Die Ausreißer der Branche haben unsere Definition von Empfehlungssystemen verzerrt. TikTok, Spotify und Netflix Nutzen Sie hybride Deep-Studying-Modelle, die kollaborative und inhaltsbasierte Filterung kombinieren, um personalisierte Empfehlungen zu liefern, von denen Sie nicht einmal wussten, dass Sie sie möchten. Wenn Sie über eine Stelle bei RecSys nachdenken, sollten Sie sich sofort damit befassen. Aber nicht alle RecSys-Probleme funktionieren auf dieser Ebene – oder müssen funktionieren. Die meisten Praktiker arbeiten mit relativ einfachen, tabellarischen Modellen, oft mit Gradienten-verstärkten Bäumen. Bis ich an der RecSys ’25 in Prag teilnahm, dachte ich, meine Erfahrung sei ein Ausreißer. Nun glaube ich, dass dies die Norm ist, die sich hinter den großen Ausreißern verbirgt, die den Stand der Technik der Branche bestimmen. Was unterscheidet diese Giganten von den meisten anderen Unternehmen? In diesem Artikel verwende ich das im Bild oben abgebildete Framework, um über diese Unterschiede nachzudenken und Ihnen dabei zu helfen, Ihre eigene Empfehlungsarbeit in das Spektrum einzuordnen.
Die meisten Empfehlungssysteme beginnen mit a Kandidatengeneration Part, wodurch Millionen möglicher Elemente auf eine überschaubare Menge reduziert werden, die durch Lösungen mit höherer Latenz eingestuft werden kann. Aber Kandidatengeneration ist nicht immer der harte Kampf, als den es dargestellt wirdEs ist auch nicht unbedingt maschinelles Lernen erforderlich. Kontexte mit klar definierten Bereichen und harten Filtern erfordern häufig keine komplexe Abfragelogik oder Vektorsuche. In Betracht ziehen Reserving.com: Wenn ein Benutzer nach „4-Sterne-Accommodations in Barcelona vom 1. bis 4. Oktober“ sucht, haben die geografischen und Verfügbarkeitsbeschränkungen bereits Millionen von Unterkünften auf einige Hundert eingegrenzt. Die eigentliche Herausforderung für Praktiker des maschinellen Lernens besteht dann darin, diese Accommodations präzise zu bewerten. Das ist ein großer Unterschied Die Produktsuche von Amazon oder die YouTube-Homepagewo harte Filter fehlen. In diesen Umgebungen ist skalierbares maschinelles Lernen erforderlich, um einen riesigen Katalog auf eine kleinere, semantik- und absichtsempfindliche Kandidatenmenge zu reduzieren – und das alles, bevor überhaupt ein Rating stattfindet.
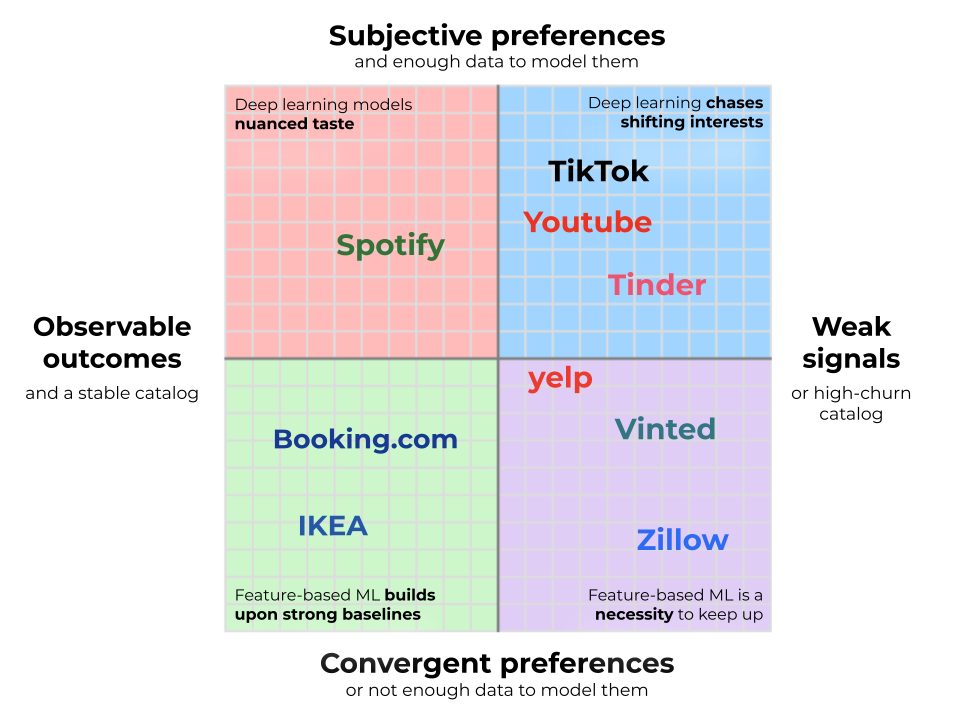
Über die Kandidatengenerierung hinaus ist die Komplexität von Rang lässt sich am besten anhand der beiden im Bild unten abgebildeten Dimensionen verstehen. Erste, beobachtbare Ergebnisse und Katalogstabilitätdie bestimmen, wie stark Ihre Grundlinie sein kann. Zweitens, die Subjektivität der Präferenzen und deren Erlernbarkeit, die bestimmen, wie komplex Ihre Personalisierungslösung sein muss.

Beobachtbare Ergebnisse und Katalogstabilität
Am linken Ende der X-Achse befinden sich Unternehmen, die ihre wichtigsten Ergebnisse direkt beobachten. Große Händler mögen IKEA sind ein gutes Beispiel dafür: Wenn ein Kunde ein ESKILSTUNA-Couch anstelle eines KIVIK-Sofas kauft, ist das Sign eindeutig. Fassen Sie genügend davon zusammen, und das Unternehmen weiß genau, welches Produkt die höhere Kaufrate hat. Wenn Sie direkt beobachten können, wie Benutzer mit ihren Geldbörsen abstimmen, verfügen Sie über eine starke Foundation, die kaum zu übertreffen ist.
Das andere Extrem sind Plattformen, die nicht beobachten können, ob ihre Empfehlungen tatsächlich erfolgreich waren. Zunder Und Hummel Sie sehen möglicherweise, dass Benutzer übereinstimmen, wissen aber oft nicht, ob sich das Paar intestine versteht (insbesondere, wenn Benutzer zu anderen Plattformen wechseln). Jaulen können Eating places empfehlen, aber in den allermeisten Fällen können sie nicht beobachten, ob Sie sie tatsächlich besucht haben, sondern nur, welche Einträge Sie angeklickt haben. Sich auf solche Signale des oberen Trichters zu verlassen, bedeutet Positionsvoreingenommenheit dominiert: Elemente in Spitzenpositionen häufen Interaktionen unabhängig von ihrer tatsächlichen Qualität an, sodass es nahezu unmöglich ist zu sagen, ob Engagement echte Präferenz oder bloße Sichtbarkeit widerspiegelt. Vergleichen Sie dies mit dem IKEA-Beispiel: Ein Benutzer klickt möglicherweise auf ein Restaurant auf Yelp, nur weil es zuerst angezeigt wird, aber die Wahrscheinlichkeit, dass er aus demselben Grund ein Couch kauft, ist weitaus geringer. Ohne eine harte Konvertierung verlieren Sie den Anker einer zuverlässigen Bestenliste. Dies zwingt Sie dazu, viel härter zu arbeiten, um das Sign aus dem Rauschen zu extrahieren. Rezensionen können eine gewisse Bodenständigkeit bieten, aber sie sind selten dicht genug, um als primäres Sign zu dienen. Stattdessen bleibt es Ihnen überlassen Führen Sie endlose Experimente mit Ihren Rating-Heuristiken durch und optimieren Sie ständig die Logik, um aus einem Strom schwacher Signale einen Proxy für Qualität herauszuholen.
Katalog mit hoher Abwanderung
Selbst bei beobachtbaren Ergebnissen ist eine solide Ausgangslage jedoch nicht garantiert. Wenn sich Ihr Katalog ständig ändert, sammeln Sie möglicherweise nicht genügend Daten, um eine ordnungsgemäße Bestenliste zu erstellen. Immobilienplattformen wie Zillow und Second-Hand-Websites wie Vinted Stellen Sie sich die extremste Model vor: Jeder Artikel hat einen Bestand von einem und verschwindet, sobald er gekauft wird. Dies zwingt Sie dazu, sich auf einfache und starre Sortierungen wie „Neueste zuerst“ oder „Niedrigster Preis professional Quadratmeter“ zu verlassen. Diese sind weitaus schwächer als Conversion-Bestenlisten, die auf echten, dichten Benutzersignalen basieren. Um es besser zu machen, müssen Sie maschinelles Lernen nutzen, um die Conversion-Wahrscheinlichkeit sofort vorherzusagen, indem Sie intrinsische Attribute mit einer verzerrten kurzfristigen Leistung kombinieren, um das beste Inventar zu finden, bevor es verschwindet.
Die Allgegenwärtigkeit merkmalsbasierter Modelle
Unabhängig von der Stabilität oder Signalstärke Ihres Katalogs bleibt die Kernherausforderung dieselbe: Sie versuchen, die verfügbare Basislinie zu verbessern. Dies wird typischerweise durch das Coaching eines Modells für maschinelles Lernen (ML) erreicht, um die Wahrscheinlichkeit eines Engagements oder einer Konversion in einem bestimmten Kontext vorherzusagen. Gradient-Boosted Bushes (GBDTs) sind die pragmatische Wahl und lassen sich viel schneller trainieren und optimieren als Deep Studying.
GBDTs prognostizieren diese Ergebnisse auf der Grundlage von Merkmalen technischer Artikel: kategoriale und numerische Attribute, die ein Produkt quantifizieren und beschreiben. Noch bevor individuelle Präferenzen bekannt sind, können GBDTs Empfehlungen anpassen und dabei grundlegende Benutzerfunktionen wie Land und Gerätetyp nutzen. Allein mit diesen Artikel- und Benutzerfunktionen kann ein ML-Modell die Basislinie bereits verbessern – sei es durch die Entzerrung einer Beliebtheitsrangliste oder durch die Einstufung eines Feeds mit hoher Abwanderung. Beispielsweise nutzen Fashions im Mode-E-Commerce häufig Ort und Jahreszeit, um Artikel anzuzeigen, die an die Saison gebunden sind, während sie gleichzeitig Land und Gerät verwenden, um den Preispunkt zu kalibrieren.
Diese Eigenschaften ermöglichen es dem Modell, die oben genannten Probleme zu bekämpfen Positionsvoreingenommenheit indem wir wahre Qualität von bloßer Sichtbarkeit trennen. Indem das Modell lernt, welche intrinsischen Attribute die Konvertierung fördern, kann es die Positionsverzerrung korrigieren, die Ihrer Beliebtheitsbasislinie innewohnt. Es lernt, Elemente zu identifizieren, die aufgrund ihrer Leistung funktionieren, und nicht nur, weil sie an der Spitze platziert wurden. Das ist schwieriger, als es aussieht: Sie riskieren, bewährte Gewinner stärker herabzustufen, als Sie sollten, was möglicherweise zu einer Verschlechterung des Erlebnisses führt.
Entgegen der landläufigen Meinung können funktionsbasierte Modelle auch die Personalisierung vorantreiben. Elemente können aus zwei Quellen in Einbettungen kodiert werden: semantischer Inhalt (Beschreibungen, Fotos und Rezensionen auf Plattformen wie Reserving.com Und Jaulen) oder Interaktionsdaten (Methoden wie StarSpace, die daraus lernen, welche Elemente angeklickt oder zusammen angezeigt werden). Indem wir die jüngsten Interaktionen eines Benutzers nutzen, können wir Ähnlichkeitswerte für Kandidatenelemente berechnen und diese als Options in das Gradienten-verstärkte Modell einspeisen.
Dieser Ansatz hat jedoch seine Grenzen. Ein GBDT könnte lernen, Eating places zu bewerben, die den letzten italienischen Suchanfragen eines Benutzers ähneln Jaulenaber die Ähnlichkeit selbst ergibt sich aus semantischen Inhalten oder aus den Eating places, die häufig zusammengeklickt werden, und nicht aus denen, die Benutzer tatsächlich buchen. Deep-Studying-Modelle lernen Elementdarstellungen durchgängig: Die Einbettungen werden optimiert, um die Leistung bei der endgültigen Aufgabe zu maximieren. Ob diese Einschränkung von Bedeutung ist, hängt von etwas Grundlegenderem ab: wie sehr die Benutzer tatsächlich anderer Meinung sind.
Subjektivität
Nicht alle Bereiche sind gleichermaßen persönlich oder kontrovers. In einigen Fällen sind sich die Benutzer weitgehend darüber einig, was ein gutes Produkt ausmacht, wenn grundlegende Einschränkungen erfüllt sind. Wir nennen diese konvergenten Präferenzen und sie nehmen die untere Hälfte des Diagramms ein. Nehmen Reserving.com: Reisende haben möglicherweise unterschiedliche Budgets und Standortpräferenzen, aber sobald diese durch Filter und Karteninteraktionen aufgedeckt werden, stimmen die Rating-Kriterien überein – höhere Preise sind schlecht, Annehmlichkeiten sind intestine, gute Bewertungen sind besser. Oder überlegen Sie Heftklammern: Sobald ein Benutzer Druckerpapier oder AA-Batterien benötigt, dominieren Marke und Preis, wodurch die Benutzerpräferenzen bemerkenswert konsistent sind.
Das andere Extrem – die obere Hälfte – sind subjektive Bereiche, die durch einen stark fragmentierten Geschmack definiert sind. Spotify veranschaulicht dies: Der Lieblingstitel eines Benutzers wird von einem anderen sofort übersprungen. Dennoch existiert Geschmack selten im luftleeren Raum. Irgendwo in den Daten befindet sich ein Benutzer genau auf Ihrer Wellenlänge, und maschinelles Lernen schließt diese Lücke. Wandeln Sie ihre Entdeckungen von gestern in Ihre Empfehlungen für heute um. Hier ist der Wert der Personalisierung enorm und damit auch der erforderliche technische Aufwand.
Die richtigen Daten
Der subjektive Geschmack ist nur dann umsetzbar, wenn Sie über genügend Daten verfügen, um ihn zu beobachten. In vielen Bereichen gibt es unterschiedliche Präferenzen, es fehlt jedoch die Rückkopplungsschleife, um diese zu erfassen. Eine Nischen-Content material-Plattform, ein neuer Marktplatz oder ein B2B-Produkt kann auf völlig unterschiedliche Geschmäcker stoßen, aber es fehlt ihnen das klare Sign, sie zu erlernen. Jaulen Restaurantempfehlungen veranschaulichen diese Herausforderung: Essenspräferenzen sind subjektiv, aber die Plattform kann keine tatsächlichen Restaurantbesuche beobachten, sondern nur Klicks. Das bedeutet, dass sie die Personalisierung nicht für das wahre Ziel (Conversions) optimieren können. Sie können nur für Proxy-Metriken wie Klicks optimiert werden, aber mehr Klicks können tatsächlich auf einen Fehler hinweisen, was darauf hindeutet, dass Benutzer mehrere Einträge durchsuchen, ohne das Gesuchte zu finden.
Aber in subjektiven Bereichen mit umfangreichen Verhaltensdaten bleibt Geld auf dem Tisch, wenn die Personalisierung versäumt wird. YouTube veranschaulicht dies: Mit Milliarden von täglichen Interaktionen lernt die Plattform differenzierte Zuschauerpräferenzen und zeigt Movies an, von denen Sie nicht wussten, dass Sie sie wollen. Hier wird Deep Studying unumgänglich. An diesem Punkt koordinieren sich große Groups über Jira- und Cloud-Rechnungen, die die Genehmigung des VP erfordern. Ob diese Komplexität gerechtfertigt ist, hängt ausschließlich von den Daten ab, über die Sie verfügen.
Wissen Sie, wo Sie stehen
Zu verstehen, wo Ihr Drawback in diesem Spektrum liegt, ist weitaus wertvoller, als blind der neuesten Architektur nachzujagen. Der „Stand der Technik“ der Branche wird weitgehend von den Ausreißern bestimmt – den Technologiegiganten, die sich mit riesigen, subjektiven Beständen und dichten Benutzerdaten befassen. Ihre Lösungen sind berühmt, weil ihre Probleme extrem sind, nicht weil sie allgemein richtig sind.
Jedoch, Sie werden bei Ihrer eigenen Arbeit wahrscheinlich mit unterschiedlichen Einschränkungen konfrontiert sein. Wenn Ihre Area durch einen stabilen Katalog und beobachtbare Ergebnisse gekennzeichnet ist, landen Sie im unteren linken Quadranten neben Unternehmen wie IKEA Und Reserving.com. Hier sind die Beliebtheitswerte so hoch, dass die Herausforderung einfach darin besteht, darauf mit Modellen für maschinelles Lernen aufzubauen, die zu messbaren A/B-Testerfolgen führen können. Wenn Sie stattdessen mit einer hohen Abwanderung konfrontiert sind (z Vinted) oder schwache Signale (wie Jaulen), wird maschinelles Lernen zu einer Notwendigkeit, um Schritt zu halten.
Das heißt aber nicht, dass Sie es brauchen tiefes Lernen. Diese zusätzliche Komplexität zahlt sich nur in Gebieten wirklich aus, in denen Präferenzen zutiefst subjektiv sind und genügend Daten vorhanden sind, um sie zu modellieren. Wir behandeln Systeme oft wie Netflix oder Spotify als Goldstandard, es handelt sich jedoch um Speziallösungen für seltene Erkrankungen. Für den Relaxation von uns geht es bei Exzellenz nicht darum, die komplexeste verfügbare Architektur einzusetzen; Es geht darum, die Einschränkungen des Geländes zu erkennen und das Selbstvertrauen zu haben, die Lösung zu wählen, die Ihre Probleme löst.
Bilder vom Autor.