

Bild vom Herausgeber
# Einführung
Erhalten beschriftete Daten – additionally Daten mit Floor-Reality-Zielbezeichnungen – sind ein grundlegender Schritt für die Erstellung der meisten überwachten Modelle für maschinelles Lernen wie Random Forests, logistische Regression oder auf neuronalen Netzwerken basierende Klassifikatoren. Auch wenn eine große Schwierigkeit bei vielen realen Anwendungen darin besteht, eine ausreichende Menge an beschrifteten Daten zu erhalten, gibt es Zeiten, in denen es, auch nachdem dieses Kästchen angekreuzt wurde, noch eine weitere wichtige Herausforderung geben kann: Klassenungleichgewicht.
Klassenungleichgewicht tritt auf, wenn ein beschrifteter Datensatz Klassen mit sehr unterschiedlichen Beobachtungszahlen enthält, wobei in der Regel eine oder mehrere Klassen stark unterrepräsentiert sind. Dieses Downside führt häufig zu Problemen beim Erstellen eines Modells für maschinelles Lernen. Anders ausgedrückt: Das Trainieren eines Vorhersagemodells wie eines Klassifikators auf unausgeglichene Daten führt zu Problemen wie verzerrten Entscheidungsgrenzen, schlechter Erinnerung an die Minderheitsklasse und irreführend hoher Genauigkeit, was in der Praxis bedeutet, dass das Modell „auf dem Papier“ intestine funktioniert, aber nach der Implementierung in kritischen Fällen versagt, die uns am meisten am Herzen liegen – die Betrugserkennung bei Banktransaktionen ist ein klares Beispiel dafür, wobei Transaktionsdatensätze extrem unausgewogen sind, da etwa 99 % der Transaktionen legitim sind.
Artificial Minority Oversampling-Technik (SMOTE) ist eine datenfokussierte Resampling-Technik zur Bewältigung dieses Issues, indem mithilfe von Interpolationstechniken zwischen vorhandenen realen Instanzen synthetisch neue Stichproben generiert werden, die zur Minderheitsklasse gehören, z. B. betrügerische Transaktionen.
In diesem Artikel wird SMOTE kurz vorgestellt und anschließend erklärt, wie man es richtig anwendet, warum es oft falsch verwendet wird und wie man diese Situationen vermeidet.
# Was SMOTE ist und wie es funktioniert
SMOTE ist eine Datenerweiterungstechnik zur Behebung von Klassenungleichgewichtsproblemen beim maschinellen Lernen, insbesondere in überwachten Modellen wie Klassifikatoren. Wenn bei der Klassifizierung mindestens eine Klasse im Vergleich zu anderen deutlich unterrepräsentiert ist, kann das Modell leicht auf die Mehrheitsklasse ausgerichtet sein, was zu einer schlechten Leistung führt, insbesondere wenn es um die Vorhersage der seltenen Klasse geht.
Um diese Herausforderung zu bewältigen, erstellt SMOTE synthetische Datenbeispiele für die Minderheitsklasse, indem es nicht nur vorhandene Instanzen so repliziert, wie sie sind, sondern indem es zwischen einer Stichprobe aus der Minderheitsklasse und ihren nächsten Nachbarn im Raum der verfügbaren Merkmale interpoliert: Dieser Prozess gleicht im Wesentlichen dem effektiven „Ausfüllen“ von Lücken in Regionen, um die sich bestehende Minderheitsinstanzen bewegen, und hilft so dabei, den Datensatz auszubalancieren.
SMOTE iteriert über jedes Minderheitsbeispiel, identifiziert seine ( ok ) nächsten Nachbarn und generiert dann einen neuen synthetischen Punkt entlang der „Linie“ zwischen der Stichprobe und einem zufällig ausgewählten Nachbarn. Das Ergebnis der iterativen Anwendung dieser einfachen Schritte ist ein neuer Satz von Beispielen für Minderheitenklassen, sodass der Prozess zum Trainieren des Modells auf der Grundlage einer umfassenderen Darstellung der Minderheitsklasse(n) im Datensatz erfolgt und ein effektiveres, weniger voreingenommenes Modell entsteht.
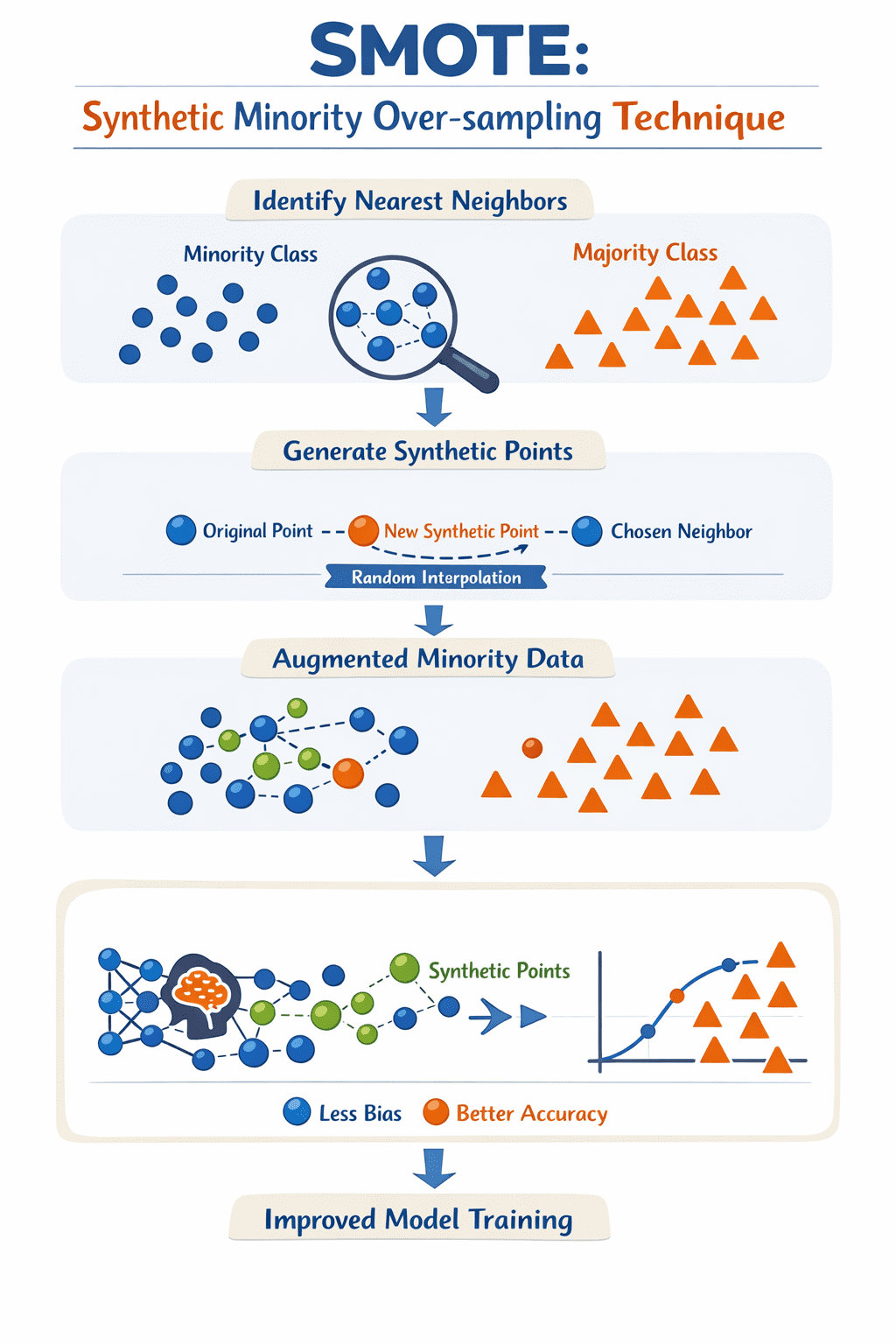
So funktioniert SMOTE | Bild vom Autor
# SMOTE richtig in Python implementieren
Um die zuvor erwähnten Datenverlustprobleme zu vermeiden, ist es am besten, eine Pipeline zu verwenden. Der unausgeglichen-lernen Die Bibliothek stellt ein Pipeline-Objekt bereit, das sicherstellt, dass SMOTE nur während jeder Faltung einer Kreuzvalidierung oder während einer einfachen Maintain-out-Aufteilung auf die Trainingsdaten angewendet wird, sodass der Testsatz unberührt bleibt und für reale Daten repräsentativ bleibt.
Das folgende Beispiel zeigt, wie man SMOTE in ein integriert maschinelles Lernen Workflow mit scikit-learn Und imblearn:
from imblearn.over_sampling import SMOTE
from imblearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# Cut up knowledge into coaching and testing units first
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Outline the pipeline: Resampling then modeling
# The imblearn Pipeline solely applies SMOTE to the coaching knowledge
pipeline = Pipeline((
('smote', SMOTE(random_state=42)),
('classifier', RandomForestClassifier(random_state=42))
))
# Match the pipeline on coaching knowledge
pipeline.match(X_train, y_train)
# Consider on the untouched check knowledge
y_pred = pipeline.predict(X_test)
print(classification_report(y_test, y_pred))Durch die Verwendung der Pipelinestellen Sie sicher, dass die Transformation nur im Trainingskontext erfolgt. Dadurch wird verhindert, dass synthetische Informationen in Ihren Bewertungssatz „einfließen“, und Sie erhalten eine viel ehrlichere Einschätzung, wie Ihr Modell mit unausgeglichenen Klassen in der Produktion umgeht.
# Häufige Missbrauchsfälle von SMOTE
Schauen wir uns drei häufige Arten des Missbrauchs von SMOTE an maschinelles Lernen Arbeitsabläufe und wie man diese Fehlanwendungen vermeidet:
- Anwenden von SMOTE vor der Partitionierung des Datensatzes in Trainings- und Testsätze: Dies ist ein sehr häufiger Fehler, der unerfahrenen Datenwissenschaftlern häufig (und in den meisten Fällen versehentlich) unterlaufen kann. SMOTE generiert neue synthetische Beispiele basierend auf alle verfügbaren Datenund das Einfügen synthetischer Punkte in die späteren Trainings- und Testpartitionen ist das „nicht so perfekte“ Rezept, um die Modellbewertungsmetriken künstlich und unrealistisch aufzublähen. Der richtige Ansatz ist einfach: Teilen Sie zuerst die Daten auf und wenden Sie dann SMOTE nur auf den Trainingssatz an. Denken Sie darüber nach, auch eine k-fache Kreuzvalidierung anzuwenden? Noch besser.
- Übergewicht: Ein weiterer häufiger Fehler besteht darin, blind erneut abzutasten, bis die Klassenanteile exakt übereinstimmen. In vielen Fällen ist das Erreichen dieses perfekten Gleichgewichts nicht nur unnötig, sondern kann angesichts der Domänen- oder Klassenstruktur auch kontraproduktiv und unrealistisch sein. Dies gilt insbesondere für Multiklassen-Datensätze mit mehreren spärlichen Minderheitsklassen, bei denen SMOTE möglicherweise synthetische Beispiele erstellt, die die Grenzen überschreiten oder in Regionen liegen, in denen keine echten Datenbeispiele gefunden werden: Mit anderen Worten, es kann unbeabsichtigt zu Rauschen kommen, mit möglichen unerwünschten Folgen wie einer Modellüberanpassung. Der allgemeine Ansatz besteht darin, behutsam vorzugehen und zu versuchen, Ihr Modell mit subtilen, schrittweisen Erhöhungen der Minderheitenklassenanteile zu trainieren.
- Ignorieren des Kontexts rund um Metriken und Modelle: Die Gesamtgenauigkeitsmetrik eines Modells ist eine leicht zu erhaltende und interpretierbare Metrik, sie kann jedoch auch eine irreführende und „hohle Metrik“ sein, die nicht die Unfähigkeit Ihres Modells widerspiegelt, Fälle der Minderheitenklasse zu erkennen. Dies ist ein kritisches Downside in wichtigen Bereichen wie dem Bankwesen und dem Gesundheitswesen, beispielsweise bei der Erkennung seltener Krankheiten. In der Zwischenzeit kann SMOTE dazu beitragen, die Abhängigkeit von Metriken wie dem Rückruf zu verbessern, kann jedoch dessen Gegenstück, die Präzision, verringern, indem verrauschte synthetische Stichproben eingeführt werden, die möglicherweise nicht mit den Geschäftszielen übereinstimmen. Um nicht nur Ihr Modell, sondern auch die Wirksamkeit von SMOTE in seiner Leistung richtig zu bewerten, konzentrieren Sie sich gemeinsam auf Metriken wie Rückruf, F1-Rating, Matthews-Korrelationskoeffizient (MCC, eine „Zusammenfassung“ einer gesamten Verwirrungsmatrix) oder Präzisionsrückruffläche unter der Kurve (PR-AUC). Erwägen Sie im Rahmen der Anwendung von SMOTE auch various Strategien wie Klassengewichtung oder Schwellenwertoptimierung, um die Effektivität weiter zu steigern.
# Abschließende Bemerkungen
Dieser Artikel drehte sich um SMOTE: eine häufig verwendete Technik, um Klassenungleichgewichte bei der Erstellung einiger Klassifikatoren für maschinelles Lernen auf der Grundlage realer Datensätze zu beheben. Wir haben einige häufige Fehlanwendungen dieser Technik identifiziert und praktische Ratschläge gegeben, um sie zu vermeiden.
Iván Palomares Carrascosa ist ein führender Autor, Redner und Berater in den Bereichen KI, maschinelles Lernen, Deep Studying und LLMs. Er schult und leitet andere darin, KI in der realen Welt zu nutzen.