durch die Standardisierung der Telemetrie ermöglicht GCM Groups, hardwarespezifische Daten (wie GPU-Temperatur, NVLink-Fehler und XID-Ereignisse) in moderne Observability-Stacks zu übertragen. Dies bedeutet, dass Sie endlich einen Rückgang des Trainingsdurchsatzes mit einem bestimmten {Hardware}-Drosselungsereignis in Verbindung bringen können, indem Sie von „Das Modell ist langsam“ zu „GPU 3 auf Knoten 50 ist überhitzt“ übergehen.
Unter der Haube: Der Tech Stack
Die Implementierung von Meta ist eine Meisterklasse in pragmatischer Technik. Das Repository ist in erster Linie Python (94 %), wodurch es für KI-Entwickler hochgradig erweiterbar ist und leistungskritische Logik berücksichtigt Gehen.
- Sammler: Modulare Komponenten, die Telemetriedaten aus Quellen wie sammeln
nvidia-smiund die Slurm-API. - Waschbecken: Die „Ausgabe“-Ebene. GCM unterstützt mehrere Senken, einschließlich
stdoutfür lokales Debugging und OTLP zur produktionsnahen Überwachung. - DCGM und NVML: GCM nutzt die NVIDIA-Verwaltungsbibliothek (NVML) um direkt mit der {Hardware} zu kommunizieren und Abstraktionen auf hoher Ebene zu umgehen, die möglicherweise Fehler verbergen.
Wichtige Erkenntnisse
- Überbrückung der Lücke des „stillen Versagens“: GCM löst ein kritisches Drawback der KI-Infrastruktur: die Identifizierung von „Zombie“-GPUs, die on-line erscheinen, aber aufgrund von {Hardware}-Instabilität zum Absturz von Trainingsläufen oder zu fehlerhaften Farbverläufen führen.
- Deep Slurm-Integration: Im Gegensatz zur allgemeinen Cloud-Überwachung ist GCM speziell für Excessive-Efficiency Computing (HPC) entwickelt. Es verankert Hardwaremetriken spezifisch Slurm-Job-IDsDadurch können Ingenieure Leistungseinbrüche oder Leistungsspitzen bestimmten Modellen und Benutzern zuordnen.
- Automatisierte Gesundheit „Prolog“ und „Epilog“: Das Framework verwendet eine proaktive Diagnosestrategie und führt spezielle Gesundheitsprüfungen durch NVIDIA DCGM vor Beginn eines Jobs (Prolog) und nach dessen Ende (Epilog), um sicherzustellen, dass fehlerhafte Knoten entleert werden, bevor sie teure Rechenzeit verschwenden.
- Standardisierte Telemetrie über OTLP: GCM wandelt Low-Degree-Hardwaredaten (Temperatur, NVLink-Fehler, XID-Ereignisse) in die um OpenTelemetry (OTLP) Format. Dadurch können Groups komplexe Clusterdaten zur Echtzeitvisualisierung an moderne Observability-Stacks wie Prometheus oder Grafana weiterleiten.
- Modulares, sprachunabhängiges Design: Während die Kernlogik eingeschrieben ist Python Für die Barrierefreiheit verwendet GCM Gehen für leistungskritische Abschnitte. Seine „Collector-and-Sink“-Architektur ermöglicht es Entwicklern, problemlos neue Datenquellen einzubinden oder Metriken in benutzerdefinierte Backend-Systeme zu exportieren.
Schauen Sie sich das an Repo Und Projektseite. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 120.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
