
Bild vom Autor
# Einführung
Die manuelle Erstellung eines Modells für maschinelles Lernen erfordert eine lange Entscheidungskette. Es sind viele Schritte erforderlich, z. B. das Bereinigen der Daten, die Auswahl des richtigen Algorithmus und die Abstimmung der Hyperparameter, um gute Ergebnisse zu erzielen. Dieser Trial-and-Error-Prozess dauert oft Stunden oder sogar Tage. Es gibt jedoch eine Möglichkeit, dieses Drawback mithilfe von zu lösen Baumbasiertes Pipeline-Optimierungstooloder TPOT.
TPOT ist eine Python-Bibliothek, die genetische Algorithmen verwendet, um automatisch nach der besten Pipeline für maschinelles Lernen zu suchen. Es behandelt Pipelines wie eine Inhabitants in der Natur: Es probiert viele Kombinationen aus, bewertet ihre Leistung und „entwickelt“ die besten über mehrere Generationen hinweg weiter. Durch diese Automatisierung können Sie sich auf die Lösung Ihres Issues konzentrieren, während TPOT sich um die technischen Particulars der Modellauswahl und -optimierung kümmert.
# Wie TPOT funktioniert
TPOT nutzt genetische Programmierung (GP). Es handelt sich um eine Artwork evolutionären Algorithmus, der von der natürlichen Selektion in der Biologie inspiriert ist. Anstatt Organismen weiterzuentwickeln, entwickelt GP Computerprogramme oder Arbeitsabläufe, um ein Drawback zu lösen. Im Kontext von TPOT sind die „Programme“, die entwickelt werden, Pipelines für maschinelles Lernen.
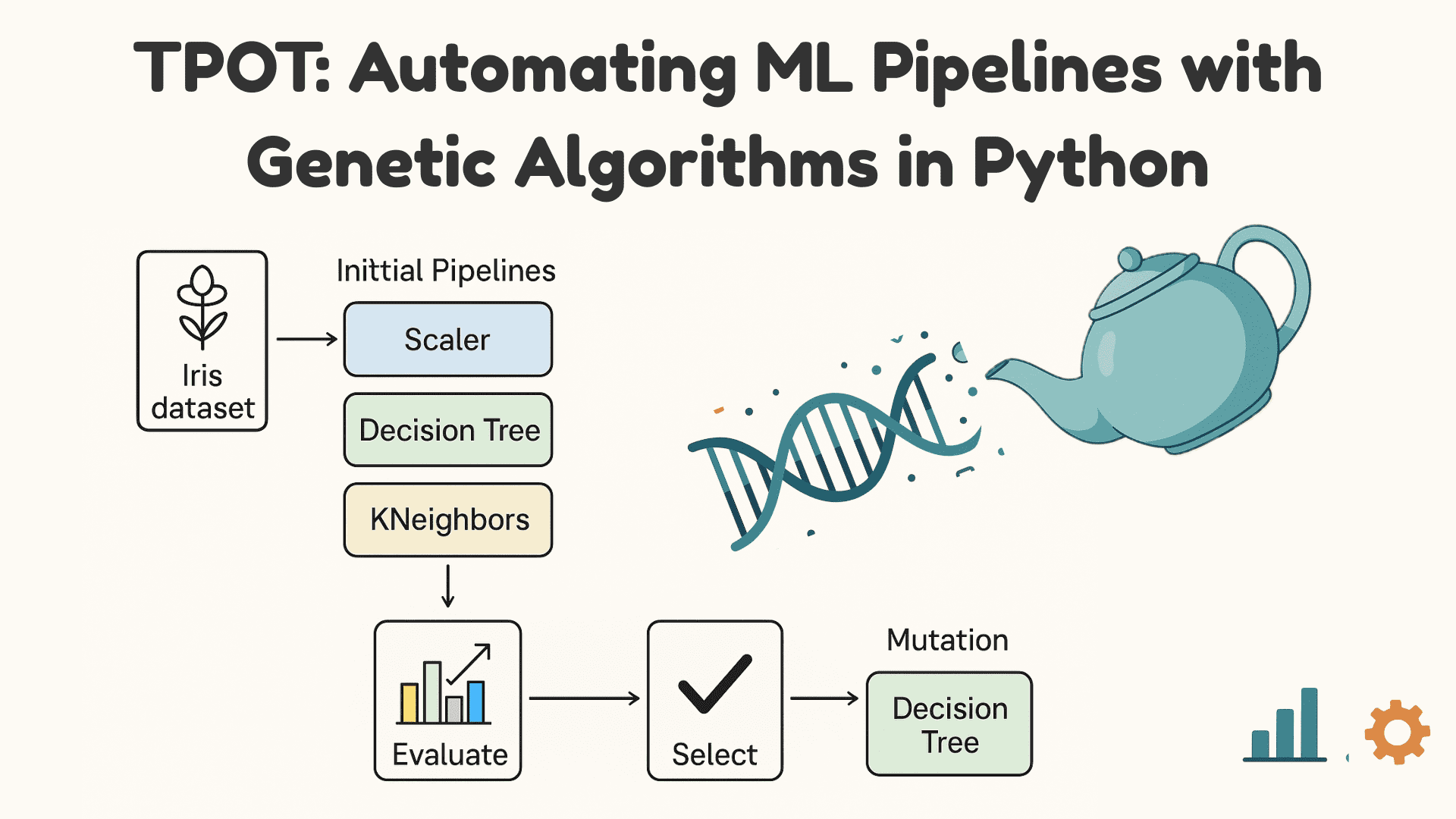
TPOT funktioniert in vier Hauptschritten:
- Pipelines generieren: Es beginnt mit einer zufälligen Inhabitants von Pipelines für maschinelles Lernen, einschließlich Vorverarbeitungsmethoden und -modellen.
- Health bewerten: Jede Pipeline wird anhand der Daten trainiert und bewertet, um die Leistung zu messen.
- Auswahl und Entwicklung: Die leistungsstärksten Pipelines werden ausgewählt, um sie zu „reproduzieren“ und durch Crossover und Mutation neue Pipelines zu erstellen.
- Über Generationen hinweg iterieren: Dieser Vorgang wiederholt sich über mehrere Generationen, bis TPOT die Pipeline mit der besten Leistung identifiziert.
Der Prozess ist im folgenden Diagramm dargestellt:

Als nächstes schauen wir uns an, wie man TPOT in Python einrichtet und verwendet.
# 1. TPOT installieren
Um TPOT zu installieren, führen Sie den folgenden Befehl aus:
# 2. Bibliotheken importieren
Importieren Sie die erforderlichen Bibliotheken:
from tpot import TPOTClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 3. Laden und Aufteilen von Daten
Für dieses Beispiel verwenden wir den beliebten Iris-Datensatz:
iris = load_iris()
X, y = iris.knowledge, iris.goal
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Der load_iris() Die Funktion stellt die Funktionen bereit X und Etiketten y. Der train_test_split Die Funktion stellt einen Testsatz bereit, damit Sie die endgültige Leistung anhand unsichtbarer Daten messen können. Dadurch wird eine Umgebung vorbereitet, in der Pipelines bewertet werden. Alle Pipelines werden im Trainingsteil trainiert und intern validiert.
Notiz: TPOT verwendet während der Fitnessbewertung eine interne Kreuzvalidierung.
# 4. TPOT initialisieren
Initialisieren Sie TPOT wie folgt:
tpot = TPOTClassifier(
generations=5,
population_size=20,
random_state=42
)Sie können steuern, wie lange und wie umfassend TPOT nach einer guten Pipeline sucht. Zum Beispiel:
- Generationen=5 bedeutet, dass TPOT fünf Evolutionszyklen durchlaufen wird. In jedem Zyklus wird basierend auf der vorherigen Technology ein neuer Satz Kandidatenpipelines erstellt.
- Populationsgröße=20 bedeutet, dass in jeder Technology 20 Kandidaten-Pipelines vorhanden sind.
- random_state stellt sicher, dass die Ergebnisse reproduzierbar sind.
# 5. Trainieren des Modells
Trainieren Sie das Modell, indem Sie diesen Befehl ausführen:
tpot.match(X_train, y_train)Wenn du rennst tpot.match(X_train, y_train)TPOT beginnt mit der Suche nach der besten Pipeline. Es erstellt eine Gruppe von Kandidaten-Pipelines, trainiert jede einzelne, um zu sehen, wie intestine sie funktioniert (normalerweise mithilfe einer Kreuzvalidierung), und behält die Prime-Performer. Anschließend werden sie gemischt und leicht verändert, um eine neue Gruppe zu bilden. Dieser Zyklus wiederholt sich für die von Ihnen festgelegte Anzahl von Generationen. TPOT merkt sich immer, welche Pipeline bisher die beste Leistung erbracht hat.
Ausgabe:

# 6. Bewertung der Genauigkeit
Dies ist Ihre letzte Überprüfung, wie sich die ausgewählte Pipeline bei unsichtbaren Daten verhält. Sie können die Genauigkeit wie folgt berechnen:
y_pred = tpot.fitted_pipeline_.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print("Accuracy:", acc)Ausgabe:
# 7. Exportieren der besten Pipeline
Sie können die Pipeline zur späteren Verwendung in eine Datei exportieren. Beachten Sie, dass wir importieren müssen dump aus Joblib Erste:
from joblib import dump
dump(tpot.fitted_pipeline_, "best_pipeline.pkl")
print("Pipeline saved as best_pipeline.pkl")joblib.dump() Speichert das gesamte angepasste Modell als best_pipeline.pkl.
Ausgabe:
Pipeline saved as best_pipeline.pklSie können es später wie folgt laden:
from joblib import load
mannequin = load("best_pipeline.pkl")
predictions = mannequin.predict(X_test)Dadurch wird Ihr Modell wiederverwendbar und einfach bereitzustellen.
# Zusammenfassung
In diesem Artikel haben wir gesehen, wie Pipelines für maschinelles Lernen mithilfe genetischer Programmierung automatisiert werden können, und wir sind auch ein praktisches Beispiel für die Implementierung von TPOT in Python durchgegangen. Für weitere Erkundungen konsultieren Sie bitte die Dokumentation.
Kanwal Mehreen ist ein Ingenieur für maschinelles Lernen und ein technischer Redakteur mit einer großen Leidenschaft für Datenwissenschaft und die Schnittstelle zwischen KI und Medizin. Sie ist Mitautorin des E-Books „Maximizing Productiveness with ChatGPT“. Als Google Technology Scholar 2022 für APAC setzt sie sich für Vielfalt und akademische Exzellenz ein. Sie ist außerdem als Teradata Range in Tech Scholar, Mitacs Globalink Analysis Scholar und Harvard WeCode Scholar anerkannt. Kanwal ist ein leidenschaftlicher Verfechter von Veränderungen und hat FEMCodes gegründet, um Frauen in MINT-Bereichen zu stärken.