
Große Sprachmodelle sind großartig. Dem können wir alle zustimmen. Sie sind ein Eckpfeiler der modernen Industrie und wirken sich zunehmend auf immer mehr Bereiche aus.
Angesichts der ständigen Aktualisierungen und Verbesserungen der Architektur und Fähigkeiten von Sprachmodellen könnte man denken: „Das ist es!“ Leider … Eine aktuelle Entwicklung unter dem Namen RLM oder rekursive Sprachmodelle steht jetzt im Mittelpunkt.
Was ist das? Wie hängt es mit LLMs zusammen? Und wie verschiebt es die Grenzen der KI? Wir werden es in diesem Artikel herausfinden, der diese neueste Technologie auf verständliche Weise analysiert. Beginnen wir damit, die Probleme durchzugehen, die aktuelle LLMs plagen.
Ein grundsätzliches Downside
LLMs haben eine architektonische Grenze. Es heißt Token-Fenster. Dies ist die maximale Anzahl an Token, die das Modell in einem Vorwärtsdurchlauf physisch lesen kann, bestimmt durch die Positionseinbettungen + den Speicher des Transformators. Wenn die Eingabe länger als diese Grenze ist, kann das Modell sie nicht verarbeiten. Es ist, als würde man versuchen, eine 5-GB-Datei in ein 500-MB-RAM-Programm zu laden. Es führt zu einem Überlauf! Hier sind die Token-Fenster einiger beliebter Modelle:
| Modell | Max-Token-Fenster |
| Google Gemini (neueste Model) | 1.000.000 |
| OpenAI GPT-5 (neueste Model) | 400.000 |
| Anthropic Claude (neueste) | 200.000 |
Normalerweise gilt: Je größer die Zahl, desto besser das Modell … Oder doch?
Kontextfäule: Der versteckte Fehler vor dem Restrict
Hier ist der Haken. Selbst wenn eine Eingabeaufforderung in das Token-Fenster passt, nimmt die Modellqualität mit zunehmender Länge der Eingabe stillschweigend ab. Die Aufmerksamkeit wird diffus, frühere Informationen verlieren an Einfluss und das Modell beginnt, Verbindungen über entfernte Textteile hinweg zu übersehen. Dieses Phänomen ist bekannt als Kontextfäule.
Obwohl ein Modell technisch gesehen 1 Million Token akzeptieren kann, ist dies oft nicht möglich Grund zuverlässig in allen Bereichen. In der Praxis bricht die Leistung lange vor Erreichen des Token-Fensters ein.
Kontextfenster

Kontextfenster ist wie viele Informationen das Modell tatsächlich nutzen kann, lange bevor die Leistung einbricht. Diese Zahl ändert sich je nach Komplexität der Eingabeaufforderung und der Artwork der verarbeiteten Daten. Der wirksam Das Kontextfenster eines LLM ist viel kleiner als das Tokenfenster. Und im Gegensatz zum Token-Fenster, das mehr oder weniger eindeutig ist, ändert sich das Kontextfenster mit der Komplexität der Eingabeaufforderung. Dies zeigt sich an der schlechten Leistung von LLMs mit großen Tokenfenstern bei Argumentationsaufgaben, da quick alle gleichzeitig zugeführten Informationen beibehalten werden müssen.
Das ist ein Downside. Lange Kontextfenster und folglich Token-Fenster sind wünschenswert, aber ein Kontextverlust (aufgrund ihrer Länge) ist unvermeidbar … oder zumindest so Conflict.
Rekursive Sprachmodelle: Zur Rettung
Trotz des Namens handelt es sich bei RLMs nicht um eine neue Modellklasse wie LLM. VLMSLM usw. Stattdessen ist es ein Inferenzstrategie. Eine Lösung für das Downside der Kontextfäule in langen Eingabeaufforderungen. RLMs behandeln lange Eingabeaufforderungen als Teil einer externen Umgebung und ermöglichen dies LLM um sich über Ausschnitte der Eingabeaufforderung programmgesteuert zu untersuchen, zu zerlegen und rekursiv aufzurufen.
Dadurch wird das Kontextfenster effektiv um ein Vielfaches größer als üblich. Dies geschieht auf ähnliche Weise:
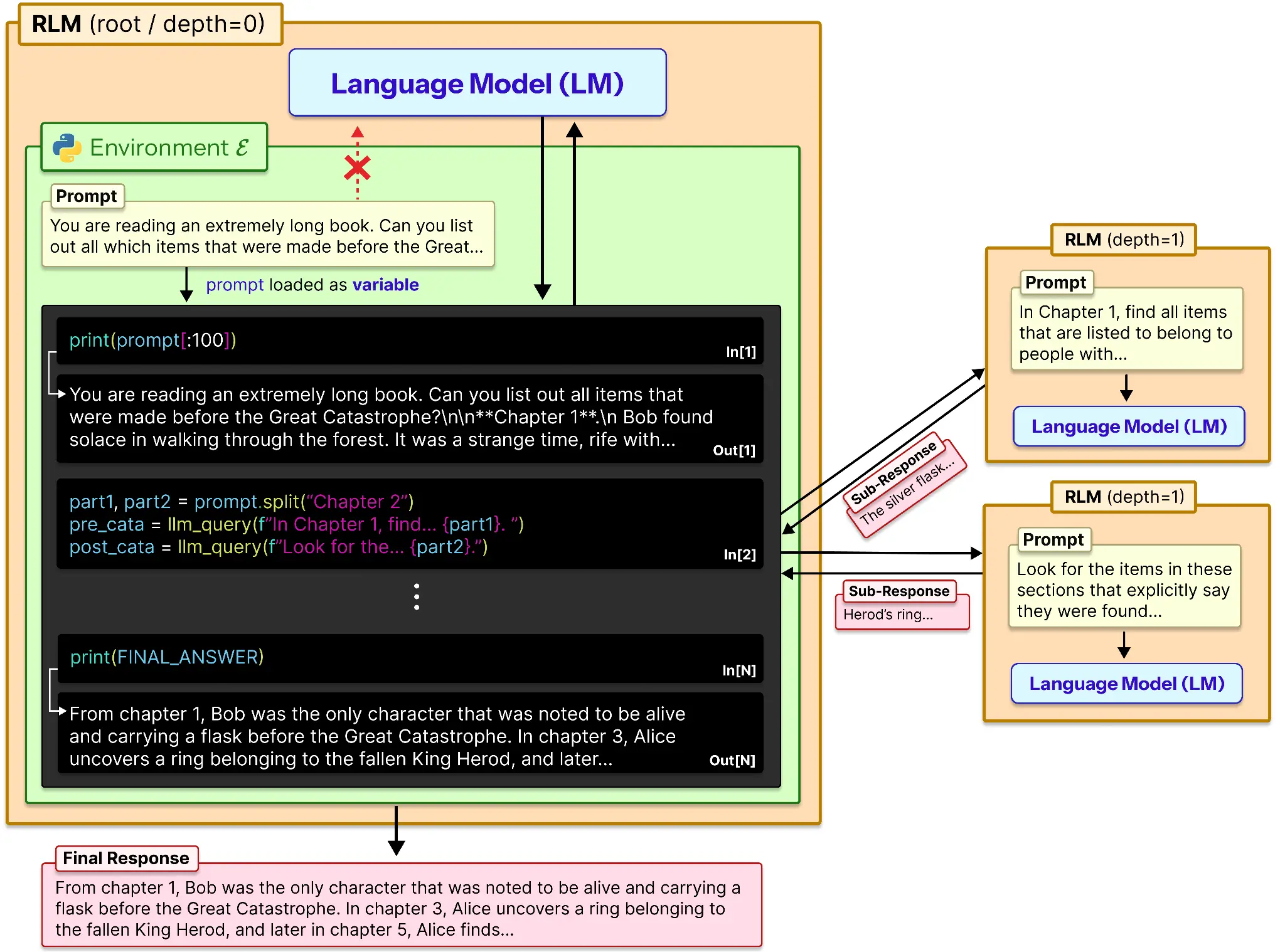
Konzeptionell bietet RLM einen externen LLM-Speicher und eine Möglichkeit, damit zu arbeiten. So funktioniert es:
- Die Eingabeaufforderung wird in eine Variable geladen.
- Diese Variable wird abhängig vom Speicher oder einer fest codierten Zahl gespleißt.
- Diese Daten werden an das LLM gesendet und ihre Ausgabe wird als Referenz gespeichert.
- Ebenso werden alle Teile der Eingabeaufforderung einzeln verarbeitet und ihre Ausgaben aufgezeichnet.
- Diese Liste von Ausgaben wird verwendet, um die endgültige Antwort des Modells zu erzeugen.
Ein Untermodell wie o3-mini oder ein anderes praktisches Modell könnte verwendet werden, um das Modell bei der Zusammenfassung oder Begründung lokal in einer Untereingabeaufforderung zu unterstützen.
Ist das nicht… Chunking?
Auf den ersten Blick magazine das wie verherrlichtes Chunking aussehen. Aber es ist grundlegend anders. Beim herkömmlichen Chunking wird das Modell dazu gezwungen, frühere Teile zu vergessen, während es sich vorwärts bewegt. RLM hält alles außerhalb des Modells am Leben und ermöglicht es dem LLM, jedes Teil bei Bedarf selektiv erneut aufzurufen. Es geht nicht darum, die Erinnerung zusammenzufassen, sondern darin zu navigieren.
Welche Probleme RLM endlich löst
RLM macht Dinge frei, an denen normale LLMs regelmäßig scheitern:
- Argumentation zu massiven Daten: Anstatt frühere Teile zu vergessen, kann das Modell jeden Abschnitt großer Eingaben erneut aufrufen.
- Synthese mehrerer Dokumente: Es zieht Beweise aus verstreuten Quellen, ohne an Kontextgrenzen zu stoßen.
- Informationsreiche Aufgaben: Funktioniert auch dann, wenn die Antworten von quick jeder Zeile der Eingabe abhängen.
- Lange strukturierte Ausgaben: Erstellt Ergebnisse außerhalb des Token-Fensters und fügt sie sauber zusammen.
Kurz gesagt: Mit RLM können LLMs Skalierung, Dichte und Struktur verwalten, die herkömmliche Eingabeaufforderungen übertreffen.
Die Kompromisse
Bei allem, was RLM löst, gibt es auch ein paar Nachteile:
| Einschränkung | Auswirkungen |
| Sofortige Nichtübereinstimmung zwischen den Modellen | Die gleiche RLM-Eingabeaufforderung führt zu instabilem Verhalten und übermäßigen rekursiven Aufrufen |
| Erfordert starke Programmierfähigkeiten | Schwächere Modelle können den Kontext in der REPL nicht zuverlässig manipulieren |
| Erschöpfung des Ausgabetokens | Lange Argumentationsketten überschreiten die Ausgabegrenzen und verkürzen die Trajektorien |
| Keine asynchronen Unteraufrufe | Sequentielle Rekursion erhöht die Latenz erheblich |
Kurz gesagt: RLM tauscht pure Geschwindigkeit und Stabilität gegen Skalierbarkeit und Tiefe.
Abschluss
Skalierende LLMs bedeuteten früher mehr Parameter und größere Token-Fenster. RLM führt eine dritte Achse ein: die Inferenzstruktur. Anstatt größere Gehirne aufzubauen, bringen wir Modellen bei, wie sie das Gedächtnis außerhalb ihres Gehirns nutzen können – genau wie Menschen.
Es ist eine ganzheitliche Sichtweise. Es ist nicht mehr das, was vorher battle, wie üblich. Eher eine Neuinterpretation der herkömmlichen Ansätze des Modellbetriebs.
Häufig gestellte Fragen
A. Sie überwinden Token-Fensterbeschränkungen und Kontextfäule und ermöglichen es LLMs, über extrem lange und informationsdichte Eingabeaufforderungen hinweg zuverlässig zu argumentieren.
A. Nein. RLMs sind eine Inferenzstrategie, die es LLMs ermöglicht, extern mit langen Eingabeaufforderungen zu interagieren und kleinere Teile rekursiv abzufragen.
A. Beim traditionellen Chunking werden frühere Teile vergessen. RLM behält die vollständige Eingabeaufforderung außerhalb des Modells und greift bei Bedarf auf jeden Abschnitt erneut zu.
Ich bin auf die Überprüfung und Verfeinerung von KI-gestützter Forschung, technischer Dokumentation und Inhalten im Zusammenhang mit neuen KI-Technologien spezialisiert. Meine Erfahrung umfasst KI-Modelltraining, Datenanalyse und Informationsabruf und ermöglicht es mir, Inhalte zu erstellen, die sowohl technisch korrekt als auch zugänglich sind.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.