
Bild des Autors
# Einführung
Stresstests sind entscheidend, um zu verstehen, wie sich Ihre Anwendung unter starker Belastung verhält. Für APIs mit maschinellem Lernen ist dies besonders wichtig, da die Modellinferenz CPU-intensiv sein kann. Durch die Simulation einer großen Anzahl von Benutzern können wir Leistungs Engpässe identifizieren, die Kapazität unseres Techniques bestimmen und Zuverlässigkeit sicherstellen.
In diesem Tutorial werden wir verwenden:
- Fastapi: Ein modernes, schnelles (leistungsstarkes) Webrahmen zum Aufbau von APIs mit Python.
- Uvicorn: Ein ASGI -Server, der unsere Fastapi -Anwendung ausführt.
- Heuschrecke: Ein Open-Supply-Lasttest-Software. Sie definieren das Benutzerverhalten mit Python -Code und schwärmen Ihr System mit Hunderten von gleichzeitigen Benutzern.
- Scikit-Be taught: Für unser Beispiel für maschinelles Lernen.
# 1. Projekteinrichtung und Abhängigkeiten
Richten Sie die Projektstruktur ein und installieren Sie die erforderlichen Abhängigkeiten.
- Erstellen
necessities.txtDatei und fügen Sie die folgenden Python -Pakete hinzu: - Öffnen Sie Ihr Terminal, erstellen Sie eine virtuelle Umgebung und aktivieren Sie sie.
- Installieren Sie alle Python -Pakete mit dem
necessities.txtDatei.
fastapi==0.115.12
locust==2.37.10
numpy==2.3.0
pandas==2.3.0
pydantic==2.11.5
scikit-learn==1.7.0
uvicorn==0.34.3
orjson==3.10.18python -m venv venv
venvScriptsactivatepip set up -r necessities.txt# 2. Aufbau der Fastapi -Anwendung
In diesem Abschnitt erstellen wir eine Datei zum Coaching des Regressionsmodells, für pydantische Modelle und die Fastapi -Anwendung.
Das ml_model.py behandelt das maschinelle Lernmodell. Es verwendet ein Singleton -Muster, um sicherzustellen, dass nur eine Instanz des Modells geladen wird. Das Modell ist ein zufälliger Forest -Regressor, der auf dem California Housing Dataset ausgebildet ist. Wenn ein vorgebildetes Modell (modell.pkl und scaler.pkl) nicht vorhanden ist, trainiert und rettet es eine neue.
app/ml_model.py:
import os
import threading
import joblib
import numpy as np
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
class MLModel:
_instance = None
_lock = threading.Lock()
def __new__(cls):
if cls._instance is None:
with cls._lock:
if cls._instance is None:
cls._instance = tremendous().__new__(cls)
return cls._instance
def __init__(self):
if not hasattr(self, "initialized"):
self.mannequin = None
self.scaler = None
self.model_path = "mannequin.pkl"
self.scaler_path = "scaler.pkl"
self.feature_names = None
self.initialized = True
self.load_or_create_model()
def load_or_create_model(self):
"""Load present mannequin or create a brand new one utilizing California housing dataset"""
if os.path.exists(self.model_path) and os.path.exists(self.scaler_path):
self.mannequin = joblib.load(self.model_path)
self.scaler = joblib.load(self.scaler_path)
housing = fetch_california_housing()
self.feature_names = housing.feature_names
print("Mannequin loaded efficiently")
else:
print("Creating new mannequin...")
housing = fetch_california_housing()
X, y = housing.knowledge, housing.goal
self.feature_names = housing.feature_names
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
self.scaler = StandardScaler()
X_train_scaled = self.scaler.fit_transform(X_train)
self.mannequin = RandomForestRegressor(
n_estimators=50, # Diminished for quicker predictions
max_depth=8, # Diminished for quicker predictions
random_state=42,
n_jobs=1, # Single thread for consistency
)
self.mannequin.match(X_train_scaled, y_train)
joblib.dump(self.mannequin, self.model_path)
joblib.dump(self.scaler, self.scaler_path)
X_test_scaled = self.scaler.rework(X_test)
rating = self.mannequin.rating(X_test_scaled, y_test)
print(f"Mannequin R² rating: {rating:.4f}")
def predict(self, options):
"""Make prediction for home worth"""
features_array = np.array(options).reshape(1, -1)
features_scaled = self.scaler.rework(features_array)
prediction = self.mannequin.predict(features_scaled)(0)
return prediction * 100000
def get_feature_info(self):
"""Get details about the options"""
return {
"feature_names": record(self.feature_names),
"num_features": len(self.feature_names),
"description": "California housing dataset options",
}
# Initialize mannequin as singleton
ml_model = MLModel()Der pydantic_models.py Die Datei definiert die pydantischen Modelle für Anforderungs- und Antwortdatenvalidierung und Serialisierung.
app/pydantic_models.py:
from typing import Checklist
from pydantic import BaseModel, Subject
class PredictionRequest(BaseModel):
options: Checklist(float) = Subject(
...,
description="Checklist of 8 options: MedInc, HouseAge, AveRooms, AveBedrms, Inhabitants, AveOccup, Latitude, Longitude",
min_length=8,
max_length=8,
)
model_config = {
"json_schema_extra": {
"examples": (
{"options": (8.3252, 41.0, 6.984, 1.024, 322.0, 2.556, 37.88, -122.23)}
)
}
}app/essential.py: Diese Datei ist die Kern -Fastapi -Anwendung, die die API -Endpunkte definiert.
import asyncio
from contextlib import asynccontextmanager
from fastapi import FastAPI, HTTPException
from fastapi.responses import ORJSONResponse
from .ml_model import ml_model
from .pydantic_models import (
PredictionRequest,
)
@asynccontextmanager
async def lifespan(app: FastAPI):
# Pre-load the mannequin
_ = ml_model.get_feature_info()
yield
app = FastAPI(
title="California Housing Value Prediction API",
model="1.0.0",
description="API for predicting California housing costs utilizing Random Forest mannequin",
lifespan=lifespan,
default_response_class=ORJSONResponse,
)
@app.get("/well being")
async def health_check():
"""Well being verify endpoint"""
return {"standing": "wholesome", "message": "Service is operational"}
@app.get("/model-info")
async def model_info():
"""Get details about the ML mannequin"""
attempt:
feature_info = await asyncio.to_thread(ml_model.get_feature_info)
return {
"model_type": "Random Forest Regressor",
"dataset": "California Housing Dataset",
"options": feature_info,
}
besides Exception:
increase HTTPException(
status_code=500, element="Error retrieving mannequin data"
)
@app.publish("/predict")
async def predict(request: PredictionRequest):
"""Make home worth prediction"""
if len(request.options) != 8:
increase HTTPException(
status_code=400,
element=f"Anticipated 8 options, obtained {len(request.options)}",
)
attempt:
prediction = ml_model.predict(request.options)
return {
"prediction": float(prediction),
"standing": "success",
"features_used": request.options,
}
besides ValueError as e:
increase HTTPException(status_code=400, element=str(e))
besides Exception:
increase HTTPException(status_code=500, element="Prediction error")Schlüsselpunkte:
lifespanSupervisor: Stellen Sie sicher, dass das ML -Modell während des Anwendungsstarts geladen wird.asyncio.to_thread: Dies ist entscheidend, da die Vorhersagemethode von Scikit-Be taught CPU-gebunden (synchron) ist. Das Ausführen in einem separaten Thread verhindert, dass es die asynchrone Ereignisschleife von Fastapi blockiert, sodass der Server andere Anforderungen gleichzeitig bearbeiten kann.
Endpunkte:
/well being: Eine einfache Gesundheitsprüfung./model-info: Bietet Metadaten über das ML -Modell./predict: Akzeptiert eine Liste von Funktionen und gibt eine Immobilienpreisvorhersage zurück.
run_server.py: Es enthält das Skript, mit dem die Fastapi -Anwendung mit Uvicorn ausgeführt wird.
import uvicorn
if __name__ == "__main__":
uvicorn.run("app.essential:app", host="localhost", port=8000, employees=4)Alle Dateien und Konfigurationen sind im GitHub -Repository verfügbar: Kingabzpro/Stress-Take a look at-Fastapi
# 3.. Schreiben Sie den Heuschreckspannungstest
Lassen Sie uns nun das Spannungstestskript mit Locust erstellen.
checks/locustfile.py: Diese Datei definiert das Verhalten simulierter Benutzer.
import json
import logging
import random
from locust import HttpUser, job
# Scale back logging to enhance efficiency
logging.getLogger("urllib3").setLevel(logging.WARNING)
class HousingAPIUser(HttpUser):
def generate_random_features(self):
"""Generate random however life like California housing options"""
return (
spherical(random.uniform(0.5, 15.0), 4), # MedInc
spherical(random.uniform(1.0, 52.0), 1), # HouseAge
spherical(random.uniform(2.0, 10.0), 2), # AveRooms
spherical(random.uniform(0.5, 2.0), 2), # AveBedrms
spherical(random.uniform(3.0, 35000.0), 0), # Inhabitants
spherical(random.uniform(1.0, 10.0), 2), # AveOccup
spherical(random.uniform(32.0, 42.0), 2), # Latitude
spherical(random.uniform(-124.0, -114.0), 2), # Longitude
)
@job(1)
def model_info(self):
"""Take a look at well being endpoint"""
with self.shopper.get("/model-info", catch_response=True) as response:
if response.status_code == 200:
response.success()
else:
response.failure(f"Mannequin information failed: {response.status_code}")
@job(3)
def single_prediction(self):
"""Take a look at single prediction endpoint"""
options = self.generate_random_features()
with self.shopper.publish(
"/predict", json={"options": options}, catch_response=True, timeout=10
) as response:
if response.status_code == 200:
attempt:
knowledge = response.json()
if "prediction" in knowledge:
response.success()
else:
response.failure("Invalid response format")
besides json.JSONDecodeError:
response.failure("Didn't parse JSON")
elif response.status_code == 503:
response.failure("Service unavailable")
else:
response.failure(f"Standing code: {response.status_code}")Schlüsselpunkte:
- Jeder simulierte Benutzer wartet zwischen 0,5 und 2 Sekunden zwischen Ausführungsaufgaben.
- Erstellt realistische Zufallsfunktionsdaten für die Vorhersageanforderungen.
- Jeder Benutzer stellt eine Health_Check -Anfrage und 3 Single_Prediction -Anforderungen durch.
# 4. Ausführen des Stresstests
- Um die Leistung Ihrer Anwendung unter Final zu bewerten, beginnen Sie, indem Sie Ihre asynchrone Anwendung für maschinelles Lernen in einem Terminal starten.
- Öffnen Sie Ihren Browser und navigieren Sie zu http: // localhost: 8000/docs. Verwenden Sie die interaktive API -Dokumentation, um Ihre Endpunkte zu testen und sicherzustellen, dass sie korrekt funktionieren.
- Öffnen Sie ein neues Terminalfenster, aktivieren Sie die virtuelle Umgebung und navigieren Sie zum Root -Verzeichnis Ihres Projekts, um HOLUGE mit der Net -Benutzeroberfläche auszuführen:
- Stellen Sie in der LOCUST -Net -Benutzeroberfläche die Gesamtzahl der Benutzer auf 500, die Spawn -Charge auf 10 Benutzer professional Sekunde und führen Sie sie für eine Minute aus.
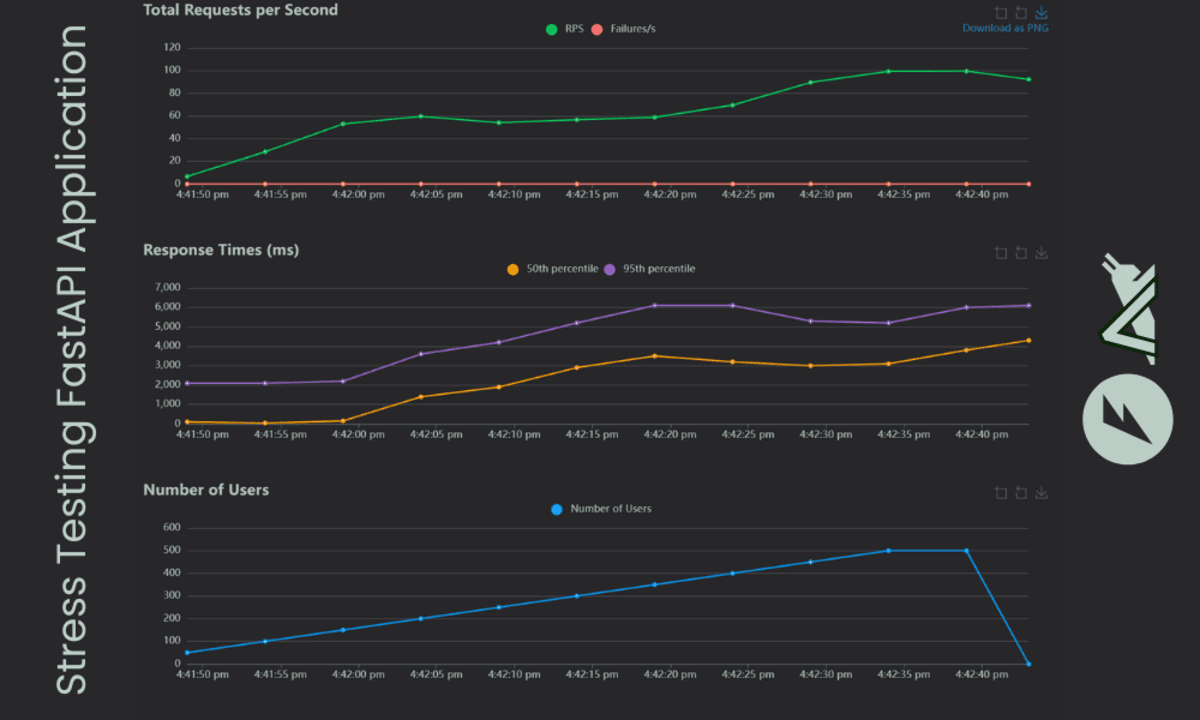
- Während des Checks zeigt Locust Echtzeitstatistiken an, einschließlich der Anzahl der Anforderungen, Fehler und Antwortzeiten für jeden Endpunkt.
- Sobald der Take a look at abgeschlossen ist, klicken Sie auf die Registerkarte „Diagramme“, um interaktive Diagramme anzuzeigen, die die Anzahl der Benutzer, Anforderungen professional Sekunde und Antwortzeiten angezeigt werden.
- Verwenden Sie den folgenden Befehl:
Mannequin loaded efficiently
INFO: Began server course of (26216)
INFO: Ready for utility startup.
INFO: Software startup full.
INFO: Uvicorn operating on http://0.0.0.0:8000 (Press CTRL+C to give up)
locust -f checks/locustfile.py --host http://localhost:8000Greifen Sie auf die Locust Net -Benutzeroberfläche unter http://localhost:8089 in deinem Browser.



locust -f checks/locustfile.py --host http://localhost:8000 --users 500 --spawn-rate 10 --run-time 60s --headless --html report.htmlNach dem Take a look at wird ein HTML -Bericht mit dem Namen Report.html zur späteren Überprüfung in Ihrem Projektverzeichnis gespeichert.

# Letzte Gedanken
Unsere App kann eine große Anzahl von Benutzern verarbeiten, da wir ein einfaches maschinelles Lernmodell verwenden. Die Ergebnisse zeigen, dass der Modell-Information-Endpunkt eine größere Reaktionszeit als die Vorhersage hat, was beeindruckend ist. Dies ist das beste Szenario, um Ihre Anwendung lokal zu testen, bevor Sie sie in die Produktion drücken.
Wenn Sie dieses Setup aus erster Hand erleben möchten, besuchen Sie bitte die Kingabzpro/Stress-Take a look at-Fastapi Repository und befolgen Sie die Anweisungen in der Dokumentation.
Abid Ali Awan (@1abidaliawan) ist ein zertifizierter Datenwissenschaftler, der es liebt, maschinelles Lernenmodelle zu bauen. Derzeit konzentriert er sich auf die Erstellung von Inhalten und das Schreiben von technischen Blogs über maschinelles Lernen und Datenwissenschaftstechnologien. Abid hat einen Grasp -Abschluss in Technologiemanagement und einen Bachelor -Abschluss in Telekommunikationstechnik. Seine Imaginative and prescient ist es, ein KI -Produkt zu bauen, das ein Diagramm neuronales Netzwerk für Schüler mit psychische Erkrankungen mit kämpfender Krankheiten unterhält.