
Was kommt nach Transformers? Google Analysis schlägt eine neue Möglichkeit vor, Sequenzmodellen mit Titans und MIRAS ein nutzbares Langzeitgedächtnis zu verleihen und gleichzeitig das Coaching parallel und die Inferenz nahezu linear zu halten.
Titans ist eine konkrete Architektur, die einem Rückgrat im Transformer-Stil ein tiefes neuronales Gedächtnis hinzufügt. MIRAS ist ein allgemeines Framework, das die meisten modernen Sequenzmodelle als Instanzen der On-line-Optimierung über einen assoziativen Speicher betrachtet.
Warum Titanen und MIRAS?
Normal-Transformer verwenden Aufmerksamkeit gegenüber einem Schlüsselwert-Cache. Dies ermöglicht ein starkes Kontextlernen, aber die Kosten steigen quadratisch mit der Kontextlänge, sodass der praktische Kontext selbst mit FlashAttention und anderen Kernel-Tips begrenzt ist.
Effiziente lineare rekurrente neuronale Netze und Zustandsraummodelle wie Mamba-2 komprimieren den Verlauf in einen Zustand fester Größe, sodass die Kosten linear in der Sequenzlänge sind. Bei dieser Komprimierung gehen jedoch Informationen in sehr langen Sequenzen verloren, was Aufgaben wie die Genommodellierung und den extrem langen Kontextabruf beeinträchtigt.
Titans und MIRAS kombinieren diese Ideen. Die Aufmerksamkeit fungiert als präzises Kurzzeitgedächtnis für das aktuelle Fenster. Ein separates neuronales Modul stellt das Langzeitgedächtnis bereit, lernt zum Testzeitpunkt und ist so trainiert, dass seine Dynamik auf Beschleunigern parallelisierbar ist.
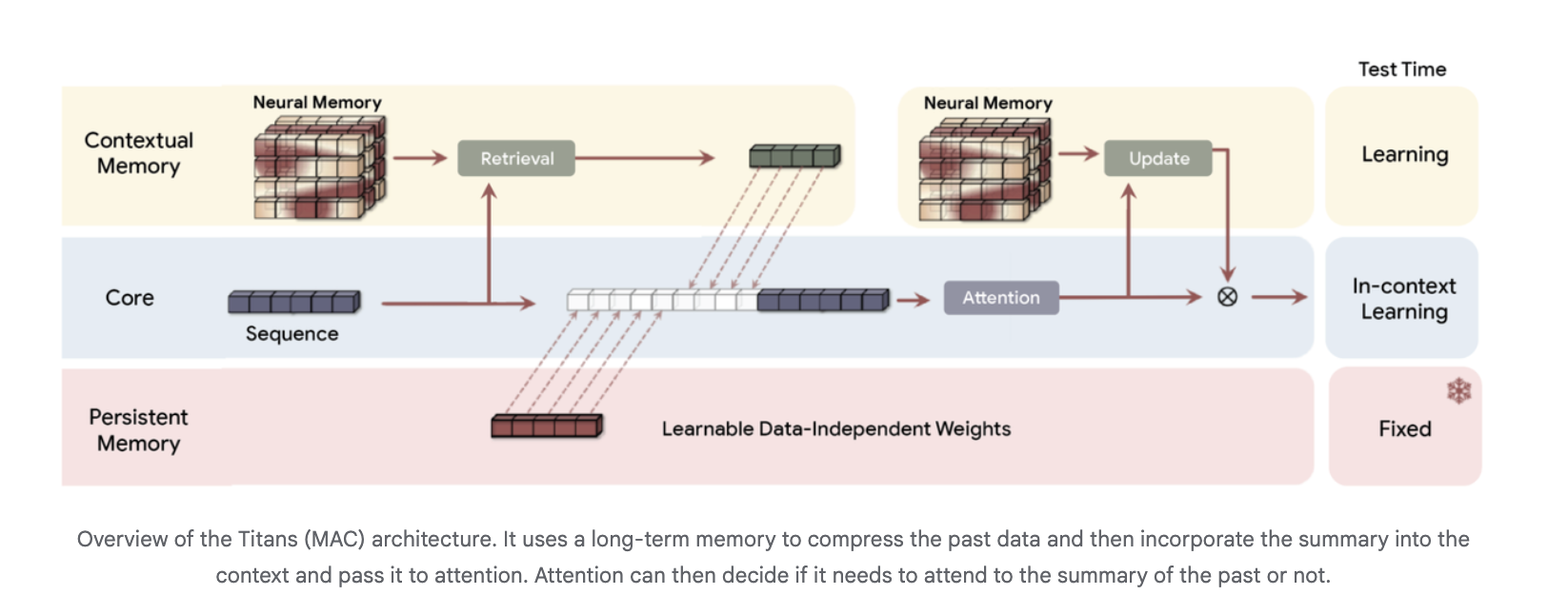
Titans, ein neuronales Langzeitgedächtnis, das bei Prüfungen lernt
Der Titans-Forschungspapier führt ein neuronales Langzeitgedächtnismodul ein, das selbst ein tiefes mehrschichtiges Perzeptron und kein Vektor- oder Matrixzustand ist. Aufmerksamkeit wird als Kurzzeitgedächtnis interpretiert, da sie nur ein begrenztes Fenster sieht, während das neuronale Gedächtnis als dauerhaftes Langzeitgedächtnis fungiert.
Für jeden Token definiert Titans einen assoziativen Gedächtnisverlust
ℓ(Mₜ₋₁; kₜ, vₜ) = ‖Mₜ₋₁(kₜ) − vₜ‖²
Dabei ist Mₜ₋₁ der aktuelle Speicher, kₜ der Schlüssel und vₜ der Wert. Der Gradient dieses Verlusts in Bezug auf die Speicherparameter ist die „Überraschungsmetrik“. Große Gradienten entsprechen überraschenden Token, die gespeichert werden sollten, kleine Gradienten entsprechen erwarteten Token, die größtenteils ignoriert werden können.
Die Speicherparameter werden zum Testzeitpunkt durch Gradientenabstieg mit Impuls- und Gewichtsabfall aktualisiert, die zusammen als Retention Gate und Vergessensmechanismus fungieren. Um diese On-line-Optimierung effizient zu halten, zeigt das Forschungspapier, wie diese Aktualisierungen mit gestapelten Matrixmultiplikationen über Sequenzblöcke berechnet werden, wodurch das parallele Coaching über lange Sequenzen hinweg erhalten bleibt.
Architektonisch verwendet Titans drei Speicherzweige im Spine, die häufig in der Titans-MAC-Variante vorkommen:
- ein Kernzweig, der Normal-Kontextlernen mit Aufmerksamkeit durchführt
- ein kontextueller Speicherzweig, der aus der aktuellen Sequenz lernt
- ein persistenter Speicherzweig mit festen Gewichtungen, der das Wissen vor dem Coaching kodiert
Das Langzeitgedächtnis komprimiert vergangene Token zu einer Zusammenfassung, die dann als zusätzlicher Kontext an die Aufmerksamkeit weitergegeben wird. Die Aufmerksamkeit kann entscheiden, wann diese Zusammenfassung gelesen werden soll.
Experimentelle Ergebnisse für Titanen
Bei Sprachmodellierungs- und Frequent-Sense-Argumentation-Benchmarks wie C4, WikiText und HellaSwag übertreffen Titans-Architekturen die hochmodernen linearen rekurrenten Basislinien-Modelle Mamba-2 und Gated DeltaNet und Transformer++ vergleichbarer Größe. Die Google-Forschung führt dies auf die höhere Ausdruckskraft des Deep Reminiscence und seine Fähigkeit zurück, die Leistung bei zunehmender Kontextlänge aufrechtzuerhalten. Tiefe neuronale Erinnerungen mit dem gleichen Parameterbudget, aber höherer Tiefe führen zu einer durchweg geringeren Ratlosigkeit.
Für die Erinnerung an extrem lange Kontexte verwendet das Forschungsteam den BABILong-Benchmark, bei dem Fakten auf sehr lange Dokumente verteilt werden. Titans übertrifft alle Basismodelle, einschließlich sehr großer Modelle wie GPT-4, verwendet dabei viel weniger Parameter und lässt sich auf Kontextfenster über 2.000.000 Token skalieren.
Das Forschungsteam berichtet, dass Titans ein effizientes paralleles Coaching und schnelle lineare Schlussfolgerungen ermöglicht. Das neuronale Gedächtnis allein ist etwas langsamer als die schnellsten linearen wiederkehrenden Modelle, aber Hybrid-Titans-Schichten mit Sliding Window Consideration bleiben beim Durchsatz konkurrenzfähig und verbessern gleichzeitig die Genauigkeit.
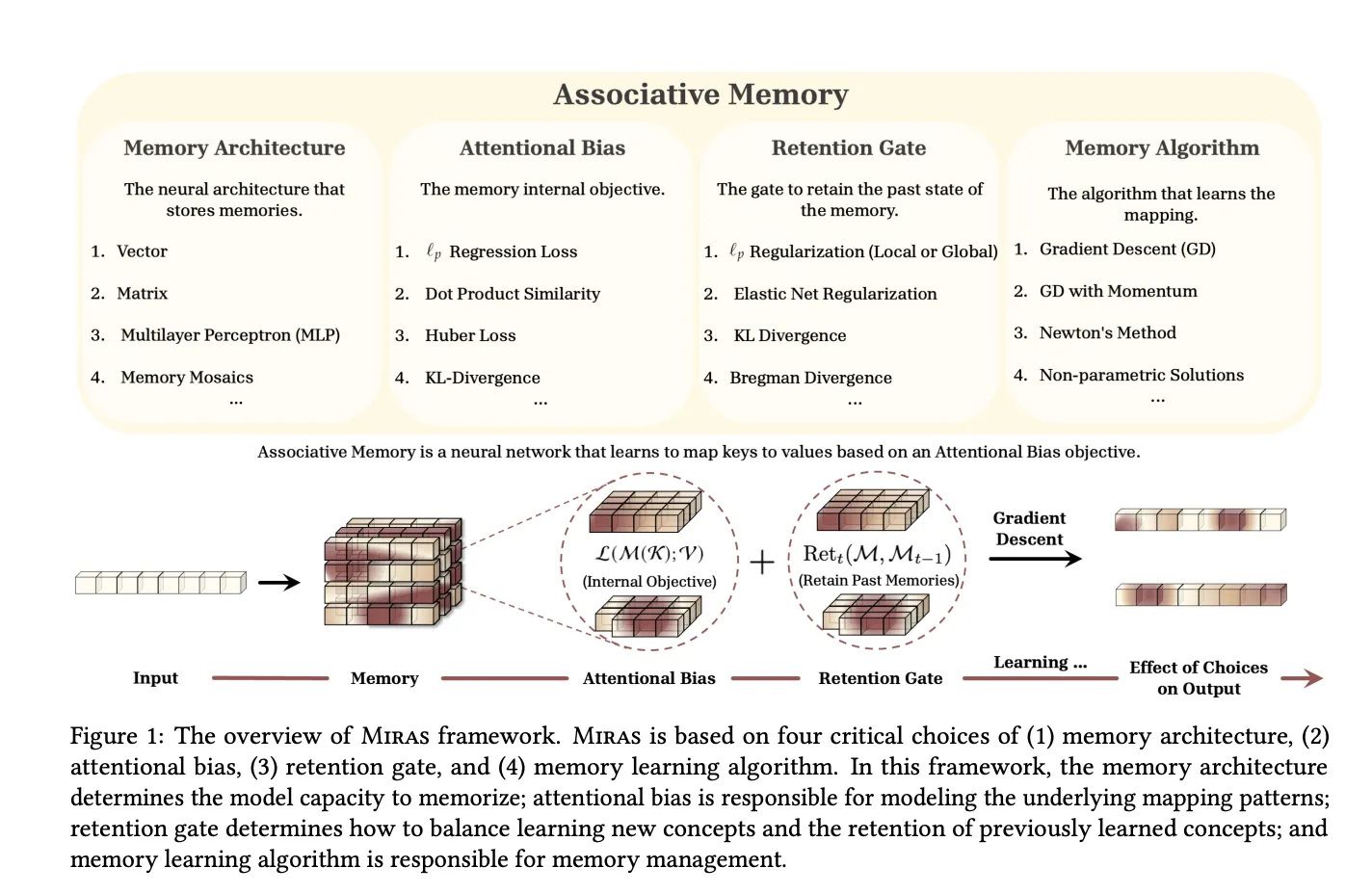
MIRAS, ein einheitliches Framework für Sequenzmodelle als assoziatives Gedächtnis
Das MIRAS-Forschungspapier, „Alles hängt zusammen: Eine Reise durch das Auswendiglernen von Testzeiten, Aufmerksamkeitsverzerrung, Merkfähigkeit und On-line-Optimierung.“„verallgemeinert diese Ansicht. Es stellt fest, dass moderne Sequenzmodelle als assoziative Erinnerungen betrachtet werden können, die Schlüssel zu Werten abbilden und gleichzeitig Lernen und Vergessen in Einklang bringen.
MIRAS definiert jedes Sequenzmodell durch vier Designoptionen:
- Speicherstruktur zum Beispiel ein Vektor, eine lineare Karte oder MLP
- Aufmerksamkeitsdefizit der interne Verlust, der definiert, welche Ähnlichkeiten die Erinnerung interessiert
- Rückhaltetor der Regularisierer, der den Speicher nahe seinem früheren Zustand hält
- Speicheralgorithmus Bei der On-line-Optimierungsregel kommt es häufig zu einem Gradientenabstieg mit Schwung
Mithilfe dieser Linse stellt MIRAS mehrere Familien wieder her:
- Lineare wiederkehrende Modelle im Hebbian-Stil und RetNet als Skalarprodukt-basierte assoziative Erinnerungen
- Delta-Regelmodelle wie DeltaNet und Gated DeltaNet als MSE-basierte Speicher mit Wertersatz und spezifischen Retention Gates
- Titans LMM als nichtlinearer MSE-basierter Speicher mit lokaler und globaler Aufbewahrung, optimiert durch Gradientenabstieg mit Impuls
Entscheidend ist, dass MIRAS dann über die üblichen MSE- oder Dot-Product-Ziele hinausgeht. Das Forschungsteam konstruiert neue Aufmerksamkeitsverzerrungen auf der Grundlage von Lₚ-Normen, robustem Huber-Verlust und robuster Optimierung sowie neue Retention Gates auf der Grundlage von Divergenzen über Wahrscheinlichkeitsvereinfachungen, elastischer Netzregularisierung und Bregman-Divergenz.
Ausgehend von diesem Designraum instanziiert das Forschungsteam drei aufmerksamkeitsfreie Modelle:
- Moneta verwendet einen 2-Schicht-MLP-Speicher mit Lₚ-Aufmerksamkeitsverzerrung und einem hybriden Retention-Gate basierend auf allgemeinen Normen
- Yaad verwendet den gleichen MLP-Speicher mit Huber-Verlust-Aufmerksamkeitsfehler und einem Vergessenstor im Zusammenhang mit Titans
- Memora verwendet Regressionsverlust als Aufmerksamkeitsverzerrung und ein auf KL-Divergenz basierendes Retention-Gate über einem Wahrscheinlichkeits-Simplex-Speicher.
Diese MIRAS-Varianten ersetzen Aufmerksamkeitsblöcke in einem Grundgerüst im Lama-Stil, verwenden in der Tiefe trennbare Windungen in der Miras-Schicht und können in Hybridmodellen mit Sliding Window Consideration kombiniert werden. Das Coaching bleibt parallel, indem Sequenzen aufgeteilt und Gradienten in Bezug auf den Speicherzustand des vorherigen Blocks berechnet werden.
In Forschungsexperimenten erreichen oder übertreffen Moneta, Yaad und Memora starke lineare wiederkehrende Modelle und Transformer++ in Bezug auf Sprachmodellierung, vernünftiges Denken und abrufintensive Aufgaben, während gleichzeitig die lineare Zeitinferenz beibehalten wird.
Wichtige Erkenntnisse
- Titans führt ein tiefes neuronales Langzeitgedächtnis ein, das zum Zeitpunkt der Prüfung lerntwobei der Gradientenabstieg bei einem assoziativen L2-Speicherverlust verwendet wird, sodass das Modell selektiv nur überraschende Token speichert und gleichzeitig Aktualisierungen auf Beschleunigern parallelisierbar hält.
- Titans kombiniert Aufmerksamkeit mit neuronalem Gedächtnis für lange KontexteDabei werden Zweige wie der Kern, das Kontextgedächtnis und das persistente Gedächtnis verwendet, damit die Aufmerksamkeit die Präzision im Nahbereich verarbeitet und das neuronale Modul Informationen über Sequenzen über 2.000.000 Token hinweg verwaltet.
- Titans übertrifft starke lineare RNNs und Transformer++-Basislinieneinschließlich Mamba-2 und Gated DeltaNet, zu Sprachmodellierungs- und Frequent-Sense-Argumentation-Benchmarks auf vergleichbaren Parameterskalen, während sie gleichzeitig beim Durchsatz wettbewerbsfähig bleiben.
- Bei extrem langen Kontext-Recall-Benchmarks wie BABILongTitans erreicht eine höhere Genauigkeit als alle Basislinien, einschließlich größerer Aufmerksamkeitsmodelle wie GPT 4, verwendet dabei weniger Parameter und ermöglicht dennoch effizientes Coaching und Inferenz.
- MIRAS bietet einen vereinheitlichenden Rahmen für Sequenzmodelle als assoziative Erinnerungenindem es sie durch Speicherstruktur, Aufmerksamkeitsverzerrung, Retention Gate und Optimierungsregel definiert und neue aufmerksamkeitsfreie Architekturen wie Moneta, Yaad und Memora hervorbringt, die linearen RNNs und Transformer++ bei langen Kontext- und Argumentationsaufgaben entsprechen oder diese übertreffen.
Schauen Sie sich das an Technische Particulars. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.

Michal Sutter ist ein Knowledge-Science-Experte mit einem Grasp of Science in Knowledge Science von der Universität Padua. Mit einer soliden Grundlage in statistischer Analyse, maschinellem Lernen und Datentechnik ist Michal hervorragend darin, komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.