
Rekursive Sprachmodelle Ziel ist es, den üblichen Kompromiss zwischen Kontextlänge, Genauigkeit und Kosten in großen Sprachmodellen zu durchbrechen. Anstatt ein Modell zu zwingen, eine riesige Eingabeaufforderung in einem Durchgang zu lesen, behandeln RLMs die Eingabeaufforderung als externe Umgebung und lassen das Modell entscheiden, wie es sie mit Code überprüft, und rufen sich dann rekursiv für kleinere Teile auf.
Die Grundlagen
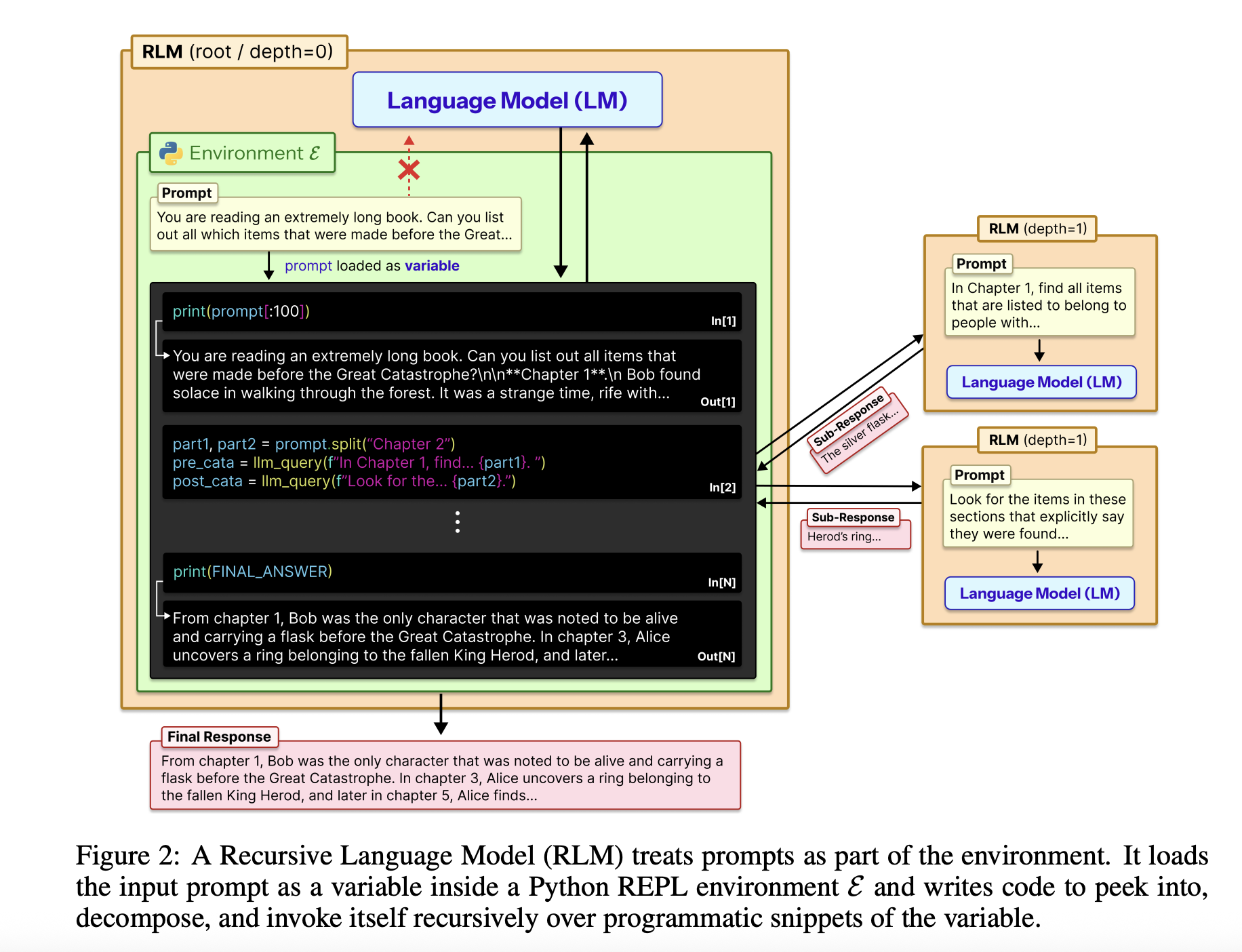
Die vollständige Eingabe wird als einzelne String-Variable in eine Python-REPL geladen. Das Root-Modell, zum Beispiel GPT-5, sieht diese Zeichenfolge nie direkt in ihrem Kontext. Stattdessen erhält es eine Systemaufforderung, die erklärt, wie Slices der Variablen gelesen, Hilfsfunktionen geschrieben, Sub-LLM-Aufrufe erzeugt und Ergebnisse kombiniert werden. Das Modell gibt eine abschließende Textantwort zurück, sodass die externe Schnittstelle mit einem Customary-Chat-Abschlussendpunkt identisch bleibt.
Das RLM-Design verwendet die REPL als Steuerebene für langen Kontext. Die normalerweise in Python geschriebene Umgebung stellt Instruments wie String-Slicing, Regex-Suche und Hilfsfunktionen wie bereit llm_query die eine kleinere Modellinstanz aufrufen, zum Beispiel GPT-5-mini. Das Root-Modell schreibt Code, der diese Helfer aufruft, um die externe Kontextvariable zu scannen, zu partitionieren und zusammenzufassen. Der Code kann Zwischenergebnisse in Variablen speichern und die endgültige Antwort Schritt für Schritt aufbauen. Diese Struktur macht die Eingabeaufforderungsgröße unabhängig vom Modellkontextfenster und macht die Handhabung langer Kontexte zu einem Downside bei der Programmsynthese.
Wo steht es in der Bewertung?
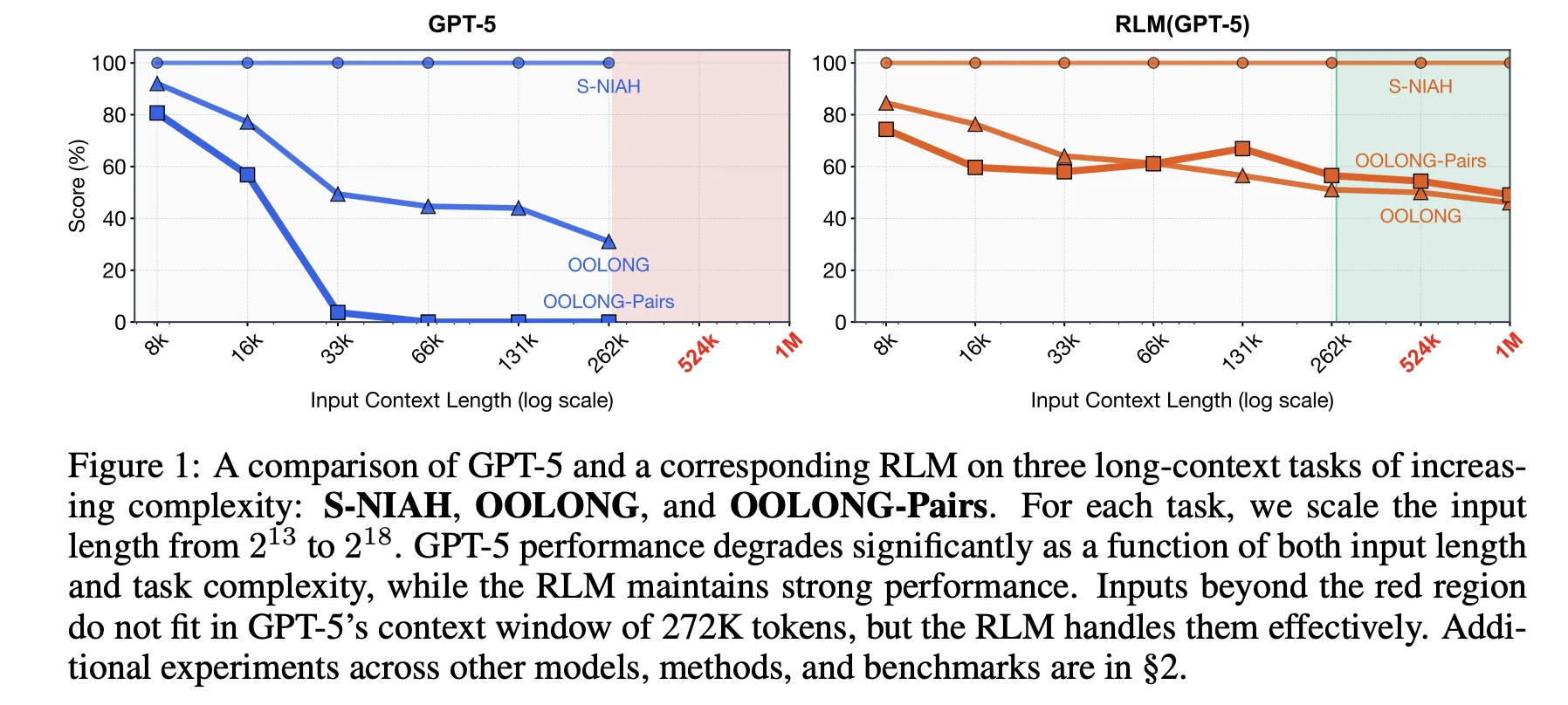
Der Forschungsarbeit bewertet diese Idee anhand von vier langen Kontext-Benchmarks mit unterschiedlicher Rechenstruktur. S-NIAH ist eine Nadel im Heuhaufen mit konstanter Komplexität. BrowseComp-Plus ist ein Multi-Hop-Benchmark für Fragen und Antworten im Internet-Stil für bis zu 1.000 Dokumente. OOLONG ist eine lineare Komplexitätsaufgabe mit langem Kontextschluss, bei der das Modell viele Einträge transformieren und dann aggregieren muss. OOLONG-Paare erhöhen die Schwierigkeit durch quadratische paarweise Aggregation über die Eingabe weiter. Bei diesen Aufgaben wird sowohl die Kontextlänge als auch die Argumentationstiefe betont, nicht nur das Abrufen.
Bei diesen Benchmarks bieten RLMs große Genauigkeitsgewinne gegenüber direkten LLM-Aufrufen und herkömmlichen Agenten mit langem Kontext. Für GPT-5 auf CodeQA, einem Setup für die Beantwortung langer Dokumentfragen, erreicht das Basismodell eine Genauigkeit von 24,00, ein Zusammenfassungsagent erreicht 41,33, während RLM 62,00 und das RLM ohne Rekursion 66,00 erreicht. Für Qwen3-Coder-480B-A35B erreicht das Basismodell 20,00, ein CodeAct-Retrieval-Agent 52,00 und das RLM 56,00 mit einer reinen REPL-Variante bei 44,66.
Die Gewinne sind bei der härtesten Einstellung, den OOLONG-Paaren, am größten. Für GPT-5 ist das direkte Modell mit F1 von 0,04 nahezu unbrauchbar. Zusammenfassungs- und CodeAct-Agenten liegen in der Nähe von 0,01 und 24,67. Der volle RLM erreicht 58,00 F1 und die nicht rekursive REPL-Variante erreicht immer noch 43,93. Für Qwen3-Coder bleibt das Basismodell unter 0,10 F1, während das vollständige RLM 23,11 und die REPL nur Model 17,34 erreicht. Diese Zahlen zeigen, dass sowohl REPL als auch rekursive Unteraufrufe bei dichten quadratischen Aufgaben von entscheidender Bedeutung sind.
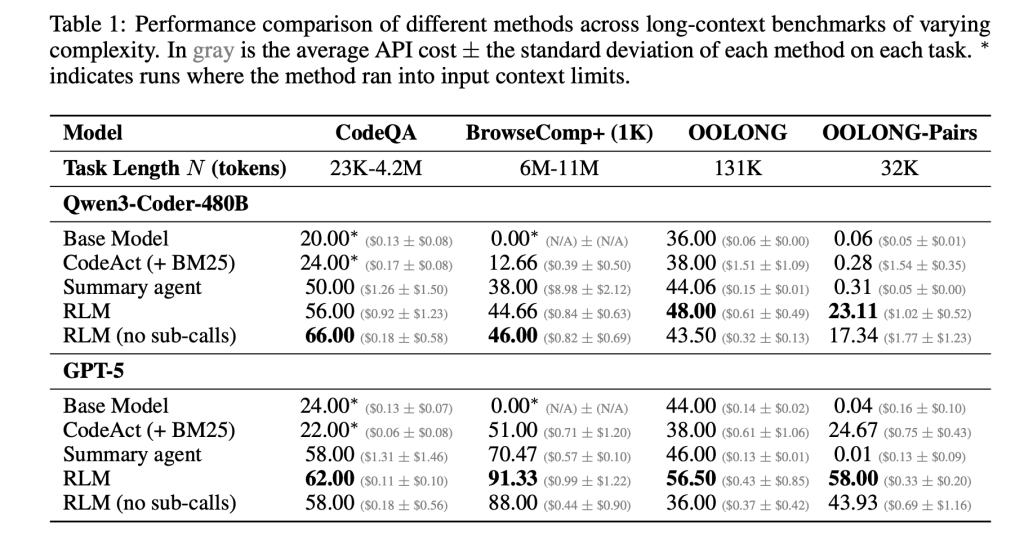
BrowseComp-Plus hebt die effektive Kontexterweiterung hervor. Der Korpus umfasst etwa 6 bis 11 Millionen Token, was zwei Größenordnungen über dem 272.000 Token-Kontextfenster von GPT-5 liegt. RLM mit GPT 5 behält eine starke Leistung bei, selbst wenn 1.000 Dokumente in der Umgebungsvariablen angegeben werden, während die Customary-GPT-5-Baselines mit zunehmender Dokumentanzahl abnehmen. Bei diesem Benchmark erreicht RLM GPT 5 eine Genauigkeit von etwa 91,33 bei durchschnittlichen Kosten von 0,99 USD professional Abfrage, während ein hypothetisches Modell, das den vollständigen Kontext direkt liest, zum aktuellen Preis zwischen 1,50 und 2,75 USD kosten würde.
Der Forschungsarbeit analysiert auch die Trajektorien von RLM-Läufen. Es entstehen mehrere Verhaltensmuster. Das Modell beginnt oft mit einem Peek-Schritt, bei dem es die ersten paar tausend Zeichen des Kontexts untersucht. Anschließend wird eine Filterung im Grep-Stil mit Regex oder einer Stichwortsuche verwendet, um relevante Zeilen einzugrenzen. Bei komplexeren Abfragen wird der Kontext in Blöcke unterteilt und für jeden Block rekursive LMs aufgerufen, um eine Kennzeichnung oder Extraktion durchzuführen, gefolgt von einer programmgesteuerten Aggregation. Bei langen Ausgabeaufgaben speichert das RLM Teilausgaben in Variablen und fügt sie zusammen, wodurch die Ausgabelängenbeschränkungen des Basismodells umgangen werden.
Die neue Model von Prime Mind
Prime Mind-Crew hat dieses Konzept in eine konkrete Umgebung, RLMEnv, umgesetzt, die in ihren Verifizierer-Stack und Environments Hub integriert ist. In ihrem Design verfügt das Haupt-RLM nur über eine Python-REPL, während Unter-LLMs die umfangreichen Instruments wie Websuche oder Dateizugriff erhalten. Die REPL macht eine verfügbar llm_batch Funktion, damit das Root-Modell viele Unterabfragen parallel auffächern kann, und eine reply Variable, in die die endgültige Lösung geschrieben und als fertig gekennzeichnet werden muss. Dadurch werden Token-lastige Werkzeugausgaben vom Hauptkontext isoliert und das RLM kann teure Vorgänge an Untermodelle delegieren.
Höchster Intellekt bewertet diese Implementierung in vier Umgebungen. DeepDive testet die Webrecherche mit Such- und Öffnungstools und sehr ausführlichen Seiten. Math Python stellt eine Python-REPL für schwierige mathematische Probleme im Wettbewerbsstil bereit. Oolong verwendet den Lengthy-Context-Benchmark in RLMEnv wieder. Der Schwerpunkt der wörtlichen Kopie liegt auf der exakten Reproduktion komplexer Zeichenfolgen über Inhaltstypen wie JSON, CSV und gemischte Codes hinweg. In diesen Umgebungen profitieren sowohl GPT-5-mini als auch das INTELLECT-3-MoE-Modell vom RLM-Gerüst hinsichtlich der Erfolgsrate und der Robustheit gegenüber sehr langen Kontexten, insbesondere wenn die Werkzeugausgabe andernfalls den Modellkontext überfordern würde
Sowohl das Autorenteam des Forschungspapiers als auch das Prime Mind-Crew betonen, dass die aktuellen Implementierungen nicht vollständig optimiert sind. RLM-Aufrufe sind synchron, die Rekursionstiefe ist begrenzt und Kostenverteilungen weisen aufgrund sehr langer Trajektorien starke Ausläufer auf. Die eigentliche Likelihood besteht darin, RLM-Gerüst mit dediziertem Verstärkungslernen zu kombinieren, damit Modelle im Laufe der Zeit bessere Chunking-, Rekursions- und Werkzeugnutzungsrichtlinien erlernen. In diesem Fall bieten RLMs einen Rahmen, in dem Verbesserungen in Basismodellen und im Systemdesign direkt in leistungsfähigere Agenten mit langem Horizont umgesetzt werden, die Umgebungen mit mehr als 10 Millionen Token ohne Kontextverlust nutzen können.
Wichtige Erkenntnisse
Hier sind 5 prägnante, technische Erkenntnisse, die Sie unter den Artikel einfügen können.
- RLMs formatieren den langen Kontext als Umgebungsvariable um: Rekursive Sprachmodelle behandeln die gesamte Eingabeaufforderung als externe Zeichenfolge in einer REPL im Python-Stil, die vom LLM überprüft und durch Code transformiert wird, anstatt alle Token direkt in den Transformer-Kontext aufzunehmen.
- Die Inferenzzeitrekursion erweitert den Kontext auf mehr als 10 Millionen Token: RLMs ermöglichen es einem Root-Modell, rekursiv Sub-LLMs für ausgewählte Ausschnitte des Kontexts aufzurufen, was eine effektive Verarbeitung von Eingabeaufforderungen ermöglicht, die bis zu etwa zwei Größenordnungen länger als das Basiskontextfenster sind und bei Workloads im BrowseComp-Plus-Stil mehr als 10 Millionen Token erreichen.
- RLMs übertreffen herkömmliche Gerüste mit langem Kontext bei harten Benchmarks: Über S-NIAH-, BrowseComp-Plus-, OOLONG- und OOLONG-Paare hinweg verbessern RLM-Varianten von GPT-5 und Qwen3-Coder die Genauigkeit und F1 gegenüber direkten Modellaufrufen, Abrufagenten wie CodeAct und Zusammenfassungsagenten, während die Kosten professional Abfrage vergleichbar oder niedriger bleiben.
- Nur REPL-Varianten helfen bereits, Rekursion ist für quadratische Aufgaben von entscheidender Bedeutung: Eine Ablation, die nur die REPL ohne rekursive Unteraufrufe verfügbar macht, steigert immer noch die Leistung bei einigen Aufgaben, was den Wert der Auslagerung des Kontexts in die Umgebung zeigt, aber vollständige RLMs sind erforderlich, um große Gewinne bei informationsdichten Einstellungen wie OOLONG-Paaren zu erzielen.
- Prime Mind operationalisiert RLMs durch RLMEnv und INTELLECT 3: Das Crew von Prime Mind implementiert das RLM-Paradigma als RLMEnv, wobei der Root-LM eine Sandbox-Python-REPL steuert, Instruments über Sub-LMs aufruft und das Endergebnis in eine schreibt
replyVariable und meldet konsistente Gewinne in DeepDive-, Math Python-, Oolong- und Verbatim-Copy-Umgebungen mit Modellen wie INTELLECT-3.
Schauen Sie sich das an Papier Und Technische Particulars. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Asif Razzaq ist CEO von Marktechpost Media Inc.. Als visionärer Unternehmer und Ingenieur setzt sich Asif dafür ein, das Potenzial der künstlichen Intelligenz für das soziale Wohl zu nutzen. Sein jüngstes Unterfangen ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch eine ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die sowohl technisch fundiert als auch für ein breites Publikum leicht verständlich ist. Die Plattform verfügt über mehr als 2 Millionen monatliche Aufrufe, was ihre Beliebtheit beim Publikum verdeutlicht.