
Bild des Autors
Die Bereitstellung der richtigen Daten zum richtigen Zeitpunkt ist ein Hauptbedarf einer Organisation in der datengesteuerten Gesellschaft. Aber seien wir ehrlich: Das Erstellen einer zuverlässigen, skalierbaren und wartbaren Datenpipeline ist keine leichte Aufgabe. Es erfordert nachdenkliche Planung, absichtliches Design und eine Kombination aus Geschäftswissen und technischem Fachwissen. Unabhängig davon, ob mehrere Datenquellen integriert, Datenübertragungen verwaltet oder einfach eine zeitnahe Berichterstattung gewährleistet sind, stellt jede Komponente ihre eigenen Herausforderungen vor.
Aus diesem Grund möchte ich heute hervorheben, was eine Datenpipeline ist, und die kritischsten Komponenten des Erstellens eines.
Was ist eine Datenpipeline?
Bevor Sie versuchen zu verstehen, wie eine Datenpipeline bereitgestellt wird, müssen Sie verstehen, was sie ist und warum sie notwendig ist.
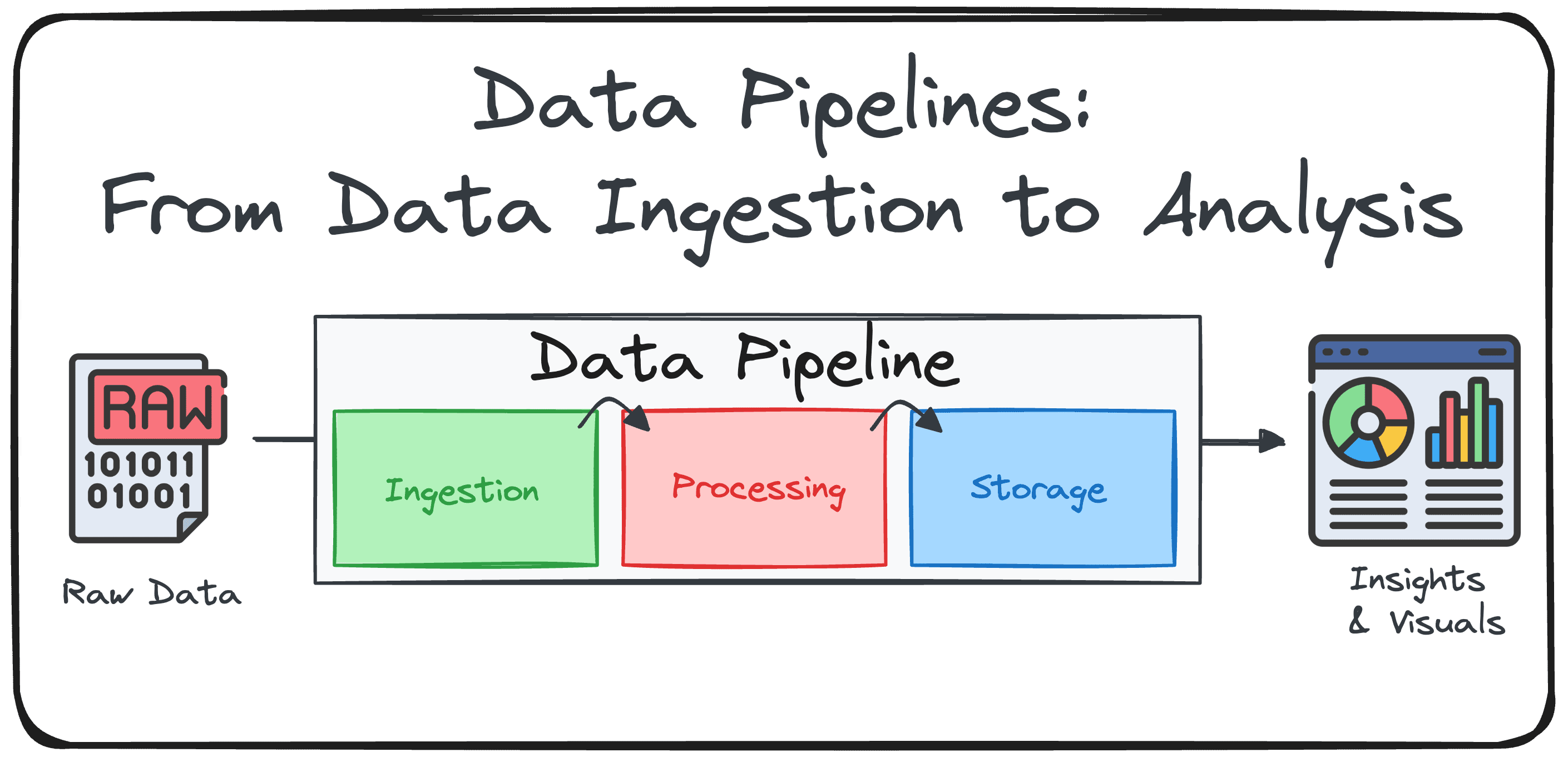
Eine Datenpipeline ist eine strukturierte Abfolge von Verarbeitungsschritten, mit denen Rohdaten in ein nützliches, analysebares Format für Enterprise Intelligence und Entscheidungsfindung umgewandelt werden sollen. Einfach ausgedrückt, es ist ein System, das Daten aus verschiedenen Quellen sammelt, transformiert, bereichert und optimiert und dann an ein oder mehrere Zielziele liefert.

Bild des Autors
Es ist ein weit verbreitetes Missverständnis, eine Datenpipeline mit jeglicher Kind der Datenbewegung gleichzusetzen. Das einfache Verschieben von Rohdaten von Punkt A nach Punkt B (z. B. zur Replikation oder Sicherung) ist keine Datenpipeline.
Warum eine Datenpipeline definieren?
Es gibt mehrere Gründe, eine Datenpipeline bei der Arbeit mit Daten zu definieren:
- Modularität: bestehend aus wiederverwendbaren Phasen für einfache Wartung und Skalierbarkeit
- Fehlertoleranz: Kann sich von Fehlern mit Protokollierung, Überwachung und Wiederholungsmechanismen wiederherstellen
- Datenqualitätssicherung: Validiert Daten für Integrität, Genauigkeit und Konsistenz
- Automatisierung: Läuft nach Zeitplan oder Auslöser und minimieren Sie die manuelle Intervention
- Sicherheit: Schutz sensibler Daten mit Zugriffskontrollen und Verschlüsselung
Die drei Kernkomponenten einer Datenpipeline
Die meisten Pipelines sind um die ETL (um die ETL () gebaut (Extrahieren, transformieren, laden) oder elt (Extrakt, Final, Transformation) Rahmen. Beide folgen den gleichen Prinzipien: Verarbeitung großer Datenmengen effizient und sicherstellen, dass sie sauber, konsistent und verwendet werden.

Bild des Autors
Lassen Sie uns jeden Schritt aufschlüsseln:
Komponente 1: Datenaufnahme (oder Extrakt)
Die Pipeline beginnt mit der Erfassung von Rohdaten aus mehreren Datenquellen wie Datenbanken, APIs, Cloud -Speicher, IoT -Geräten, CRMs, Flat -Dateien und mehr. Daten können in Chargen (stündliche Berichte) oder als Echtzeitströme (Reside-Webverkehr) eintreffen. Die Hauptziele sind es, sich sicher und zuverlässig mit verschiedenen Datenquellen zu verbinden und Daten in Bewegung (Echtzeit) oder in Ruhe zu sammeln.
Es gibt zwei gemeinsame Ansätze:
- Batch: Zeitplan regelmäßige Ziehungen (täglich, stündlich).
- Streaming: Verwenden Sie Instruments wie Kafka oder ereignisgesteuerte APIs, um Daten kontinuierlich aufzunehmen.
Die am häufigsten zu verwendenden Werkzeuge sind:
- Batch -Instruments: AirByte, Fivetran, Apache Nifi, benutzerdefinierte Python/SQL -Skripte
- APIs: Für strukturierte Daten aus Diensten (Twitter, Eurostat, TripAdvisor)
- Internet-Scraping: Instruments wie BeautifulSoup, Scrapy oder No-Code Scrapers
- Flache Dateien: CSV/Excel von offiziellen Web sites oder internen Servern
Komponente 2: Datenverarbeitung und Transformation (oder Transformation)
Nach der Einnahme müssen Rohdaten verfeinert und für die Analyse vorbereitet werden. Dies beinhaltet das Reinigen, Standardisieren, Zusammenführen von Datensätzen und die Anwendung der Geschäftslogik. Seine Hauptziele sind es, die Datenqualität, Konsistenz und Benutzerfreundlichkeit sicherzustellen und Daten mit Analysemodellen oder Berichtsanforderungen auszurichten.
Während dieser zweiten Komponente werden normalerweise mehrere Schritte berücksichtigt:
- Reinigung: Behandeln Sie fehlende Werte, entfernen Sie Duplikate, vereinheitlichen Formate
- Transformation: Filterung, Aggregation, Codierung oder Umgestaltung der Logik anwenden
- Validierung: Führen Sie Integritätsprüfungen durch, um die Korrektheit der Korrektheit zu gewährleisten
- Zusammenführung: Kombinieren Sie Datensätze aus mehreren Systemen oder Quellen
Die häufigsten Werkzeuge sind:
- DBT (Datenbauwerkzeug)
- Apache Funken
- Python (Pandas)
- SQL-basierte Pipelines
Komponente 3: Datenlieferung (oder Final)
Transformierte Daten werden an sein endgültiges Ziel geliefert, üblicherweise ein Knowledge Warehouse (für strukturierte Daten) oder einen Datensee (für semi- oder unstrukturierte Daten). Es kann auch direkt an Dashboards, APIs oder ML -Modelle gesendet werden. Seine Hauptziele sind es, Daten in einem Format zu speichern, das schnelle Abfragen und Skalierbarkeit unterstützt und Echtzeit- oder nahezu realer Zeitzugriff für die Entscheidungsfindung ermöglicht.
Die beliebtesten Instruments sind:
- Cloud -Speicher: Amazon S3, Google Cloud -Speicher
- Knowledge Warehouses: BigQuery, Snowflake, Databricks
- BI-fähige Ausgänge: Dashboards, Berichte, Echtzeit-APIs
Sechs Schritte zum Erstellen einer Finish-to-Finish-Datenpipeline
Das Erstellen einer guten Datenpipeline umfasst in der Regel sechs wichtige Schritte.

Die sechs Schritte zum Erstellen einer robusten Datenpipeline | Bild des Autors
1. Definieren Sie Ziele und Architektur
Eine erfolgreiche Pipeline beginnt mit einem klaren Verständnis ihres Zwecks und der Architektur, die zur Unterstützung erforderlich ist.
Schlüsselfragen:
- Was sind die Hauptziele dieser Pipeline?
- Wer sind die Endbenutzer der Daten?
- Wie frisch oder Echtzeit müssen die Daten sein?
- Welche Instruments und Datenmodelle entsprechen unseren Anforderungen am besten?
Empfohlene Maßnahmen:
- Klären Sie die geschäftlichen Fragen, die Ihre Pipeline beantwortet
- Skizzieren Sie ein hochrangiges Architekturdiagramm, um technische und geschäftliche Stakeholder auszurichten
- Wählen Sie Instruments und Entwurfsdatenmodelle entsprechend (z. B. ein Sternschema für die Berichterstattung).
2. Aufnahme von Daten
Sobald Ziele definiert sind, besteht der nächste Schritt darin, Datenquellen zu identifizieren und zu bestimmen, wie die Daten zuverlässig aufgenommen werden können.
Schlüsselfragen:
- Was sind die Datenquellen und in welchen Formaten stehen sie zur Verfügung?
- Sollte die Einnahme in Echtzeit, in Chargen oder beides stattfinden?
- Wie werden Sie die Vollständigkeit und Konsistenz der Daten sicherstellen?
Empfohlene Maßnahmen:
- Stellen Sie sichere, skalierbare Verbindungen zu Datenquellen wie APIs, Datenbanken oder Instruments von Drittanbietern her.
- Verwenden Sie Einnahmewerkzeuge wie AirByte, Fivetran, Kafka oder benutzerdefinierte Anschlüsse.
- Implementieren Sie grundlegende Validierungsregeln während der Einnahme, um Fehler frühzeitig zu erfassen.
3.. Datenverarbeitung und Transformation
Wenn Rohdaten einfließen, ist es Zeit, sie nützlich zu machen.
Schlüsselfragen:
- Welche Transformationen sind erforderlich, um Daten für die Analyse vorzubereiten?
- Sollten Daten mit externen Eingaben angereichert werden?
- Wie werden Duplikate oder ungültige Aufzeichnungen behandelt?
Empfohlene Maßnahmen:
- Wenden Sie Transformationen wie Filterung, Aggregation, Standardisierung und Verbinden von Datensätzen an
- Implementieren Sie die Geschäftslogik und sicherstellen
- Verwenden Sie Instruments wie DBT, Spark oder SQL, um diese Schritte zu verwalten und zu dokumentieren
4. Datenspeicher
Wählen Sie als Nächstes aus, wie und wo Sie Ihre verarbeiteten Daten für die Analyse und Berichterstattung speichern können.
Schlüsselfragen:
- Sollten Sie ein Knowledge Warehouse, einen Knowledge Lake oder einen Hybridansatz (Lakehouse) verwenden?
- Was sind Ihre Anforderungen an Kosten, Skalierbarkeit und Zugangskontrolle?
- Wie werden Sie Daten für eine effiziente Abfrage strukturieren?
Empfohlene Maßnahmen:
- Wählen Sie Speichersysteme aus, die Ihren analytischen Anforderungen übereinstimmen (z. B. BigQuery, Snowflake, S3 + Athena)
- Entwurfsschemas, die für die Berichterstattung über Anwendungsfälle optimieren
- Planen Sie das Datenlebenszyklusmanagement, einschließlich Archivierung und Reinigung
5. Orchestrierung und Automatisierung
Das Zusammenbinden aller Komponenten erfordert Workflow Orchestration und Überwachung.
Schlüsselfragen:
- Welche Schritte hängen voneinander ab?
- Was sollte passieren, wenn ein Schritt fehlschlägt?
- Wie werden Sie Ihre Pipelines überwachen, debuggen und pflegen?
Empfohlene Maßnahmen:
- Verwenden Sie Orchestrierungswerkzeuge wie Luftstrom, Präfekt oder Dagster, um Workflows zu planen und zu automatisieren
- Richten Sie die Wiederholung von Richtlinien und Warnungen für Fehler ein
- Model Ihr Pipeline -Code und modularisieren Sie für die Wiederverwendbarkeit
6. Berichterstattung und Analyse
Schließlich Wert liefern, indem Sie den Stakeholdern Erkenntnisse aufdecken.
Schlüsselfragen:
- Welche Instruments verwenden Analysten und Geschäftsbenutzer, um auf die Daten zuzugreifen?
- Wie oft sollten Dashboards aktualisieren?
- Welche Berechtigungen oder Governance -Richtlinien werden benötigt?
Empfohlene Maßnahmen:
- Schließen Sie Ihr Lager oder See an BI -Werkzeuge wie Looker, Energy BI oder Tableau an
- Richten Sie semantische Ebenen oder Ansichten ein, um den Zugriff zu vereinfachen
- Überwachen Sie die Nutzung der Dashboard -Nutzung und die Aktualisierung der Leistung
Schlussfolgerungen
Bei der Erstellung einer vollständigen Datenpipeline geht es nicht nur um die Übertragung von Daten, sondern auch darum, diejenigen zu befähigen, die sie benötigen, um Entscheidungen zu treffen und Maßnahmen zu ergreifen. Mit diesem organisierten, sechsstufigen Prozess können Sie Pipelines erstellen, die nicht nur effektiv, sondern widerstandsfähig und skalierbar sind.
Jede Part der Pipeline – Einnahme, Transformation und Entbindung – spielt eine entscheidende Rolle. Zusammen bilden sie eine Dateninfrastruktur, die datengesteuerte Entscheidungen unterstützt, die betriebliche Effizienz verbessert und neue Wege für Innovationen fördert.
Josep Ferrer ist ein Analyseingenieur aus Barcelona. Er absolvierte das Physik -Engineering und arbeitet derzeit im Bereich Knowledge Science, der für die menschliche Mobilität angewendet wurde. Er ist ein Teilzeit-Inhaltsersteller, der sich auf Datenwissenschaft und -technologie konzentriert. Josep schreibt über alle Dinge KI und deckt die Anwendung der laufenden Explosion vor Ort ab.