KI -Agenten sind jetzt ein Teil von Enterprises Huge und Small. Von Ausfüllformularen in Krankenhäusern und Überprüfung rechtlicher Dokumente bis hin zur Analyse von Videomaterial und Handhabung Kundenbetreuung – Wir haben KI -Agenten für alle Arten von Aufgaben. Unternehmen geben häufig Hunderttausende von Greenback für die Einstellung von Kundenunterstützungsmitarbeitern aus, die die Bedürfnisse eines Kunden verstehen und auf der Grundlage der Richtlinien des Unternehmens beheben können. Heute kann ein intelligenter Chatbot zur Beantwortung von FAQs den Kundenservice effizient verbessern. In diesem Artikel lernen wir, wie Sie einen FAQ -Chatbot erstellen, mit dem Kundenabfragen in Sekundenschnelle unter Verwendung von Nutzung gelöst werden können Agentenlappen (Wiederaufnahme Augmented Era), Langgraph Und Chromadb.
Kurzliste über Agentenlappen
Rag ist heutzutage ein heißes Thema. Jeder spricht über Lappen und Bauanwendungen. RAG hilft LLMs, Zugriff auf die Echtzeitdaten zu erhalten, was LLMs genauer ist als je zuvor. Jedoch, Traditionelle Lappensysteme In der Regel scheitern, wenn es darum geht, die beste Abrufmethode auszuwählen, den Abruf-Workflow zu ändern oder mehrstufige Argumente zu erstellen. Hier kommt der agierende Lappen ins Spiel.
Der Agentenlag verbessert den traditionellen Lappen, indem die Fähigkeiten von AI -Agenten in ihn einbezogen werden. Mit dieser Supermacht können Lumpen den Workflow dynamisch auf der Artwork der Abfrage, der Multi-Stufe-Argumentation und dem mehrstufigen Abruf verändern. Wir können sogar Instruments in das Agentenlag -System integrieren, und es kann dynamisch entscheiden, welches Device verwendet werden soll. Insgesamt führt dies zu einer verbesserten Genauigkeit und macht das System effizienter und skalierbarer.
Hier ist ein Beispiel für einen agierenden Lag -Workflow.
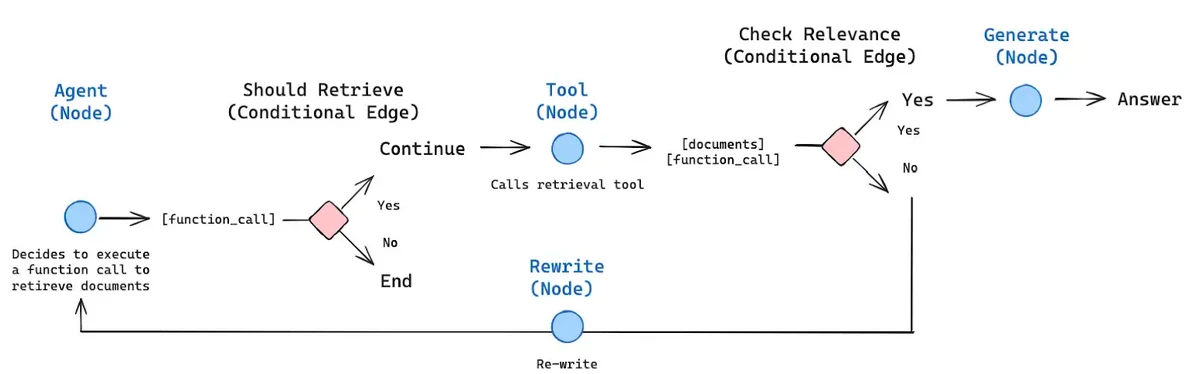
Das obige Bild bezeichnet die Architektur eines agierenden Rag -Frameworks. Es zeigt, wie KI -Agenten in Kombination mit Lappen unter bestimmten Bedingungen Entscheidungen treffen können. Das Bild zeigt deutlich, dass der Agent entscheidet, welche Kante basierend auf dem bereitgestellten Kontext ausgewählt werden soll, wenn ein bedingter Knoten vorhanden ist.
Lesen Sie auch: 10 Geschäftsanwendungen von LLM -Agenten
Architektur des intelligenten FAQ -Chatbots
Jetzt werden wir in die Architektur des Chatbots eintauchen, den wir bauen werden. Wir werden untersuchen, wie es funktioniert und was seine wichtigen Komponenten sind.
Die folgende Abbildung zeigt die Gesamtstruktur unseres Techniques. Wir werden dies mit Langgraph implementieren, einem Open-Supply-AI-Agenten-Framework von Langchain.
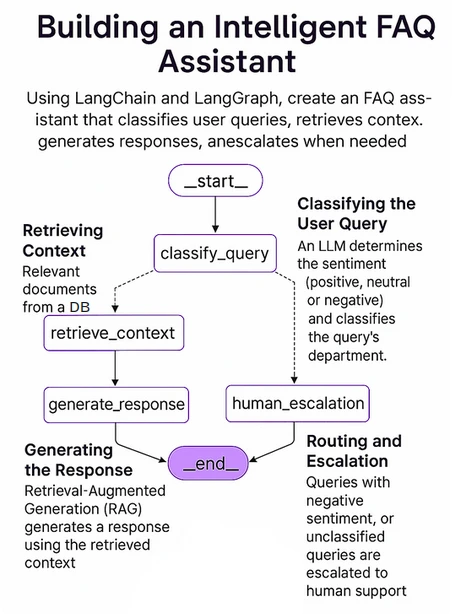
Die Schlüsselkomponenten unseres Techniques umfassen:
- Langgraph: Ein leistungsstarkes Open-Supply-AI-Agenten-Framework, das effizient komplexe, multi-Agent-Agent-Brokers erstellt. Diese Agenten können die Staaten im gesamten Workflow aufrechterhalten und die komplexen Abfragen effizient behandeln.
- LLM: Effizient und mächtig Großsprachige Modell Dies kann den Anweisungen des Benutzers folgen und entsprechend das Beste aus seinem Wissen beantworten. Hier verwenden wir O4-Mini von OpenAI, ein kleines Argumentationsmodell, das speziell für Geschwindigkeit, Erschwinglichkeit und Werkzeuggebrauch ausgelegt ist.
- Vektordatenbank: Eine Vektordatenbank wird verwendet, um Vektor -Einbettungen zu speichern, zu verwalten und abzurufen, die normalerweise die numerische Darstellung von Daten sind. Hier verwenden wir Chromadb, eine Open -Supply -AI -native Vektor -Datenbank. Es soll die Systeme befähigen, die von Ähnlichkeitssuche, semantischen Suchvorgängen und anderen Aufgaben mit Vektordaten abhängen.
Lesen Sie auch: So bauen Sie einen Sachvertreter des Kunden Helps auf
Praktische Implementierung zum Aufbau des intelligenten FAQ-Chatbots
Jetzt werden wir den Finish-to-Finish-Workflow unseres Chatbot basierend auf der oben diskutierten Architektur implementieren. Wir werden es Schritt für Schritt mit detaillierten Erklärungen, Code und Beispielausgängen machen. Additionally fangen wir an.
Schritt 1: Abhängigkeiten installieren
Wir werden zunächst alle erforderlichen Bibliotheken in unser Jupyter -Notizbuch installieren. Dazu gehören Bibliotheken wie Langchain, Langgraph, Langchain-Openai, Langchain-Neighborhood, Chromadb, Openai, Python-Dotenv, Pydantic und Pysqlite3.
!pip set up -q langchain langgraph langchain-openai langchain-community chromadb openai python-dotenv pydantic pysqlite3Schritt 2: Importierende Bibliotheken importieren
Jetzt sind wir bereit, alle verbleibenden Bibliotheken zu importieren, die wir für dieses Projekt benötigen.
import os
import json
from typing import Listing, TypedDict, Annotated, Dict
from dotenv import load_dotenv
# Langchain & LangGraph particular imports
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from pydantic import BaseModel, Area
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
from langchain_core.paperwork import Doc
from langchain_community.vectorstores import Chroma
from langgraph.graph import StateGraph, ENDSchritt 3: Richten Sie die OpenAI -API -Schlüssel ein
Geben Sie Ihren OpenAI -Schlüssel ein, um sie als Umgebungsvariable festzulegen.
from getpass import getpass
OPENAI_API_KEY = getpass("OpenAI API Key:")
load_dotenv()
os.getenv("OPENAI_API_KEY")Schritt 4: Laden Sie den Datensatz herunter
Für verschiedene Abteilungen haben wir im JSON -Format einen Beispiel für FAQ -Datensatz im JSON -Format erstellt. Wir müssen es aus dem Laufwerk herunterladen und es entpacken.
!gdown 1j6pdIansfQzKOZSEUinnHd8w6GlkKE6w
!unzip -o /content material/blog_faq_files.zipAusgabe:
Schritt 5: Definieren der Abteilungsnamen für die Zuordnung
Lassen Sie uns nun die Zuordnung der Abteilungen so definieren, dass unser Agentensystem verstehen kann, welche Datei zu welcher Abteilung gehört.
# Outline Division Names (guarantee these match metadata used throughout ingestion)
DEPARTMENTS = (
"Buyer Help",
"Product Info",
"Loyalty Program / Rewards"
)
UNKNOWN_DEPARTMENT = "Unknown/Different"
FAQ_FILES = {
"Buyer Help": "customer_support_faq.json",
"Product Info": "product_information_faq.json",
"Loyalty Program / Rewards": "loyalty_program_faq.json",
}Schritt 6: Definieren Sie die Helferfunktionen
Wir werden einige Helferfunktionen definieren, die für das Laden von FAQs aus den JSON -Dateien verantwortlich sind und sie auch in Chromadb speichern.
1. Load_faqs (…): Es ist eine Helferfunktion, die die FAQ aus den JSON -Dateien lädt und in einer Liste namens All_FAQS speichert.
def load_faqs(file_paths: Dict(str, str)) -> Dict(str, Listing(Dict(str, str))):
"""Masses QA pairs from JSON information for every division."""
all_faqs = {}
print("Loading FAQs...")
for dept, file_path in file_paths.objects():
strive:
with open(file_path, 'r', encoding='utf-8') as f:
all_faqs(dept) = json.load(f)
print(f" - Loaded {len(all_faqs(dept))} FAQs for {dept}")
besides FileNotFoundError:
print(f" - WARNING: FAQ file not discovered for {dept}: {file_path}. Skipping.")
besides json.JSONDecodeError:
print(f" - ERROR: Couldn't decode JSON for {dept} from {file_path}. Skipping.")
return all_faqs2. Setup_chroma_Vector_Store (…): Diese Funktion richtet den Chromadb ein, um die Vektor -Einbettungen zu speichern. Hierzu definieren wir zunächst die Chroma -Konfiguration, dh das Verzeichnis, das die Chroma -Datenbankdateien enthält. Dann werden wir die FAQs in Langchains Dokumente umwandeln. Es enthält Metadaten und Seiteninhalte, die das vordefinierte Format für einen genauen Lappen sind. Wir können Fragen und Antworten für ein besseres Kontextabruf kombinieren oder einfach die Antwort einbetten. Wir behalten die Frage auch die Abteilungsnamen in den Metadaten.
# ChromaDB Configuration
CHROMA_PERSIST_DIRECTORY = "./chroma_db_store"
CHROMA_COLLECTION_NAME = "Chatbot_faqs"
def setup_chroma_vector_store(
all_faqs: Dict(str, Listing(Dict(str, str))),
persist_directory: str,
collection_name: str,
embedding_model: OpenAIEmbeddings,
) -> Chroma:
"""Creates or hundreds a Chroma vector retailer with FAQ knowledge and metadata."""
paperwork = ()
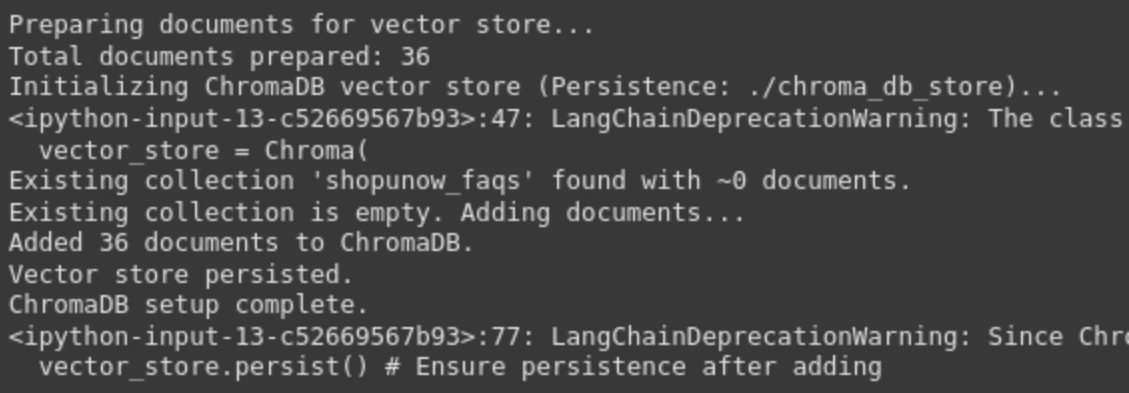
print("nPreparing paperwork for vector retailer...")
for division, faqs in all_faqs.objects():
for faq in faqs:
# Mix Q&A for higher contextual embedding, or simply embed solutions
# content material = f"Query: {faq('query')}nAnswer: {faq('reply')}"
content material = faq('reply') # Typically embedding simply the reply is efficient for FAQ retrieval
doc = Doc(
page_content=content material,
metadata={
"division": division,
"query": faq('query') # Maintain query in metadata for potential show
}
)
paperwork.append(doc)
print(f"Complete paperwork ready: {len(paperwork)}")
if not paperwork:
increase ValueError("No paperwork discovered so as to add to the vector retailer. Test FAQ loading.")
print(f"Initializing ChromaDB vector retailer (Persistence: {persist_directory})...")
vector_store = Chroma(
collection_name=collection_name,
embedding_function=embedding_model,
persist_directory=persist_directory,
)
strive:
vector_store = Chroma.from_documents(
paperwork=paperwork,
embedding=embedding_model,
persist_directory=persist_directory,
collection_name=collection_name
)
print(f"Created and populated ChromaDB with {len(paperwork)} paperwork.")
vector_store.persist() # Guarantee persistence after creation
print("Vector retailer endured.")
besides Exception as create_e:
print(f"FATAL ERROR: Couldn't create Chroma vector retailer: {create_e}")
increase create_e
print("ChromaDB setup full.")
return vector_storeSchritt 7: Definieren Sie die Langgraph -Agentenkomponenten
Definieren wir nun unsere KI -Agentenkomponente, die die Hauptkomponente unseres Arbeitsflusss ist.
1. Zustandsdefinition: Es ist eine Python -Klasse, die den aktuellen Zustand des Agenten während der Leitung enthält. Es enthält Variablen wie Abfrage, Stimmung, Abteilung.
class AgentState(TypedDict):
question: str
sentiment: str
division: str
context: str # Retrieved context for RAG
response: str # Remaining response to the consumer
error: str | None # To seize potential errors2. Pydantisches Modell: Wir haben a definiert Pydantisches Modell Hier sorgen Sie für eine strukturierte LLM -Ausgabe. Es enthält ein Gefühl, das drei Werte hat, „positiv“, „negativ“ und „impartial“ und einen Abteilungsnamen, der von der LLM vorhergesagt wird.
class ClassificationResult(BaseModel):
"""Structured output for question classification."""
sentiment: str = Area(description="Sentiment of the question (optimistic, impartial, destructive)")
division: str = Area(description=f"Most related division from the listing: {DEPARTMENTS + (UNKNOWN_DEPARTMENT)}. Use '{UNKNOWN_DEPARTMENT}' if uncertain or not relevant.")3. Knoten: Im Folgenden finden Sie die Knotenfunktionen, die jede Aufgabe einzeln umgehen.
- Classify_query_Node: Es klassifiziert die eingehende Abfrage in das Gefühl sowie den Namen der Zielabteilung basierend auf der Artwork der Abfrage.
- RECRIEVE_CONTEXT_NODE: Es führt den Lappen über die Vektor -Datenbank durch und filtert die Ergebnisse auf der Grundlage des Abteilungsnamens.
- generate_response_node: Es generiert die endgültige Antwort basierend auf der Abfrage und dem abgerufenen Kontext aus der Datenbank.
- Human_escalation_node: Wenn das Gefühl negativ ist oder die Zielabteilung unbekannt ist, eskaliert es die Abfrage an den menschlichen Benutzer.
- Route_Query: Es bestimmt den nächsten Schritt basierend auf der Abfrage und Ausgabe des Klassifizierungsknotens.
# 3. Nodes
def classify_query_node(state: AgentState) -> Dict(str, str):
"""
Classifies the consumer question for sentiment and goal division utilizing an LLM.
"""
print("--- Classifying Question ---")
question = state("question")
llm = ChatOpenAI(mannequin="o4-mini", api_key=OPENAI_API_KEY) # Use a dependable, cheaper mannequin
# Put together immediate for classification
prompt_template = ChatPromptTemplate.from_messages((
SystemMessage(
content material=f"""You might be an professional question classifier for ShopUNow, a retail firm.
Analyze the consumer's question to find out its sentiment and essentially the most related division.
The out there departments are: {', '.be a part of(DEPARTMENTS)}.
If the question does not clearly match into one among these, or is ambiguous, classify the division as '{UNKNOWN_DEPARTMENT}'.
If the question expresses frustration, anger, dissatisfaction, or complains about an issue, classify sentiment as 'destructive'.
If the question is asking a query, searching for info, or making a impartial assertion, classify sentiment as 'impartial'.
If the question expresses satisfaction, reward, or optimistic suggestions, classify sentiment as 'optimistic'.
Reply ONLY with the structured JSON output format."""
),
HumanMessage(content material=f"Person Question: {question}")
))
# LLM Chain with structured output
classifier_chain = prompt_template | llm.with_structured_output(ClassificationResult)
strive:
end result: ClassificationResult = classifier_chain.invoke({}) # Move empty dict as enter appears required now
print(f" Classification End result: Sentiment="{end result.sentiment}", Division="{end result.division}"")
return {
"sentiment": end result.sentiment.decrease(), # Normalize
"division": end result.division
}
besides Exception as e:
print(f" Error throughout classification: {e}")
return {
"sentiment": "impartial", # Default on error
"division": UNKNOWN_DEPARTMENT,
"error": f"Classification failed: {e}"
}
def retrieve_context_node(state: AgentState) -> Dict(str, str):
"""
Retrieves related context from the vector retailer primarily based on the question and division.
"""
print("--- Retrieving Context ---")
question = state("question")
division = state("division")
if not division or division == UNKNOWN_DEPARTMENT:
print(" Skipping retrieval: Division unknown or not relevant.")
return {"context": "", "error": "Can not retrieve context and not using a legitimate division."}
# Initialize embedding mannequin and vector retailer entry
embedding_model = OpenAIEmbeddings(api_key=OPENAI_API_KEY)
vector_store = Chroma(
collection_name=CHROMA_COLLECTION_NAME,
embedding_function=embedding_model,
persist_directory=CHROMA_PERSIST_DIRECTORY,
)
retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={
'okay': 3, # Retrieve prime 3 related docs
'filter': {'division': division} # *** CRITICAL: Filter by division ***
}
)
strive:
retrieved_docs = retriever.invoke(question)
if retrieved_docs:
context = "nn---nn".be a part of((doc.page_content for doc in retrieved_docs))
print(f" Retrieved {len(retrieved_docs)} paperwork for division '{division}'.")
# print(f" Context Snippet: {context(:200)}...") # Optionally available: log snippet
return {"context": context, "error": None}
else:
print(" No related paperwork present in vector retailer for this division.")
return {"context": "", "error": "No related context discovered."}
besides Exception as e:
print(f" Error throughout context retrieval: {e}")
return {"context": "", "error": f"Retrieval failed: {e}"}
def generate_response_node(state: AgentState) -> Dict(str, str):
"""
Generates a response utilizing RAG primarily based on the question and retrieved context.
"""
print("--- Producing Response (RAG) ---")
question = state("question")
context = state("context")
llm = ChatOpenAI(mannequin="o4-mini", api_key=OPENAI_API_KEY) # Can use a extra succesful mannequin for era
if not context:
print(" No context supplied, producing generic response.")
# Fallback if retrieval failed however routing determined RAG path anyway
response_text = "I could not discover particular info associated to your question in our data base. May you please rephrase or present extra particulars?"
return {"response": response_text}
# RAG Immediate
prompt_template = ChatPromptTemplate.from_messages((
SystemMessage(
content material=f"""You're a useful AI Chatbot for ShopUNow. Reply the consumer's question primarily based *solely* on the supplied context.
Be concise and straight tackle the question. If the context does not comprise the reply, state that clearly.
Don't make up info.
Context:
---
{context}
---"""
),
HumanMessage(content material=f"Person Question: {question}")
))
RAG_chain = prompt_template | llm
strive:
response = RAG_chain.invoke({})
response_text = response.content material
print(f" Generated RAG Response: {response_text(:200)}...")
return {"response": response_text}
besides Exception as e:
print(f" Error throughout response era: {e}")
return {"response": "Sorry, I encountered an error whereas producing the response.", "error": f"Era failed: {e}"}
def human_escalation_node(state: AgentState) -> Dict(str, str):
"""
Supplies a message indicating the question can be escalated to a human.
"""
print("--- Escalating to Human Help ---")
cause = ""
if state.get("sentiment") == "destructive":
cause = "Because of the nature of your question,"
elif state.get("division") == UNKNOWN_DEPARTMENT:
cause = "As your question requires particular consideration,"
response_text = f"{cause} I must escalate this to our human assist group. They'll assessment your request and get again to you shortly. Thanks on your persistence."
print(f" Escalation Message: {response_text}")
return {"response": response_text}
# 4. Conditional Routing Logic
def route_query(state: AgentState) -> str:
"""Determines the subsequent step primarily based on classification outcomes."""
print("--- Routing Choice ---")
sentiment = state.get("sentiment", "impartial")
division = state.get("division", UNKNOWN_DEPARTMENT)
if sentiment == "destructive" or division == UNKNOWN_DEPARTMENT:
print(f" Routing to: human_escalation (Sentiment: {sentiment}, Division: {division})")
return "human_escalation"
else:
print(f" Routing to: retrieve_context (Sentiment: {sentiment}, Division: {division})")
return "retrieve_context"Schritt 8: Definieren Sie die Graph -Funktion
Erstellen wir die Funktion für das Diagramm und weisen dem Diagramm die Knoten und Kanten zu.
# --- Graph Definition ---
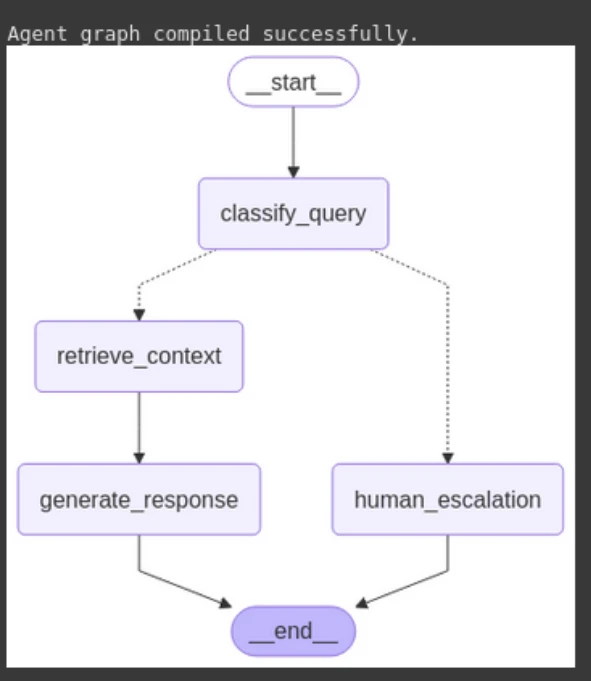
def build_agent_graph(vector_store: Chroma) -> StateGraph:
"""Builds the LangGraph agent."""
graph = StateGraph(AgentState)
# Add nodes
graph.add_node("classify_query", classify_query_node)
graph.add_node("retrieve_context", retrieve_context_node)
graph.add_node("generate_response", generate_response_node)
graph.add_node("human_escalation", human_escalation_node)
# Set entry level
graph.set_entry_point("classify_query")
# Add edges
graph.add_conditional_edges(
"classify_query", # Supply node
route_query, # Operate to find out the route
{ # Mapping: output of route_query -> vacation spot node
"retrieve_context": "retrieve_context",
"human_escalation": "human_escalation"
}
)
graph.add_edge("retrieve_context", "generate_response")
graph.add_edge("generate_response", END)
graph.add_edge("human_escalation", END)
# Compile the graph
# reminiscence = SqliteSaver.from_conn_string(":reminiscence:") # Instance for in-memory persistence
app = graph.compile() # checkpointer=reminiscence non-obligatory for stateful conversations
print("nAgent graph compiled efficiently.")
return appSchritt 9: Agentenausführung initiieren
Jetzt werden wir den Agenten initialisieren und den Workflow ausführen.
1. Laden wir zunächst die FAQs.
# 1. Load FAQs
faqs_data = load_faqs(FAQ_FILES)
if not faqs_data:
print("ERROR: No FAQ knowledge loaded. Exiting.")
exit()Ausgabe:

2. Richten Sie die Einbettungsmodelle ein. Hier werden wir OpenAi -Einbettungsmodelle für ein schnelleres Abruf einrichten.
# 2. Setup Vector Retailer
embedding_model = OpenAIEmbeddings(api_key=OPENAI_API_KEY)
vector_store = setup_chroma_vector_store(
faqs_data,
CHROMA_PERSIST_DIRECTORY,
CHROMA_COLLECTION_NAME,
embedding_model
)Ausgabe:
Lesen Sie auch: Wie wähle ich die richtige Einbettung für Ihr Lappenmodell aus?
3. Erstellen Sie nun den Mittel mithilfe der vordefinierten Funktion und visualisieren Sie den Wirkstofffluss mit dem Meerjungfrau -Diagramm.
# 3. Construct the Agent Graph
agent_app = build_agent_graph(vector_store)
from IPython.show import show, Picture, Markdown
show(Picture(agent_app.get_graph().draw_mermaid_png()))Ausgabe:
Schritt 10: Testen des Agenten
Wir sind im letzten Teil unseres Workflows angekommen. Bisher haben wir mehrere Knoten und Funktionen gebaut. Jetzt ist es an der Zeit, unseren Agenten zu testen und die Ausgabe zu sehen.
1. Definieren Sie zuerst die Testfragen.
# Check the Agent
test_queries = (
"How do I monitor my order?",
"What's the return coverage?",
"Inform me in regards to the 'City Explorer' jacket supplies.",
)2. Jetzt testen wir den Agenten.
print("n--- Testing Agent ---")
for question in test_queries:
print(f"nInput Question: {question}")
# Outline the enter for the graph invocation
inputs = {"question": question}
# strive:
# Invoke the graph
# The config argument is non-obligatory however helpful for stateful execution if wanted
# config = {"configurable": {"thread_id": "user_123"}} # Instance config
final_state = agent_app.invoke(inputs) #, config=config)
print(f"Remaining State Division: {final_state.get('division')}")
print(f"Remaining State Sentiment: {final_state.get('sentiment')}")
print(f"Agent Response: {final_state.get('response')}")
if final_state.get('error'):
print(f"Error encountered: {final_state.get('error')}")
# besides Exception as e:
# print(f"ERROR working agent graph for question '{question}': {e}")
# import traceback
# traceback.print_exc() # Print detailed traceback for debugging
print("n--- Agent Testing Full ---")print („ n – Testagent -“)
Ausgabe:
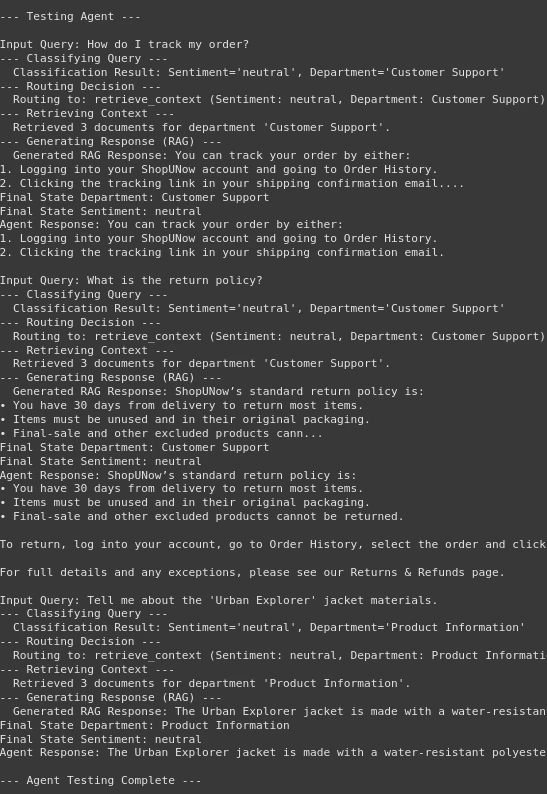
Wir können in der Ausgabe sehen, dass unser Agent intestine abschneidet. Zuerst klassifiziert es die Abfrage und leitet dann die Entscheidung an den Abrufknoten oder den menschlichen Knoten. Anschließend kommt der Abrufteil erfolgreich ab, um den Kontext aus der Vektor -Datenbank abzurufen. Letztendlich generieren Sie die Antwort nach Bedarf. Daher haben wir unseren intelligenten FAQ -Chatbot gemacht.
Sie können mit dem gesamten Code auf das Colab -Notizbuch zugreifen Hier.
Abschluss
Wenn Sie so weit erreicht haben, bedeutet dies, dass Sie gelernt haben, wie man einen intelligenten FAQ -Chatbot mit Agentic Rag und Langgraph erstellt. Hier haben wir gesehen, dass der Aufbau eines intelligenten Agenten, der eine Entscheidung argumentieren und treffen kann, nicht so schwer ist. Der von uns erstellte Agenten -Chatbot ist kostengünstig, schnell und kann den Kontext der Fragen oder Eingabebfragen vollständig verstehen. Die Architektur, die wir hier verwendet haben, ist vollständig anpassbar, was bedeutet, dass man jeden Knoten des Agenten für seinen jeweiligen Anwendungsfall bearbeiten kann. Mit Agentenlappen, Langgraph und Chromadb struggle es noch nie so einfach, Agenten zu machen. Nie so einfach. Ich bin sicher, was wir in diesem Handbuch behandelt haben, hat Ihnen das grundlegende Wissen gegeben, um komplexeres System mit diesen Instruments zu erstellen.
Harsh Mishra ist ein KI/ML -Ingenieur, der mehr Zeit damit verbringt, mit großen Sprachmodellen zu sprechen als mit tatsächlichen Menschen. Leidenschaft über Genai, NLP und Maschinen schlauer (damit sie ihn noch nicht ersetzen). Wenn er Fashions nicht optimiert, optimiert er wahrscheinlich seine Kaffeeaufnahme. 🚀☕
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.