
Wenn Sie Sprachschnittstellen, Transkriptionen oder multimodale Agenten erstellen, wird die Obergrenze Ihres Modells durch Ihre Daten bestimmt. Bei der Spracherkennung (ASR) bedeutet das, vielfältige, intestine gekennzeichnete Audiodaten zu sammeln, die reale Benutzer, Geräte und Umgebungen widerspiegeln, und diese diszipliniert auszuwerten.
Dieser Leitfaden zeigt Ihnen genau, wie Sie Sprachtrainingsdaten planen, sammeln, kuratieren und auswerten, damit Sie zuverlässige Produkte schneller liefern können.
Was zählt als „Spracherkennungsdaten“?
Mindestens: Audio + Textual content. In der Praxis benötigen leistungsstarke Systeme auch umfangreiche Metadaten (Sprecherdemografie, Standort, Gerät, akustische Bedingungen), Anmerkungsartefakte (Zeitstempel, Tagebuchführung, nicht-lexikalische Ereignisse wie Lachen) und Bewertungsaufteilungen mit robuster Abdeckung.
Profi-Tipp: Wenn Sie „Datensatz“ sagen, geben Sie die Aufgabe (Diktat vs. Befehle vs. Konversations-ASR), die Domäne (Supportanrufe, medizinische Notizen, Befehle im Auto) und Einschränkungen (Latenz, auf dem Gerät vs. Cloud) an. Es ändert alles von der Abtastrate bis zum Anmerkungsschema.
Das Sprachdatenspektrum (Wählen Sie aus, was zu Ihrem Anwendungsfall passt)
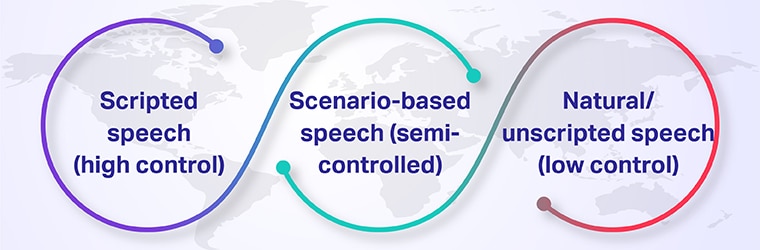
1. Geskriptete Rede (hohe Kontrolle)
Die Redner lesen die Aufforderungen wörtlich vor. Best für Befehl und Kontrolle, Weckwörter oder phonetische Abdeckung. Schnell skalierbar; weniger natürliche Variation.
2. Szenariobasierte Sprache (halbkontrolliert)
Die Referenten spielen Handlungsaufforderungen innerhalb eines Szenarios („Fragen Sie eine Klinik nach einem Glaukom-Termin“) durch. Sie erhalten abwechslungsreiche Formulierungen und bleiben gleichzeitig bei der Aufgabe – supreme für die Abdeckung der Fachsprache.
3. Natürliche/ungeschriebene Sprache (geringe Kontrolle)
Echte Gespräche oder kostenlose Monologe. Erforderlich für Anwendungsfälle mit mehreren Sprechern, Langformaten oder lauten Anwendungen. Schwieriger zu reinigen, aber entscheidend für die Robustheit. Der Originalartikel stellte dieses Spektrum vor; Hier legen wir Wert auf die Anpassung des Spektrums an das Produkt, um eine Über- oder Unteranpassung zu vermeiden.
Planen Sie Ihren Datensatz wie ein Produkt
Definieren Sie Erfolg und Einschränkungen im Voraus
- Primäre Metrik: WER (Wortfehlerrate) für die meisten Sprachen; CER (Character Error Charge) für Sprachen ohne klare Wortgrenzen.
- Latenz und Footprint: Werden Sie auf dem Gerät laufen? Das wirkt sich auf die Abtastrate, das Modell und die Komprimierung aus.
- Datenschutz und Compliance: Wenn Sie PHI/PII berühren (z. B. Gesundheitswesen), stellen Sie Einwilligung, Anonymisierung und Überprüfbarkeit sicher.
Ordnen Sie die tatsächliche Nutzung den Datenspezifikationen zu
- Gebietsschemata und Akzente: z. B. en-US, en-IN, en-GB; Steadiness zwischen städtischem/ländlichem und mehrsprachigem Code-Switching.
- Umgebungen: Büro, Straße, Auto, Küche; SNR-Ziele; Corridor vs. Shut-Speak-Mikrofone.
- Geräte: Good Speaker, Mobiltelefone (Android/iOS), Headsets, Automotive Kits, Festnetzanschlüsse.
- Inhaltsrichtlinien: Schimpfwörter, smart Themen, Hinweise zur Barrierefreiheit (Stottern, Dysarthrie), sofern angemessen und erlaubt.
Wie viele Daten benötigen Sie?
Es gibt keine einheitliche Zahl, aber die Abdeckung ist besser als reine Stundenzahlen. Geben Sie der Breite der Lautsprecher, Geräte und Akustik Vorrang vor extrem langen Aufnahmen von einigen wenigen Mitwirkenden. Für die Befehls- und Kontrollfunktion schlagen oft Tausende von Äußerungen über Hunderte von Sprechern weniger, dafür aber längere Aufzeichnungen vor. Investieren Sie für Konversations-ASR in Stunden × Vielfalt und sorgfältige Anmerkungen.
Aktuelle Landschaft: Open-Supply-Modelle (z. B. Whisper), die in Hunderttausenden von Stunden trainiert wurden, bilden eine solide Grundlage. Die Domänen-, Akzent- und Rauschanpassung an Ihre Daten ist immer noch das, was die Produktionsmetriken beeinflusst.
Sammlung: Schritt-für-Schritt-Workflow
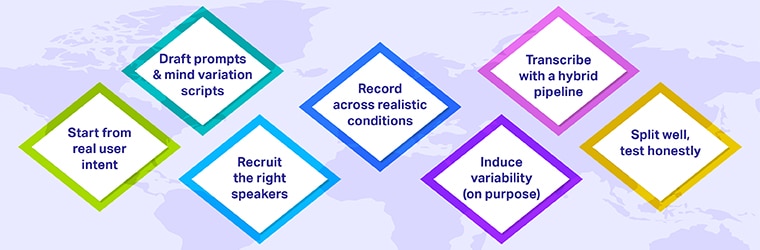
1. Beginnen Sie mit der tatsächlichen Benutzerabsicht
Durchsuchen Sie Suchprotokolle, Help-Tickets, IVR-Transkripte, Chat-Protokolle und Produktanalysen, um Eingabeaufforderungen und Szenarien zu entwerfen. Sie decken Lengthy-Tail-Absichten ab, die Ihnen sonst entgehen würden.
2. Entwerfen Sie Eingabeaufforderungen und Skripte unter Berücksichtigung von Variationen
- Schreiben Sie minimale Paare („Wohnzimmerlicht einschalten“ vs. „einschalten…“).
- Seed-Disfluenzen („äh, kannst du…“) und ggf. Codewechsel.
- Begrenzen Sie die Lesesitzungen auf etwa 15 Minuten, um Ermüdung zu vermeiden. Fügen Sie 2–3 Sekunden Lücken zwischen den Zeilen ein, um eine saubere Segmentierung zu gewährleisten (im Einklang mit Ihrer ursprünglichen Anleitung).
3. Rekrutieren Sie die richtigen Redner
Zielen Sie auf die demografische Vielfalt im Einklang mit Markt- und Fairnesszielen. Dokumentieren Sie Berechtigung, Quoten und Einwilligung. Honest entschädigen.
4. Nehmen Sie unter realistischen Bedingungen auf
Erstellen Sie eine Matrix: Lautsprecher × Geräte × Umgebungen.
Zum Beispiel:
- Geräte: iPhone-Mittelklasse, Android-Low-Tier, Good-Speaker-Fernfeldmikrofon.
- Umgebungen: ruhiger Raum (Nahfeld), Küche (Geräte), Auto (Autobahn), Straße (Verkehr).
- Formate: 16 kHz / 16-Bit-PCM ist für ASR üblich; Ziehen Sie höhere Tarife in Betracht, wenn Sie ein Downsampling durchführen.
5. Variabilität induzieren (absichtlich)
Fördern Sie natürliches Tempo, Selbstkorrekturen und Unterbrechungen. Bei szenariobasierten und natürlichen Daten sollten Sie nicht zu viel trainieren; Sie wollen die Unordnung, die Ihre Kunden verursachen.
6. Transkribieren Sie mit einer Hybridpipeline
- Automatische Transkription mit einem starken Basismodell (z. B. Whisper oder Ihrem internen Modell).
- Menschliche Qualitätssicherung für Korrekturen, Tagebuchführung und Ereignisse (Lachen, Füllwörter).
- Konsistenzprüfungen: Rechtschreibwörterbücher, Domänenlexika, Interpunktionsrichtlinie.
7. Intestine teilen; Teste ehrlich
- Trainieren/Entwickeln/Testen Sie mit Sprecher- und Szenario-Disjunktheit (Leckagen vermeiden).
- Behalten Sie ein reales Blindset bei, das Produktionsgeräusche und Geräte widerspiegelt; Berühren Sie es während der Iteration nicht.
Anmerkung: Machen Sie Etiketten zu Ihrem Burggraben
Definieren Sie ein klares Schema
- Lexikalische Regeln: Zahlen („fünfundzwanzig“ vs. „25“), Akronyme, Satzzeichen.
- Ereignisse: (Lachen), (Übersprechen), (unhörbar: 00:03.2–00:03.7).
- Diarisierung: Sprecher-A/B-Etiketten oder nachverfolgte IDs, sofern zulässig.
- Zeitstempel: Wort- oder Phrasenebene, wenn Sie Suche, Untertitel oder Ausrichtung unterstützen.
Annotatoren trainieren; Messen Sie sie
Nutzen Sie Gold Duties und Inter-Annotator Settlement (IAA). Verfolgen Sie die Präzision/den Rückruf kritischer Token (Produktnamen, Medikamente) und die Bearbeitungszeiten. Die Qualitätssicherung in mehreren Durchgängen (Peer-Evaluation → Lead-Evaluation) zahlt sich später in der Stabilität der Modellbewertung aus.
Qualitätsmanagement: Versenden Sie Ihren Knowledge Lake nicht
- Automatisierte Bildschirme: Clipping, Clipping-Verhältnis, SNR-Grenzen, lange Pausen, Codec-Nichtübereinstimmungen.
- Humanaudits: Zufallsstichproben nach Umgebung und Gerät; Stichprobenweise Tagebuchführung und Interpunktion.
- Versionierung: Behandeln Sie Datensätze wie Code – Semver, Änderungsprotokolle und unveränderliche Testsätze.
Bewerten Sie Ihre ASR: Mehr als nur ein einzelner WER
Messen Sie WER insgesamt und professional Scheibe:
- Nach Umgebung: Ruhe vs. Auto vs. Straße
- Nach Gerät: Low-Tier-Android vs. iPhone
- Nach Akzent/Gebietsschema: en-IN vs. en-US
- Nach Area-Begriffen: Produktnamen, Medikamente, Adressen
Verfolgen Sie Latenz, Teilverhalten und Endpointing, wenn Sie Echtzeit-UX nutzen. Bei der Modellüberwachung können Untersuchungen zur WER-Schätzung und Fehlererkennung dazu beitragen, der menschlichen Überprüfung Vorrang einzuräumen, ohne alles zu transkribieren.
Erstellen vs. Kaufen (oder beides): Datenquellen, die Sie kombinieren können

1. Standardkataloge
Nützlich für Bootstrapping und Vortraining, insbesondere um Sprachen oder Sprechervielfalt schnell abzudecken.
2. Benutzerdefinierte Datenerfassung
Wenn Domänen-, Akustik- oder Gebietsschemaanforderungen spezifisch sind, können Sie mit „Benutzerdefiniert“ den zielgerichteten WER erreichen. Sie steuern Eingabeaufforderungen, Kontingente, Geräte und Qualitätssicherung.
3. Daten öffnen (sorgfältig)
Best zum Experimentieren; Stellen Sie Lizenzkompatibilität, PII-Sicherheit und Bewusstsein für Verteilungsverschiebungen im Verhältnis zu Ihren Benutzern sicher.
Sicherheit, Datenschutz und Compliance
- Ausdrückliche Zustimmung und transparente Bedingungen für Mitwirkende
- Gegebenenfalls Deidentifizierung/Anonymisierung
- Geo-umzäunte Lager- und Zugangskontrollen
- Audit-Trails für Aufsichtsbehörden oder Unternehmenskunden
Reale Anwendungen (aktualisiert)
- Sprachsuche und -erkennung: Wachsende Benutzerbasis; Die Akzeptanz variiert je nach Markt und Anwendungsfall.
- Good Dwelling & Geräte: Assistenten der nächsten Technology unterstützen mehr gesprächige, mehrstufige Anfragen und legen damit die Messlatte für die Qualität von Trainingsdaten für weit entfernte, laute Räume höher.
- Kundensupport: Kurzfristiges, domänenlastiges ASR mit Diarisierung und Agentenunterstützung.
- Gesundheitsdiktat: Strukturierte Vokabeln, Abkürzungen und strenge Datenschutzkontrollen.
- Stimme im Auto: Fernfeldmikrofone, Bewegungsgeräusche und sicherheitskritische Latenz.
Mini-Fallstudie: Mehrsprachige Befehlsdaten im großen Maßstab
Ein globaler OEM benötigte Äußerungsdaten (3–30 Sekunden) in Tier-1- und Tier-2-Sprachen, um Befehle auf dem Gerät zu ermöglichen. Das Staff:
- Entworfene Eingabeaufforderungen zu Aktivierungswörtern, Navigation, Medien und Einstellungen
- Rekrutierte Sprecher professional Gebietsschema mit Gerätekontingenten
- Aufgenommener Ton in ruhigen Räumen und Fernfeldumgebungen
- Gelieferte JSON-Metadaten (Gerät, SNR, Gebietsschema, Geschlecht/Altersgruppe) sowie verifizierte Transkripte
Ergebnis: Ein produktionsbereiter Datensatz, der eine schnelle Modelliteration und messbare WER-Reduzierung bei domäneninternen Befehlen ermöglicht.
Häufige Fallstricke (und die Lösung)
- Zu viele Stunden, nicht genügend Abdeckung: Legen Sie Lautsprecher-/Geräte-/Umgebungskontingente fest.
- Undichte Auswertung: Erzwingen Sie sprecherdisjunkte Aufteilungen und einen echten Blindtest.
- Anmerkungsdrift: Führen Sie eine fortlaufende Qualitätssicherung durch und aktualisieren Sie Richtlinien mit realen Beispielen.
- Randmärkte ignorieren: Fügen Sie gezielte Daten für Code-Switching, regionale Akzente und ressourcenarme Gebiete hinzu.
- Latenzüberraschungen: Profilieren Sie Modelle frühzeitig mit Ihrem Audio auf Zielgeräten.
Wann sollten handelsübliche oder benutzerdefinierte Daten verwendet werden?
Verwenden Sie handelsübliche Standardlösungen, um schnell zu starten oder die Sprachabdeckung zu erweitern. Wechseln Sie zu „Benutzerdefiniert“, sobald WER auf Ihrer Area ein Plateau erreicht. Viele Groups kombinieren: Vorschulung/Feinabstimmung auf Katalogstunden, dann Anpassung mit maßgeschneiderten Daten, die Ihren Produktionstrichter widerspiegeln.
Checkliste: Bereit zur Abholung?
- Anwendungsfall, Erfolgsmetriken, definierte Einschränkungen
- Gebietsschemata, Geräte, Umgebungen und Kontingente abgeschlossen
- Einwilligung + Datenschutzrichtlinien dokumentiert
- Immediate-Pakete (Skript + Szenario) vorbereitet
- Anmerkungsrichtlinien + QA-Stufen genehmigt
- Regeln für die Aufteilung von Coaching, Entwicklung und Take a look at (sprecher- und szenariounabhängig)
- Überwachungsplan für Publish-Launch-Drift
Wichtige Erkenntnisse
- Abdeckung geht über Stunden. Balancieren Sie Lautsprecher, Geräte und Umgebungen aus, bevor Sie weitere Minuten anstreben.
- Kennzeichnung hochwertiger Verbindungen. Klares Schema und mehrstufige Qualitätssicherung übertreffen Single-Cross-Bearbeitungen.
- Nach Slice auswerten. Verfolgen Sie WER nach Akzent, Gerät und Geräusch; Hier lauern Produktrisiken.
- Datenquellen kombinieren. Bootstrapping mit Katalogen + kundenspezifische Anpassung ist oft am schnellsten gewinnbringend.
- Privatsphäre ist Produkt. Integrieren Sie vom ersten Tag an Einwilligung, De-ID und Überprüfbarkeit.
Wie Shaip Ihnen helfen kann
Benötigen Sie maßgeschneiderte Sprachdaten? Shaip bietet benutzerdefinierte Sammlung, Annotation und Transkription – und bietet gebrauchsfertige Datensätze mit handelsüblichen Audiodaten/Transkripten in über 150 Sprachen/Varianten, sorgfältig abgestimmt auf Sprecher, Geräte und Umgebungen.