
dots.oc ist ein Open-Supply-Visionsprachtransformatormodell, das für mehrsprachige Dokumentenlayout-Parsen und optische Charaktererkennung (OCR) entwickelt wurde. Es führt sowohl die Layouterkennung als auch die Inhaltserkennung innerhalb einer einzelnen Architektur durch und unterstützt über 100 Sprachen und eine Vielzahl strukturierter und unstrukturierter Dokumenttypen.
Architektur
- Einheitliches Modell: DOTS.OCR kombiniert Format-Erkennung und Inhaltserkennung in ein einzelnes transformatorbasiertes neuronales Netzwerk. Dadurch wird die Komplexität separater Erkennungs- und OCR -Pipelines beseitigt, sodass Benutzer die Aufgaben durch Einstellen der Eingabeaufforderungen anpassen können.
- Parameter: Das Modell enthält 1,7 Milliarden Parameter, die die Recheneffizienz mit Leistung für die meisten praktischen Szenarien ausbalancieren.
- Eingabeflexibilität: Eingänge können Bilddateien oder PDF -Dokumente sein. Das Modell verfügt über die Vorverarbeitungsoptionen (z. B. Fitz_Proprocess) zur Optimierung der Qualität bei niedrigen Auflösungen oder dichten mehrseitigen Dateien.
Fähigkeiten
- Mehrsprachig: DOTS.OCR wird auf Datensätzen geschult, die mehr als 100 Sprachen umfassen, einschließlich der wichtigsten Weltsprachen und weniger gemeinsamen Skripte, die breite mehrsprachige Unterstützung widerspiegeln.
- Inhaltsextraktion: Das Modell extrahiert Klartext, tabellarische Daten, mathematische Formeln (in Latex) und bewahrt die Lesereihenfolge in Dokumenten. Zu den Ausgangsformaten gehören strukturierte JSON, Markdown und HTML, abhängig vom Format- und Inhaltstyp.
- Bewahrung der Struktur: DOTS.OCR behält die Dokumentstruktur bei, einschließlich Tabellengrenzen, Formelregionen und Bildplatzierungen, wodurch gewährleistet wird, dass extrahierte Daten dem Originaldokument treu bleiben.
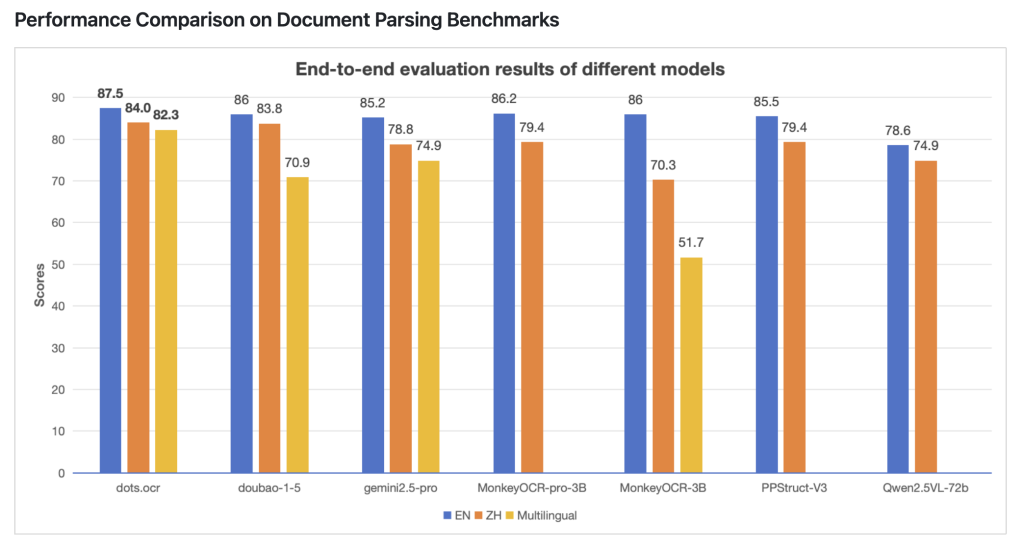
Benchmark -Leistung
DOTS.OCR wurde an modernen Dokument -KI -Systemen bewertet, wobei die Ergebnisse nachstehend zusammengefasst sind:
| Benchmark | dots.oc | Gemini2.5-pro |
|---|---|---|
| Tabelle TEDS -Genauigkeit | 88,6% | 85,8% |
| Textual content Distanz bearbeiten | 0,032 | 0,055 |
- Tische: Übertrifft Gemini2.5-pro in der Genauigkeit der Tabelle Parsing.
- Textual content: Demonstriert einen niedrigeren Textbearbeitungsabstand (was höhere Präzision anzeigt).
- Formeln und Format: Übereinstimmt oder übertrifft führende Modelle in der Rekonstruktion der Formelerkennung und der Dokumentstruktur.
Bereitstellung und Integration
- Open-Supply: Veröffentlicht unter der MIT-Lizenz mit Quell-, Dokumentations- und Vor-ausgebildeten Modellen, die auf GitHub verfügbar sind. Das Repository enthält Installationsanweisungen für PIP-, Conda- und Docker-basierte Bereitstellungen.
- API und Scripting: Unterstützt die versatile Aufgabenkonfiguration über Eingabeaufforderung Vorlagen. Das Modell kann interaktiv oder in automatisierten Pipelines zur Verarbeitung von Stapeldokumenten verwendet werden.
- Ausgangsformate: Extrahierte Ergebnisse werden in strukturiertem JSON für den programmatischen Gebrauch geliefert, wobei gegebenenfalls Optionen für Markdown und HTML geeignet sind. Visualisierungsskripte ermöglichen die Inspektion erkannter Layouts.
Abschluss
DOTS.OCR bietet eine technische Lösung für die Hochschuldauer, mehrsprachige Dokumente an die Parsen, indem sie Layouterkennung und Inhaltserkennung in einem einzigen Open-Supply-Modell vereint. Es ist besonders für Szenarien geeignet, die eine robuste, sprachunabhängige Dokumentanalyse und strukturierte Informationsextraktion in ressourcenbeschränkten oder Produktionsumgebungen erfordern.
Schauen Sie sich das an Github -Seite. Fühlen Sie sich frei, unsere zu überprüfen Github -Seite für Tutorials, Codes und Notizbücher. Fühlen Sie sich auch frei, uns zu folgen Twitter Und vergessen Sie nicht, sich unserer anzuschließen 100k+ ml Subreddit und abonnieren Unser E-newsletter.

Michal Sutter ist ein Datenwissenschaftler bei einem Grasp of Science in Knowledge Science von der College of Padova. Mit einer soliden Grundlage für statistische Analyse, maschinelles Lernen und Datentechnik setzt Michal aus, um komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.