

Bild vom Herausgeber
# Einführung
Information-Science-Projekte Normalerweise beginnen sie als explorative Python-Notebooks, müssen jedoch irgendwann in die Produktionsumgebung verschoben werden, was schwierig sein kann, wenn sie nicht sorgfältig geplant werden.
QuantumBlacks Framework, Kedroist ein Open-Supply-Software, das die Lücke zwischen experimentellen Notebooks und produktionsreifen Lösungen schließt, indem es Konzepte rund um Projektstruktur, Skalierbarkeit und Reproduzierbarkeit in die Praxis umsetzt.
In diesem Artikel werden die Hauptfunktionen von Kedro vorgestellt und untersucht. Er führt Sie zum besseren Verständnis durch die Kernkonzepte, bevor Sie tiefer in dieses Framework eintauchen, um echte Information-Science-Projekte anzugehen.
# Erste Schritte mit Kedro
Der erste Schritt zur Nutzung von Kedro ist natürlich die Set up in unserer laufenden Umgebung, idealerweise einer IDE – Kedro kann in Pocket book-Umgebungen nicht vollständig genutzt werden. Öffnen Sie Ihre bevorzugte Python-IDE, zum Beispiel VS Code, und geben Sie das integrierte Terminal ein:
Als nächstes erstellen wir mit diesem Befehl ein neues Kedro-Projekt:
Wenn der Befehl intestine funktioniert, werden Ihnen einige Fragen gestellt, einschließlich eines Namens für Ihr Projekt. Wir werden es benennen Churn Predictor. Wenn der Befehl nicht funktioniert, liegt möglicherweise ein Konflikt im Zusammenhang mit der Set up mehrerer Python-Versionen vor. In diesem Fall besteht die sauberste Lösung darin, in einer virtuellen Umgebung innerhalb Ihrer IDE zu arbeiten. Dies sind einige schnelle Workaround-Befehle zum Erstellen eines Kedro-Projekts (ignorieren Sie sie, wenn der vorherige Befehl zum Erstellen eines Kedro-Projekts bereits funktioniert hat!):
python3.11 -m venv venv
supply venv/bin/activate
pip set up kedro
kedro --versionWählen Sie dann in Ihrer IDE den folgenden Python-Interpreter aus, an dem Sie von nun an arbeiten möchten: ./venv/bin/python.
Wenn zu diesem Zeitpunkt alles intestine funktioniert hat, sollten Sie auf der linken Seite (im „EXPLORER“-Bereich in VS Code) eine vollständige Projektstruktur haben churn-predictor. Navigieren wir im Terminal zum Hauptordner unseres Projekts:
Zeit, einen Blick auf die Kernfunktionen von Kedro durch unser neu erstelltes Projekt zu werfen.
# Erkundung der Kernelemente von Kedro
Das erste Aspect, das wir einführen – und selbst erstellen – ist das Datenkatalog. In Kedro ist dieses Aspect dafür verantwortlich, Datendefinitionen vom Hauptcode zu isolieren.
Als Teil der Projektstruktur wurde bereits eine leere Datei erstellt, die als Datenkatalog fungiert. Wir müssen es nur finden und mit Inhalt füllen. Im IDE-Explorer, innerhalb der churn-predictor Projekt, gehen Sie zu conf/base/catalog.yml und öffnen Sie diese Datei, dann fügen Sie Folgendes hinzu:
raw_customers:
kind: pandas.CSVDataset
filepath: information/01_raw/clients.csv
processed_features:
kind: pandas.ParquetDataset
filepath: information/02_intermediate/options.parquet
train_data:
kind: pandas.ParquetDataset
filepath: information/02_intermediate/practice.parquet
test_data:
kind: pandas.ParquetDataset
filepath: information/02_intermediate/check.parquet
trained_model:
kind: pickle.PickleDataset
filepath: information/06_models/churn_model.pklKurz gesagt, wir haben gerade fünf Datensätze definiert (noch nicht erstellt), jeder mit einem zugänglichen Schlüssel oder Namen: raw_customers, processed_featuresund so weiter. Die Hauptdatenpipeline, die wir später erstellen werden, sollte in der Lage sein, diese Datensätze anhand ihres Namens zu referenzieren und so Eingabe-/Ausgabevorgänge vom Code zu abstrahieren und vollständig zu isolieren.
Wir werden jetzt welche brauchen Daten Dies fungiert als erster Datensatz in den obigen Datenkatalogdefinitionen. Für dieses Beispiel können Sie nehmen dieses Beispiel von synthetisch generierten Kundendaten, laden Sie sie herunter und integrieren Sie sie in Ihr Kedro-Projekt.
Als nächstes navigieren wir zu information/01_rawerstellen Sie eine neue Datei mit dem Namen clients.csvund fügen Sie den Inhalt des Beispieldatensatzes hinzu, den wir verwenden werden. Der einfachste Weg besteht darin, den „Rohinhalt“ der Datensatzdatei in GitHub anzuzeigen, alles auszuwählen, zu kopieren und in Ihre neu erstellte Datei im Kedro-Projekt einzufügen.
Jetzt erstellen wir einen Kedro Pipelinedas den datenwissenschaftlichen Arbeitsablauf beschreibt, der auf unseren Rohdatensatz angewendet wird. Geben Sie im Terminal Folgendes ein:
kedro pipeline create data_processingDieser Befehl erstellt darin mehrere Python-Dateien src/churn_predictor/pipelines/data_processing/. Jetzt werden wir öffnen nodes.py und fügen Sie den folgenden Code ein:
import pandas as pd
from typing import Tuple
def engineer_features(raw_df: pd.DataFrame) -> pd.DataFrame:
"""Create derived options for modeling."""
df = raw_df.copy()
df('tenure_months') = df('account_age_days') / 30
df('avg_monthly_spend') = df('total_spend') / df('tenure_months')
df('calls_per_month') = df('support_calls') / df('tenure_months')
return df
def split_data(df: pd.DataFrame, test_fraction: float) -> Tuple(pd.DataFrame, pd.DataFrame):
"""Cut up information into practice and check units."""
practice = df.pattern(frac=1-test_fraction, random_state=42)
check = df.drop(practice.index)
return practice, checkDie beiden Funktionen, die wir gerade definiert haben, fungieren als Knoten die als Teil eines reproduzierbaren, modularen Workflows Transformationen auf einen Datensatz anwenden kann. Bei der ersten Methode wird ein einfaches, anschauliches Characteristic-Engineering angewendet, indem aus den Rohfeatures mehrere abgeleitete Options erstellt werden. Die zweite Funktion definiert die Aufteilung des Datensatzes in Trainings- und Testsätze, beispielsweise für die weitere nachgelagerte Modellierung des maschinellen Lernens.
Im selben Unterverzeichnis befindet sich eine weitere Python-Datei: pipeline.py. Öffnen wir es und fügen wir Folgendes hinzu:
from kedro.pipeline import Pipeline, node
from .nodes import engineer_features, split_data
def create_pipeline(**kwargs) -> Pipeline:
return Pipeline((
node(
func=engineer_features,
inputs="raw_customers",
outputs="processed_features",
title="feature_engineering"
),
node(
func=split_data,
inputs=("processed_features", "params:test_fraction"),
outputs=("train_data", "test_data"),
title="split_dataset"
)
))Ein Teil der Magie findet hier statt: Beachten Sie die Namen, die für Ein- und Ausgänge von Knoten in der Pipeline verwendet werden. Genau wie Legosteine, Hier können wir flexibel auf verschiedene Datensatzdefinitionen in unserem Datenkatalog verweisenbeginnend natürlich mit dem Datensatz, der die Rohkundendaten enthält, die wir zuvor erstellt haben.
Damit alles funktioniert, müssen noch ein paar letzte Konfigurationsschritte durchgeführt werden. Der Anteil der Testdaten für den Partitionierungsknoten wurde als Parameter definiert, der übergeben werden muss. In Kedro definieren wir diese „externen“ Parameter zum Code, indem wir sie dem hinzufügen conf/base/parameters.yml Datei. Fügen wir dieser derzeit leeren Konfigurationsdatei Folgendes hinzu:
Darüber hinaus importiert das Kedro-Projekt standardmäßig implizit Module aus der PySpark-Bibliothek, die wir nicht wirklich benötigen. In settings.py (im Unterverzeichnis „src“) können wir dies deaktivieren, indem wir die ersten paar vorhandenen Codezeilen wie folgt auskommentieren und ändern:
# Instantiated mission hooks.
# from churn_predictor.hooks import SparkHooks # noqa: E402
# Hooks are executed in a Final-In-First-Out (LIFO) order.
HOOKS = ()Speichern Sie alle Änderungen, stellen Sie sicher, dass Pandas in Ihrer Laufumgebung installiert sind, und machen Sie sich bereit, das Projekt über das IDE-Terminal auszuführen:
Abhängig von der installierten Kedro-Model kann dies zunächst funktionieren oder auch nicht. Wenn es nicht funktioniert und Sie eine erhalten DatasetErrordie wahrscheinliche Lösung ist pip set up kedro-datasets oder pip set up pyarrow (oder vielleicht beides!), dann versuchen Sie es erneut.
Hoffentlich erhalten Sie eine Reihe von „INFO“-Nachrichten, die Sie über die verschiedenen Phasen des Daten-Workflows informieren. Das ist ein gutes Zeichen. Im information/02_intermediate Im Verzeichnis finden Sie möglicherweise mehrere Parquet-Dateien, die die Ergebnisse der Datenverarbeitung enthalten.
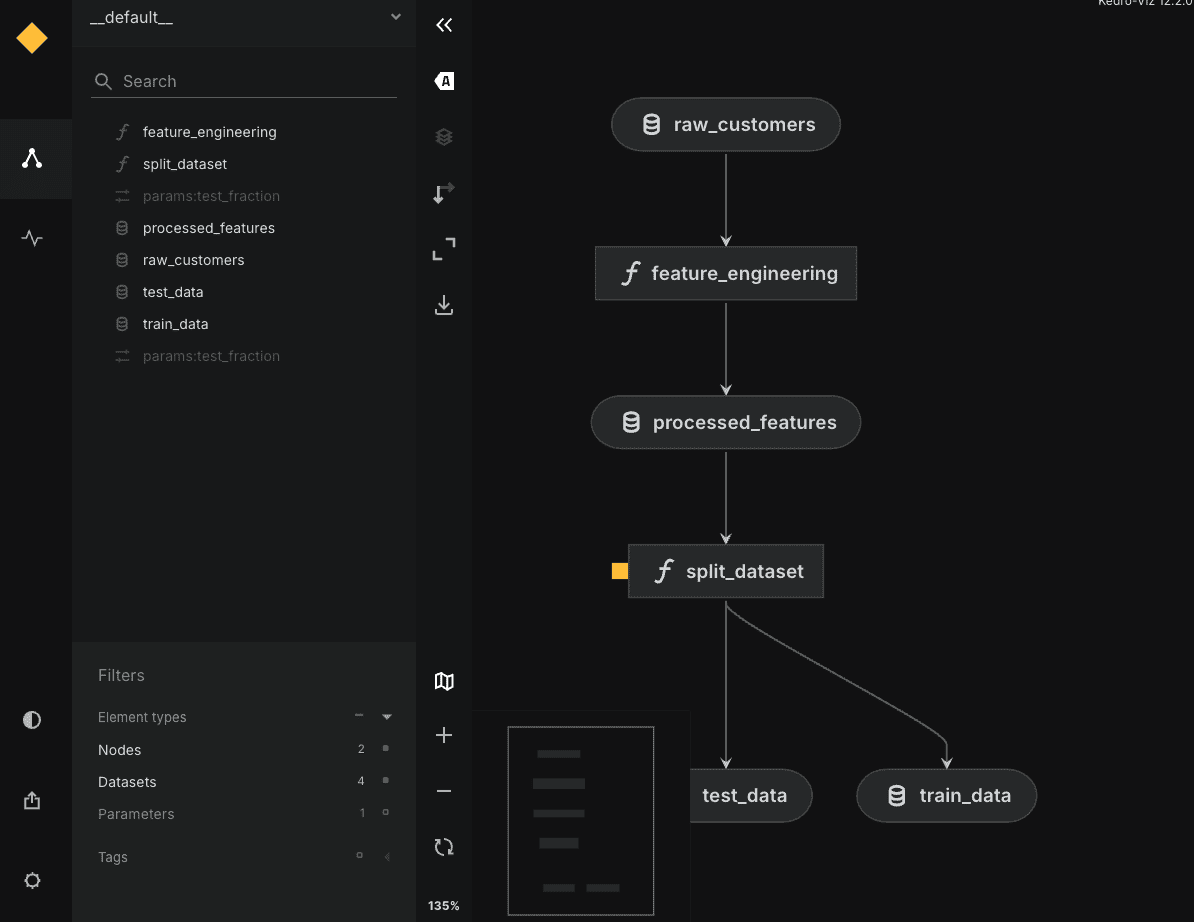
Zum Abschluss können Sie elective pip set up kedro-viz und laufen kedro viz um in Ihrem Browser ein interaktives Diagramm Ihres auffälligen Arbeitsablaufs zu öffnen, wie unten gezeigt:
# Zusammenfassung
Wir werden die weitere Erkundung dieses Instruments einem möglichen zukünftigen Artikel überlassen. Wenn Sie hier angekommen sind, konnten Sie Ihr erstes Kedro-Projekt erstellen, seine Kernkomponenten und Funktionen kennenlernen und verstehen, wie sie dabei interagieren.
Intestine gemacht!
Iván Palomares Carrascosa ist ein führender Autor, Redner und Berater in den Bereichen KI, maschinelles Lernen, Deep Studying und LLMs. Er schult und leitet andere darin, KI in der realen Welt zu nutzen.