Context Engineering in 3 Schwierigkeitsgraden erklärt | Bild vom Autor
# Einführung
LLM-Anwendungen (Massive Language Mannequin) stoßen ständig an die Grenzen des Kontextfensters. Das Modell vergisst frühere Anweisungen, verliert den Überblick über relevante Informationen oder nimmt mit zunehmender Interaktionszeit an Qualität ab. Dies liegt daran, dass LLMs feste Token-Budgets haben, Anwendungen jedoch unbegrenzte Informationen generieren – Konversationsverlauf, abgerufene Dokumente, Datei-Uploads, Antworten der Anwendungsprogrammierschnittstelle (API) und Benutzerdaten. Ohne Administration werden wichtige Informationen willkürlich abgeschnitten oder überhaupt nicht in den Kontext einbezogen.
Context Engineering behandelt das Kontextfenster als verwaltete Ressource mit expliziten Zuordnungsrichtlinien und Speichersystemen. Sie entscheiden, welche Informationen wann in den Kontext gelangen, wie lange sie bleiben und was zum Abruf komprimiert oder im externen Speicher archiviert wird. Dies orchestriert den Informationsfluss über die gesamte Laufzeit der Anwendung, anstatt zu hoffen, dass alles passt, oder Leistungseinbußen in Kauf zu nehmen.
In diesem Artikel wird das Kontext-Engineering auf drei Ebenen erläutert:
- Verständnis der grundlegenden Notwendigkeit des Kontext-Engineerings
- Umsetzung praktischer Optimierungsstrategien in Produktionssystemen
- Überprüfung fortgeschrittener Speicherarchitekturen, Abrufsysteme und Optimierungstechniken
In den folgenden Abschnitten werden diese Ebenen im Element erläutert.
# Ebene 1: Den Kontextengpass verstehen
LLMs haben feste Kontextfenster. Alles, was das Modell zum Zeitpunkt der Inferenz weiß, muss in diese Token passen. Bei Single-Flip-Abschlüssen stellt dies kein großes Drawback dar. Für RAG-Anwendungen (Retrieval-Augmented Technology) und KI-Agenten, die mehrstufige Aufgaben mit Toolaufrufen, Datei-Uploads, Konversationsverlauf und externen Daten ausführen, entsteht ein Optimierungsproblem: Welche Informationen erhalten Aufmerksamkeit und welche werden verworfen?
Angenommen, Sie haben einen Agenten, der mehrere Schritte ausführt, 50 API-Aufrufe durchführt und 10 Dokumente verarbeitet. Ein solches Agenten-KI-System wird ohne explizites Kontextmanagement höchstwahrscheinlich scheitern. Das Modell vergisst wichtige Informationen, halluziniert Werkzeugausgaben oder nimmt mit zunehmender Gesprächsdauer an Qualität ab.
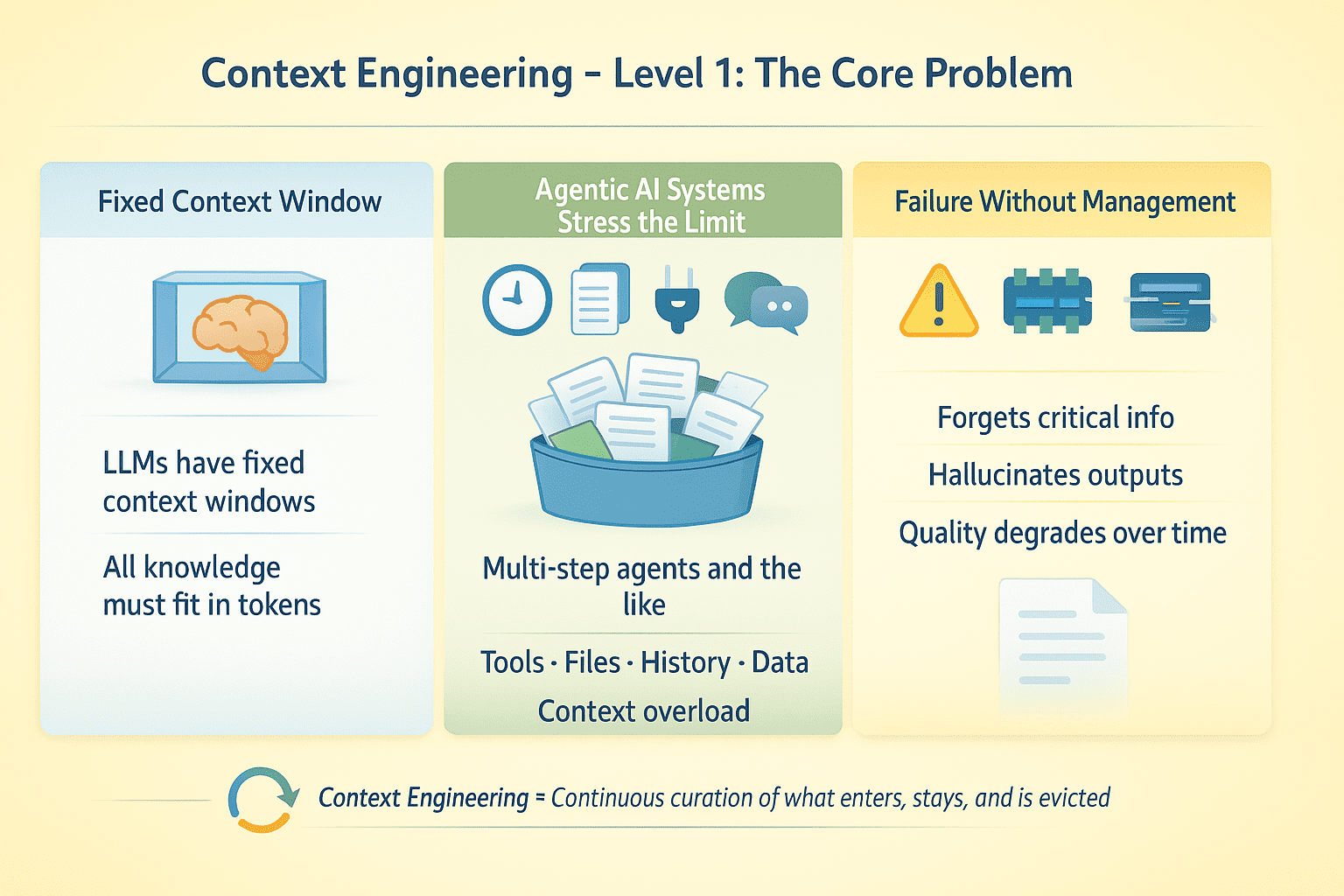
Kontext-Engineering Degree 1 | Bild vom Autor
Beim Context Engineering geht es um das Entwerfen für Kontinuierliche Pflege der Informationsumgebung rund um ein LLM während seiner Ausführung. Dazu gehört die Verwaltung, was wann und für wie lange in den Kontext gelangt und was entfernt wird, wenn der Platz knapp wird.
# Ebene 2: Kontext in der Praxis optimieren
Effektives Context Engineering erfordert explizite Strategien über mehrere Dimensionen hinweg.
// Budgetierungstoken
Ordnen Sie Ihr Kontextfenster bewusst zu. Systemanweisungen erfordern möglicherweise 2K-Token. Gesprächsverlauf, Software-Schemata, abgerufene Dokumente und Echtzeitdaten können sich schnell summieren. Mit einem sehr großen Kontextfenster gibt es viel Spielraum. Bei einem viel kleineren Zeitfenster sind Sie gezwungen, harte Kompromisse darüber einzugehen, was Sie behalten und was Sie löschen möchten.
// Gespräche abkürzen
Behalten Sie aktuelle Wendungen bei, lassen Sie mittlere Wendungen weg und behalten Sie den kritischen frühen Kontext bei. Die Zusammenfassung funktioniert, verliert jedoch an Genauigkeit. Einige Systeme implementieren semantische Komprimierung – das Extrahieren wichtiger Fakten, statt den wörtlichen Textual content beizubehalten. Testen Sie, wo Ihr Agent bei längeren Gesprächen Pausen einlegt.
// Werkzeugausgaben verwalten
Große API-Antworten verbrauchen Token schnell. Fordern Sie bestimmte Felder anstelle vollständiger Nutzdaten an, kürzen Sie die Ergebnisse, fassen Sie sie zusammen, bevor Sie zum Modell zurückkehren, oder verwenden Sie Multi-Go-Strategien, bei denen der Agent zunächst Metadaten erhält und dann nur Particulars für relevante Elemente anfordert.
// Verwendung des Mannequin Context Protocol und On-Demand-Abruf
Anstatt alles im Voraus zu laden, verbinden Sie das Modell mit externen Datenquellen, die es bei Bedarf abfragt Modellkontextprotokoll (MCP). Der Agent entscheidet anhand der Aufgabenanforderungen, was abgerufen werden soll. Dadurch verlagert sich das Drawback von „alles in den Kontext einpassen“ hin zu „die richtigen Dinge zur richtigen Zeit abrufen“.
// Strukturierte Zustände trennen
Fügen Sie stabile Anweisungen in Systemnachrichten ein. Fügen Sie variable Daten in Benutzernachrichten ein, wo sie aktualisiert oder entfernt werden können, ohne Kernanweisungen zu berühren. Behandeln Sie den Gesprächsverlauf, die Software-Ausgaben und die abgerufenen Dokumente als separate Streams mit unabhängigen Verwaltungsrichtlinien.
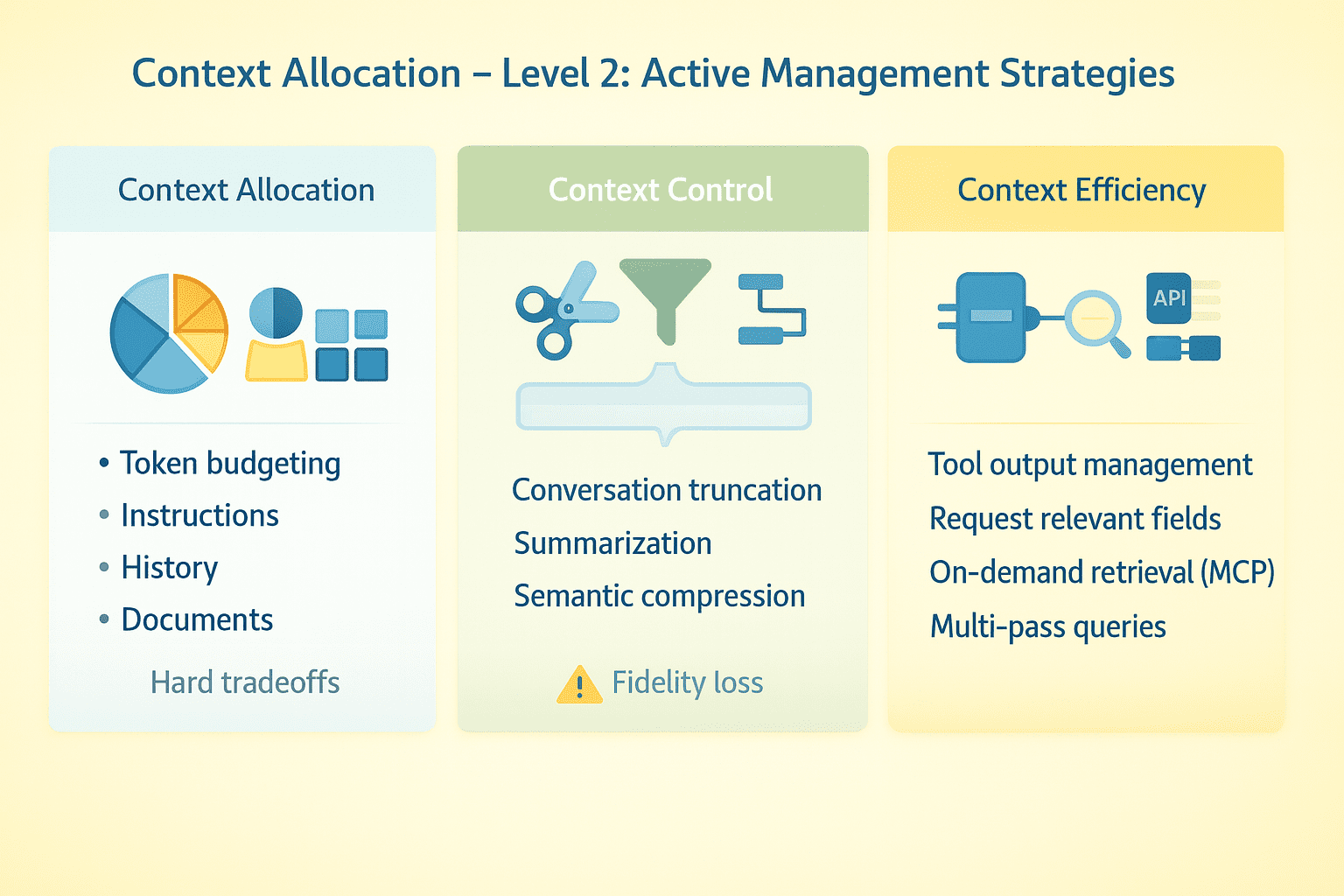
Kontext-Engineering Degree 2 | Bild vom Autor
Der praktische Wandel besteht hier darin, den Kontext als zu behandeln dynamische Ressource, die während der gesamten Laufzeit eines Agenten eine aktive Verwaltung erfordertkeine statische Sache, die Sie einmal konfigurieren.
# Ebene 3: Kontext-Engineering in der Produktion implementieren
Kontext-Engineering im großen Maßstab erfordert ausgefeilte Speicherarchitekturen, Komprimierungsstrategien und Abrufsysteme, die zusammenarbeiten. Hier erfahren Sie, wie Sie Implementierungen in Produktionsqualität erstellen.
// Entwerfen von Speicherarchitekturmustern
Separate Speicher in Agenten-KI-Systemen in Stufen:
- Arbeitsspeicher (aktives Kontextfenster)
- Episodisches Gedächtnis (komprimierter Gesprächsverlauf und Aufgabenstatus)
- Semantisches Gedächtnis (Fakten, Dokumente, Wissensbasis)
- Prozedurales Gedächtnis (Anweisungen)
Das Modell sieht jetzt den Arbeitsspeicher, der für unmittelbare Aufgabenanforderungen optimiert werden soll. Das episodische Gedächtnis speichert, was passiert ist. Sie können aggressiv komprimieren, aber zeitliche Beziehungen und Kausalketten bewahren. Speichern Sie für das semantische Gedächtnis Indizes nach Thema, Entität und Relevanz für einen schnellen Abruf.
// Anwenden von Kompressionstechniken
Durch eine naive Zusammenfassung gehen wichtige Particulars verloren. Ein besserer Ansatz ist die extraktive Komprimierung, bei der Sie Sätze mit hoher Informationsdichte identifizieren und bewahren und gleichzeitig Füllmaterial verwerfen.
- Extrahieren Sie für Software-Ausgaben strukturierte Daten (Entitäten, Metriken, Beziehungen) anstelle von Prosa-Zusammenfassungen.
- Behalten Sie bei Gesprächen die Benutzerabsichten und Agentenverpflichtungen genau bei und komprimieren Sie gleichzeitig die Argumentationsketten.
// Entwerfen von Abrufsystemen
Wenn das Modell Informationen benötigt, die nicht im Kontext stehen, entscheidet die Abrufqualität über den Erfolg. Hybridsuche implementieren: dichte Einbettungen für semantische Ähnlichkeit, BM25 für Key phrase-Matchingund Metadatenfilter für Präzision.
Ordnen Sie die Ergebnisse nach Aktualität, Relevanz und Informationsdichte. Rückkehr nach oben Ok aber auch Beinaheunfälle an der Oberfläche; Das Modell sollte wissen, was quick übereinstimmte. Der Abruf erfolgt im Kontext, sodass das Modell die Abfrageformulierung und die Ergebnisse sieht. Schlechte Abfragen führen zu schlechten Ergebnissen. Legen Sie dies offen, um eine Selbstkorrektur zu ermöglichen.
// Optimierung auf Token-Ebene
Erstellen Sie kontinuierlich ein Profil Ihrer Token-Nutzung.
- Systemanweisungen verbrauchen 5.000 Token, die 1.000 sein könnten? Schreiben Sie sie um.
- Software-Schemata ausführlich? Kompakt verwenden
JSONSchemata statt vollständigOpenAPISpezifikationen. - Konversation führt dazu, dass ähnliche Inhalte wiederholt werden? Deduplizieren.
- Abgerufene Dokumente überschneiden sich? Vor dem Hinzufügen zum Kontext zusammenführen.
Jeder gespeicherte Token ist ein Token, der für aufgabenkritische Informationen verfügbar ist.
// Speicherabruf auslösen
Das Modell sollte nicht ständig abrufen; es ist teuer und erhöht die Latenz. Implementieren Sie intelligente Set off: Rufen Sie ab, wenn das Modell explizit Informationen anfordert, wenn Wissenslücken erkannt werden, wenn Aufgabenwechsel auftreten oder wenn der Benutzer auf früheren Kontext verweist.
Wenn der Abruf nichts Nützliches zurückgibt, sollte das Modell dies explizit wissen und nicht halluzinieren. Geben Sie leere Ergebnisse mit Metadaten zurück: „Keine Dokumente gefunden, die der Abfrage entsprechen X in der Wissensdatenbank Y.“ Dadurch kann das Modell die Strategie anpassen, indem es die Abfrage neu formuliert, eine andere Quelle durchsucht oder den Benutzer darüber informiert, dass Informationen nicht verfügbar sind.
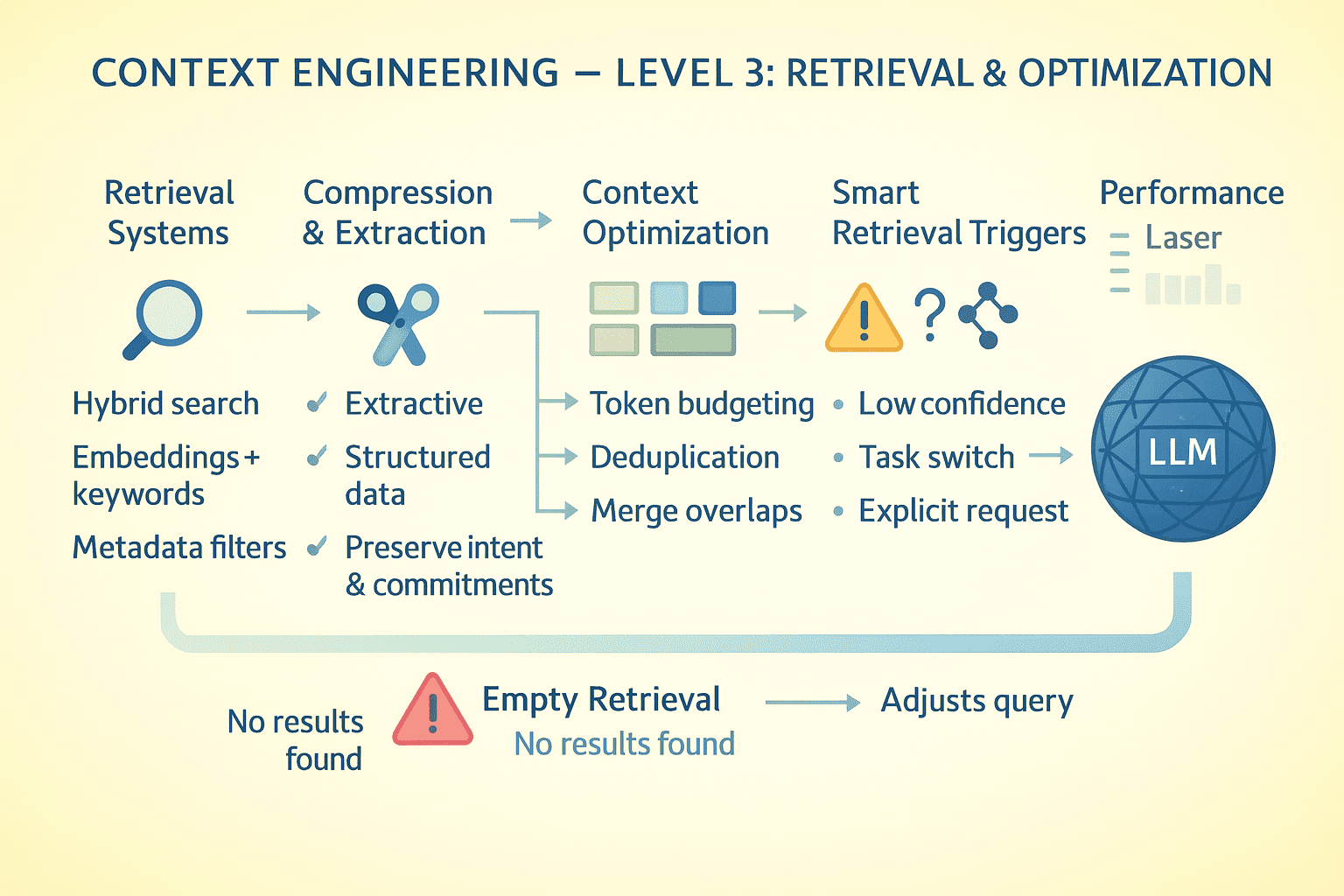
Kontext-Engineering Degree 3 | Bild vom Autor
// Synthetisieren von Informationen aus mehreren Dokumenten
Wenn die Argumentation mehrere Quellen erfordert, verarbeiten Sie sie hierarchisch.
- Erster Durchgang: Extrahieren Sie wichtige Fakten aus jedem Dokument unabhängig (parallelierbar).
- Zweiter Durchgang: Extrahierte Fakten in Kontext laden und synthetisieren.
Dies vermeidet eine Kontexterschöpfung durch das Laden von 10 vollständigen Dokumenten und bewahrt gleichzeitig die Fähigkeit zur Argumentation aus mehreren Quellen. Behalten Sie bei widersprüchlichen Quellen den Widerspruch bei. Lassen Sie das Modell widersprüchliche Informationen sehen und lösen oder sie zur Aufmerksamkeit des Benutzers kennzeichnen.
// Anhaltender Gesprächszustand
Für Agenten, die anhalten und fortfahren, serialisieren Sie den Kontextstatus in den externen Speicher. Speichern Sie den komprimierten Gesprächsverlauf, das aktuelle Aufgabendiagramm, die Software-Ausgaben und den Abruf-Cache. Rekonstruieren Sie im Lebenslauf den minimal notwendigen Kontext; Laden Sie nicht alles neu.
// Leistung bewerten und messen
Verfolgen Sie wichtige Kennzahlen, um zu verstehen, wie Ihre Context-Engineering-Strategie funktioniert. Überwachen Sie die Kontextnutzung, um den durchschnittlichen Prozentsatz der verwendeten Fenster zu sehen, und die Entfernungshäufigkeit, um zu verstehen, wie oft Sie auf Kontextgrenzen stoßen. Messen Sie die Abrufgenauigkeit, indem Sie prüfen, welcher Anteil der abgerufenen Dokumente tatsächlich related ist und verwendet wird. Verfolgen Sie schließlich die Informationspersistenz, um zu sehen, wie viele Umdrehungen wichtige Fakten überleben, bevor sie verloren gehen.
# Zusammenfassung
Beim Context Engineering geht es letztendlich um Informationsarchitektur. Sie bauen ein System auf, in dem das Modell Zugriff auf alles in seinem Kontextfenster hat und keinen Zugriff auf alles, was nicht. Jede Entwurfsentscheidung – was komprimiert, was abgerufen, was zwischengespeichert und was verworfen werden soll – erstellt die Informationsumgebung, in der Ihre Anwendung ausgeführt wird.
Wenn Sie sich nicht auf das Kontext-Engineering konzentrieren, kann es sein, dass Ihr System halluziniert, wichtige Particulars vergisst oder mit der Zeit zusammenbricht. Wenn Sie es richtig machen, erhalten Sie eine LLM-Anwendung, die trotz der zugrunde liegenden architektonischen Einschränkungen auch bei komplexen, ausgedehnten Interaktionen kohärent, zuverlässig und effektiv bleibt.
Viel Spaß beim Context Engineering!
# Referenzen und weiteres Lernen
Bala Priya C ist ein Entwickler und technischer Redakteur aus Indien. Sie arbeitet gerne an der Schnittstelle von Mathematik, Programmierung, Datenwissenschaft und Inhaltserstellung. Zu ihren Interessen- und Fachgebieten gehören DevOps, Datenwissenschaft und Verarbeitung natürlicher Sprache. Sie liebt es zu lesen, zu schreiben, zu programmieren und Kaffee zu trinken! Derzeit arbeitet sie daran, zu lernen und ihr Wissen mit der Entwickler-Neighborhood zu teilen, indem sie Tutorials, Anleitungen, Meinungsbeiträge und mehr verfasst. Bala erstellt außerdem ansprechende Ressourcenübersichten und Programmier-Tutorials.