
Am meisten KI-Projekte Beginnen Sie mit einer lästigen Aufgabe: dem Bereinigen unordentlicher Dateien. PDFs, Phrase-Dokumente, PPTs, Bilder, Audiodateien und Tabellenkalkulationen müssen alle in sauberen Textual content umgewandelt werden, bevor sie nützlich werden können. Microsofts MarkItDown behebt dieses Downside endlich. In dieser Anleitung zeige ich Ihnen, wie Sie es installieren, jeden wichtigen Dateityp in Markdown konvertieren, OCR für Bilder ausführen, Audio transkribieren, Inhalte aus ZIPs extrahieren und mit nur wenigen Codezeilen sauberere Pipelines für Ihre LLM-Workflows erstellen.
Warum ist MarkItDown wichtig?
Bevor wir uns mit den praktischen Beispielen befassen, ist es hilfreich zu verstehen, wie MarkItDown tatsächlich verschiedene Dateien in sauberes Markdown konvertiert. Die Bibliothek behandelt nicht jedes Format gleich. Stattdessen kommt ein intelligenter zweistufiger Prozess zum Einsatz.
Zunächst wird jeder Dateityp mit dem für ihn am besten geeigneten Software analysiert. Phrase-Dokumente durchlaufen Mammut, Excel-Tabellen durchlaufen Pandas und PowerPoint-Folien durchlaufen Python-PPTX. Alle werden in strukturiertes HTML umgewandelt.
Zweitens wird dieser HTML-Code mithilfe von BeautifulSoup bereinigt und in Markdown umgewandelt. Dadurch wird sichergestellt, dass die endgültige Ausgabe Überschriften, Hear, Tabellen und die logische Struktur intakt behält.
Sie können das Bild hier hinzufügen, um den Ablauf zu verdeutlichen:
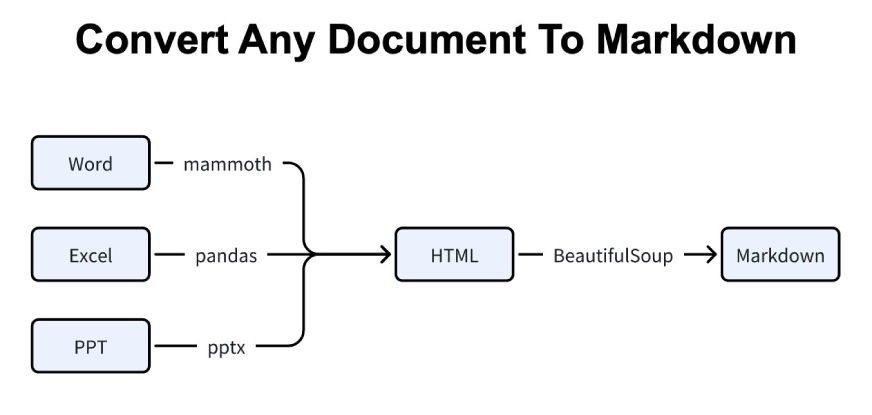
MarkItDown folgt dieser Pipeline jedes Mal, wenn Sie eine Konvertierung durchführen, unabhängig davon, wie chaotisch das Originaldokument ist.
Lesen Sie mehr darüber in unserem vorherigen Artikel über Wie verwende ich MarkItDown MCP, um die Dokumente in Markdowns umzuwandeln?
Set up und Einrichtung von Microsofts MarkItDown
Zum Starten sind eine Python-Umgebung und Pip erforderlich. Sie benötigen außerdem einen offenen AI-API-Schlüssel, falls Sie Bilder oder Audio verarbeiten möchten.
In jedem Terminal installiert der folgende Befehl die MarkItDown-Python-Bibliothek:
!pip set up markitdown(all) Es ist besser, eine virtuelle Umgebung einzurichten, um Konflikte mit anderen Projekten zu vermeiden.
# Create a digital atmosphere
python -m venv venv
# Activate it (Home windows)
venvScriptsactivate
# Activate it (Mac/Linux)
supply venv/bin/activate Importieren Sie die Bibliothek nach der Set up in Python, um sie zu testen. Sie können nun Dateien in Markdown konvertieren
8 Dinge, die Sie mit der MarkItDown-Bibliothek von Microsoft tun können
MarkItDown unterstützt die meisten Formate. Dies sind Beispiele für die Verwendung bei allgemeinen Dateien.
Aufgabe 1: Konvertieren von MS Phrase-Dokumenten
Phrase-Dokumente enthalten häufig Überschriften, fetten Textual content und Hear. MarkItDown behält diese Formatierung während der Konvertierung bei.
from markitdown import MarkItDown
md = MarkItDown()
res = md.convert("/content material/test-sample.docx")
print(res.text_content) Ausgabe:
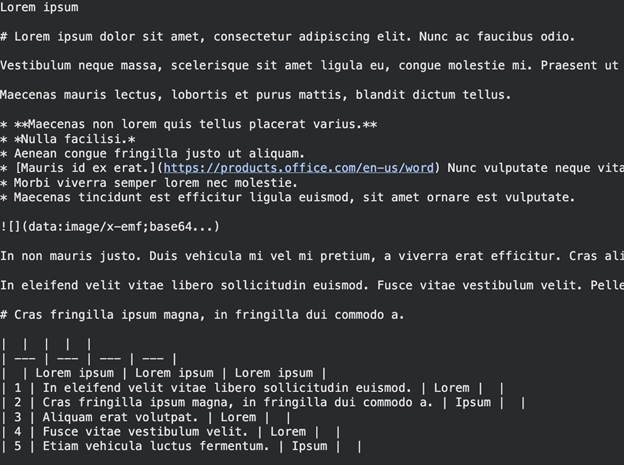
Sie finden den Markdown-Textual content. Überschriften werden durch die Buchstaben # und Hear durch * gekennzeichnet. Diese Type der Struktur hilft den LLMs, die Struktur Ihrer Arbeit zu verstehen.
Datenanalysten benötigen regelmäßig Excel-Daten. Es handelt sich um ein Dokumentkonvertierungstool, das Tabellenkalkulationen in saubere Markdown-Tabellen konvertieren kann.
from markitdown import MarkItDown
md = MarkItDown()
end result = md.convert("/content material/file_example_XLS_10.xls")
print(end result.text_content) Ausgabe:
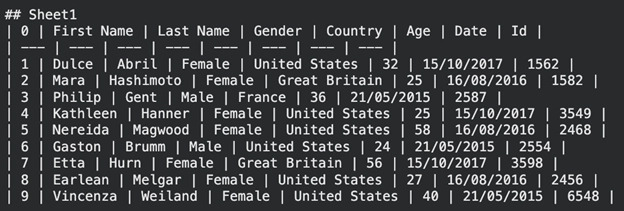
Die Informationen werden in Type einer Markdown-Tabelle dargestellt. Dieses Format ist sowohl für Menschen als auch für KI-Modelle nicht schwer zu interpretieren.
Aufgabe 3: PowerPoint-Folien in Clear Markdown umwandeln
Folienstapel enthalten nützliche Zusammenfassungen. Dieser Textual content kann extrahiert werden, um Daten zu erstellen, die in LLM-Zusammenfassungsaufgaben verwendet werden.
from markitdown import MarkItDown
md = MarkItDown()
end result = md.convert("/content material/file-sample.pptx")
print(end result.text_content) Ausgabe:
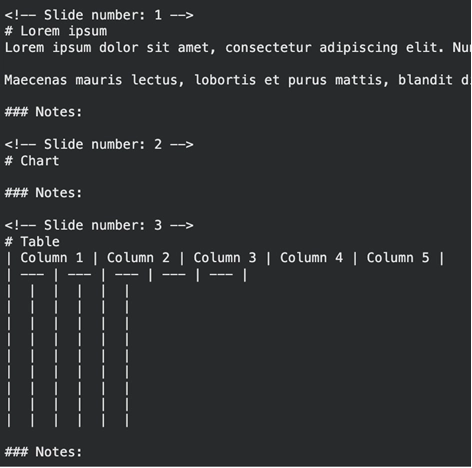
Das Software erfasst Aufzählungspunkte und Folientitel, getrennt nach Foliennummer. Es ignoriert komplizierte Layoutfunktionen, die dazu führen, dass Textparser verloren gehen.
Aufgabe 4: PDFs in strukturierten Markdown analysieren
Das PDF ist äußerst schwer zu entschlüsseln. MarkItDown erleichtert diesen Prozess.
from markitdown import MarkItDown
md = MarkItDown()
end result = md.convert("/content material/1706.03762.pdf")
print(end result.text_content) Ausgabe:
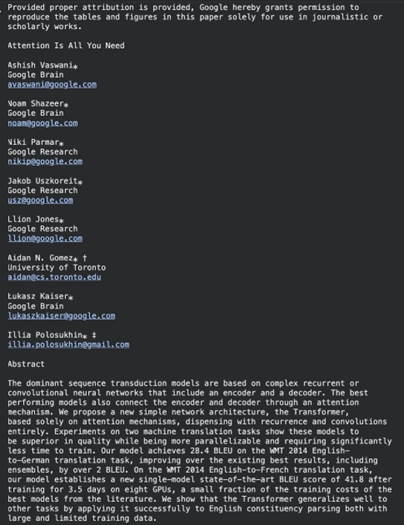
Es extrahiert den Textual content mit der Formatierung abschnittsweise. Die Bibliothek kann auch mit OCR-Instruments kombiniert werden, wenn komplexe PDFs gescannter Dokumente verwendet werden.
Aufgabe 5: Textual content aus Bildern mithilfe von OCR generieren
Die MarkItDown-Python-Bibliothek ist in der Lage, Bilder zu beschreiben, falls Sie sie einem multimodalen LLM zuordnen. Dabei handelt es sich um eine LLC-Kundenvereinbarung.
from markitdown import MarkItDown
from openai import OpenAI
from google.colab import userdata
shopper = OpenAI(api_key=userdata.get('OPENAI_KEY'))
md = MarkItDown(llm_client=shopper, llm_model="gpt-4o-mini")
end result = md.convert("/content material/Screenshot 2025-12-03 at 5.46.29 PM.png")
print(end result.text_content) Ausgabe:

Das Modell erstellt eine beschreibende Bildunterschrift oder einen Textual content, der im Bild sichtbar ist.
Aufgabe 6: Audiodateien in Markdown transkribieren
Sie können sogar Audiodateien in Textual content umwandeln. Es verfügt über diese Funktion über Sprachtranskription.
from markitdown import MarkItDown
from openai import OpenAI
md = MarkItDown(llm_client=shopper, llm_model="gpt-4o-mini")
end result = md.convert("/content material/speech.mp3")
print(end result.text_content) Ausgabe:

Eine Texttranskription der Audiodatei im Markdown-Format.
Aufgabe 7: Mehrere Dateien in ZIP-Archiven verarbeiten
MarkItDown kann ganze Archive gleichzeitig verarbeiten, sofern Sie über eine ZIP-Datei mit Dokumenten verfügen.
from markitdown import MarkItDown
md = MarkItDown()
end result = md.convert("/content material/test-sample.zip")
print(end result.text_content) Ausgabe:
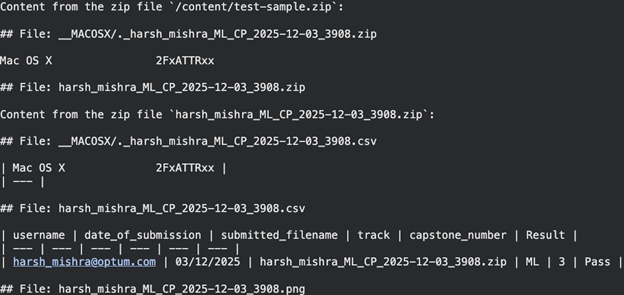
Die Anwendung vereinheitlicht den Inhalt aller unterstützten Dateien in einer ZIP-Datei in einer einzigen Markdown-Ausgabe. Es extrahiert auch den Inhalt der CSV-Datei und konvertiert ihn in Markdown.
Aufgabe 8: Umgang mit HTML und textbasierten Formaten
Webseiten und Datendateien wie CSVs lassen sich einfach in Markdown konvertieren.
from markitdown import MarkItDown
md = MarkItDown()
end result = md.convert("/content material/sample1.html")
print(end result.text_content) Ausgabe:
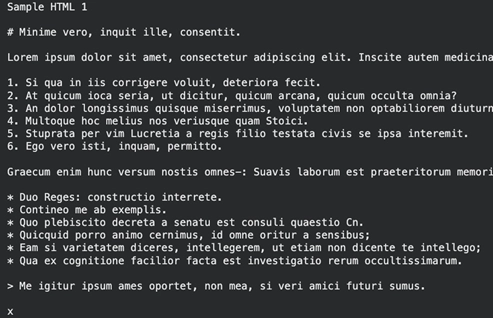
Verarbeiten Sie mehrere Dateien in ZIP-Archiven
Clear Markdown, der Hyperlinks und Header aus dem HTML beibehält.
Erweiterte Tipps und Fehlerbehebung
Beachten Sie die folgenden Tipps, um mit diesem Dokumentkonvertierungstool die besten Ergebnisse zu erzielen:
Wählen Sie 77 weitere Wörter aus, um Humanizer auszuführen.
- Optimierung der Ausgabe: Das Flag -o kann in der Befehlszeile zum Speichern in einer Datei verwendet werden.
- Große Dateien: Die Verarbeitung großer Dateien kann zeitaufwändig sein. Stellen Sie sicher, dass in Ihrem Gerät ausreichend Speicherkapazität vorhanden ist.
- API-Fehler: API-Schlüssel und Internetproblem: Bei Problemen mit der Bild-/Audiokonvertierung überprüfen Sie den API-Schlüssel und die Internetverbindung.
- Unterstützte Formate: Erfassen Sie einen Fehler: Sehen Sie sich die GitHub-Problemseite an. Die Gesellschaft ist engagiert und unterstützend.
Noch weiter gehen: Aufbau einer KI-Pipeline
MarkItDown fungiert als solide Grundlage für KI-Workflows. Sie können es mit Instruments wie LangChain integrieren, um leistungsstarke KI-Anwendungen zu erstellen. Beim Coaching von LLMs sind qualitativ hochwertige Daten wichtig. Die Open-Supply-Instruments von Microsoft helfen Ihnen, saubere Eingabedaten beizubehalten, was zu genaueren und zuverlässigeren KI-Antworten führt.
Abschluss
Die MarkItDown-Python-Bibliothek ist ein Durchbruch bei der Datenaufbereitung. Es ermöglicht Ihnen, Dateien mit geringstem Aufwand in Markdown zu konvertieren. Es verarbeitet einfache Texte zu Multimedia. Auch die Open-Supply-Instruments von Microsoft verbessern das Entwicklererlebnis. Dies ist ein Dokumentkonvertierungstool, das in Ihrem Toolkit enthalten sein muss, falls Sie mit LLMs arbeiten. Probieren Sie die obigen Beispiele aus. Treten Sie der Neighborhood auf GitHub bei. Natürlich bereiten Sie Daten in kürzester Zeit auf die Arbeitsabläufe von LLM vor.
Häufig gestellte Fragen
A. Ja. Microsoft verwaltet es als Open-Supply-Bibliothek und Sie können es kostenlos mit pip installieren.
A. Es unterstützt am besten Textual content-PDFs, kann aber auch mit gescannten Bildern arbeiten, sofern Sie es mit einem LLM-Consumer für OCR einrichten.
A. Nein. MarkItDown benötigt einen API-Schlüssel nur für Bild- und Audiokonvertierungen. Es konvertiert textbasierte Dateien lokal ohne API-Schlüssel.
A. Die Set up der Bibliothek bedeutet auch, dass ein Befehlszeilentool zum Einfügen schneller Dateikonvertierungen verfügbar ist.
A. Es unterstützt PDF, Docx, PPTX, XLSX, Bilder, Audio, HTML, CSV, JSON, ZIP und YouTube-URLs.
Harsh Mishra ist ein KI/ML-Ingenieur, der mehr Zeit damit verbringt, mit großen Sprachmodellen zu sprechen als mit echten Menschen. Leidenschaftlich für GenAI, NLP und die intelligentere Entwicklung von Maschinen (damit sie ihn noch nicht ersetzen). Wenn er nicht gerade Modelle optimiert, optimiert er wahrscheinlich seinen Kaffeekonsum. 🚀☕
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.