Mistral AI hat Mistral OCR 3 veröffentlicht, seinen neuesten optischen Zeichenerkennungsdienst, der den Doc AI-Stack des Unternehmens unterstützt. Das Modell mit dem Namen mistral-ocr-2512ist darauf ausgelegt, verschachtelte Texte und Bilder aus PDFs und anderen Dokumenten zu extrahieren und dabei die Struktur beizubehalten. Dies geschieht zu einem günstigen Preis von 2 US-Greenback professional 1.000 Seiten mit einem Rabatt von 50 % bei Verwendung über die Batch-API.
Wofür ist Mistral OCR 3 optimiert?
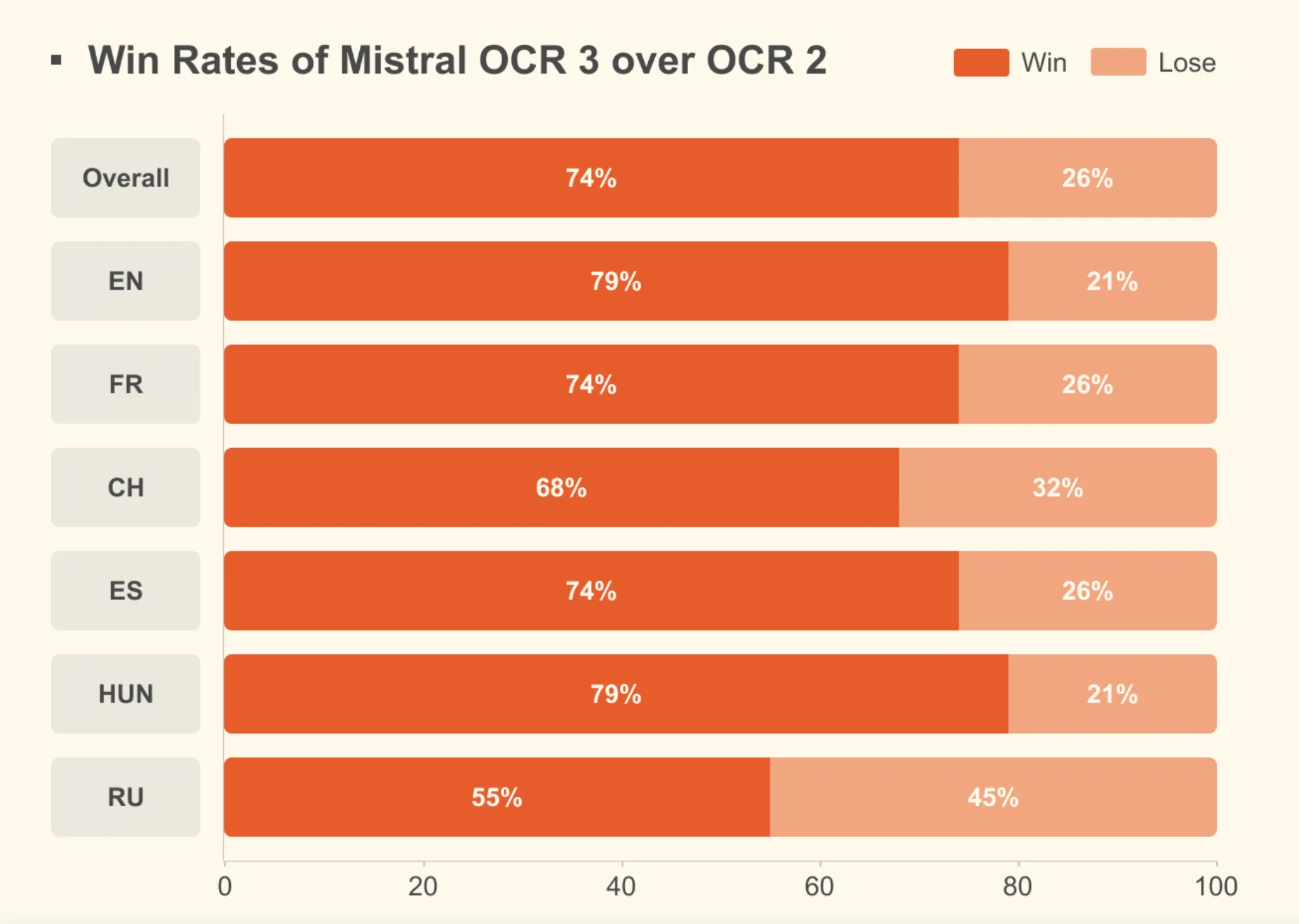
Mistral OCR 3 ist auf typische Dokumenten-Workloads in Unternehmen ausgerichtet. Das Modell ist auf Formulare, gescannte Dokumente, komplexe Tabellen und Handschrift abgestimmt. Es wird anhand interner Benchmarks bewertet, die aus realen Geschäftsanwendungsfällen stammen, wobei es in diesen Dokumentkategorien eine Gesamtsiegerquote von 74 % gegenüber Mistral OCR 2 erreicht, wobei eine Fuzzy-Match-Metrik im Vergleich zur Floor Reality verwendet wird.
Das Modell gibt einen Markdown aus, der das Dokumentlayout beibehält, und wenn die Tabellenformatierung aktiviert ist, reichert es die Ausgabe mit HTML-basierten Tabellendarstellungen an. Durch diese Kombination erhalten nachgeschaltete Systeme sowohl den Inhalt als auch die Strukturinformationen, die für Abrufpipelines, Analysen und Agenten-Workflows erforderlich sind.
Rolle in Mistral Doc AI
OCR 3 ist in Mistral Doc AI integriert, der Dokumentenverarbeitungsfunktion des Unternehmens, die OCR mit strukturierter Datenextraktion und Dokumenten-QnA kombiniert.
Es unterstützt jetzt den Doc AI Playground in Mistral AI Studio. Über diese Schnittstelle laden Benutzer PDFs oder Bilder hoch und erhalten entweder sauberen Textual content oder strukturiertes JSON zurück, ohne Code schreiben zu müssen. Auf die gleiche zugrunde liegende OCR-Pipeline kann über die öffentliche API zugegriffen werden, sodass Groups von der interaktiven Erkundung zu Produktions-Workloads wechseln können, ohne das Kernmodell zu ändern.
Eingaben, Ausgaben und Struktur
Der OCR-Prozessor akzeptiert mehrere Dokumentformate über eine einzige API. Der doc Feld kann zeigen auf:
document_urlfür PDFs, pptx, docx und mehrimage_urlfür Bildtypen wie PNG, JPEG oder AviF- Hochgeladene oder Base64-kodierte PDFs oder Bilder über dasselbe Schema
Dies ist im Abschnitt „OCR-Prozessor“ der Doc AI-Dokumente von Mistral dokumentiert.
Die Antwort ist ein JSON-Objekt mit einem pages Array. Jede Seite enthält einen Index, eine Markdown-Zeichenfolge, eine Liste von Bildern und eine Liste von Tabellen table_format="html" wird verwendet, erkannte Hyperlinks, non-compulsory header Und footer Felder, wenn die Kopf- oder Fußzeilenextraktion aktiviert ist, und a dimensions Objekt mit Seitengröße. Es gibt auch eine document_annotation Feld für strukturierte Anmerkungen und a usage_info Block für Buchhaltungsinformationen.
Wenn Bilder und HTML-Tabellen extrahiert werden, enthält der Markdown Platzhalter wie !(img-0.jpeg)(img-0.jpeg) Und (tbl-3.html)(tbl-3.html). Diese Platzhalter werden mithilfe von dem tatsächlichen Inhalt zugeordnet photographs Und tables Arrays in der Antwort, was die nachgelagerte Rekonstruktion vereinfacht.
Upgrades gegenüber Mistral OCR 2
Mistral OCR 3 führt im Vergleich zu OCR 2 mehrere konkrete Verbesserungen ein. In den öffentlichen Versionshinweisen werden vier Hauptbereiche hervorgehoben.
- Handschrift Mistral OCR 3 interpretiert kursive, gemischte Inhaltsanmerkungen und handgeschriebenen Textual content, der über gedruckten Vorlagen platziert wird, genauer.
- Formulare Es verbessert die Erkennung von Kartons, Etiketten und handschriftlichen Einträgen in dichten Layouts wie Rechnungen, Quittungen, Compliance-Formularen und Regierungsdokumenten.
- Gescannte und komplexe Dokumente Das Modell ist robuster gegenüber Komprimierungsartefakten, Schräglauf, Verzerrung, niedrigem DPI-Wert und Hintergrundrauschen auf gescannten Seiten.
- Komplexe Tabellen Es rekonstruiert Tabellenstrukturen mit Kopfzeilen, zusammengeführten Zellen, mehrzeiligen Blöcken und Spaltenhierarchien und kann HTML-Tabellen mit den richtigen zurückgeben
colspanUndrowspanTags hinzufügen, damit das Structure erhalten bleibt.

Preise, Batch-Inferenz und Anmerkungen
Die OCR 3-Modellkarte gibt einen Preis von 2 $ professional 1.000 Seiten für Normal-OCR und 3 $ professional 1.000 mit Anmerkungen versehenen Seiten an, wenn strukturierte Anmerkungen verwendet werden.
Mistral stellt OCR 3 auch über seine Batch-Inferenz-API zur Verfügung /v1/batchwas im Batch-Bereich der Plattform dokumentiert ist. Die Stapelverarbeitung halbiert den effektiven OCR-Preis auf 1 US-Greenback professional 1.000 Seiten, indem ein Rabatt von 50 % für Aufträge gewährt wird, die die Batch-Pipeline durchlaufen.
Das Modell lässt sich mit zwei wichtigen Funktionen auf demselben Endpunkt integrieren: Annotations – Structured und BBox Extraction. Diese ermöglichen es Entwicklern, schemagesteuerte Beschriftungen an Bereiche eines Dokuments anzuhängen und Begrenzungsrahmen für Textual content und andere Elemente zu erhalten, was nützlich ist, wenn Inhalte in nachgelagerte Systeme oder UI-Overlays zugeordnet werden.
Wichtige Erkenntnisse
- Vorbild und Rolle: Mistral OCR 3, benannt als
mistral-ocr-2512ist der neue OCR-Dienst, der den Doc AI-Stack von Mistral für das seitenbasierte Dokumentverständnis unterstützt. - Genauigkeitsgewinne: Bei internen Benchmarks, die Formulare, gescannte Dokumente, komplexe Tabellen und Handschrift abdecken, erreicht OCR 3 eine Gesamtsiegerquote von 74 % gegenüber Mistral OCR 2 und Mistral positioniert es als State of the Artwork sowohl im Vergleich zu herkömmlichen als auch KI-nativen OCR-Systemen.
- Strukturierte Ausgaben für RAG: Der Dienst extrahiert verschachtelten Textual content und eingebettete Bilder und gibt den mit HTML rekonstruierten Tabellen angereicherten Markdown zurück, wobei Structure und Tabellenstruktur erhalten bleiben, sodass die Ausgaben mit minimalem zusätzlichem Parsing direkt in RAG, Agenten und Suchpipelines eingespeist werden können.
- API- und Dokumentformate: Entwickler greifen über das auf OCR 3 zu
/v1/ocrEndpunkt oder SDK, Übergeben von PDFs alsdocument_urlund Bilder wie PNG oder JPEG alsimage_urlund kann Optionen wie HTML-Tabellenausgabe, Kopf- oder Fußzeilenextraktion und Base64-Bilder in der Antwort aktivieren. - Preisgestaltung und Batch-Verarbeitung: OCR 3 kostet 2 Greenback professional 1.000 Seiten und 3 Greenback professional 1.000 kommentierte Seiten. Bei Verwendung über die Batch-API sinkt der effektive Preis für Normal-OCR auf 1 Greenback professional 1.000 Seiten für die Verarbeitung in großem Maßstab.
Schauen Sie sich das an TECHNISCHE DETAILS. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser E-newsletter.
Der Beitrag Mistral AI veröffentlicht OCR 3: ein kleineres OCR-Modell (Optical Character Recognition) für strukturierte Dokumenten-KI im großen Maßstab erschien zuerst auf MarkTechPost.