Bild vom Autor
# Einführung
Künstliche Intelligenz (KI) bedeutete jahrzehntelang Textual content. Sie haben eine Frage eingegeben und eine Textantwort erhalten. Auch als die Sprachmodelle immer leistungsfähiger wurden, blieb die Benutzeroberfläche dieselbe: ein Textfeld, das auf Ihre sorgfältig gestaltete Eingabeaufforderung wartet.
Das ändert sich. Die leistungsfähigsten KI-Systeme von heute lesen nicht nur. Sie sehen Bilder, hören Sprache, verarbeiten Movies und verstehen strukturierte Daten. Dies ist kein inkrementeller Fortschritt; Es ist ein grundlegender Wandel in der Artwork und Weise, wie wir mit KI-Anwendungen interagieren und diese erstellen.
Willkommen bei multimodaler KI.
Die eigentliche Auswirkung besteht nicht nur darin, dass Modelle mehr Datentypen verarbeiten können. Es ist so, dass ganze Arbeitsabläufe zusammenbrechen. Aufgaben, die früher mehrere Konvertierungsschritte erforderten – Bild in Textbeschreibung, Sprache in Transkription, Diagramm in Erklärung – werden jetzt direkt ausgeführt. KI versteht Informationen in ihrer nativen Kind und eliminiert die Übersetzungsebene, die jahrzehntelang die Mensch-Laptop-Interaktion definiert hat.
# Definition multimodaler künstlicher Intelligenz: Von der Single-Sense- zur Multi-Sense-Intelligenz
Unter multimodaler KI versteht man Systeme, die mehrere Arten von Daten (Modalitäten) gleichzeitig verarbeiten und generieren können. Dazu gehören nicht nur Textual content, sondern auch Bilder, Audio, Video und zunehmend auch 3D-Geodaten, strukturierte Datenbanken und domänenspezifische Formate wie molekulare Strukturen oder Musiknotation.
Der Durchbruch bestand nicht nur darin, die Modelle größer zu machen. Es ging darum, verschiedene Arten von Daten in einem gemeinsamen „Verständnisraum“ darzustellen, in dem sie interagieren können. Ein Bild und seine Bildunterschrift sind keine getrennten Dinge, die zufällig miteinander verbunden sind; Sie sind unterschiedliche Ausdrücke desselben zugrunde liegenden Konzepts, abgebildet in einer gemeinsamen Darstellung.
Dadurch entstehen Fähigkeiten, die Einzelmodalitätssysteme nicht erreichen können. Eine Nur-Textual content-KI kann ein Foto beschreiben, wenn Sie es in Worten erklären. Eine multimodale KI kann das Foto sehen und den Kontext verstehen, den Sie nie erwähnt haben: die Beleuchtung, die Emotionen in Gesichtern, die räumlichen Beziehungen zwischen Objekten. Es verarbeitet nicht nur mehrere Eingaben; es synthetisiert das Verständnis zwischen ihnen.
Die Unterscheidung zwischen „wirklich multimodalen“ Modellen und „multimodalen Systemen“ ist wichtig. Einige Modelle verarbeiten alles zusammen in einer einheitlichen Architektur. GPT-4 Imaginative and prescient (GPT-4V) sieht und versteht gleichzeitig. Andere verbinden spezialisierte Modelle: Ein Visionsmodell analysiert ein Bild und übergibt die Ergebnisse dann zur Begründung an ein Sprachmodell. Beide Ansätze funktionieren. Ersteres bietet eine engere Integration, während letzteres mehr Flexibilität und Spezialisierung bietet.
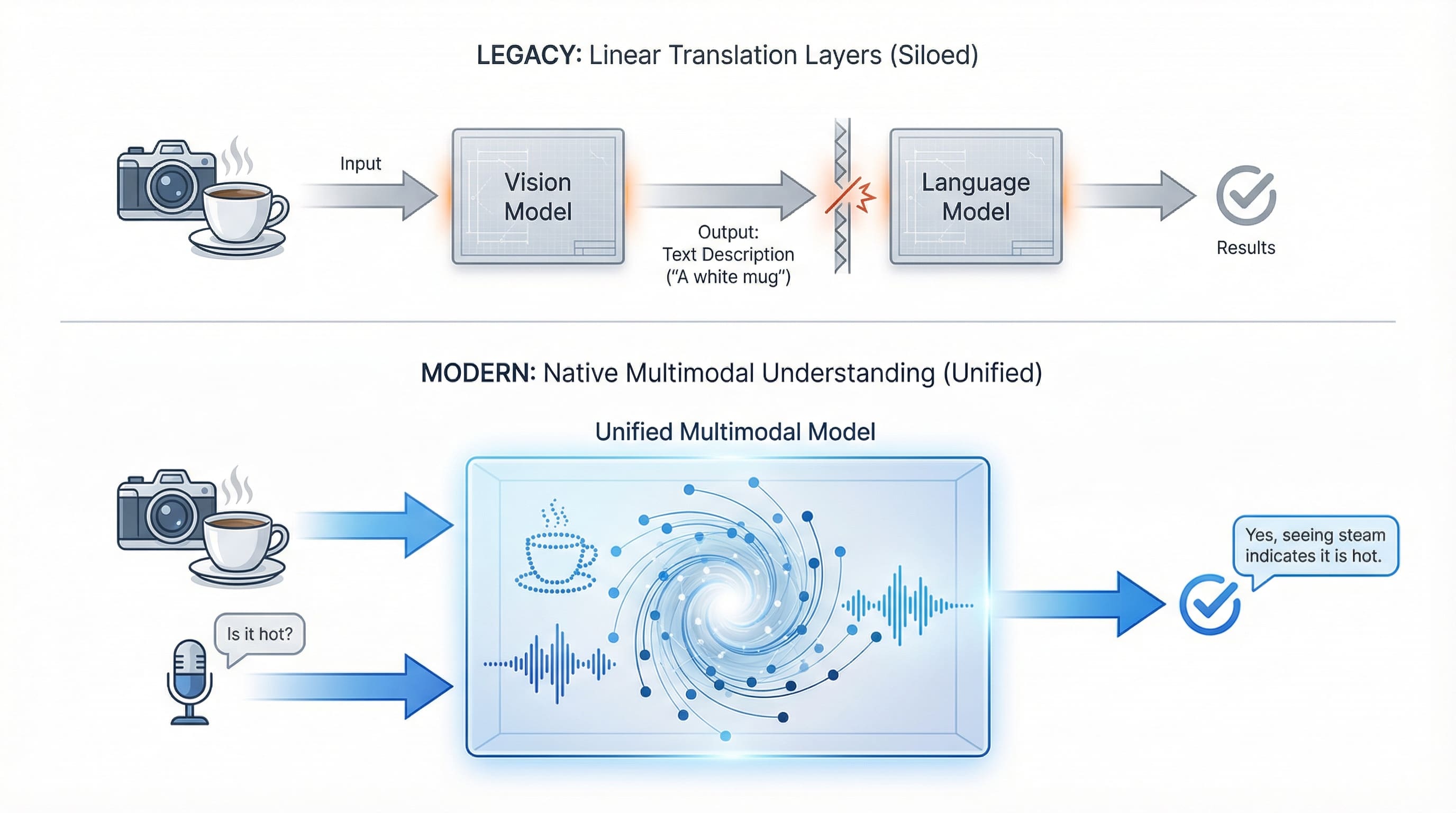
Legacy-Systeme erfordern die Übersetzung zwischen spezialisierten Modellen, während moderne multimodale KI Imaginative and prescient und Stimme gleichzeitig in einer einheitlichen Architektur verarbeitet. | Bild vom Autor
# Das Basis Trio verstehen: Imaginative and prescient-, Sprach- und Textmodelle
Drei Modalitäten sind für den breiten Produktionseinsatz ausgereift und bringen jeweils unterschiedliche Fähigkeiten und unterschiedliche technische Einschränkungen für KI-Systeme mit sich.
// Verbesserung des visuellen Verständnisses
Imaginative and prescient AI hat sich von der einfachen Bildklassifizierung zum echten visuellen Verständnis weiterentwickelt. GPT-4V und Claude kann Diagramme analysieren, Code anhand von Screenshots debuggen und komplexe visuelle Zusammenhänge verstehen. Zwillinge integriert Imaginative and prescient nativ über die gesamte Benutzeroberfläche. Die Open-Supply-Alternativen – LLaVA, Qwen-VLUnd CogVLM – konkurrieren mittlerweile bei vielen Aufgaben mit kommerziellen Optionen, während sie auf Client-{Hardware} laufen.
Hier wird die Verschiebung des Arbeitsablaufs deutlich: Anstatt zu beschreiben, was Sie in einem Screenshot sehen oder Diagrammdaten manuell zu transkribieren, zeigen Sie es einfach. Die KI sieht es direkt. Was früher fünf Minuten sorgfältiger Beschreibung erforderte, erfordert heute fünf Sekunden Add.
Die technische Realität bringt jedoch Einschränkungen mit sich. Im Allgemeinen können Sie kein rohes 60-fps-Video an ein großes Sprachmodell (LLM) streamen. Es ist zu langsam und zu teuer. Produktionssysteme nutzen Body-Samplingdas Extrahieren von Schlüsselbildern (vielleicht eines alle zwei Sekunden) oder die Bereitstellung einfacher „Änderungserkennungs“-Modelle, um nur Bilder zu senden, wenn sich die visuelle Szene verschiebt.
Was das Sehen fähig macht, ist nicht nur das Erkennen von Objekten. Es ist räumliches Denken: zu verstehen, dass die Tasse auf dem Tisch steht und nicht schwebt. Es geht darum, implizite Informationen zu lesen: zu erkennen, dass ein vollgestopfter Schreibtisch auf Stress hindeutet oder dass der Pattern einer Grafik im Widerspruch zum begleitenden Textual content steht. Imaginative and prescient AI zeichnet sich durch Dokumentenanalyse, visuelles Debugging, Bildgenerierung und alle Aufgaben aus, bei denen „Zeigen, nicht erzählen“ gilt.
// Weiterentwicklung der Sprach- und Audiointeraktion
Sprach-KI geht über die einfache Transkription hinaus. Flüstern hat das Feld verändert, indem es hochwertige Spracherkennung kostenlos und lokal ermöglicht hat. Es verarbeitet Akzente, Hintergrundgeräusche und mehrsprachiges Audio mit bemerkenswerter Zuverlässigkeit. Aber Sprach-KI umfasst jetzt Textual content-to-Speech (TTS) über ElfLabs, Bellenoder Coquizusammen mit Emotionserkennung und Sprecheridentifikation.
Mit der Stimme lässt sich ein weiterer Konvertierungsengpass beseitigen: Sie sprechen auf natürliche Weise, anstatt das einzutippen, was Sie sagen wollten. Die KI hört Ihren Tonfall, erkennt Ihr Zögern und reagiert auf das, was Sie gemeint haben, nicht nur auf die Wörter, die Sie eingegeben haben.
Die entscheidende Herausforderung ist nicht die Qualität der Transkription; es ist Latenz und Flip-Taking. Bei einem Gespräch in Echtzeit fühlt es sich unnatürlich an, drei Sekunden auf eine Antwort zu warten. Ingenieure lösen dieses Drawback mit Sprachaktivitätserkennung (VAD)Algorithmen, die genau die Millisekunde erkennen, in der ein Benutzer aufhört zu sprechen, um das Modell sofort auszulösen, plus „Barge-in“-Unterstützung, die es Benutzern ermöglicht, die KI mitten in der Reaktion zu unterbrechen.
Die Unterscheidung zwischen Transkription und Verstehen ist wichtig. Whisper wandelt Sprache mit beeindruckender Genauigkeit in Textual content um. Neuere Sprachmodelle erfassen jedoch den Tonfall, erkennen Sarkasmus, erkennen Zögern und verstehen den Kontext, der dem Textual content allein entgeht. Ein Kunde, der frustriert „intestine“ sagt, unterscheidet sich von „intestine“ zufrieden. Voice AI erfasst diesen Unterschied.
// Synthetisieren mit Textintegration
Die Textintegration dient als Klebstoff, der alles zusammenhält. Sprachmodelle bieten Argumentations-, Synthese- und Generierungsfähigkeiten, die anderen Modalitäten fehlen. Ein Imaginative and prescient-Modell kann Objekte in einem Bild identifizieren; Ein LLM erklärt ihre Bedeutung. Ein Audiomodell kann Sprache transkribieren; Ein LLM extrahiert Erkenntnisse aus dem Gespräch.
Die Fähigkeit ergibt sich aus der Kombination. Zeigen Sie einer KI einen medizinischen Scan, während Sie Symptome beschreiben, und sie synthetisiert das Verständnis über alle Modalitäten hinweg. Dies geht über die Parallelverarbeitung hinaus; Es handelt sich um echtes mehrsinniges Denken, bei dem jede Modalität die Interpretation der anderen beeinflusst.
# Erkundung neuer Grenzen jenseits der Grundlagen
Während Bild, Sprache und Textual content aktuelle Anwendungen dominieren, wächst die multimodale Landschaft schnell.
3D- und räumliches Verständnis bewegt KI über flache Bilder hinaus in den physischen Raum. Modelle, die Tiefe, dreidimensionale Beziehungen und räumliches Denken erfassen, ermöglichen Robotik, Augmented Actuality (AR), Digital Actuality (VR)-Anwendungen und Architekturwerkzeuge. Diese Systeme verstehen, dass ein Stuhl, aus verschiedenen Blickwinkeln betrachtet, dasselbe Objekt ist.
Strukturierte Daten als Modalität stellt eine subtile, aber wichtige Entwicklung dar. Anstatt Tabellenkalkulationen für LLMs in Textual content umzuwandeln, verstehen neuere Systeme Tabellen, Datenbanken und Diagramme nativ. Sie erkennen, dass eine Spalte eine Kategorie darstellt, dass Beziehungen zwischen Tabellen eine Bedeutung haben und dass Zeitreihendaten zeitliche Muster aufweisen. Dadurch kann die KI Datenbanken direkt abfragen, Finanzberichte ohne Aufforderung analysieren und strukturierte Informationen ohne verlustbehaftete Konvertierung in Textual content analysieren.
Wenn KI native Formate versteht, ergeben sich völlig neue Möglichkeiten. Ein Finanzanalyst kann auf eine Tabelle zeigen und fragen: „Warum ist der Umsatz im dritten Quartal gesunken?“ Die KI liest die Tabellenstruktur, erkennt die Anomalie und erklärt sie. Ein Architekt kann 3D-Modelle einspeisen und räumliches Suggestions erhalten, ohne zuerst alles in 2D-Diagramme umwandeln zu müssen.
Domänenspezifische Modalitäten auf Spezialgebiete abzielen. AlphaFoldSeine Fähigkeit, Proteinstrukturen zu verstehen, ermöglichte der KI die Arzneimittelentwicklung. Modelle, die die musikalische Notation verstehen, ermöglichen Kompositionswerkzeuge. Systeme, die Sensordaten und Zeitreiheninformationen verarbeiten, bringen KI in das Web der Dinge (IoT) und die industrielle Überwachung.
# Implementierung realer Anwendungen
Multimodale KI hat sich von Forschungsarbeiten zu Produktionssystemen entwickelt, die reale Probleme lösen.
- Inhaltsanalyse: Videoplattformen nutzen das Sehen, um Szenen zu erkennen, Audio, um Dialoge zu transkribieren, und Textmodelle, um Inhalte zusammenzufassen. Medizinische Bildgebungssysteme kombinieren die visuelle Analyse von Scans mit der Patientengeschichte und Symptombeschreibungen, um die Diagnose zu unterstützen.
- Barrierefreiheitstools: Gebärdensprachübersetzung in Echtzeit kombiniert Sehen (Sehen von Gesten) mit Sprachmodellen (Erzeugen von Textual content oder Sprache). Bildbeschreibungsdienste helfen sehbehinderten Benutzern, visuelle Inhalte zu verstehen.
- Kreative Arbeitsabläufe: Designer skizzieren Schnittstellen, die KI in Code umwandelt, während sie Designentscheidungen mündlich erklären. Inhaltsersteller beschreiben Konzepte in Sprache, während KI passende Bilder generiert.
- Entwicklertools: Debugging-Assistenten sehen Ihren Bildschirm, lesen Fehlermeldungen und erklären Lösungen mündlich. Code-Evaluation-Instruments analysieren sowohl die Codestruktur als auch die zugehörigen Diagramme oder Dokumentationen.
Der Wandel zeigt sich in der Artwork und Weise, wie Menschen arbeiten: Anstatt den Kontext zwischen den Instruments zu wechseln, zeigt man einfach etwas und fragt nach. Die Reibung verschwindet. Bei multimodalen Ansätzen bleibt jeder Informationstyp in seiner ursprünglichen Kind.
Die Herausforderung in der Produktion liegt oft weniger in der Leistungsfähigkeit als vielmehr in der Latenz. Voice-to-Voice-Systeme müssen Audio → Textual content → Argumentation → Textual content → Audio in weniger als 500 ms verarbeiten, um sich natürlich anzufühlen, was Streaming-Architekturen erfordert, die Daten in Blöcken verarbeiten.
# Navigieren in der neuen multimodalen Infrastruktur
Rund um die multimodale Entwicklung bildet sich eine neue Infrastrukturebene:
- Modellanbieter: OpenAI, Anthropic und Google führen kommerzielle Angebote an. Open-Supply-Projekte wie die LLaVA-Familie und Qwen-VL demokratisieren den Zugang.
- Framework-Unterstützung: LangChain multimodale Ketten zur Verarbeitung von Combined-Media-Workflows hinzugefügt. LamaIndex Erweitert RAG-Muster (Retrieval-Augmented Technology) auf Bilder und Audio.
- Spezialisierte Anbieter: ElevenLabs dominiert die Sprachsynthese, während Mitten auf der Reise Und Stabilitäts-KI Lead-Picture-Generierung.
- Integrationsprotokolle: Der Mannequin Context Protocol (MCP) standardisiert die Verbindung von KI-Systemen mit multimodalen Datenquellen.
Die Infrastruktur demokratisiert die multimodale KI. Was vor Jahren Forschungsteams erforderten, läuft jetzt im Framework-Code. Was Tausende an API-Gebühren kostete, läuft jetzt lokal auf Verbraucherhardware.
# Zusammenfassung der wichtigsten Erkenntnisse
Multimodale KI repräsentiert mehr als nur technische Fähigkeiten; Es verändert die Artwork und Weise, wie Menschen und Laptop interagieren. Grafische Benutzeroberflächen (GUIs) weichen multimodalen Schnittstellen, auf denen Sie auf natürliche Weise zeigen, erzählen, zeichnen und sprechen können.
Dies ermöglicht neue Interaktionsmuster wie visuelle Erdung. Anstatt „Was ist das für ein rotes Objekt in der Ecke?“ einzugeben, zeichnen Benutzer einen Kreis auf ihren Bildschirm und fragen „Was ist das?“ Die KI empfängt sowohl Bildkoordinaten als auch Textual content und verankert die Sprache in visuellen Pixeln.
Die Zukunft der KI liegt nicht in der Wahl zwischen Imaginative and prescient, Stimme oder Textual content. Es geht darum, Systeme aufzubauen, die alle drei so natürlich verstehen wie Menschen.
Vinod Chugani ist ein KI- und Datenwissenschaftspädagoge, der die Lücke zwischen neuen KI-Technologien und der praktischen Anwendung für Berufstätige schließt. Zu seinen Schwerpunkten zählen Agentische KI, Anwendungen für maschinelles Lernen und Automatisierungsworkflows. Durch seine Arbeit als technischer Mentor und Ausbilder hat Vinod Datenprofis bei der Kompetenzentwicklung und bei Karriereübergängen unterstützt. Er bringt analytisches Fachwissen aus dem quantitativen Finanzwesen in seinen praxisorientierten Lehransatz ein. Sein Inhalt betont umsetzbare Strategien und Rahmenbedingungen, die Fachleute sofort anwenden können.