
Wie kann ein Massive Language Mannequin mit Billionen Parametern eine Unternehmensleistung auf dem neuesten Stand der Technik erreichen und gleichzeitig die Gesamtzahl der Parameter um 33,3 % reduzieren und die Effizienz vor dem Coaching um 49 % steigern? Yuan Lab AI veröffentlicht Yuan3.0 Extremely, ein Open-Supply-Combination-of-Specialists (MoE) großes Sprachmodell mit 1T Gesamtparameter Und 68,8B aktivierte Parameter. Die Modellarchitektur ist darauf ausgelegt, die Leistung bei unternehmensspezifischen Aufgaben zu optimieren und gleichzeitig wettbewerbsfähige Allzweckfunktionen beizubehalten. Im Gegensatz zu herkömmlichen dichten Modellen nutzt Yuan3.0 Extremely Sparsity, um die Kapazität zu skalieren, ohne dass die Rechenkosten linear steigen.
Layer-Adaptive Knowledgeable Pruning (LAEP)
Die Hauptinnovation im Coaching von Yuan3.0 Extremely ist die Layer-Adaptive Knowledgeable Pruning (LAEP) Algorithmus. Während die Expertenbereinigung in der Regel nach dem Coaching angewendet wird, identifiziert und entfernt LAEP nicht ausgelastete Experten direkt während des Trainings Vorbereitungsphase.
Untersuchungen zur Belastungsverteilung durch Experten ergaben zwei unterschiedliche Phasen während des Vortrainings:
- Erste Übergangsphase: Gekennzeichnet durch eine hohe Volatilität der Expertenlasten, die durch zufällige Initialisierung geerbt werden.
- Stabile Part: Die Expertenlasten konvergieren und die relative Rangfolge der Experten basierend auf der Token-Zuweisung bleibt weitgehend unverändert.
Sobald die stabile Part erreicht ist, wendet LAEP eine Beschneidung an, die auf zwei Einschränkungen basiert:
- Individuelle Lastbeschränkung (⍺): Zielgruppe sind Experten, deren Token-Final deutlich unter dem Layer-Durchschnitt liegt.
- Kumulative Lastbeschränkung (β): Identifiziert die Teilmenge der Experten, die am wenigsten zur gesamten Tokenverarbeitung beitragen.
Durch die Anwendung von LAEP mit β=0,1 und Variation von ⍺ wurde das Modell von einem Anfangsmodell beschnitten 1,5T-Parameter bis hin zu 1T-Parameter. Das Reduzierung um 33,3 % Die Gesamtparameter bewahrten die Multidomänenleistung des Modells und senkten gleichzeitig den Speicherbedarf für die Bereitstellung erheblich. In der 1T-Konfiguration wurde die Anzahl der Experten professional Schicht von 64 auf maximal reduziert 48 erhaltene Experten.
{Hardware}-Effizienz und fachmännische Neuanordnung
MoE-Modelle leiden häufig unter einem Lastungleichgewicht auf Geräteebene, wenn Experten über einen Computercluster verteilt sind. Um dieses Downside zu beheben, implementiert Yuan3.0 Extremely eine Expertenalgorithmus für die Neuanordnung.
Dieser Algorithmus ordnet Experten nach Token-Final ein und verwendet eine Grasping-Strategie, um sie auf GPUs zu verteilen, sodass die kumulative Token-Varianz minimiert wird.
| Verfahren | TFLOPS professional GPU |
| Basismodell (1515B) | 62.14 |
| DeepSeek-V3 Aux-Verlust | 80,82 |
| Yuan3.0 Extremely (LAEP) | 92,60 |
Gesamteffizienz vor dem Coaching verbessert um 49 %. Diese Verbesserung ist auf zwei Faktoren zurückzuführen:
- Modellschnitt: Beigetragen 32,4 % zum Effizienzgewinn.
- Fachmännische Neuordnung: Beigetragen 15,9 % zum Effizienzgewinn.
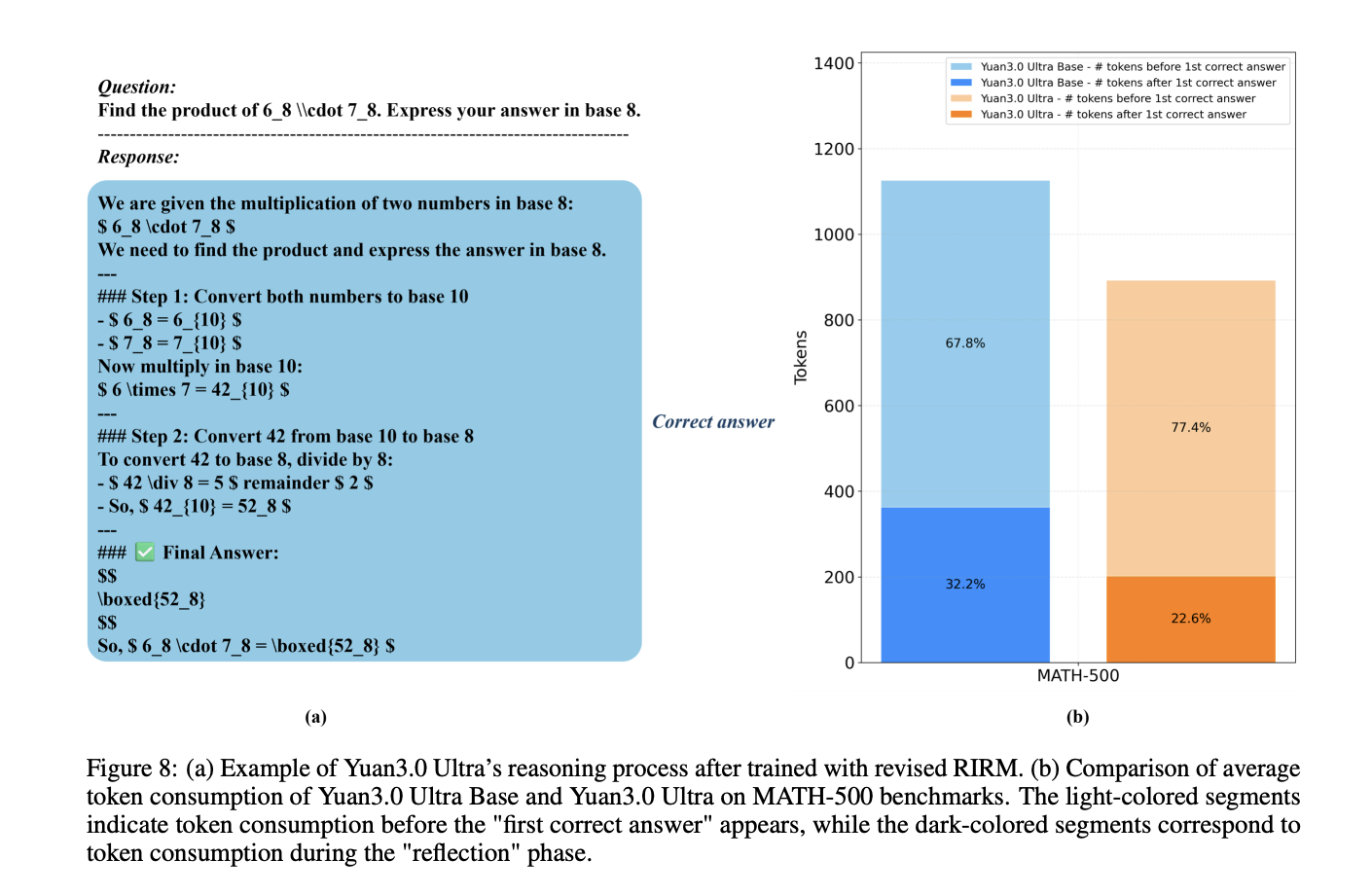
Übermäßiges Nachdenken mit überarbeitetem RIRM abmildern
In der Part des verstärkenden Lernens (RL) verwendet das Modell eine Verfeinerung Reflection Inhibition Reward Mechanism (RIRM) um zu lange Argumentationsketten für einfache Aufgaben zu verhindern.
Die Belohnung für Reflexion, $R_{ver}$, wird mithilfe eines schwellenwertbasierten Strafsystems berechnet:
- Rmin=0: Die ideale Anzahl an Reflexionsschritten für direkte Antworten.
- Rmax=3: Die maximal tolerierbare Reflexionsschwelle.
Für korrekte Stichproben nimmt die Belohnung ab, wenn sich die Reflexionsschritte r nähernmaxwährend falsche Proben, die „überdenken“ (über rmax Höchststrafen erhalten. Dieser Mechanismus führte zu a 16,33 % Steigerung der Trainingsgenauigkeit und a 14,38 % Reduzierung der Ausgabe-Token-Länge.

Unternehmens-Benchmark-Leistung
Yuan3.0 Extremely wurde im Rahmen spezieller Unternehmens-Benchmarks anhand mehrerer Branchenmodelle, darunter GPT-5.2 und Gemini 3.1 Professional, bewertet.
| Benchmark | Aufgabenkategorie | Yuan3.0 Extremely-Rating | Bester Wettbewerber-Rating |
| Docmatix | Multimodales RAG | 67,4 % | 48,4 % (GPT-5,2) |
| ChatRAG | Textabruf (Durchschn.) | 68,2 % | 53,6 % (Kimi K2,5) |
| MMTab | Tabellenbegründung | 62,3 % | 66,2 % (Kimi K2,5) |
| SummEval | Textzusammenfassung | 62,8 % | 49,9 % (Claude Opus 4,6) |
| Spinne 1.0 | Textual content-zu-SQL | 83,9 % | 82,7 % (Kimi K2,5) |
| BFCL V3 | Software-Aufruf | 67,8 % | 78,8 % (Gemini 3.1 Professional) |
Die Ergebnisse zeigen, dass Yuan3.0 Extremely modernste Genauigkeit beim multimodalen Retrieval (Docmatix) und Lengthy-Context-Retrieval (ChatRAG) erreicht und gleichzeitig eine robuste Leistung bei der strukturierten Datenverarbeitung und beim Software-Aufruf beibehält.
Schauen Sie sich das an Papier Und Repo. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 120.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.