
Seit dem Aufstieg von AI -Chatbots hat sich Googles Gemini als einer der mächtigsten Spieler entwickelt, die die Entwicklung intelligenter Systeme vorantreiben. Über seine Konversationskraft hinaus setzt Gemini auch praktische Möglichkeiten im Computervision auf und ermöglicht es Maschinen, die Welt um sie herum zu sehen, zu interpretieren und zu beschreiben.
Dieser Leitfaden führt Sie durch die Schritte, um Google Gemini für Laptop Imaginative and prescient zu nutzen, einschließlich der Einrichtung Ihrer Umgebung, zum Senden von Bildern mit Anweisungen und die Interpretation der Ausgaben des Modells für ObjekterkennungBildunterschrift Generierung und OCR. Wir werden auch Datenannotationsinstrumente (wie bei YOLO verwendet) berühren, um benutzerdefinierte Trainingsszenarien einen Kontext zu geben.
Was ist Google Gemini?
Google Gemini ist eine Familie von KI -Modellen, die für mehrere Datentypen erstellt wurden, z. B. Textual content, Bilder, Audio und Code zusammen. Dies bedeutet, dass sie Aufgaben verarbeiten können, die sowohl Bilder als auch Wörter verstehen.
Gemini 2.5 Professional Funktionen
- Multimodale Eingabe: Es akzeptiert Kombinationen von Textual content und Bildern in einer einzigen Anfrage.
- Argumentation: Das Modell kann Informationen aus den Eingaben analysieren, um Aufgaben wie die Identifizierung von Objekten oder die Beschreibung von Szenen auszuführen.
- Anweisung folgt: Es reagiert auf Textanweisungen (Eingabeaufforderungen), die seine Analyse des Bildes leiten.
Diese Funktionen ermöglichen es Entwicklern, Gemini für Visionsbezogene Aufgaben durch eine API zu verwenden, ohne ein separates Modell für jeden Job auszubilden.
Die Rolle des Datenanschlags: Der YOLO -Annotator
Während Gemini-Modelle für diese Laptop-Imaginative and prescient-Aufgaben leistungsstarke Null-Shot-Funktionen oder wenige Funktionen bieten, bauen Sie hochspezialisiert auf Laptop Imaginative and prescient -Modelle Erfordert Schulungen auf einem Datensatz, das auf das spezifische Drawback zugeschnitten ist. Hier wird die Datenannotation wichtig, insbesondere für überwachte Lernaufgaben wie das Coaching eines benutzerdefinierten Objektdetektors.
Der YOLO -Annotator (häufig bezieht sich auf Instruments, die mit dem YOLO -Format kompatibel sind, wie Beschriftung, CVAT oder Roboflow), wurde so konzipiert, dass sie beschriftete Datensätze erstellen.
Was ist Datenanmerkungen?
Für die Objekterkennung beinhaltet Annotation das Zeichnen von Begrenzungsboxen um jedes Interesse an einem Bild und das Zuweisen eines Klassenetiketts (z. B. „Auto“, „Individual“, „Hund“). Diese kommentierten Daten geben dem Modell mit, wonach und wo während des Trainings gesucht werden soll.
Schlüsselmerkmale von Annotationstools (wie Yolo Annotator)
- Benutzeroberfläche: Sie bieten grafische Schnittstellen, sodass Benutzer Bilder laden, Kästchen (oder Polygone, Tastoint usw.) zeichnen und die Beschriftungen effizient zuweisen.
- Formatkompatibilität: Instruments, die für YOLO -Modelle entwickelt wurden, speichern Annotationen in einem bestimmten Textdateiformat, das YOLO -Trainingsskripte erwarten (normalerweise eine .txt -Datei professional Bild, die Klassenindex und normalisierte Begrenzungsbox -Koordinaten enthält).
- Effizienzfunktionen: Viele Instruments umfassen Funktionen wie Hotkeys, automatisches Speichern und manchmal modellunterstützte Kennzeichnung, um den häufig zeitaufwändigen Annotationsprozess zu beschleunigen. Die Batch -Verarbeitung ermöglicht eine effektivere Handhabung großer Bildsätze.
- Integration: Die Verwendung von Standardformaten wie Yolo stellt sicher, dass die kommentierten Daten leicht mit beliebten Trainingsrahmen, einschließlich Ultralytics YOLO, verwendet werden können.
Während Google Gemini für Laptop Imaginative and prescient allgemeine Objekte ohne vorherige Annotation erkennen kann, müssen Sie wahrscheinlich ein dediziertes Yolo -Modell mit einem Device wie einem Yolo -Annotator trainieren, wenn Sie ein Modell benötigen, um sehr spezifische, benutzerdefinierte Objekte (z.
Code -Implementierung – Google Gemini für Laptop Imaginative and prescient
Zunächst müssen Sie die erforderlichen Softwarebibliotheken installieren.
Schritt 1: Installieren Sie die Voraussetzungen
1. Installieren Sie Bibliotheken
Führen Sie diesen Befehl in Ihrem Terminal aus:
!uv pip set up -U -q google-genai ultralyticsDieser Befehl installiert die Google-Genai Bibliothek zur Kommunikation mit dem Gemini API und die Ultralytics Bibliothek, die hilfreiche Funktionen für den Umgang mit Bildern und das Zeichnen auf sie enthält.
2. Importmodule
Fügen Sie diese Zeilen Ihrem Python -Notizbuch hinzu:
import json
import cv2
import ultralytics
from google import genai
from google.genai import varieties
from PIL import Picture
from ultralytics.utils.downloads import safe_download
from ultralytics.utils.plotting import Annotator, colours
ultralytics.checks()Dieser Code importiert Bibliotheken für Aufgaben wie das Lesen von Bildern (CV2Anwesend Pil), Handhabung von JSON -Daten (JSON), mit der API interagieren (Google.GenerativeAI) und Versorgungsfunktionen (Ultralytics).
3. Konfigurieren Sie den API -Schlüssel
Initialisieren Sie den Shopper mit Ihrem Google AI -API -Schlüssel.
# Substitute "your_api_key" together with your precise key
# Use GenerativeModel for newer variations of the library
# Initialize the Gemini consumer together with your API key
consumer = genai.Shopper(api_key=”your_api_key”)Dieser Schritt erstellt Ihr Skript zum Senden authentifizierter Anfragen.
Schritt 2: Funktion mit Gemini funktionieren
Erstellen Sie eine Funktion, um Anforderungen an das Modell zu senden. Diese Funktion nimmt ein Bild und eine Textaufforderung auf und gibt die Textausgabe des Modells zurück.
def inference(picture, immediate, temp=0.5):
"""
Performs inference utilizing Google Gemini 2.5 Professional Experimental mannequin.
Args:
picture (str or genai.varieties.Blob): The picture enter, both as a base64-encoded string or Blob object.
immediate (str): A textual content immediate to information the mannequin's response.
temp (float, optionally available): Sampling temperature for response randomness. Default is 0.5.
Returns:
str: The textual content response generated by the Gemini mannequin primarily based on the immediate and picture.
"""
response = consumer.fashions.generate_content(
mannequin="gemini-2.5-pro-exp-03-25",
contents=(immediate, picture), # Present each the textual content immediate and picture as enter
config=varieties.GenerateContentConfig(
temperature=temp, # Controls creativity vs. determinism in output
),
)
return response.textual content # Return the generated textual responseErläuterung
- Diese Funktion sendet das Bild und Ihre Textanweisung (Eingabeaufforderung) an das im model_client angegebene Gemini -Modell.
- Die Temperatureinstellung (TEMP) beeinflusst die Ausgabe zufällig; Niedrigere Werte liefern vorhersehbare Ergebnisse.
Schritt 3: Bilddaten vorbereiten
Sie müssen Bilder korrekt laden, bevor Sie sie an das Modell senden. Diese Funktion lädt bei Bedarf ein Bild herunter, liest es, konvertiert das Farbformat und gibt a zurück Pil -Bild Objekt und seine Dimensionen.
def read_image(filename):
image_name = safe_download(filename)
# Learn picture with opencv
picture = cv2.cvtColor(cv2.imread(f"/content material/{image_name}"), cv2.COLOR_BGR2RGB)
# Extract width and top
h, w = picture.form(:2)
# # Learn the picture utilizing OpenCV and convert it into the PIL format
return Picture.fromarray(picture), w, hErläuterung
- Diese Funktion verwendet OpenCV (CV2), um die Bilddatei zu lesen.
- Es wandelt die Bildfarbe in RGB um, was Customary ist.
- Es gibt das Bild als PIL -Objekt zurück, das für die Inferenzfunktion geeignet ist, und seine Breite und Höhe.
Schritt 4: Ergebnisformatierung
def clean_results(outcomes):
"""Clear the outcomes for visualization."""
return outcomes.strip().removeprefix("```json").removesuffix("```").strip()Diese Funktion formatiert das Ergebnis in das JSON -Format.
Aufgabe 1: Objekterkennung
Gemini kann Objekte in einem Bild finden und ihre Standorte (Begrenzungsboxen) basierend auf Ihren Textanweisungen melden.
# Outline the textual content immediate
immediate = """
Detect the 2nd bounding containers of objects in picture.
"""
# Fastened, plotting perform is determined by this.
output_prompt = "Return simply box_2d and labels, no extra textual content."
picture, w, h = read_image("https://media-cldnry.s-nbcnews.com/picture/add/t_fit-1000w,f_auto,q_auto:greatest/newscms/2019_02/2706861/190107-messy-desk-stock-cs-910a.jpg") # Learn img, extract width, top
outcomes = inference(picture, immediate + output_prompt) # Carry out inference
cln_results = json.hundreds(clean_results(outcomes)) # Clear outcomes, checklist convert
annotator = Annotator(picture) # initialize Ultralytics annotator
for idx, merchandise in enumerate(cln_results):
# By default, gemini mannequin return output with y coordinates first.
# Scale normalized field coordinates (0–1000) to picture dimensions
y1, x1, y2, x2 = merchandise("box_2d") # bbox publish processing,
y1 = y1 / 1000 * h
x1 = x1 / 1000 * w
y2 = y2 / 1000 * h
x2 = x2 / 1000 * w
if x1 > x2:
x1, x2 = x2, x1 # Swap x-coordinates if wanted
if y1 > y2:
y1, y2 = y2, y1 # Swap y-coordinates if wanted
annotator.box_label((x1, y1, x2, y2), label=merchandise("label"), shade=colours(idx, True))
Picture.fromarray(annotator.outcome()) # show the outputQuellbild: Hyperlink
Ausgabe
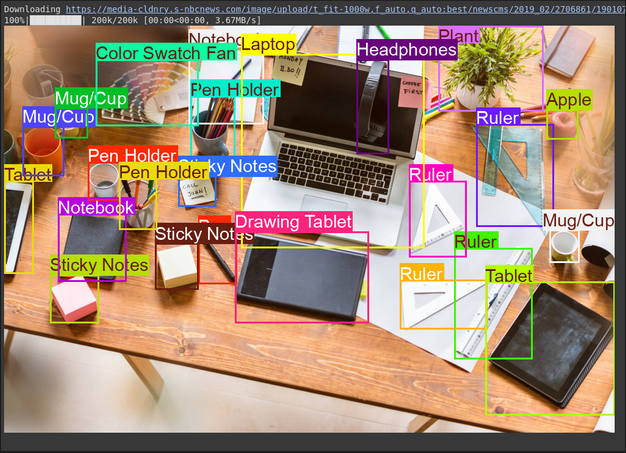
Erläuterung
- Die Eingabeaufforderung teilt dem Modell mit, was zu finden und wie die Ausgabe formatiert werden soll (JSON)
- Es konvertiert die normalisierten Boxkoordinaten (0-1000) in Pixelkoordinaten unter Verwendung der Bildbreite (W) und Höhe (H).
- Das Annotator -Device zeichnet die Kästchen und Beschriftungen auf einer Kopie des Bildes
Aufgabe 2: Testen von Argumentationsfunktionen
Mit Gemini -ModelleSie können komplexe Aufgaben anhand erweiterter Argumentation angehen, der den Kontext versteht und genauere Ergebnisse liefert.
# Outline the textual content immediate
immediate = """
Detect the 2nd bounding field round:
spotlight the world of morning mild +
PC on desk
potted plant
espresso cup on desk
"""
# Fastened, plotting perform is determined by this.
output_prompt = "Return simply box_2d and labels, no extra textual content."
picture, w, h = read_image("https://thumbs.dreamstime.com/b/modern-office-workspace-laptop-coffee-cup-cityscape-sunrise-sleek-desk-featuring-stationery-organized-neatly-city-345762953.jpg") # Learn picture and extract width, top
outcomes = inference(picture, immediate + output_prompt)
# Clear the outcomes and cargo leads to checklist format
cln_results = json.hundreds(clean_results(outcomes))
annotator = Annotator(picture) # initialize Ultralytics annotator
for idx, merchandise in enumerate(cln_results):
# By default, gemini mannequin return output with y coordinates first.
# Scale normalized field coordinates (0–1000) to picture dimensions
y1, x1, y2, x2 = merchandise("box_2d") # bbox publish processing,
y1 = y1 / 1000 * h
x1 = x1 / 1000 * w
y2 = y2 / 1000 * h
x2 = x2 / 1000 * w
if x1 > x2:
x1, x2 = x2, x1 # Swap x-coordinates if wanted
if y1 > y2:
y1, y2 = y2, y1 # Swap y-coordinates if wanted
annotator.box_label((x1, y1, x2, y2), label=merchandise("label"), shade=colours(idx, True))
Picture.fromarray(annotator.outcome()) # show the outputQuellbild: Hyperlink
Ausgabe

Erläuterung
- Dieser Codeblock enthält eine komplexe Eingabeaufforderung, um die Argumentationsfunktionen des Modells zu testen.
- Es konvertiert die normalisierten Boxkoordinaten (0-1000) in Pixelkoordinaten unter Verwendung der Bildbreite (W) und Höhe (H).
- Das Annotator -Device zeichnet die Kästchen und Beschriftungen auf einer Kopie des Bildes.
Aufgabe 3: Bildunterschrift
Gemini kann Textbeschreibungen für ein Bild erstellen.
# Outline the textual content immediate
immediate = """
What's contained in the picture, generate an in depth captioning within the type of brief
story, Make 4-5 strains and begin every sentence on a brand new line.
"""
picture, _, _ = read_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg") # Learn picture and extract width, top
plt.imshow(picture)
plt.axis('off') # Cover axes
plt.present()
print(inference(picture, immediate)) # Show the outcomesQuellbild: Hyperlink
Ausgabe

Erläuterung
- Diese Eingabeaufforderung bittet um einen bestimmten Beschreibungstil (Erzählungen, 4 Zeilen, neue Zeilen).
- Das bereitgestellte Bild ist in der Ausgabe angezeigt.
- Die Funktion gibt den generierten Textual content zurück. Dies ist nützlich, um ALT -Textual content oder Zusammenfassungen zu erstellen.
Aufgabe 4: Optische Charaktererkennung (OCR)
Gemini kann Textual content in einem Bild lesen und Ihnen mitteilen, wo er den Textual content gefunden hat.
# Outline the textual content immediate
immediate = """
Extract the textual content from the picture
"""
# Fastened, plotting perform is determined by this.
output_prompt = """
Return simply box_2d which will likely be location of detected textual content areas + label"""
picture, w, h = read_image("https://cdn.mos.cms.futurecdn.web/4sUeciYBZHaLoMa5KiYw7h-1200-80.jpg") # Learn picture and extract width, top
outcomes = inference(picture, immediate + output_prompt)
# Clear the outcomes and cargo leads to checklist format
cln_results = json.hundreds(clean_results(outcomes))
print()
annotator = Annotator(picture) # initialize Ultralytics annotator
for idx, merchandise in enumerate(cln_results):
# By default, gemini mannequin return output with y coordinates first.
# Scale normalized field coordinates (0–1000) to picture dimensions
y1, x1, y2, x2 = merchandise("box_2d") # bbox publish processing,
y1 = y1 / 1000 * h
x1 = x1 / 1000 * w
y2 = y2 / 1000 * h
x2 = x2 / 1000 * w
if x1 > x2:
x1, x2 = x2, x1 # Swap x-coordinates if wanted
if y1 > y2:
y1, y2 = y2, y1 # Swap y-coordinates if wanted
annotator.box_label((x1, y1, x2, y2), label=merchandise("label"), shade=colours(idx, True))
Picture.fromarray(annotator.outcome()) # show the outputQuellbild: Hyperlink
Ausgabe
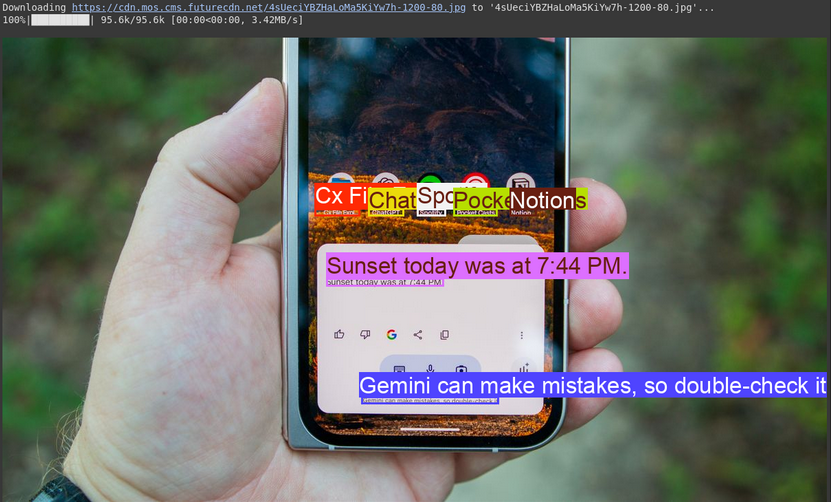
Erläuterung
- Dies verwendet eine Eingabeaufforderung, die der Objekterkennung ähnelt, jedoch nach Textual content (Etikett) anstelle von Objektnamen fragt.
- Der Code extrahiert den Textual content und seinen Standort und druckt den Textual content und die Zeichnungsfelder auf dem Bild.
- Dies ist nützlich, um Dokumente zu digitalisieren oder Textual content aus Schildern oder Etiketten in Fotos zu lesen.
Abschluss
Google Gemini für Laptop Imaginative and prescient erleichtert es einfach, Aufgaben wie Objekterkennung, Bildunterschrift und OCR durch einfache API -Aufrufe anzugehen. Durch das Senden von Bildern zusammen mit klaren Textanweisungen können Sie das Verständnis des Modells leiten und verwendbare Ergebnisse in Echtzeit erhalten.
Obwohl Gemini für allgemeine Aufgaben oder schnelle Experimente hervorragend geeignet ist, passt dies nicht immer zu hochspezialisierten Anwendungsfällen. Angenommen, Sie arbeiten mit Nischenobjekten oder benötigen eine engere Kontrolle über die Genauigkeit. In diesem Fall hält die traditionelle Route immer noch stark: Sammeln Sie Ihren Datensatz, kommentieren Sie sie mit Instruments wie YOLO -Etiketten und trainieren Sie ein benutzerdefiniertes Modell, das für Ihre Anforderungen abgestimmt ist.
Harsh Mishra ist ein KI/ML -Ingenieur, der mehr Zeit damit verbringt, mit großen Sprachmodellen zu sprechen als mit tatsächlichen Menschen. Leidenschaft über Genai, NLP und Maschinen schlauer (damit sie ihn noch nicht ersetzen). Wenn er Fashions nicht optimiert, optimiert er wahrscheinlich seine Kaffeeaufnahme. 🚀☕
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.