
Im Laufe der Tage gibt es mehr Benchmarks als je zuvor. Es ist schwer, den Überblick zu behalten HellaSwag oder DS-1000 das kommt raus. Und wozu dienen sie überhaupt? Ein Haufen cool aussehender Namen, die auf einen Benchmark geklebt wurden, damit sie cooler aussehen … Nicht wirklich.
Abgesehen von der verrückten Benennung dieser Benchmarks dienen sie einem sehr praktischen und sorgfältigen Zweck. Jeder von ihnen testet das Modell in einer Reihe von Assessments, um zu sehen, wie intestine das Modell den idealen Requirements entspricht. Diese Requirements beziehen sich normalerweise darauf, wie intestine sie im Vergleich zu einem normalen Menschen abschneiden.
Dieser Artikel hilft Ihnen herauszufinden, was diese Benchmarks sind und welcher zum Testen welcher Artwork von Modell wann verwendet wird.
Allgemeine Intelligenz: Kann sie tatsächlich denken?
Diese Benchmarks testen, wie intestine die KI-Modelle die Denkfähigkeit des Menschen nachbilden.
1. MMLU – Multitask-Sprachverständnis
MMLU ist die grundlegende „allgemeine Intelligenzprüfung“ für Sprachmodelle. Es enthält Tausende von A number of-Alternative-Fragen zu 60 Themen mit vier Optionen professional Frage und deckt Bereiche wie Medizin, Recht, Mathematik und Informatik ab.
Es ist nicht perfekt, aber es ist universell. Wenn ein Mannequin MMLU überspringt, fragen die Leute sofort Warum? Das allein zeigt schon, wie wichtig es ist.
Verwendet in: Allzweck-Sprachmodelle (GPT, Claude, Zwillinge, Lama, Mistral)
Papier: https://arxiv.org/abs/2009.03300
2. HLE – Die letzte Prüfung der Menschheit
HLE existiert, um eine einfache Frage zu beantworten: Können Modelle mit dem Denken auf Expertenebene umgehen, ohne auf das Auswendiglernen angewiesen zu sein?
Der Benchmark fasst äußerst schwierige Fragen aus den Bereichen Mathematik, Naturwissenschaften und Geisteswissenschaften zusammen. Diese Fragen werden bewusst gefiltert, um im Web durchsuchbare Fakten und häufige Schulungslecks zu vermeiden.
Die Fragenzusammensetzung des Benchmarks ähnelt möglicherweise MMLU, aber im Gegensatz zu MMLU ist HLE darauf ausgelegt, die LLMs auf Herz und Nieren zu testen, was in dieser Leistungsmetrik dargestellt wird:
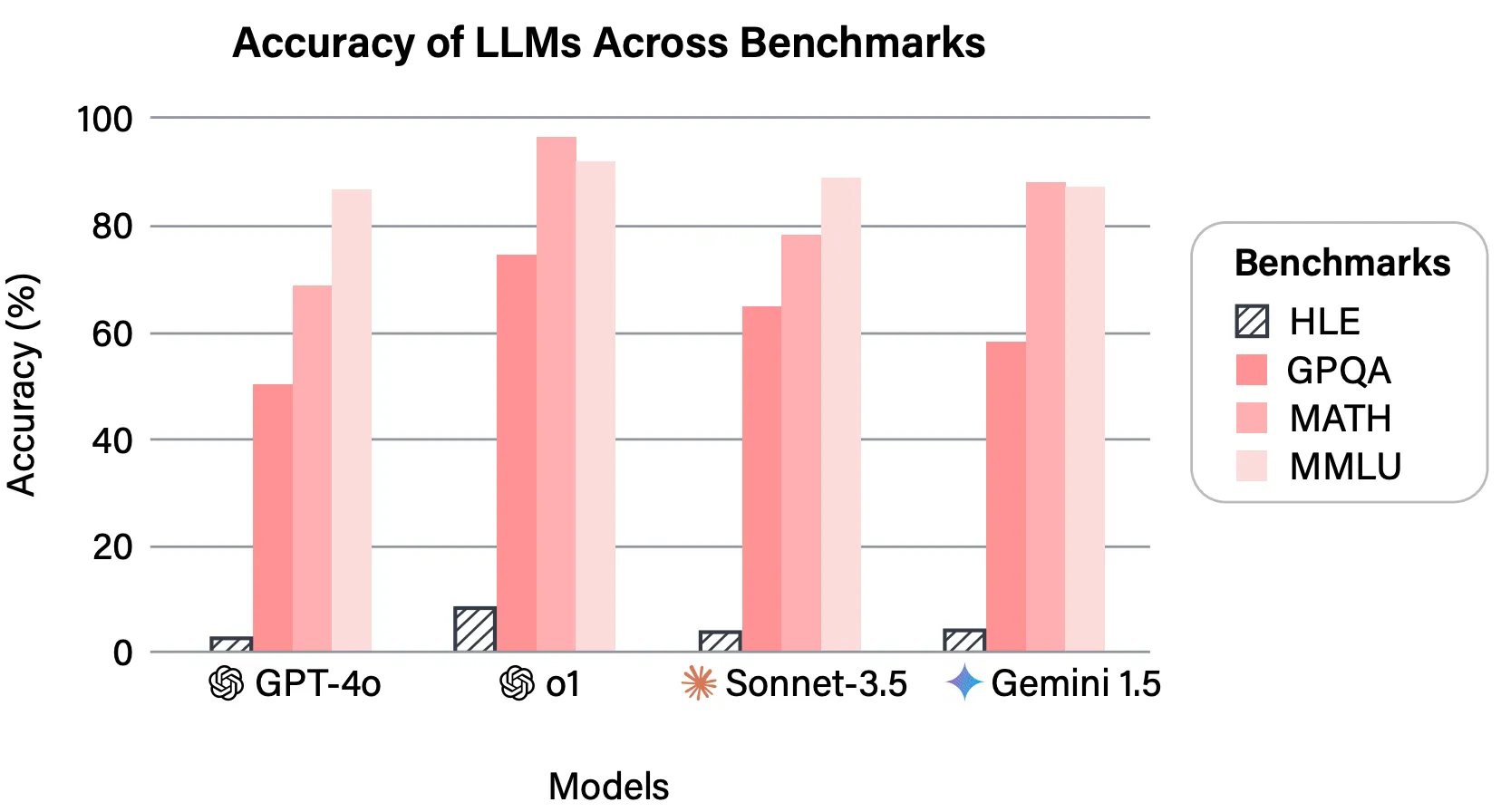
Als Grenzmodelle begannen, ältere Benchmarks zu sättigen, wurde HLE schnell zum neuen Referenzpunkt für Grenzen überschreiten!
Verwendet in: Grenzüberschreitende Argumentationsmodelle und LLMs auf Forschungsniveau (GPT-4, Claude Opus 4.5, Zwillinge Extremely)
Papier: https://arxiv.org/abs/2501.14249
Mathematische Argumentation: Kann es prozedural argumentieren?
Das Denken ist das, was den Menschen besonders macht, dh sowohl Gedächtnis als auch Lernen werden für Schlussfolgerungen genutzt. Diese Benchmarks testen den Erfolg der Argumentationsarbeit durch LLMs.
3. GSM8K – Grundschulmathematik (8.000 Probleme)
GSM8K testet, ob ein Modell Textaufgaben Schritt für Schritt lösen und nicht nur Antworten ausgeben kann. Stellen Sie sich eine Gedankenkette vor, doch statt die Bewertung anhand des Endergebnisses vorzunehmen, wird die gesamte Kette überprüft.
Es ist ganz einfach! Aber äußerst effektiv und schwer zu fälschen. Deshalb taucht es in quick jeder argumentationsorientierten Bewertung auf.
Verwendet in: Argumentationsfokussierte Sprachmodelle und Gedankenkettenmodelle (GPT-5, PalmeLLaMA)
Papier: https://arxiv.org/abs/2110.14168
4. MATH – Mathematikdatensatz für fortgeschrittene Problemlösung
Dieser Maßstab erhöht die Obergrenze. Probleme stammen aus der Wettbewerbsmathematik und erfordern Abstraktion, symbolische Manipulation und lange Argumentationsketten.
Die inhärente Schwierigkeit mathematischer Probleme hilft beim Testen der Fähigkeiten des Modells. Modelle, die bei GSM8K gute Ergebnisse erzielen, bei MATH jedoch zusammenbrechen, werden sofort angezeigt.
Verwendet in: Fortgeschrittenes Denken und mathematische LLMs (MinervaGPT-4, DeepSeek-Math)
Papier: https://arxiv.org/abs/2103.03874
Software program Engineering: Kann es menschliche Programmierer ersetzen?
Nur ein Scherz. Diese Benchmarks testen, wie intestine ein LLM fehlerfreien Code erstellt.
5. HumanEval – Benchmark zur menschlichen Bewertung für die Codegenerierung
HumanEval ist der am häufigsten zitierte Codierungs-Benchmark, den es gibt. Es bewertet Modelle danach, wie intestine sie Python-Funktionen schreiben, die versteckte Komponententests bestehen. Keine subjektive Wertung. Entweder funktioniert der Code oder nicht.
Wenn Sie auf einer Modellkarte einen Codierungs-Rating sehen, ist dies quick immer einer davon.
Verwendet in: Codegenerierungsmodelle (OpenAI Codex, CodeLLaMA, DeepSeek-Coder)
Papier: https://arxiv.org/abs/2107.03374
6. SWE-Bench – Software program-Engineering-Benchmark
SWE-Bench testet reale Technik, keine Spielzeugprobleme.
Modelle erhalten tatsächliche GitHub-Probleme und müssen Patches generieren, die diese in echten Repositorys beheben. Dieser Benchmark ist wichtig, weil er widerspiegelt, wie Menschen Codierungsmodelle tatsächlich verwenden möchten.
Verwendet in: Software program-Engineering und Agenten-Codierungsmodelle (Devin, SWE-Agent, AutoGPT)
Papier: https://arxiv.org/abs/2310.06770
Konversationsfähigkeit: Kann es sich menschlich verhalten?
Bei diesen Benchmarks wird getestet, ob das Modell über mehrere Runden hinweg arbeiten kann und wie intestine es im Vergleich zu einem Menschen abschneidet.
7. MT-Bench – Multi-Flip-Benchmark
MT-Bench bewertet, wie sich Modelle über mehrere Gesprächsrunden hinweg verhalten. Es testet Kohärenz, Befehlserhaltung, Argumentationskonsistenz und Ausführlichkeit.
Die Ergebnisse werden mithilfe von LLM als Richter erstellt, wodurch MT-Bench skalierbar genug wurde, um zu einem Normal-Chat-Benchmark zu werden.
Verwendet in: Chat-orientierte Gesprächsmodelle (ChatGPT, Claude, Gemini)
Papier: https://arxiv.org/abs/2306.05685
8. Chatbot Area – Benchmark für menschliche Vorlieben
Chatbot Area umgeht Metriken und lässt Menschen entscheiden.
Modelle werden in anonymen Kämpfen direkt miteinander verglichen und die Benutzer stimmen darüber ab, welche Antwort sie bevorzugen. Die Rankings werden anhand der Elo-Scores verwaltet.
Trotz des Lärms hat dieser Benchmark erhebliches Gewicht, da er die tatsächlichen Benutzerpräferenzen im großen Maßstab widerspiegelt.
Verwendet in: Alle wichtigen Chat-Modelle zur Bewertung menschlicher Präferenzen (ChatGPT, Claude, Gemini, Grok)
Papier: https://arxiv.org/abs/2403.04132
Informationsbeschaffung: Kann man einen Weblog schreiben?
Oder genauer: Kann es die richtigen Informationen finden, wenn es darauf ankommt?
9. BEIR – Benchmarking Data Retrieval
BEIR ist der Normal-Benchmark für die Bewertung von Retrieval- und Einbettungsmodellen.
Es aggregiert mehrere Datensätze aus Bereichen wie Qualitätssicherung, Faktenprüfung und wissenschaftlicher Recherche und ist damit die Standardreferenz für RAG-Pipelines.
Verwendet in: Abrufmodelle und Einbettungsmodelle (OpenAI text-embedding-3, BERTE5, GTE)
Papier: https://arxiv.org/abs/2104.08663
10. Nadel im Heuhaufen – Langkontext-Erinnerungstest
Dieser Benchmark testet, ob Lengthy-Context-Modelle tatsächlich funktionieren verwenden ihren Kontext.
Eine kleine, aber entscheidende Tatsache ist tief in einem langen Dokument vergraben. Das Modell muss es korrekt abrufen. Als die Kontextfenster größer wurden, wurde dies zum wichtigsten Gesundheitscheck.
Verwendet in: Langkontext-Sprachmodelle (Claude 3, GPT-4.1, Gemini 2.5)
Referenz-Repo: https://github.com/gkamradt/LLMTest_NeedleInAHaystack
Erweiterte Benchmarks
Dies sind nur die beliebtesten Benchmarks, die zur Bewertung von LLMs verwendet werden. Von dort, wo sie herkommen, gibt es weitaus mehr, und selbst diese wurden durch erweiterte Datensatzvarianten wie MMLU-Professional, GSM16K usw. ersetzt. Da Sie jedoch jetzt ein fundiertes Verständnis dafür haben, was diese Benchmarks darstellen, wäre es einfach, Verbesserungen umzusetzen.
Die oben genannten Informationen sollten als Referenz für die am häufigsten verwendeten LLM-Benchmarks verwendet werden.
Häufig gestellte Fragen
A. Sie messen, wie intestine Modelle im Vergleich zu Menschen bei Aufgaben wie Schlussfolgern, Codieren und Abrufen funktionieren.
A. Es handelt sich um einen allgemeinen Intelligenz-Benchmark, bei dem Sprachmodelle in Fächern wie Mathematik, Jura, Medizin und Geschichte getestet werden.
A. Es testet, ob Modelle echte GitHub-Probleme beheben können, indem sie korrekte Code-Patches generieren.
Ich bin auf die Überprüfung und Verfeinerung von KI-gestützter Forschung, technischer Dokumentation und Inhalten im Zusammenhang mit neuen KI-Technologien spezialisiert. Meine Erfahrung umfasst KI-Modelltraining, Datenanalyse und Informationsabruf und ermöglicht es mir, Inhalte zu erstellen, die sowohl technisch korrekt als auch zugänglich sind.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.