

Bild vom Herausgeber
# Einführung
Die explorative Datenanalyse (EDA) ist eine entscheidende Part vor tiefergehenden Datenanalyseprozessen oder dem Aufbau datengesteuerter KI-Systeme, beispielsweise solcher, die auf Modellen des maschinellen Lernens basieren. Während die Behebung allgemeiner, realer Datenqualitätsprobleme und Inkonsistenzen häufig auf nachfolgende Phasen der Datenpipeline verschoben wird, ist EDA auch eine ausgezeichnete Gelegenheit, diese Probleme proaktiv und frühzeitig zu erkennen – bevor unbemerkt Ergebnisse verzerrt, die Modellleistung beeinträchtigt oder die nachgelagerte Entscheidungsfindung beeinträchtigt wird.
Im Folgenden stellen wir eine Liste mit sieben Python-Methods zusammen, die auf Ihre frühen EDA-Prozesse anwendbar sind, insbesondere durch die effektive Identifizierung und Behebung einer Vielzahl von Datenqualitätsproblemen.
Um diese Methods zu veranschaulichen, verwenden wir einen synthetisch generierten Mitarbeiterdatensatz, in den wir absichtlich eine Vielzahl von Datenqualitätsproblemen einfügen, um zu veranschaulichen, wie diese erkannt und behandelt werden können. Bevor Sie die Methods ausprobieren, stellen Sie sicher, dass Sie zunächst den folgenden Präambelcode kopieren und in Ihre Codierungsumgebung einfügen:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# PREAMBLE CODE THAT RANDOMLY CREATES A DATASET AND INTRODUCES QUALITY ISSUES IN IT
np.random.seed(42)
n = 1000
df = pd.DataFrame({
"age": np.random.regular(40, 12, n).spherical(),
"earnings": np.random.regular(60000, 15000, n),
"experience_years": np.random.regular(10, 5, n),
"division": np.random.selection(
("Gross sales", "Engineering", "HR", "gross sales", "Eng", "HR "), n
),
"performance_score": np.random.regular(3, 0.7, n)
})
# Randomly injecting information points to the dataset
# 1. Lacking values
df.loc(np.random.selection(n, 80, substitute=False), "earnings") = np.nan
df.loc(np.random.selection(n, 50, substitute=False), "division") = np.nan
# 2. Outliers
df.loc(np.random.selection(n, 10), "earnings") *= 5
df.loc(np.random.selection(n, 10), "age") = -5
# 3. Invalid values
df.loc(np.random.selection(n, 15), "performance_score") = 7
# 4. Skewness
df("bonus") = np.random.exponential(2000, n)
# 5. Extremely correlated options
df("income_copy") = df("earnings") * 1.02
# 6. Duplicated entries
df = pd.concat((df, df.iloc(:20)), ignore_index=True)
df.head()# 1. Fehlende Werte mithilfe von Heatmaps erkennen
Zwar gibt es in Python-Bibliotheken Funktionen wie Pandas Die die Anzahl der fehlenden Werte für jedes Attribut in Ihrem Datensatz zählen. Ein attraktiver Ansatz, um einen schnellen Überblick über alle fehlenden Werte in Ihrem Datensatz zu erhalten – und darüber, welche Spalten oder Attribute welche enthalten – ist die Visualisierung einer Heatmap mithilfe von isnull() Funktion und zeichnet so weiße, barcodeähnliche Linien für jeden einzelnen fehlenden Wert in Ihrem gesamten Datensatz auf, horizontal nach Attributen angeordnet.
plt.determine(figsize=(10, 5))
sns.heatmap(df.isnull(), cbar=False)
plt.title("Lacking Worth Heatmap")
plt.present()
df.isnull().sum().sort_values(ascending=False)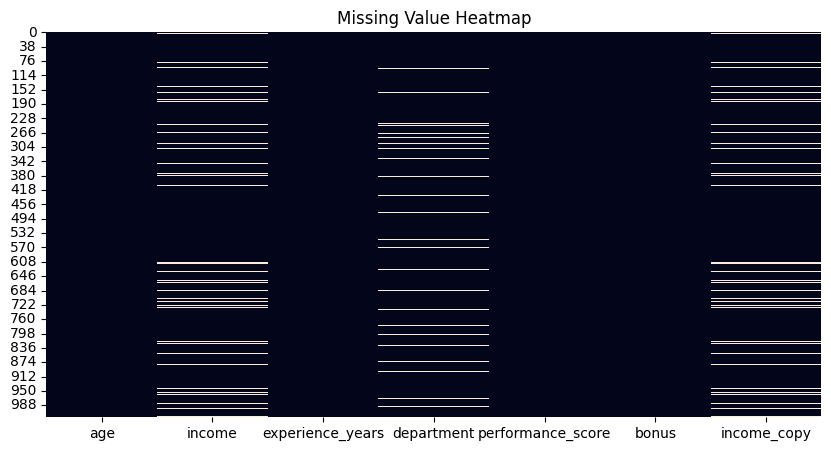
Heatmap zur Erkennung fehlender Werte | Bild vom Autor
# 2. Duplikate entfernen
Dieser Trick ist ein Klassiker: einfach, aber sehr effektiv, um die Anzahl der duplizierten Instanzen (Zeilen) in Ihrem Datensatz zu zählen und anschließend anzuwenden drop_duplicates() um sie zu entfernen. Standardmäßig behält diese Funktion das erste Vorkommen jeder duplizierten Zeile bei und eliminiert den Relaxation. Dieses Verhalten kann jedoch beispielsweise durch die Verwendung von geändert werden maintain="final" Possibility, das letzte Vorkommen anstelle des ersten beizubehalten, oder maintain=False loswerden alle komplett duplizierte Zeilen. Das zu wählende Verhalten hängt von Ihren spezifischen Problemanforderungen ab.
duplicate_count = df.duplicated().sum()
print(f"Variety of duplicate rows: {duplicate_count}")
# Take away duplicates
df = df.drop_duplicates()# 3. Identifizieren von Ausreißern mithilfe der Interquartilbereichsmethode
Die Interquartilbereichsmethode (IQR) ist ein statistikgestützter Ansatz zur Identifizierung von Datenpunkten, die aufgrund ihrer erheblichen Entfernung zu den übrigen Punkten als Ausreißer oder Extremwerte angesehen werden können. Dieser Trick stellt eine Implementierung der IQR-Methode bereit, die für verschiedene numerische Attribute wie „Einkommen“ repliziert werden kann:
def detect_outliers_iqr(information, column):
Q1 = information(column).quantile(0.25)
Q3 = information(column).quantile(0.75)
IQR = Q3 - Q1
decrease = Q1 - 1.5 * IQR
higher = Q3 + 1.5 * IQR
return information((information(column) < decrease) | (information(column) > higher))
outliers_income = detect_outliers_iqr(df, "earnings")
print(f"Revenue outliers: {len(outliers_income)}")
# Non-obligatory: cap them
Q1 = df("earnings").quantile(0.25)
Q3 = df("earnings").quantile(0.75)
IQR = Q3 - Q1
decrease = Q1 - 1.5 * IQR
higher = Q3 + 1.5 * IQR
df("earnings") = df("earnings").clip(decrease, higher)# 4. Inkonsistente Kategorien verwalten
Im Gegensatz zu Ausreißern, die normalerweise mit numerischen Merkmalen verbunden sind, können inkonsistente Kategorien in kategorialen Variablen auf verschiedene Faktoren zurückzuführen sein, z. B. manuelle Inkonsistenzen wie Groß- oder Kleinbuchstaben in Namen oder domänenspezifische Variationen. Daher könnte der richtige Ansatz für den Umgang mit ihnen teilweise Fachwissen erfordern, um über den richtigen Satz von Kategorien zu entscheiden, die als gültig erachtet werden. In diesem Beispiel wird die Verwaltung von Kategorieinkonsistenzen in Abteilungsnamen angewendet, die sich auf dieselbe Abteilung beziehen.
print("Earlier than cleansing:")
print(df("division").value_counts(dropna=False))
df("division") = (
df("division")
.str.strip()
.str.decrease()
.substitute({
"eng": "engineering",
"gross sales": "gross sales",
"hr": "hr"
})
)
print("nAfter cleansing:")
print(df("division").value_counts(dropna=False))# 5. Bereiche prüfen und validieren
Während es sich bei Ausreißern um statistisch weit entfernte Werte handelt, hängen ungültige Werte von domänenspezifischen Einschränkungen ab, z. B. können Werte für ein „Alter“-Attribut nicht negativ sein. In diesem Beispiel werden destructive Werte für das Attribut „Alter“ identifiziert und durch NaN ersetzt. Beachten Sie, dass diese ungültigen Werte in fehlende Werte umgewandelt werden und daher möglicherweise auch eine nachgelagerte Strategie für deren Handhabung erforderlich ist.
invalid_age = df(df("age") < 0)
print(f"Invalid ages: {len(invalid_age)}")
# Repair by setting to NaN
df.loc(df("age") < 0, "age") = np.nan# 6. Anwenden der Log-Transformation für verzerrte Daten
Verzerrte Datenattribute wie „Bonus“ in unserem Beispieldatensatz lassen sich normalerweise besser in etwas umwandeln, das einer Normalverteilung ähnelt, da dies die meisten nachgelagerten maschinellen Lernanalysen erleichtert. Dieser Trick wendet eine Protokolltransformation an und zeigt das Vorher und Nachher unserer Datenfunktion an.
skewness = df("bonus").skew()
print(f"Bonus skewness: {skewness:.2f}")
plt.hist(df("bonus"), bins=40)
plt.title("Bonus Distribution (Unique)")
plt.present()
# Log rework
df("bonus_log") = np.log1p(df("bonus"))
plt.hist(df("bonus_log"), bins=40)
plt.title("Bonus Distribution (Log Remodeled)")
plt.present()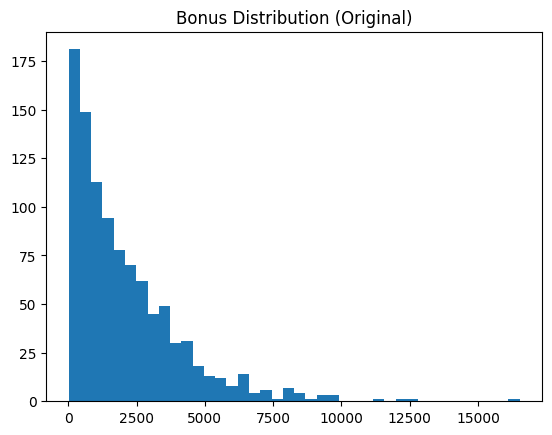
Vor der Log-Transformation | Bild vom Autor
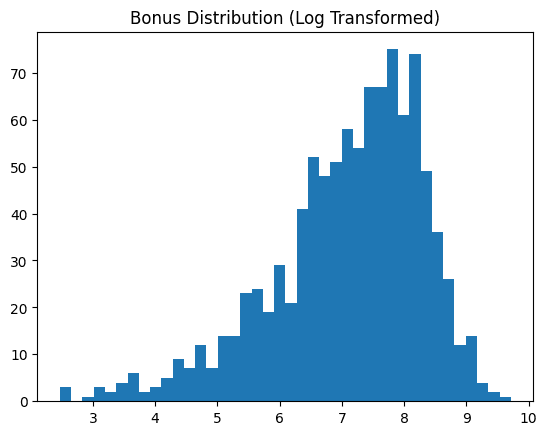
Nach der Log-Transformation | Bild vom Autor
# 7. Erkennen redundanter Merkmale mithilfe der Korrelationsmatrix
Wir schließen die Liste so ab, wie wir begonnen haben: mit einer visuellen Be aware. Als Heatmaps angezeigte Korrelationsmatrizen helfen dabei, schnell korrelierte Merkmalspaare zu identifizieren – ein starkes Zeichen dafür, dass sie möglicherweise redundante Informationen enthalten, die in der nachfolgenden Analyse häufig am besten minimiert werden. In diesem Beispiel werden zur besseren Interpretierbarkeit auch die fünf am höchsten korrelierten Attributpaare gedruckt:
corr_matrix = df.corr(numeric_only=True)
plt.determine(figsize=(10, 6))
sns.heatmap(corr_matrix, annot=True, fmt=".2f", cmap="coolwarm")
plt.title("Correlation Matrix")
plt.present()
# Discover excessive correlations
high_corr = (
corr_matrix
.abs()
.unstack()
.sort_values(ascending=False)
)
high_corr = high_corr(high_corr < 1)
print(high_corr.head(5))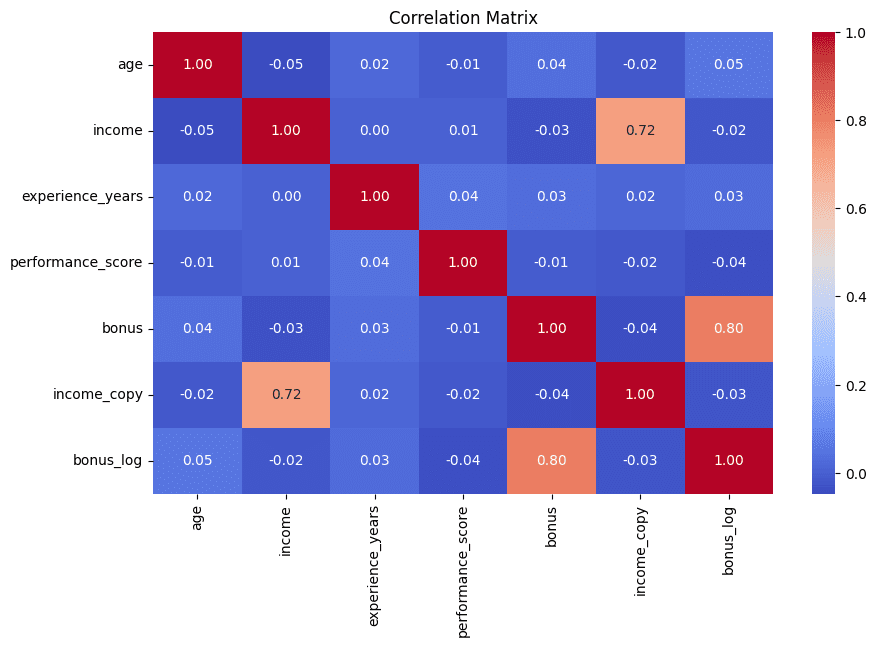
Korrelationsmatrix zur Erkennung redundanter Merkmale | Bild vom Autor
# Zusammenfassung
Mit der obigen Liste haben Sie sieben nützliche Methods kennengelernt, mit denen Sie Ihre explorative Datenanalyse optimum nutzen und dabei helfen können, verschiedene Arten von Datenqualitätsproblemen und Inkonsistenzen effektiv und intuitiv aufzudecken und zu beheben.
Iván Palomares Carrascosa ist ein führender Autor, Redner und Berater in den Bereichen KI, maschinelles Lernen, Deep Studying und LLMs. Er schult und leitet andere darin, KI in der realen Welt zu nutzen.