Erstellen Sie GenAI-Systeme und möchten diese bereitstellen, oder möchten Sie einfach mehr über FastAPI erfahren? Dann ist dies genau das, was Sie gesucht haben! Stellen Sie sich vor, Sie haben viele PDF-Berichte und möchten darin nach bestimmten Antworten suchen. Entweder könnten Sie stundenlang scrollen oder Sie könnten ein System aufbauen, das sie für Sie liest und Ihre Fragen beantwortet. Wir bauen ein RAG-System die über eine API mithilfe von FastAPI bereitgestellt und darauf zugegriffen wird. Lassen Sie uns additionally ohne weitere Umschweife eintauchen.
Was ist FastAPI?
FastAPI ist ein Python-Framework zum Erstellen von API(s). Mit FastAPI können wir HTTP-Methoden verwenden, um mit dem Server zu kommunizieren.
Eine seiner nützlichen Funktionen besteht darin, dass automatisch eine Dokumentation für Ihre von Ihnen erstellten APIs generiert wird. Nachdem Sie Ihren Code geschrieben und die APIs erstellt haben, können Sie eine URL besuchen und die Schnittstelle (Swagger UI) nutzen, um Ihre Endpunkte zu testen, ohne dass Sie das Frontend programmieren müssen.
REST-APIs verstehen
Eine REST-API ist eine Schnittstelle, die die Kommunikation zwischen Shopper und Server herstellt. REST API ist die Abkürzung für Representational State Switch API. Der Shopper kann HTTP-Anfragen an einen bestimmten API-Endpunkt senden und der Server verarbeitet diese Anfragen. Es gibt einige HTTP-Methoden gegenwärtig. Einige davon werden wir in unserem Projekt mithilfe von FastAPI implementieren.
HTTP-Methoden:

In unserem Projekt werden wir zwei Kommunikationsmethoden verwenden:
- ERHALTEN: Dies wird zum Abrufen von Informationen verwendet. Wir werden die GET-Anfrage /well being verwenden, um zu überprüfen, ob der Server läuft.
- POST: Dies wird verwendet, um Daten an den Server zu senden, um etwas zu erstellen oder zu verarbeiten. Wir werden /ingest- und /query-POST-Anfragen verwenden. Wir verwenden hier POST, weil dabei komplexe Daten wie Dateien usw. gesendet werden müssen JSON Objekte. Mehr dazu im Abschnitt Umsetzung.
Was ist RAG?
Retrieval-Augmented Technology (RAG) ist eine Möglichkeit, einem LLM Zugriff auf spezifisches Wissen zu gewähren, für das er ursprünglich nicht ausgebildet wurde.
RAG-Komponenten:
- Abruf: Auf der Grundlage der Abfrage relevante Sätze aus dem/den Dokument(en) finden.
- Technology: Übergabe dieser Sätze an ein LLM, damit dieses sie zu einer Antwort zusammenfassen kann.
Erfahren Sie mehr über die RAG im kommenden Abschnitt zur Implementierung.
Durchführung
Problemstellung: Erstellen eines Techniques, das es Benutzern ermöglicht, Dokumente hochzuladen, insbesondere TXT-Dateien oder PDFs. Anschließend indiziert es sie in einer durchsuchbaren Datenbank und stellt sicher, dass ein LLM Fragen zu den neuen Daten beantworten kann. Dieses System wird über API-Endpunkte bereitgestellt und verwendet, die wir über FastAPI erstellen.
Voraussetzungen
– Wir benötigen einen OpenAI-API-Schlüssel und verwenden das gpt-4.1-mini-Modell als Gehirn des Techniques. Sie können den API-Schlüssel über den Hyperlink erhalten: (https://platform.openai.com/settings/group/api-keys)
– Eine IDE zum Ausführen der Python-Skripte, ich verwende VSCode für die Demo. Erstellen Sie ein neues Projekt (Ordner).
– Erstellen Sie eine .env-Datei in Ihrem Projekt und fügen Sie Ihren OpenAI-Schlüssel genau wie folgt hinzu:
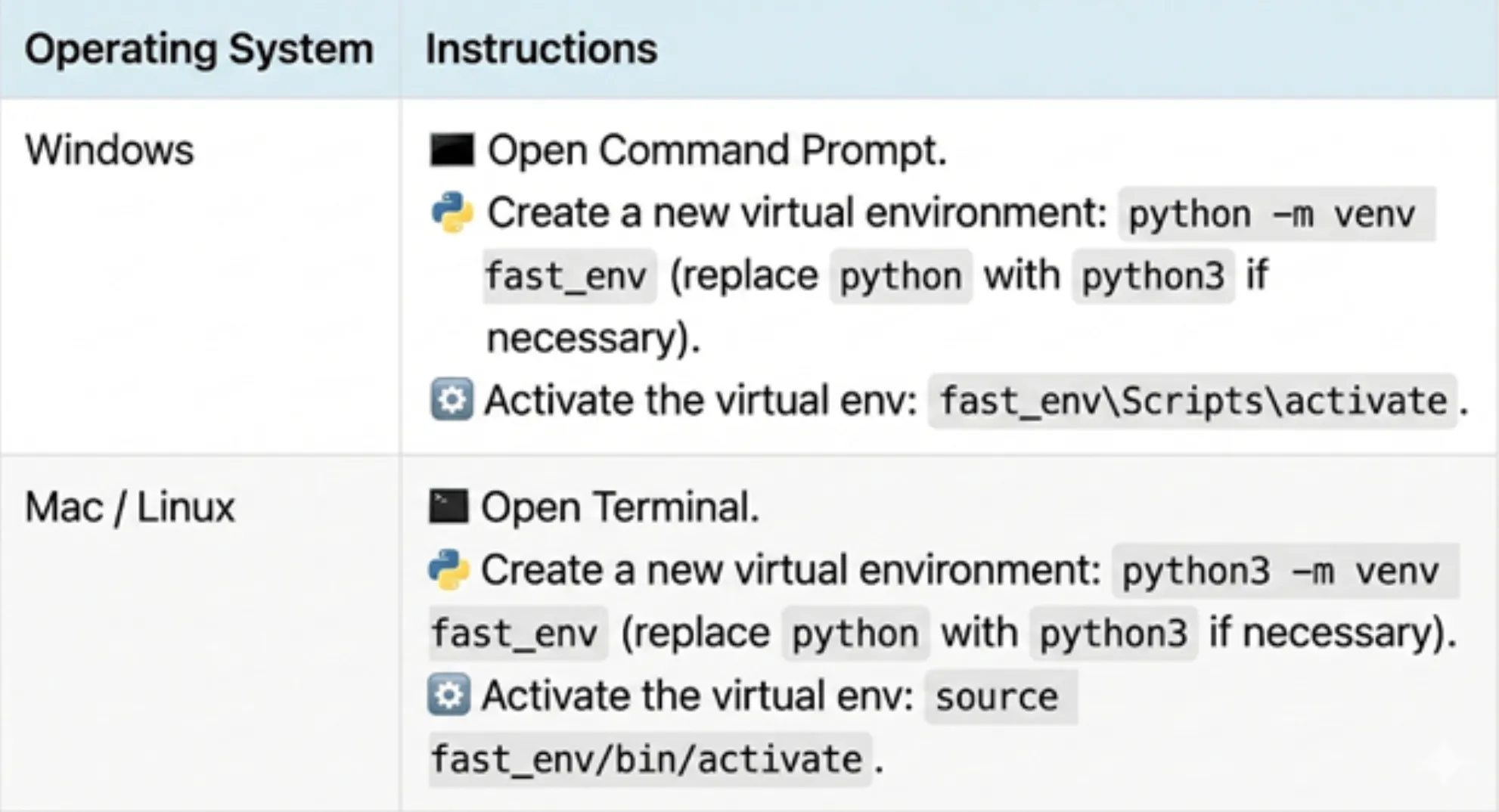
OPENAI_API_KEY=sk-proj... – Erstellen Sie eine virtuelle Umgebung für dieses Projekt (um die Abhängigkeiten des Projekts zu isolieren).
Notiz:
- Stellen Sie sicher, dass die fast_env in Ihrem Projekt erstellt wird, da Pfadfehler auftreten können, wenn das Arbeitsverzeichnis nicht auf das Projektverzeichnis festgelegt ist.
- Nach der Aktivierung sind alle von Ihnen installierten Pakete in dieser Umgebung enthalten.
– Laden Sie den folgenden Weblog über das „Obtain-Image“ als PDF herunter, um ihn in unserem RAG-System zu verwenden:
Anforderungen
Um dieses Drawback zu lösen, benötigen wir einen Stapel, der schwere Hebevorgänge effizient bewältigt:
- FastAPI: Zur Bearbeitung der Webanfragen und Datei-Uploads.
- LangChain: Erweiterung der Möglichkeiten des LLM.
- FAISS (Fb-KI-Ähnlichkeitssuche): Hilft beim Durchsuchen von Textblöcken. Wir werden es als Vektordatenbank verwenden.
- Uvicorn: Zum Hosten des Servers.
Sie können eine „necessities.txt“-Datei in Ihrem Projekt erstellen und „pip set up -r „necessities.txt““ ausführen:
fastapi==0.129.0
uvicorn(commonplace)==0.41.0
python-multipart==0.0.22
langchain==1.2.10
langchain-community==0.4.1
langchain-openai==1.1.10
langchain-core==1.2.13
faiss-cpu==1.13.2
openai==2.21.0
pypdf==6.7.1
python-dotenv==1.2.1Implementierungsansatz
Wir werden zwei FastAPI-Endpunkte implementieren:
1. Die Aufnahmepipeline (/ingest)
Wenn ein Benutzer eine Datei hochlädt, verwenden wir die RekursiverCharacterTextSplitter von LangChain. Diese Funktion unterteilt lange Dokumente in kleinere Abschnitte (wir konfigurieren die Funktion so, dass jeder Abschnitt eine Größe von 500 Zeichen hat).
Diese Chunks werden dann in Einbettungen umgewandelt und in unserem gespeichert FAISS Index (Vektordatenbank). Wir werden den lokalen Speicher für FAISS verwenden, damit die hochgeladenen Dokumente auch bei einem Neustart des Servers nicht verloren gehen.
2. Die Abfragepipeline (/question)
Wenn Sie eine Frage stellen, wird die Frage zu einem Vektor. Anschließend verwenden wir FAISS, um die obersten ok (normalerweise 4) Textabschnitte abzurufen, die der Frage am ähnlichsten sind.
Schließlich verwenden wir LCEL (LangChain Expression Language) um die Generierungskomponente des RAG zu implementieren. Wir senden die Frage und diese 4 Teile zusammen mit unserer Aufforderung, die Antwort zu erhalten, an gpt-4.1-mini.
Python-Code
Erstellen Sie im selben Projektordner zwei Skripte, rag_pipeline.py und foremost.py:
rag_pipeline.py:
Importe
import os
from langchain_community.document_loaders import TextLoader, PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import FAISS
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.paperwork import Doc
from dotenv import load_dotenv
from typing import Record Konfiguration
# Loading OpenAI API key
load_dotenv()
# Config
FAISS_INDEX_PATH = "faiss_index"
EMBEDDING_MODEL = "text-embedding-3-small"
LLM_MODEL = "gpt-4.1-mini"
CHUNK_SIZE = 500
CHUNK_OVERLAP = 50Hinweis: Stellen Sie sicher, dass Sie den API-Schlüssel in der .env-Datei hinzugefügt haben
Initialisierungen und Definition der Funktionen
# Shared state
_vectorstore: FAISS | None = None
embeddings = OpenAIEmbeddings(mannequin=EMBEDDING_MODEL)
def _load_vectorstore() -> FAISS | None:
"""Load current FAISS index from disk if it exists."""
world _vectorstore
if _vectorstore is None and os.path.exists(FAISS_INDEX_PATH):
_vectorstore = FAISS.load_local(
FAISS_INDEX_PATH,
embeddings,
allow_dangerous_deserialization=True
)
return _vectorstore
def ingest_document(file_path: str, filename: str = "") -> int:
"""
Chunks, Embeds, Shops in FAISS and returns the variety of chunks saved.
"""
world _vectorstore
# 1. Load
if file_path.endswith(".pdf"):
loader = PyPDFLoader(file_path)
else:
loader = TextLoader(file_path)
paperwork = loader.load()
# Overwriting supply with the filename
display_name = filename or os.path.basename(file_path)
for doc in paperwork:
doc.metadata("supply") = display_name
# 2. Chunk
splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=CHUNK_OVERLAP,
separators=("nn", "n", ".", " ", "")
)
chunks = splitter.split_documents(paperwork)
# 3. Embed and Retailer
if _vectorstore is None:
_load_vectorstore()
if _vectorstore is None:
_vectorstore = FAISS.from_documents(chunks, embeddings)
else:
_vectorstore.add_documents(chunks)
# 4. Persist to disk
_vectorstore.save_local(FAISS_INDEX_PATH)
return len(chunks)
def _format_docs(docs: Record(Doc)) -> str:
"""Concatenate doc page_content so as to add to the immediate."""
return "nn".be part of(doc.page_content for doc in docs)Diese Funktionen helfen dabei, die Dokumente aufzuteilen, den Textual content in Einbettungen aufzuteilen (unter Verwendung des Einbettungsmodells: text-embedding-3-small) und sie im FAISS-Index (Vektorspeicher) zu speichern.
Definieren des Retrievers und Turbines
def query_rag(query: str, top_k: int = 4) -> dict:
"""
Returns reply textual content and supply references.
"""
vs = _load_vectorstore()
if vs is None:
return {
"reply": "No paperwork have been ingested but. Please add a doc first.",
"sources": ()
}
# Retriever
retriever = vs.as_retriever(
search_type="similarity",
search_kwargs={"ok": top_k}
)
# Immediate
immediate = PromptTemplate(
input_variables=("context", "query"),
template="""You're a useful assistant. Use solely the context under to reply the query.
If the reply isn't within the context, say "I do not know based mostly on the offered paperwork."
Context:
{context}
Query: {query}
Reply:"""
)
llm = ChatOpenAI(mannequin=LLM_MODEL, temperature=0)
# LCEL chain
# Step 1:
retrieve = RunnableParallel(
_format_docs,
"query": RunnablePassthrough(),
)
# Step 2:
answer_chain = immediate | llm | StrOutputParser()
# Invoke
retrieved = retrieve.invoke(query)
reply = answer_chain.invoke(retrieved)
# Extracting sources
sources = listing({
doc.metadata.get("supply", "unknown")
for doc in retrieved("source_documents")
})
return {
"reply": reply,
"sources": sources,
}Wir haben unser RAG implementiert, das mithilfe der Ähnlichkeitssuche vier Dokumente abruft und die Frage, den Kontext und die Eingabeaufforderung an den Generator (gpt-4.1-mini) übergibt.
Zuerst werden die relevanten Dokumente mithilfe der Abfrage abgerufen, und dann wird die Antwortkette aufgerufen, die die Frage mithilfe von StrOutputParser() als Zeichenfolge beantwortet.
Hinweis: Das High-Okay und die Frage werden als Argumente an die Funktion übergeben.
foremost.py
Importe
import os
import tempfile
from fastapi import FastAPI, UploadFile, File, HTTPException
from pydantic import BaseModel
from rag_pipeline import ingest_document, query_ragWir haben die Funktionen ingest_document und query_rag importiert, die von den API-Endpunkten verwendet werden, die wir definieren werden.
Konfiguration
app = FastAPI(
title="RAG API",
description="Add paperwork and question them utilizing RAG",
model="1.0.0"
)
ALLOWED_EXTENSIONS = {
"utility/pdf": ".pdf",
"textual content/plain": ".txt",
}
class QueryRequest(BaseModel):
query: str
top_k: int = 4
class QueryResponse(BaseModel):
reply: str
sources: listing(str)Verwendung von Pydantic zur strengen Definition der Struktur der Eingaben in die API.
Hinweis: Hier können auch Validatoren hinzugefügt werden, um bestimmte Prüfungen durchzuführen (Beispiel: um zu prüfen, ob die Telefonnummer genau 10 Ziffern hat)
/health-API
@app.get("/well being", tags=("Well being"))
def well being():
"""Test if the API is operating."""
return {"standing": "okay"}Diese API ist nützlich, um zu bestätigen, ob der Server ausgeführt wird.
Hinweis: Wir umschließen die API-Funktionen mit einem Dekorator; Hier verwenden wir @app, da wir FastAPI zuvor mit dieser Variablen initialisiert hatten. Außerdem folgt darauf die HTTP-Methode, hier get(). Anschließend übergeben wir den Pfad für den Endpunkt, der hier „/well being“ ist.
/ingest API (Um das Dokument vom Benutzer zu übernehmen)
@app.put up("/ingest", tags=("Ingestion"), abstract="Add and index a doc")
async def ingest(file: UploadFile = File(...)):
"""
Add a **.txt** or **.pdf** file.
"""
if file.content_type not in ALLOWED_EXTENSIONS:
elevate HTTPException(
status_code=400,
element=f"Unsupported file sort '{file.content_type}'. Solely .txt and .pdf are supported."
)
suffix = ALLOWED_EXTENSIONS(file.content_type)
contents = await file.learn()
with tempfile.NamedTemporaryFile(delete=False, suffix=suffix) as tmp:
tmp.write(contents)
tmp_path = tmp.title
attempt:
num_chunks = ingest_document(tmp_path, filename=file.filename)
besides Exception as e:
elevate HTTPException(status_code=500, element=str(e))
lastly:
os.unlink(tmp_path)
return {
"message": f"Efficiently ingested '{file.filename}'",
"chunks_indexed": num_chunks
}Diese Funktion stellt sicher, dass nur .txt oder .pdf akzeptiert wird, und ruft dann die Funktion ingest_document() auf, die im Skript rag_pipeline.py definiert ist.
/question API (Um die RAG-Pipeline auszuführen)
@app.put up("/question", response_model=QueryResponse, tags=("Question"), abstract="Ask a query about your paperwork")
def question(request: QueryRequest):
"""
Ask a query associated to the offered doc.
The pipeline will return the reply and the supply file names used to generate it.
"""
if not request.query.strip():
elevate HTTPException(status_code=400, element="Query can't be empty.")
attempt:
consequence = query_rag(request.query, request.top_k)
besides Exception as e:
elevate HTTPException(status_code=500, element=str(e))
return QueryResponse(reply=consequence("reply"), sources=consequence("sources"))Schließlich haben wir die API definiert, die die Funktion query_rag() aufruft und die Antwort entsprechend den Dokumenten an den Benutzer zurückgibt. Lass es uns schnell testen.
Ausführen der App
– Führen Sie den folgenden Befehl an Ihrer Eingabeaufforderung oder Ihrem Terminal aus:
uvicorn foremost:app --reloadNotiz: Stellen Sie sicher, dass Ihre Umgebung aktiviert ist und alle Abhängigkeiten installiert sind. Andernfalls werden möglicherweise Fehler im Zusammenhang damit angezeigt.
– Jetzt sollte die App hier betriebsbereit sein: http://127.0.0.1:8000
– Öffnen Sie die Swagger-Benutzeroberfläche (Schnittstelle) über die folgende URL:
http://127.0.0.1:8000/docs
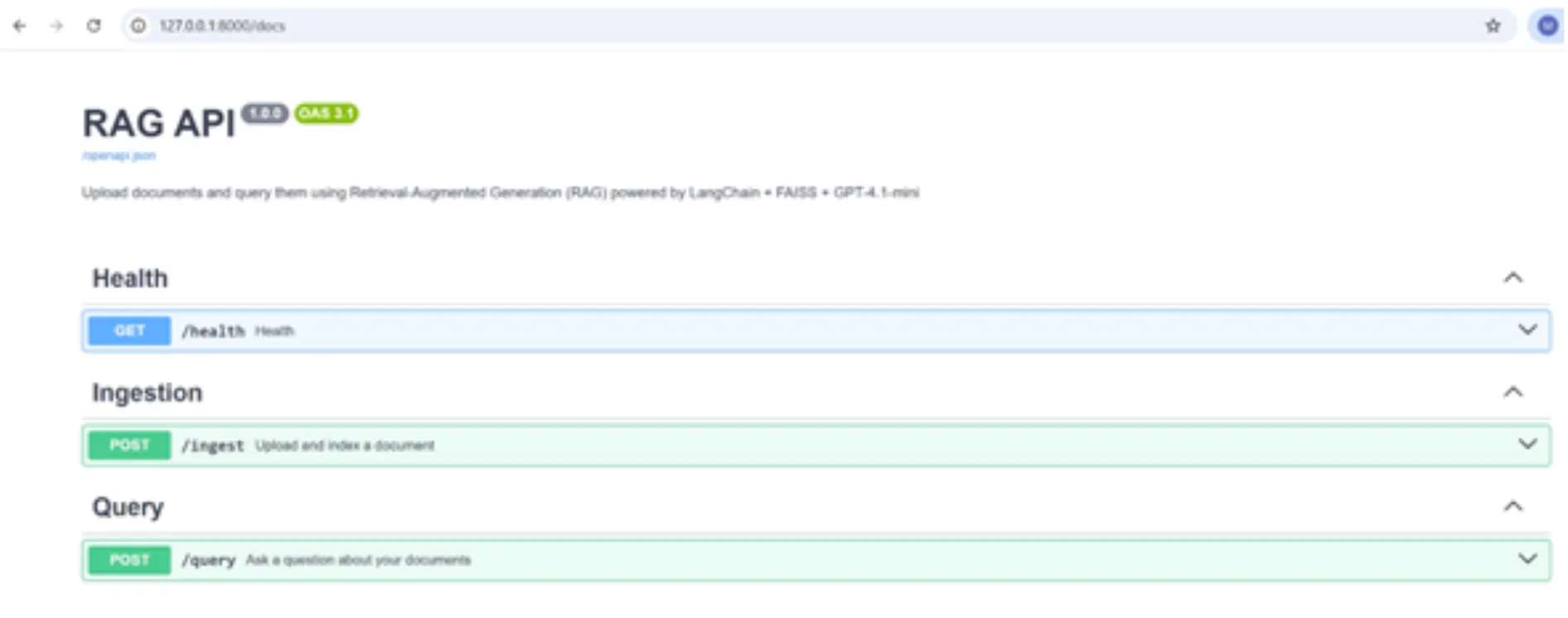
Großartig! Wir können unsere APIs mithilfe der Schnittstelle testen, indem wir einfach die Argumente an die APIs übergeben.
Testen beider APIs
1. /ingest-API:
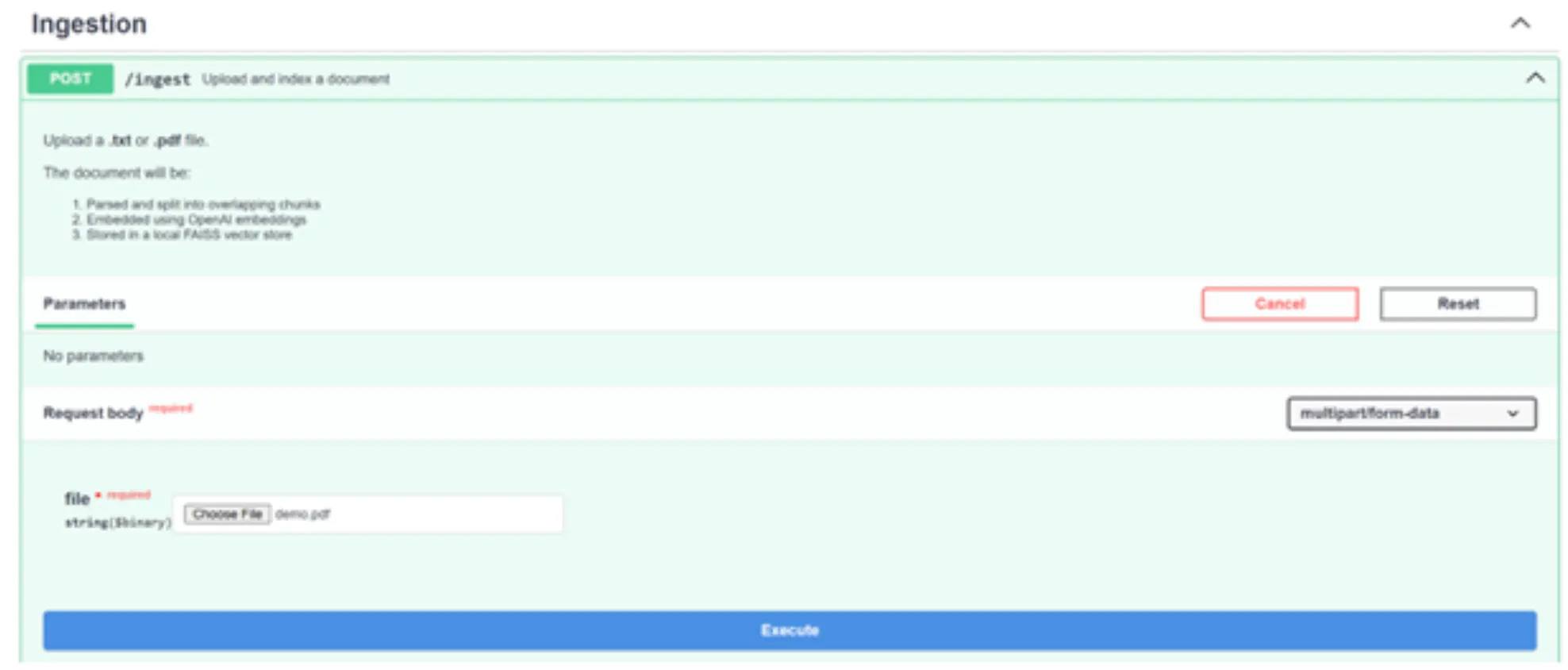
Klicken Sie auf „Ausprobieren“ und übergeben Sie die Demo-PDF-Datei (Sie können sie auch durch jede andere PDF-Datei ersetzen). Und klicken Sie auf Ausführen.
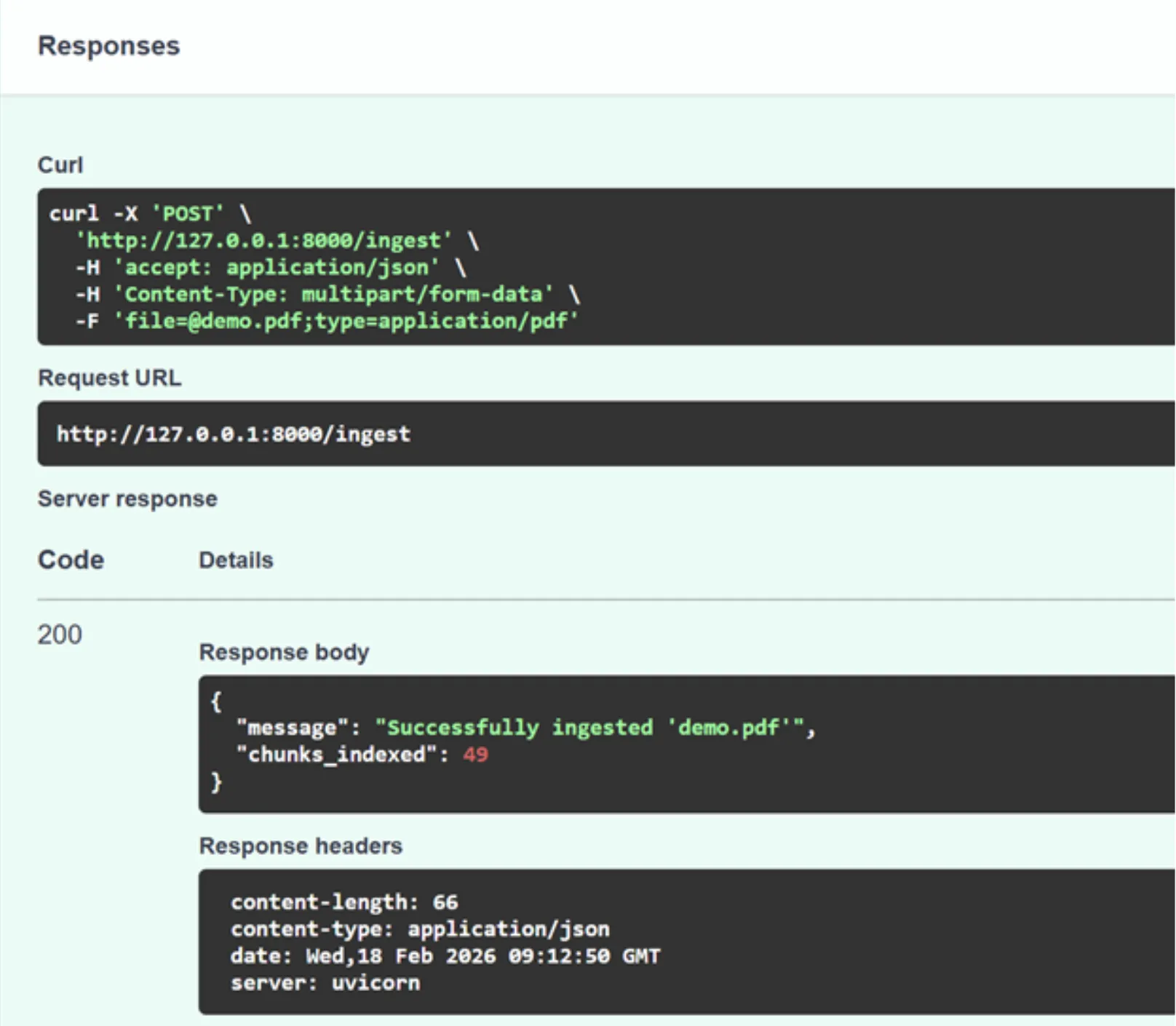
Großartig! Die API hat unsere Anfrage verarbeitet und den Vektorspeicher anhand des PDF erstellt. Sie können dies auch überprüfen, indem Sie in Ihrem Projektordner nachsehen, wo Sie den neuen Ordner „faiss_index“ sehen können.
2. /query-API:
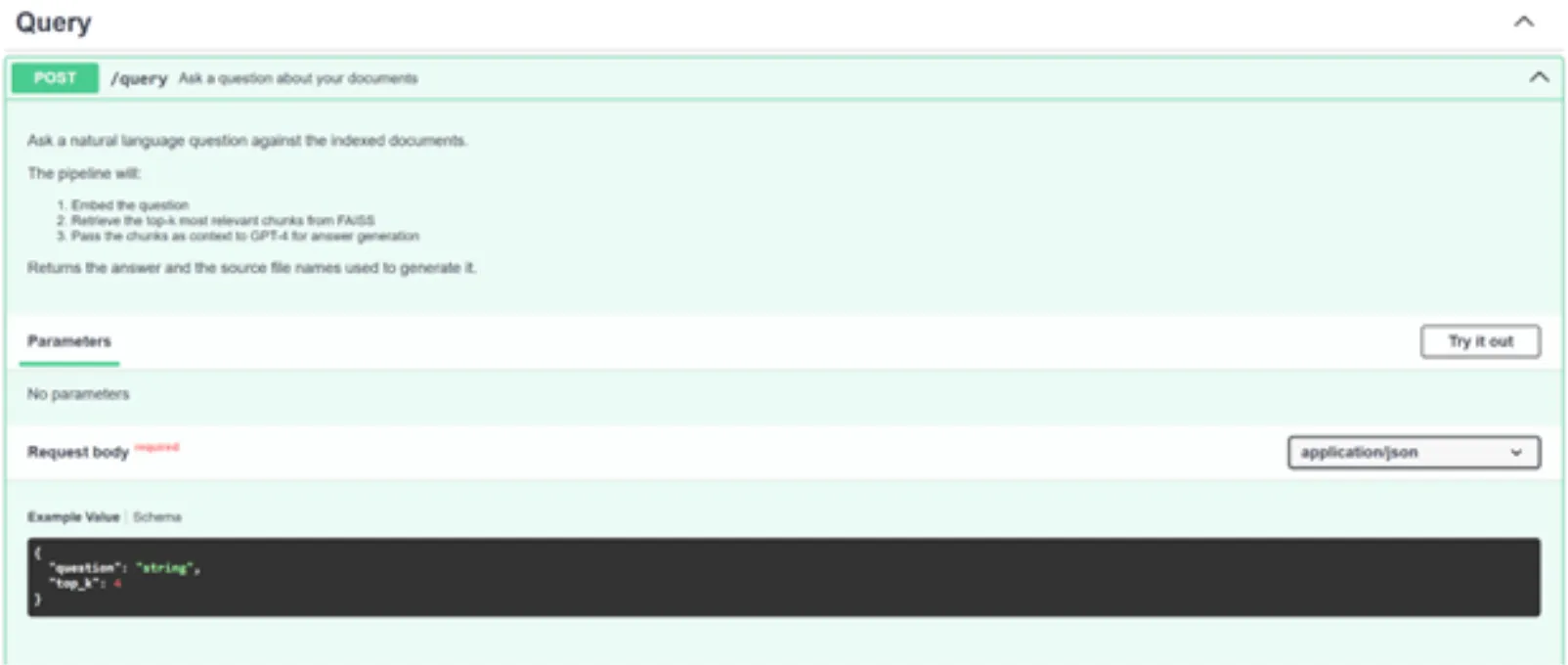
Klicken Sie nun auf „Ausprobieren“ und übergeben Sie die folgenden Argumente (Sie können auch andere Eingabeaufforderungen und PDFs verwenden).
{
"query": "Title 3 purposes of Machine Studying",
"top_k": 4
}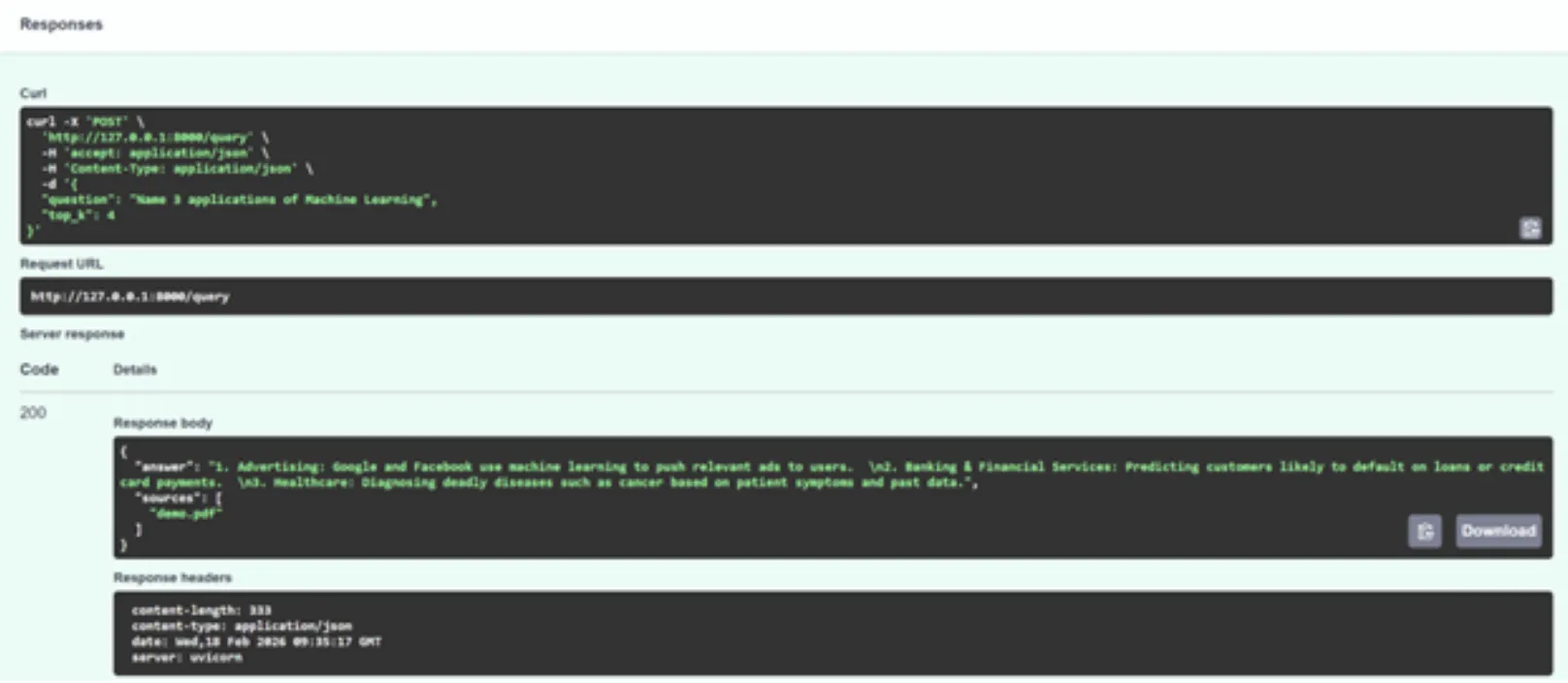
Wie erwartet ähnelt die Antwort stark dem Inhalt im PDF. Sie können mit dem High-Okay-Parameter experimentieren und ihn auch mit verschiedenen Fragen testen.

HTTP-Statuscodes verstehen
HTTP-Statuscodes Informieren Sie den Kunden darüber, ob eine Anfrage erfolgreich conflict oder ob etwas schief gelaufen ist.
Statuscode-Kategorien:
Erfolg
*Die Anfrage wurde erfolgreich empfangen und bearbeitet.
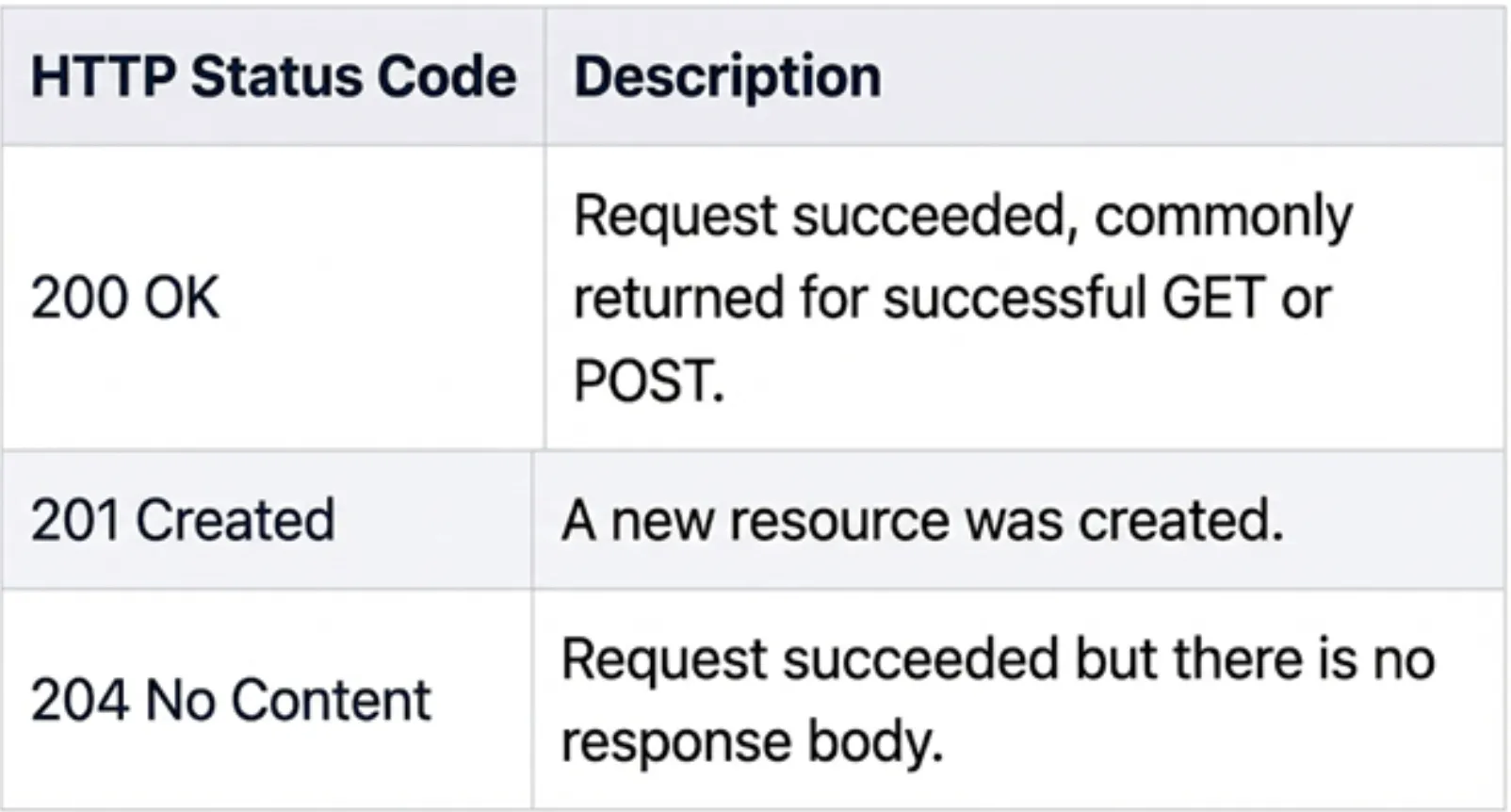
In unserem Projekt:
- /well being gibt 200 OK zurück, wenn der Server läuft.
- /ingest und /question geben bei Erfolg 200 OK zurück.
Clientfehler
*Der Fehler wird durch etwas verursacht, das der Shopper gesendet hat.

In unserem Projekt:
- Wenn Sie einen unerwarteten Dateityp hochladen (keine PDF- oder TXT-Datei), gibt die API den Statuscode 400 zurück.
- Wenn die Frage in /question leer ist, gibt die API den Statuscode 400 zurück.
- FastAPI gibt den Statuscode 422 zurück, wenn der Anforderungstext nicht mit dem erwarteten Pydantic-Modell übereinstimmt, das wir definiert haben.
Serverfehler
*Sie weisen darauf hin, dass auf der Serverseite ein Fehler aufgetreten ist.

In unserem Projekt:
- Wenn die Aufnahme oder Abfrage von Code aufgrund eines FAISS-Fehlers oder OpenAI-Fehlers fehlschlägt, gibt die API den Statuscode 500 zurück.
Lesen Sie auch:
Abschluss
Wir haben erfolgreich ein RAG-System mit FastAPI implementiert und gelernt, es aufzubauen und bereitzustellen. Hier haben wir eine API erstellt, die PDFs/.txts aufnimmt, relevante Informationen abruft und relevante Antworten generiert. Der Bereitstellungsteil macht GenAI-Systeme oder traditionelle ML-Systeme in realen Anwendungen leicht zugänglich. Wir können unsere RAG weiter verbessern, indem wir die Chunking-Strategie optimieren und verschiedene Abrufmethoden für unsere Abfragen kombinieren
Häufig gestellte Fragen
–reload sorgt dafür, dass der FastAPI-Server bei jeder Codeänderung automatisch neu startet und Aktualisierungen widerspiegelt, ohne dass der Server manuell neu gestartet werden muss.
Wir verwenden POST, weil Abfragen strukturierte Daten wie JSON-Objekte enthalten. Diese können groß und komplex sein. Dies unterscheidet sich von GET-Anfragen, die für einfache Abrufe verwendet werden.
MMR (Maximal Marginal Relevance) gleicht Relevanz und Diversität bei der Auswahl von Dokumentblöcken aus und stellt so sicher, dass die abgerufenen Ergebnisse nützlich sind, ohne redundant zu sein.
Durch Erhöhen von top_k werden mehr Blöcke für das LLM abgerufen, was aufgrund des Vorhandenseins irrelevanter Inhalte zu potenziellem Rauschen in den generierten Antworten führen kann.
Leidenschaftlich für Technologie und Innovation, Absolvent des Vellore Institute of Know-how. Derzeit arbeite ich als Knowledge Science Trainee mit Schwerpunkt auf Knowledge Science. Großes Interesse an Deep Studying und generativer KI, begierig darauf, modernste Techniken zu erforschen, um komplexe Probleme zu lösen und wirkungsvolle Lösungen zu schaffen.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.