Die multimodale Modellierung konzentriert sich auf das Aufbau von Systemen, um Inhalte für visuelle und textliche Formate zu verstehen und zu generieren. Diese Modelle sind so konzipiert, dass sie visuelle Szenen interpretieren und neue Bilder mit natürlichen Sprachanforderungen produzieren. Mit zunehmendem Interesse an der Überbrückung von Imaginative and prescient und Sprache arbeiten die Forscher daran, die Bilderkennung und die Bildgenerierungsfunktionen in ein einheitliches System zu integrieren. Dieser Ansatz beseitigt die Notwendigkeit separater Pipelines und eröffnet den Weg zu kohärenteren und intelligenteren Interaktionen über Modalitäten hinweg.
Eine zentrale Herausforderung in diesem Bereich besteht darin, Architekturen zu entwickeln, die sowohl Verständnis als auch Era bewältigen, ohne die Qualität von beiden zu beeinträchtigen. Modelle müssen komplexe visuelle Konzepte erfassen und qualitativ hochwertige Bilder erzeugen, die den Benutzeraufforderungen entsprechen. Die Schwierigkeit besteht darin, geeignete Bilddarstellungen und Schulungsverfahren zu identifizieren, die beide Aufgaben unterstützen. Dieses Drawback wird deutlicher, wenn erwartet wird, dass das gleiche Modell detaillierte Textbeschreibungen interpretiert und basierend auf ihnen visuell genaue Ausgänge generiert. Es erfordert eine Ausrichtung des semantischen Verständnisses und der Synthese auf Pixelebene.
Frühere Ansätze haben im Allgemeinen Variations-Autocoder (VAEs) oder Clip-basierte Encoder verwendet, um Bilder darzustellen. VAEs sind für den Rekonstruktion effizient, kodieren jedoch Merkmale auf niedrigerer Ebene und führen häufig zu weniger informativen Darstellungen. Clip-basierte Encoder bieten hochrangige semantische Einbettungen, indem sie aus großen Bild-Textual content-Paaren lernen. Der Clip wurde jedoch nicht für die Bildrekonstruktion erstellt, wodurch es für die Era schwierig ist, mit Modellen wie Diffusionsdecoden gepaart zu werden. In Bezug auf das Coaching wird der mittlere Quadratfehler (MSE) in den Einfachheit halber weit verbreitet, neigt jedoch dazu, deterministische Ausgaben zu erzeugen. Um die Vielfalt und Qualität der Erzeugung zu verbessern, haben sich die Forscher in Flussübereinstimmungen verwandelt, was die kontrollierte Stochastizität einführt und die kontinuierliche Natur von Bildmerkmalen besser modelliert.

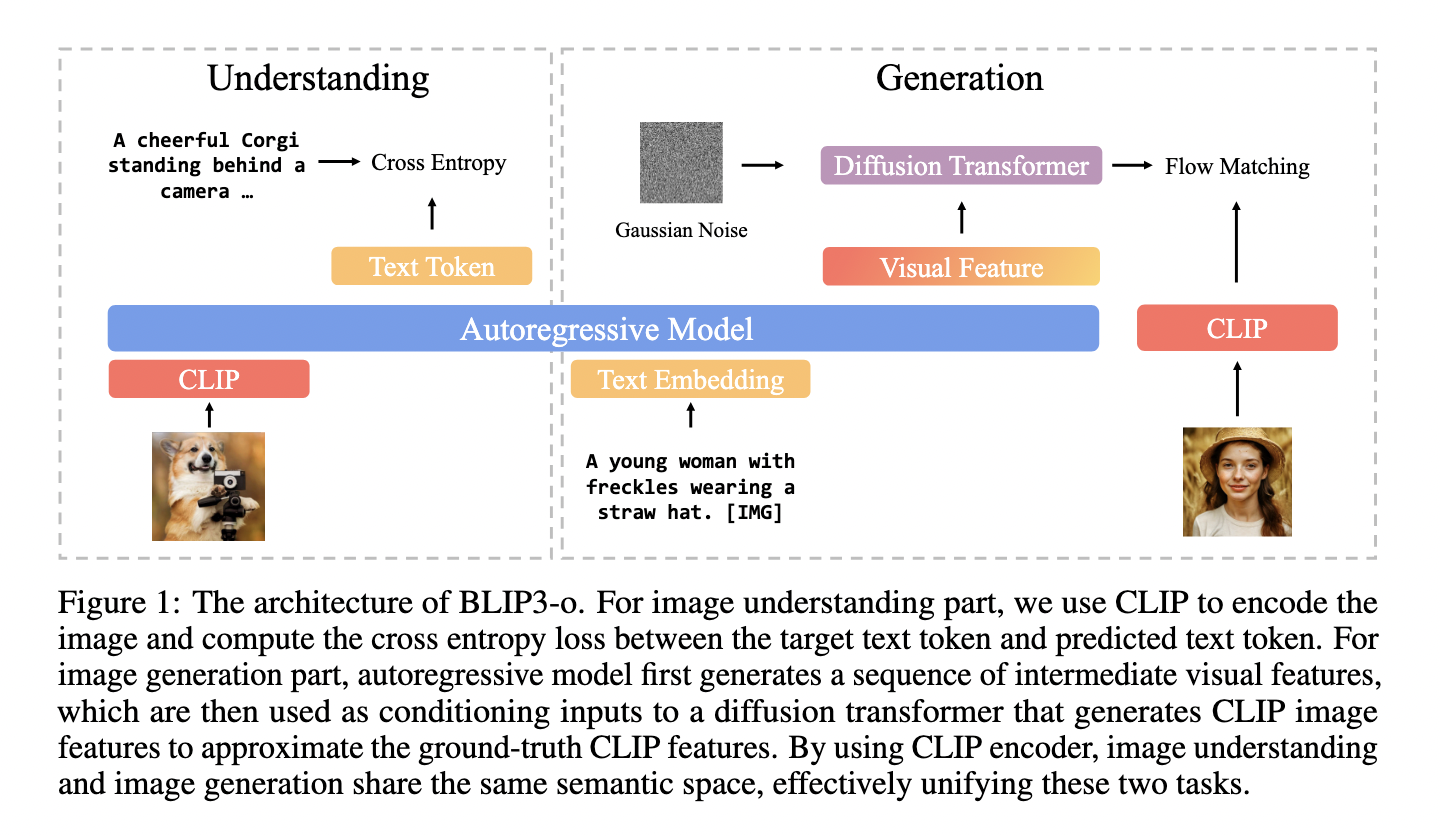
Forscher aus Salesforce Analysis in Zusammenarbeit mit der College of Maryland und mehreren akademischen Institutionen führten BLIP3-O vor, eine Familie einheitlicher multimodaler Modelle. Das Modell verwendet eine zweistufige Trainingsstrategie, bei der das Bildverständnis zuerst erlernt wird, gefolgt von der Bildgenerierung. Das vorgeschlagene System nutzt Clip -Einbettungen, um Bilder darzustellen, und integriert sie in einen Diffusionstransformator, um neue visuelle Ausgänge zu synthetisieren. Im Gegensatz zu früheren gemeinsamen Trainingsmethoden behält der sequentielle Ansatz die Stärke jeder Aufgabe unabhängig voneinander bei. Das Diffusionsmodul wird trainiert, während das autoregressive Rückgrat gefroren bleibt und Aufgabenstörungen vermeiden. Um die Ausrichtung und visuelle Treue zu verbessern, kuratierte das Workforce auch Blip3O-60K, ein hochwertiges Datensatz mit der Anweisungseinstellung, das durch Aufforderung an GPT-4O über verschiedene visuelle Kategorien hinweg erstellt wurde, einschließlich Szenen, Objekten, Gesten und Textual content. Sie entwickelten zwei Modellversionen: ein 8-Milliarden-Parametermodell, das mit proprietären und öffentlichen Daten trainiert wurde, und eine 4-Milliarden-Model mit nur Open-Supply-Daten.
Die Bildgenerierungspipeline von Blip3-O basiert auf QWEN2.5-VL-Großsprachmodellen. Eingabeaufforderungen werden verarbeitet, um visuelle Merkmale zu erzeugen, die durch einen Durchfluss -Matching -Diffusionstransformator verfeinert wurden. Dieser Transformator basiert auf der Lumina-Subsequent-Architektur, die für Geschwindigkeit und Qualität optimiert ist und die Aufmerksamkeit der 3D-Rotary-Place und die Aufmerksamkeit für Gruppierungen einbettet. Das Modell codiert jedes Bild in 64 semantische Vektoren mit fester Länge, unabhängig von der Auflösung, die kompakte Speicherung und effiziente Decodierung unterstützt. Das Forschungsteam verwendete einen groß angelegten Datensatz von 25 Millionen Bildern aus Quellen wie CC12M, SA-1B und JourneyDB, um die Modelle zu trainieren. Sie erweiterten es mit 30 Millionen proprietären Stichproben für das 8B -Modell. Dazu gehörten auch 60K-Anleitungsabstimmungen, die anspruchsvolle Eingabeaufforderungen wie komplexe Gesten und Orientierungspunkte abdecken, die über GPT-4O erzeugt wurden.

In Bezug auf die Leistung zeigte BLIP3-O High-Ergebnisse in mehreren Benchmarks. Das 8B -Modell erreichte einen Genrezwert von 0,84 für die Ausrichtung der Bildgenerierung und einen weisen Rating von 0,62 für die Argumentationsfähigkeit. Bildverständnis bewertet 1682.6 zur MME-Notion, 647.1 zu MME-Kognition, 50.6 auf MMMU und 83,1 sowohl für VQAV2- als auch für TextVQA-Datensätze. Eine menschliche Bewertung zum Vergleich von Blip3-O 8b mit Janus Professional 7b zeigte, dass Blip3-O 50,4% der Zeit für die visuelle Qualität und 51,5% für die sofortige Ausrichtung bevorzugt wurde. Diese Ergebnisse werden durch statistisch signifikante P-Werte (5.05E-06 und 1.16E-05) unterstützt, was auf die Überlegenheit von Blip3-O bei subjektiven Qualitätsbewertungen hinweist.

Diese Forschung beschreibt eine klare Lösung für die doppelte Herausforderung des Bildverständnisses und der Erzeugung. Clip -Einbettungen, Movement -Matching und eine sequentielle Trainingsstrategie zeigen, wie das Drawback methodisch angegangen werden kann. Das Blip3-O-Modell liefert modernste Ergebnisse und führt einen effizienten und offenen Ansatz für eine einheitliche multimodale Modellierung ein.
Schauen Sie sich das an PapierAnwesend Github -Seite Und Modell auf dem Umarmungsgesicht. Alle Krediten für diese Forschung gilt an die Forscher dieses Projekts. Fühlen Sie sich auch frei, uns zu folgen Twitter Und vergessen Sie nicht, sich unserer anzuschließen 90k+ ml Subreddit.
Der Beitrag Salesforce AI Releases Blip3-O: Ein mit Open-Supply-einheitliches multimodales Modell, das mit Clip-Einbettungen und Flussanpassung für Bildverständnis und Erzeugung erstellt wurde erschien zuerst auf Marktechpost.