

Bild vom Autor
# Einführung
Letzten Monat starrte ich auf meinen Kontoauszug und versuchte herauszufinden, wohin mein Geld eigentlich floss. Tabellenkalkulationen fühlten sich umständlich an. Bestehende Apps sind wie Blackboxen und das Schlimmste ist, dass sie verlangen, dass ich meine sensiblen Finanzdaten auf einen Cloud-Server hochlade. Ich wollte etwas anderes. Ich wollte einen KI-Datenanalysten, der meine Ausgaben analysieren, ungewöhnliche Transaktionen erkennen und mir klare Erkenntnisse liefern kann – und das alles, während meine Daten zu 100 % lokal bleiben. Additionally habe ich eins gebaut.
Was als Wochenendprojekt begann, entwickelte sich zu einem tiefen Einblick in die Vorverarbeitung realer Daten, praktisches maschinelles Lernen und die Leistungsfähigkeit von Native große Sprachmodelle (LLMs). In diesem Artikel werde ich Ihnen zeigen, wie ich mithilfe von eine KI-gestützte Finanzanalyse-App erstellt habe Python mit „Vibe Coding“. Unterwegs lernen Sie viele praktische Konzepte kennen, die auf jedes Information-Science-Projekt anwendbar sind, unabhängig davon, ob Sie Verkaufsprotokolle, Sensordaten oder Kundenfeedback analysieren.
Am Ende werden Sie verstehen:
- So erstellen Sie eine robuste Datenvorverarbeitungspipeline, die chaotische, reale CSV-Dateien verarbeitet
- So wählen Sie Modelle für maschinelles Lernen aus und implementieren sie, wenn Sie nur über begrenzte Trainingsdaten verfügen
- So entwerfen Sie interaktive Visualisierungen, die tatsächlich Benutzerfragen beantworten
- So integrieren Sie ein lokales LLM, um Erkenntnisse in natürlicher Sprache zu generieren, ohne die Privatsphäre zu beeinträchtigen
Der vollständige Quellcode ist verfügbar unter GitHub. Fühlen Sie sich frei, es zu forken, zu erweitern oder als Ausgangspunkt für Ihren eigenen KI-Datenanalysten zu verwenden.
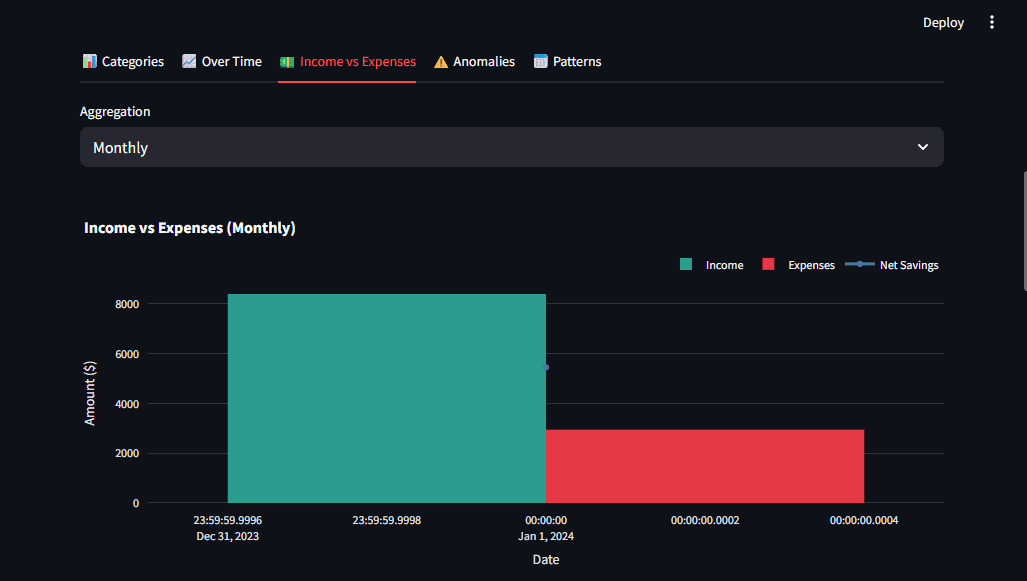
Abb. 1: App-Dashboard mit Ausgabenaufschlüsselung und KI-Einblicken | Bild vom Autor
# Das Downside: Warum ich das gebaut habe
Die meisten persönlichen Finanz-Apps haben einen grundlegenden Fehler: Ihre Daten unterliegen Ihrer Kontrolle. Sie laden Kontoauszüge bei Diensten hoch, die Ihre Informationen speichern, verarbeiten und möglicherweise monetarisieren. Ich wollte ein Werkzeug, das:
- Lassen Sie mich Daten sofort hochladen und analysieren
- Alles lokal verarbeitet – keine Cloud, keine Datenlecks
- Bereitstellung KI-gestützter Erkenntnisse, nicht nur statischer Diagramme
Dieses Projekt wurde zu meinem Instrument, um mehrere Konzepte zu erlernen, die jeder Datenwissenschaftler kennen sollte, wie den Umgang mit inkonsistenten Datenformaten, die Auswahl von Algorithmen, die mit kleinen Datensätzen arbeiten, und die Entwicklung datenschutzschützender KI-Funktionen.
# Projektarchitektur
Bevor wir uns mit dem Code befassen, finden Sie hier eine Projektstruktur, die zeigt, wie die Teile zusammenpassen:
undertaking/
├── app.py # Primary Streamlit app
├── config.py # Settings (classes, Ollama config)
├── preprocessing.py # Auto-detect CSV codecs, normalize information
├── ml_models.py # Transaction classifier + Isolation Forest anomaly detector
├── visualizations.py # Plotly charts (pie, bar, timeline, heatmap)
├── llm_integration.py # Ollama streaming integration
├── necessities.txt # Dependencies
├── README.md # Documentation with "deep dive" classes
└── sample_data/
├── sample_bank_statement.csv
└── sample_bank_format_2.csv
Wir werden uns den Aufbau jeder Ebene Schritt für Schritt ansehen.
# Schritt 1: Aufbau einer robusten Datenvorverarbeitungspipeline
Die erste Lektion, die ich gelernt habe, warfare, dass reale Daten chaotisch sind. Verschiedene Banken exportieren CSVs in völlig unterschiedlichen Formaten. Chase Financial institution verwendet „Transaktionsdatum“ und „Betrag“. Financial institution of America verwendet die Spalten „Datum“, „Zahlungsempfänger“ und „Soll“https://www.kdnuggets.com/„Kredit“. Moniepoint und OPay haben jeweils ihre eigenen Stile.
Eine Vorverarbeitungspipeline muss diese Unterschiede automatisch verarbeiten.
// Automatische Erkennung von Spaltenzuordnungen
Ich habe ein Mustervergleichssystem erstellt, das Spalten unabhängig von Namenskonventionen identifiziert. Mithilfe regulärer Ausdrücke können wir unklare Spaltennamen auf Standardfelder abbilden.
import re
COLUMN_PATTERNS = {
"date": (r"date", r"trans.*date", r"posting.*date"),
"description": (r"description", r"memo", r"payee", r"service provider"),
"quantity": (r"^quantity$", r"transaction.*quantity"),
"debit": (r"debit", r"withdrawal", r"expense"),
"credit score": (r"credit score", r"deposit", r"revenue"),
}
def detect_column_mapping(df):
mapping = {}
for area, patterns in COLUMN_PATTERNS.gadgets():
for col in df.columns:
for sample in patterns:
if re.search(sample, col.decrease()):
mapping(area) = col
break
return mappingDie wichtigste Erkenntnis: Design für Unterschiede, nicht für bestimmte Formate. Dieser Ansatz funktioniert für jede CSV-Datei, die gängige Finanzbegriffe verwendet.
// Normalisierung auf ein Standardschema
Sobald Spalten erkannt werden, werden wir normalisieren alles in eine einheitliche Struktur. Beispielsweise müssen Banken, die Soll- und Gutschriften aufteilen, in einer einzigen Betragsspalte zusammengefasst werden (negativ für Ausgaben, positiv für Einnahmen):
if "debit" in mapping and "credit score" in mapping:
debit = df(mapping("debit")).apply(parse_amount).abs() * -1
credit score = df(mapping("credit score")).apply(parse_amount).abs()
normalized("quantity") = credit score + debitSchlüssel zum Mitnehmen: Normalisieren Sie Ihre Daten so schnell wie möglich. Es vereinfacht alle folgenden Vorgänge, wie Function-Engineering, Modellierung durch maschinelles Lernen und Visualisierung.
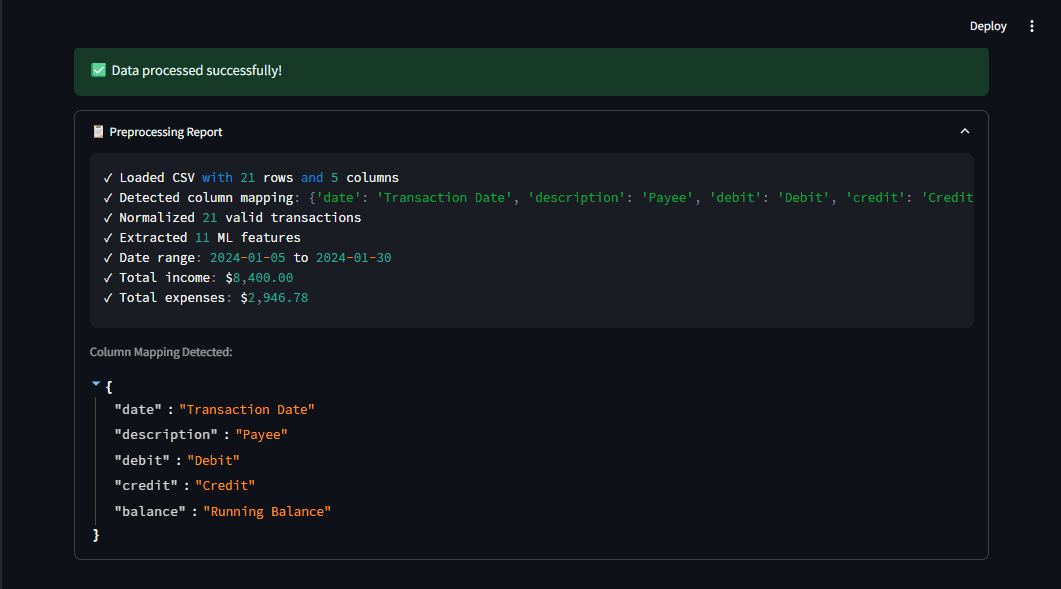
Abb. 2: Der Vorverarbeitungsbericht zeigt, was die Pipeline erkannt hat, und gibt Benutzern Transparenz | Bild vom Autor
# Schritt 2: Auswählen von Modellen für maschinelles Lernen für begrenzte Daten
Die zweite große Herausforderung sind begrenzte Trainingsdaten. Benutzer laden ihre eigenen Aussagen hoch und es gibt keinen umfangreichen beschrifteten Datensatz zum Trainieren eines Deep-Studying-Modells. Wir brauchen Algorithmen, die mit kleinen Stichproben intestine funktionieren und mit einfachen Regeln erweitert werden können.
// Transaktionsklassifizierung: Ein hybrider Ansatz
Anstelle von reinem maschinellem Lernen habe ich ein Hybridsystem aufgebaut:
- Regelbasierter Abgleich für sichere Fälle (z. B. Schlüsselwörter wie „WALMART“ → Lebensmittel)
- Musterbasierter Fallback für mehrdeutige Transaktionen
SPENDING_CATEGORIES = {
"groceries": ("walmart", "costco", "entire meals", "kroger"),
"eating": ("restaurant", "starbucks", "mcdonald", "doordash"),
"transportation": ("uber", "lyft", "shell", "chevron", "fuel"),
# ... extra classes
}
def classify_transaction(description, quantity):
for class, key phrases in SPENDING_CATEGORIES.gadgets():
if any(kw in description.decrease() for kw in key phrases):
return class
return "revenue" if quantity > 0 else "different"Dieser Ansatz funktioniert sofort ohne Trainingsdaten und ist für Benutzer leicht zu verstehen und anzupassen.
// Anomalieerkennung: Warum Isolation Forest?
Um ungewöhnliche Ausgaben zu erkennen, brauchte ich einen Algorithmus, der Folgendes konnte:
- Arbeiten Sie mit kleinen Datensätzen (im Gegensatz zu tiefes Lernen)
- Machen Sie keine Annahmen über die Datenverteilung (im Gegensatz zu statistischen Methoden wie dem Z-Rating allein).
- Stellen Sie schnelle Vorhersagen für eine interaktive Benutzeroberfläche bereit
Isolationswald von scikit-lernen hat alle Kriterien erfüllt. Es isoliert Anomalien durch zufällige Partitionierung der Daten. Da es nur wenige und unterschiedliche Anomalien gibt, sind zur Isolierung weniger Aufteilungen erforderlich.
from sklearn.ensemble import IsolationForest
detector = IsolationForest(
contamination=0.05, # Anticipate ~5% anomalies
random_state=42
)
detector.match(options)
predictions = detector.predict(options) # -1 = anomalyIch habe dies auch mit einfachen Z-Rating-Prüfungen kombiniert, um offensichtliche Ausreißer zu erkennen. A Z-Rating beschreibt die Place eines Rohwerts in Bezug auf seinen Abstand vom Mittelwert, gemessen in Standardabweichungen:
(
z = frac{x – mu}{sigma}
)
Der kombinierte Ansatz erkennt mehr Anomalien als jede der beiden Methoden allein.
Schlüssel zum Mitnehmen: Manchmal übertreffen einfache, intestine ausgewählte Algorithmen komplexe Algorithmen, insbesondere wenn Sie nur über begrenzte Daten verfügen.
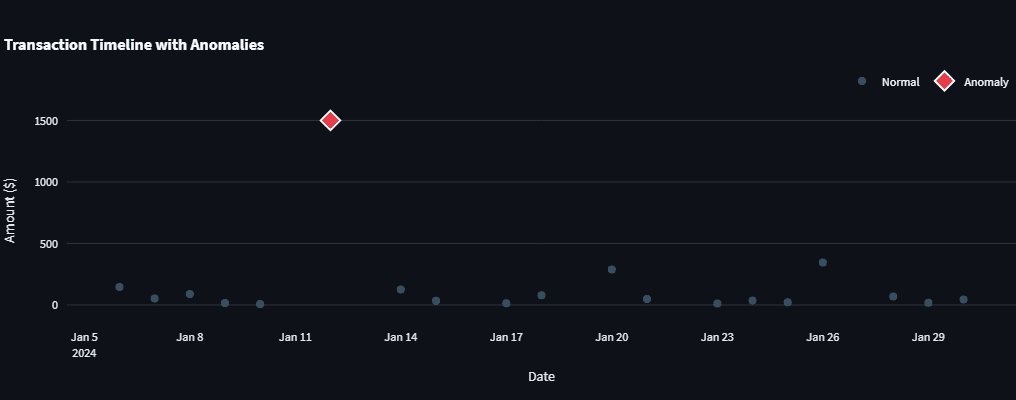
Abb. 3: Der Anomaliedetektor markiert ungewöhnliche Transaktionen, die in der Zeitleiste auffallen | Bild vom Autor
# Schritt 3: Entwerfen von Visualisierungen, die Fragen beantworten
Visualisierungen sollten Fragen beantworten und nicht nur Daten anzeigen. Ich habe verwendet Plotly für interaktive Diagramme, da es Benutzern ermöglicht, die Daten selbst zu erkunden. Hier sind die Designprinzipien, denen ich gefolgt bin:
- Einheitliche Farbkodierung: Rot für Ausgaben, Grün für Einnahmen
- Kontext durch Vergleich: Zeigen Sie Einnahmen und Ausgaben nebeneinander an
- Progressive Offenlegung: Zeigen Sie zuerst eine Zusammenfassung an und lassen Sie die Benutzer dann einen Drilldown durchführen
Die Ausgabenaufschlüsselung verwendet beispielsweise ein Donut-Diagramm mit einem Loch in der Mitte für ein übersichtlicheres Erscheinungsbild:
import plotly.specific as px
fig = px.pie(
category_totals,
values="Quantity",
names="Class",
gap=0.4,
color_discrete_map=CATEGORY_COLORS
)Streamlit erleichtert das Hinzufügen dieser Diagramme st.plotly_chart() und ein reaktionsfähiges Dashboard erstellen.
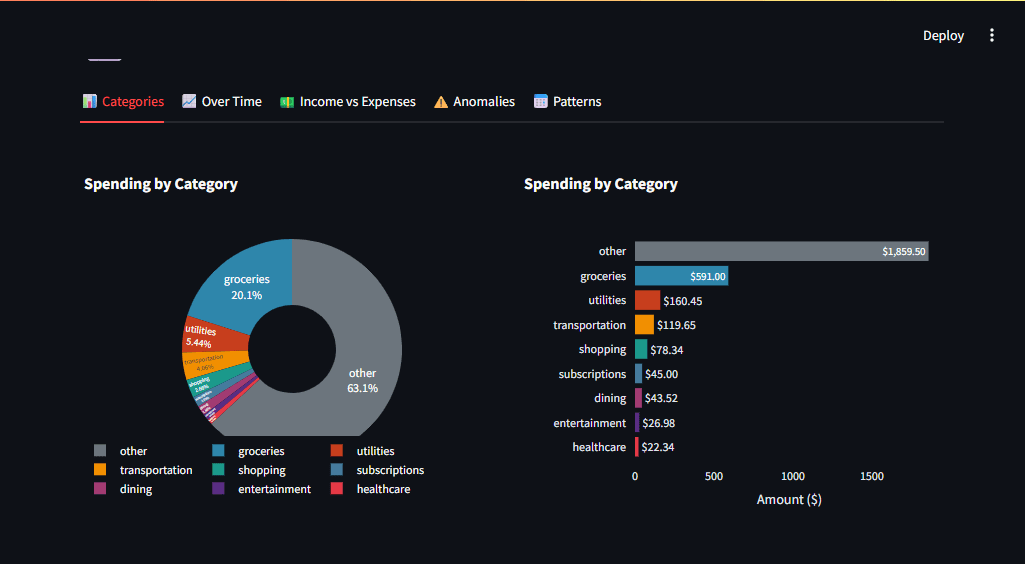
Abb. 4: Mehrere Diagrammtypen bieten Benutzern unterschiedliche Perspektiven auf dieselben Daten | Bild vom Autor
# Schritt 4: Integration eines lokalen großen Sprachmodells für Einblicke in natürliche Sprachen
Das letzte Stück bestand darin, für Menschen lesbare Erkenntnisse zu generieren. Ich habe mich für die Integration entschieden Ollamaein Software zum lokalen Ausführen von LLMs. Warum vor Ort statt anrufen OpenAI oder Claude?
- Datenschutz: Bankdaten verlassen nie den Automaten
- Kosten: Unbegrenzte Abfragen, keine API-Gebühren
- Geschwindigkeit: Keine Netzwerklatenz (obwohl die Generierung noch einige Sekunden dauert)
// Streaming für eine bessere Benutzererfahrung
Es kann mehrere Sekunden dauern, bis LLMs eine Antwort generieren. Streamlit zeigt Token an, sobald sie eintreffen, sodass sich die Wartezeit kürzer anfühlt. Hier ist eine einfache Implementierung mit requests mit Streaming:
import requests
import json
def generate(self, immediate):
response = requests.submit(
f"{self.base_url}/api/generate",
json={"mannequin": "llama3.2", "immediate": immediate, "stream": True},
stream=True
)
for line in response.iter_lines():
if line:
information = json.masses(line)
yield information.get("response", "")In Streamlit können Sie dies mit anzeigen st.write_stream().
st.write_stream(llm.get_overall_insights(df))// Immediate Engineering für Finanzdaten
Der Schlüssel zu einer nützlichen LLM-Ausgabe ist eine strukturierte Eingabeaufforderung, die tatsächliche Daten enthält. Zum Beispiel:
immediate = f"""Analyze this monetary abstract:
- Complete Revenue: ${revenue:,.2f}
- Complete Bills: ${bills:,.2f}
- Prime Class: {top_category}
- Largest Anomaly: {anomaly_desc}
Present 2-3 actionable suggestions based mostly on this information."""Dadurch erhält das Modell konkrete Zahlen, mit denen es arbeiten kann, was zu relevanteren Erkenntnissen führt.
Abb. 5: Die Add-Schnittstelle ist einfach; Wählen Sie eine CSV-Datei und lassen Sie die KI den Relaxation erledigen | Bild vom Autor
// Ausführen der Anwendung
Der Einstieg ist unkompliziert. Sie müssen Python installiert haben und dann Folgendes ausführen:
pip set up -r necessities.txt
# Optionally available, for AI insights
ollama pull llama3.2
streamlit run app.pyLaden Sie eine beliebige Financial institution-CSV-Datei hoch (die App erkennt das Format automatisch) und innerhalb von Sekunden sehen Sie ein Dashboard mit kategorisierten Transaktionen, Anomalien und KI-generierten Erkenntnissen.
# Abschluss
Dieses Projekt hat mich gelehrt, dass der Aufbau von etwas Funktionalem erst der Anfang ist. Das wirkliche Lernen geschah, als ich fragte, warum jedes Stück funktioniert:
- Warum Spalten automatisch erkennen? Weil reale Daten nicht Ihrem Schema folgen. Der Aufbau einer flexiblen Pipeline erspart stundenlanges manuelles Aufräumen.
- Warum Isolationswald? Weil kleine Datensätze speziell für sie entwickelte Algorithmen benötigen. Sie brauchen nicht immer tiefes Lernen.
- Warum lokale LLMs? Weil Datenschutz und Kosten bei der Produktion eine Rolle spielen. Das lokale Ausführen von Modellen ist jetzt praktisch und leistungsstark.
Diese Lektionen gelten weit über die persönlichen Finanzen hinaus, unabhängig davon, ob Sie Verkaufsdaten, Serverprotokolle oder wissenschaftliche Messungen analysieren. Die gleichen Prinzipien der robusten Vorverarbeitung, der pragmatischen Modellierung und der datenschutzbewussten KI kommen Ihnen bei jedem Datenprojekt zugute.
Der vollständige Quellcode ist auf GitHub verfügbar. Teilen Sie es, erweitern Sie es und machen Sie es zu Ihrem eigenen. Wenn du damit etwas Cooles baust, würde ich gerne davon hören.
// Referenzen
Shittu Olumid ist ein Software program-Ingenieur und technischer Autor, der sich leidenschaftlich dafür einsetzt, modernste Technologien zu nutzen, um fesselnde Erzählungen zu erschaffen, mit einem scharfen Blick fürs Element und einem Gespür für die Vereinfachung komplexer Konzepte. Sie können Shittu auch auf finden Twitter.