
Wenn Sie mit gearbeitet haben DeepSeek OCRwissen Sie bereits, dass es beim Extrahieren von Textual content und beim Komprimieren von Dokumenten effizient warfare. Wo es oft zu kurz kam, warfare die Lesereihenfolge und das Format von Seiten, mehrspaltigen PDFs, dichten Tabellen und gemischten Inhalten, die noch bereinigt werden mussten. DeepSeek OCR 2 ist die Antwort von DeepSeek auf diese Lücke. Anstatt sich nur auf die Komprimierung zu konzentrieren, lenkt dieses Replace die Aufmerksamkeit darauf, wie Dokumente tatsächlich gelesen werden. Erste Ergebnisse zeigen eine sauberere Struktur, eine bessere Reihenfolge und weitaus weniger Layoutfehler, insbesondere bei realen Geschäfts- und technischen Dokumenten. Lassen Sie uns alle neuen Funktionen von DeepSekk OCR 2 erkunden!
Hauptfunktionen und Verbesserungen von DeepSeek OCR 2
- DeepEncoder V2-Architektur für logische Lesereihenfolge anstelle starrer Abtastung von oben nach unten
- Verbessertes Layoutverständnis auf komplexen Seiten mit mehrspaltigem Textual content und dichten Tabellen
- Leichtes Modell mit 3 Milliarden Parametern, das größere Modelle bei strukturierten Dokumenten übertrifft
- Verbesserter Imaginative and prescient-Encoder, der die ältere Architektur durch ein sprachmodellgesteuertes Design ersetzt
- Höhere Benchmark-Leistung mit 91,09 Punkten bei OmniDocBench v1.5, eine Verbesserung um 3,73 Prozentpunkte gegenüber der Vorgängerversion
- Unterstützung umfassender Formate, einschließlich Bildern, PDFs, Tabellen und mathematischen Inhalten
- Open Supply und fein abstimmbar, was die Anpassung an domänenspezifische Anwendungsfälle in allen Branchen ermöglicht
Die DeepEncoder V2-Architektur
Herkömmliche OCR-Systeme verarbeiten Bilder mithilfe eines auf festen Rastern basierenden Scannens, was häufig die Lesereihenfolge und das Layoutverständnis einschränkt. DeepSeek OCR 2 verfolgt einen anderen Ansatz, der auf dem visuellen Kausalfluss basiert. Der Encoder erfasst zunächst eine globale Ansicht der Seite und verarbeitet dann Inhalte in einer strukturierten Reihenfolge mithilfe lernbarer Abfragen. Dies ermöglicht eine versatile Handhabung komplexer Layouts und verbessert die Konsistenz der Lesereihenfolge.
Zu den wichtigsten architektonischen Elementen gehören:
- Twin-Consideration-Design, das die Format-Wahrnehmung von der Lesereihenfolge trennt
- Visuelle Token, die den ganzseitigen Kontext und die räumliche Struktur kodieren
- Kausale Abfragetokens, die die sequentielle Inhaltsinterpretation steuern
- Sprachmodellgesteuerter Imaginative and prescient-Encoder, der Ordnungsbewusstsein und Raumbezug bietet
- Argumentationsorientierte Encoderfunktion, die über die grundlegende Merkmalsextraktion hinausgeht
- Decoderstufe, die codierte Darstellungen in die endgültige Textausgabe umwandelt
Der architektonische Ablauf unterscheidet sich von der früheren Model, die auf einem festen, nicht-kausalen Imaginative and prescient-Encoder basierte. DeepEncoder V2 ersetzt dies durch einen auf Sprachmodellen basierenden Encoder und lernbare kausale Abfragen, wodurch eine globale Wahrnehmung gefolgt von einer strukturierten, sequentiellen Interpretation ermöglicht wird.
Leistungsbenchmarks
DeepSeek OCR 2 zeigt eine starke Benchmark-Leistung. Auf OmniDocBench v1.5 erreicht es eine Punktzahl von 91,09 und setzt damit einen neuen Stand der Technik beim Verständnis strukturierter Dokumente. Die deutlichsten Verbesserungen ergeben sich bei der Genauigkeit der Lesereihenfolge, was die Wirksamkeit der aktualisierten Architektur widerspiegelt.
Im Vergleich zu anderen Imaginative and prescient-Language-Modellen bewahrt DeepSeek OCR 2 die Dokumentstruktur zuverlässiger als generische Lösungen wie GPT-4 Imaginative and prescient. Seine Genauigkeit ist mit spezialisierten kommerziellen OCR-Systemen vergleichbar und positioniert es als starke Open-Supply-Various. Berichtete Ergebnisse der Feinabstimmung deuten auf eine Reduzierung der Zeichenfehlerrate um bis zu 86 % für bestimmte Aufgaben hin. Erste Bewertungen zeigen auch eine verbesserte Handhabung von gedrehtem Textual content und komplexen Tabellen, was seine Eignung für anspruchsvolle OCR-Arbeitslasten untermauert.
Lesen Sie auch: DeepSeek OCR vs. Qwen-3 VL vs. Mistral OCR: Welches ist das Beste?
Wie kann ich auf DeepSeek OCR 2 zugreifen und es verwenden?
Sie können DeepSeek OCR 2 mit ein paar Codezeilen verwenden. Das Modell ist auf der erhältlich Umarmender Gesichtshub. Sie benötigen eine Python-Umgebung und eine GPU mit etwa 16 GB VRAM.
Bei HuggingFace Areas ist jedoch eine Demo für DeepSeek OCR 2 verfügbar – Finden Sie es hier.
Testen wir OCR 2.
Aufgabe 1: Dokumente mit dichtem Textual content und vielen Tabellen

Ergebnis:
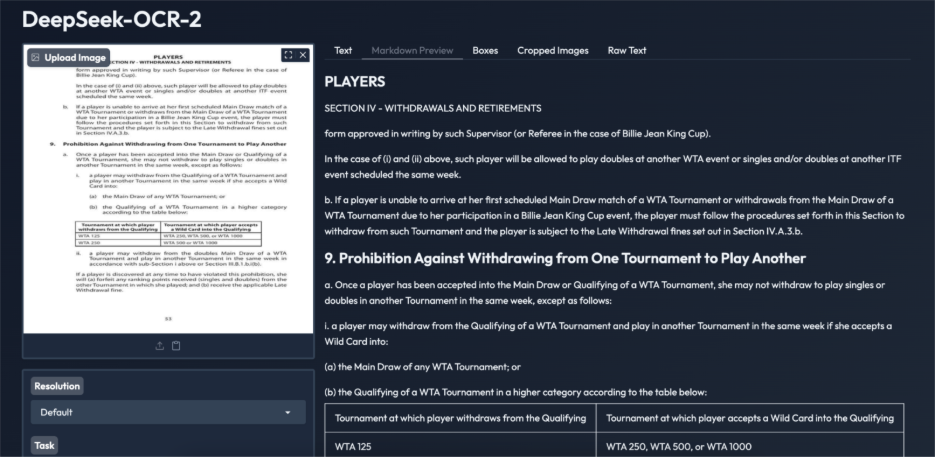
DeepSeek OCR 2 eignet sich intestine für gescannte Dokumente mit vielen Texten. Der extrahierte Textual content ist präzise, lesbar und folgt der korrekten Lesereihenfolge, selbst bei dichten Absätzen und nummerierten Abschnitten. Tabellen werden in strukturiertes HTML mit konsistenter Reihenfolge konvertiert, ein häufiger Fehlerpunkt bei herkömmlichen OCR-Systemen. Obwohl geringfügige Formatierungsredundanzen vorhanden sind, bleiben Inhalt und Format insgesamt erhalten. Dieses Beispiel demonstriert die Zuverlässigkeit des Modells bei komplexen Richtlinien- und Rechtsdokumenten und unterstützt das Verständnis auf Dokumentebene über die einfache Textextraktion hinaus.
Aufgabe 2: Verrauschte Bilder mit niedriger Auflösung

Ergebnis:
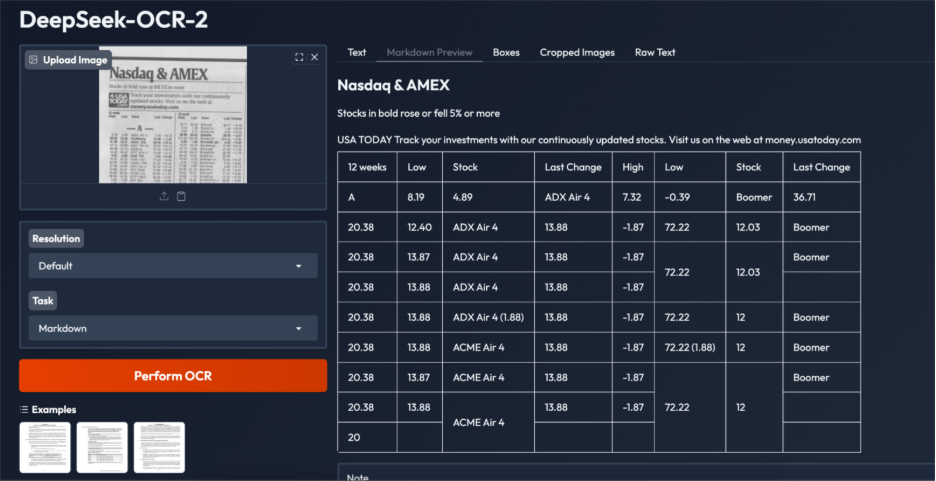
Dieses Beispiel verdeutlicht sowohl die Stärken als auch die Grenzen von DeepSeek OCR 2 bei extrem verrauschten Finanztabellendaten mit niedriger Auflösung. Das Modell identifiziert wichtige Überschriften und Quelltext korrekt und erkennt den Inhalt als tabellarisch, wodurch eine tabellenbasierte Ausgabe anstelle von reinem Textual content erstellt wird. Allerdings bleiben strukturelle Probleme bestehen, darunter doppelte Zeilen, unregelmäßige Zellenausrichtung und gelegentlich falsche Zellenzusammenführung, wahrscheinlich aufgrund dichter Layouts, kleiner Schriftgrößen und schlechter Bildqualität.
Während die meisten numerischen Werte und Beschriftungen genau erfasst werden, ist für den Produktionseinsatz eine Nachbearbeitung erforderlich. Insgesamt deuten die Ergebnisse auf eine starke Erkennung von Layoutabsichten hin, wobei stark überfüllte Finanztabellen weiterhin ein herausfordernder Grenzfall bleiben.
Wann sollte DeepSeek OCR 2 verwendet werden?
- Bearbeitung komplexer Dokumente wie wissenschaftliche Arbeiten, technische Dokumentationen und Zeitungen
- Konvertieren gescannter und digitaler Dokumente in strukturierte Formate, einschließlich Markdown
- Extrahieren strukturierter Informationen aus Geschäftsdokumenten wie Rechnungen, Verträgen und Finanzberichten
- Umgang mit layoutintensiven Inhalten, bei denen die Erhaltung der Struktur von entscheidender Bedeutung ist
- Domänenspezifische Dokumentenverarbeitung durch Feinabstimmung für medizinische, juristische oder spezielle Terminologie
- Datenschutzrelevante Arbeitsabläufe werden durch die lokale Bereitstellung vor Ort ermöglicht
- Sichere Dokumentenverarbeitung für Behörden und Unternehmen ohne Cloud-Datenübertragung
- Branchenübergreifende Integration in moderne KI- und Dokumentenverarbeitungspipelines
Lesen Sie auch: Die 8 besten OCR-Bibliotheken in Python zum Extrahieren von Textual content aus Bildern
Abschluss
DeepSeek OCR 2 stellt einen klaren Fortschritt in der Dokumenten-KI dar. Die DeepEncoder V2-Architektur verbessert die Format-Verarbeitung und Lesereihenfolge und behebt damit Einschränkungen früherer OCR-Systeme. Das Modell erreicht eine hohe Genauigkeit und bleibt dabei leicht und kosteneffizient. Als vollständig Open-Supply-System ermöglicht es Entwicklern, Workflows zum Dokumentverständnis zu erstellen, ohne auf proprietäre APIs angewiesen zu sein. Diese Model spiegelt einen umfassenderen Wandel in der OCR von der Extraktion auf Zeichenebene hin zur Interpretation auf Dokumentebene wider und kombiniert Imaginative and prescient und Sprache für eine strukturiertere und zuverlässigere Verarbeitung komplexer Dokumente.
Häufig gestellte Fragen
A. Es handelt sich um ein Imaginative and prescient-Language-Modell, das Open Supply ist. Es handelt sich um ein Unternehmen für optische Zeichenerkennung und Dokumentenverständnis.
A. Es arbeitet mit einer speziellen Architektur, durch die es die Dokumente in menschenähnlicher und logischer Reihenfolge liest. Dies erhöht die Präzision bei der Überlagerung komplexer Pläne.
A. Ja, es ist ein Open-Supply-Modell. Sie können es kostenlos herunterladen und auf Ihrer eigenen {Hardware} ausführen.
A. Sie benötigen einen Laptop mit einer modernen GPU. Für eine gute Leistung werden mindestens 16 GB VRAM empfohlen.
A. Es dient in erster Linie zur Aufnahme gedruckter oder elektronischer Texte. Andere Spezialmodelle sind möglicherweise beim Schreiben komplexer Handschriften effektiver.
Harsh Mishra ist ein KI/ML-Ingenieur, der mehr Zeit damit verbringt, mit großen Sprachmodellen zu sprechen als mit echten Menschen. Leidenschaftlich für GenAI, NLP und die intelligentere Entwicklung von Maschinen (damit sie ihn noch nicht ersetzen). Wenn er nicht gerade Modelle optimiert, optimiert er wahrscheinlich seinen Kaffeekonsum. 🚀☕
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.