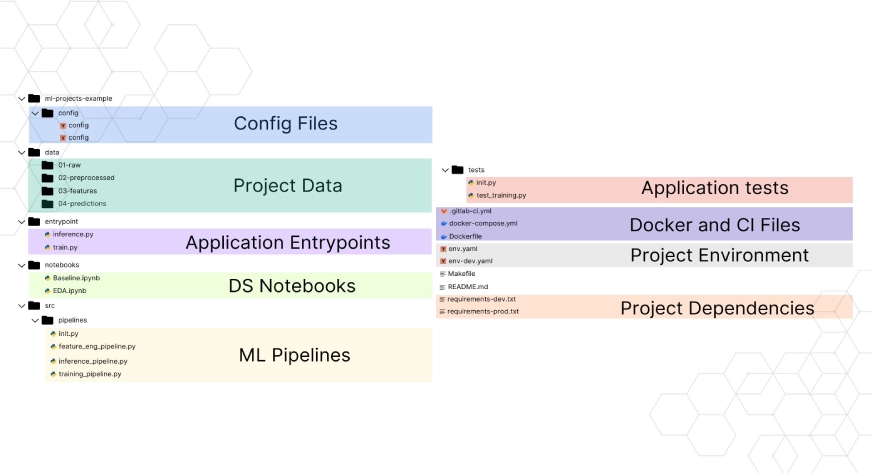
Haben Sie sich jemals in unordentlichen Ordnern, so vielen Skripten und unorganisiertem Code verloren gefühlt? Dieses Chaos verlangsamt Sie nur und erschwert die Reise in die Datenwissenschaft. Organisierte Arbeitsabläufe und Projektstrukturen sind nicht nur „nice-to-have“, denn sie wirken sich auf die Reproduzierbarkeit, Zusammenarbeit und das Verständnis des Projektgeschehens aus. In diesem Weblog erkunden wir die Greatest Practices und schauen uns ein Beispielprojekt als Leitfaden für Ihre bevorstehenden Projekte an. Schauen wir uns ohne weitere Umschweife einige der wichtigen Frameworks und gängigen Praktiken sowie deren Verbesserung an.
Beliebte Information Science-Workflow-Frameworks für die Projektstruktur
Information-Science-Frameworks Bieten Sie eine strukturierte Möglichkeit, eine klare Information-Science-Projektstruktur zu definieren und aufrechtzuerhalten, indem Sie Groups von der Problemdefinition bis zur Bereitstellung leiten und gleichzeitig die Reproduzierbarkeit und Zusammenarbeit verbessern.
CRISP-DM
CRISP-DM ist die Abkürzung für Cross-Business Course of for Information Mining. Es folgt einer zyklischen iterativen Struktur, die Folgendes umfasst:
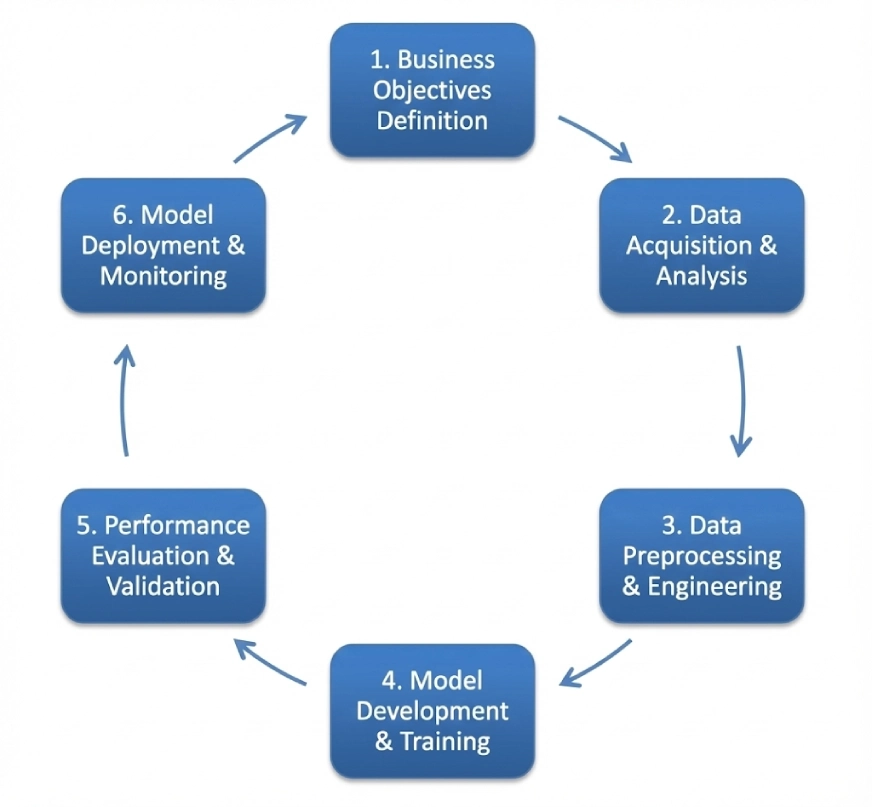
- Geschäftsverständnis
- Datenverständnis
- Datenvorbereitung
- Modellieren
- Auswertung
- Einsatz
Dieses Framework kann als Customary über mehrere Domänen hinweg verwendet werden, die Reihenfolge der Schritte kann jedoch flexibel sein und Sie können sowohl zurück als auch im Gegensatz zum unidirektionalen Fluss wechseln. Wir werden uns später in diesem Weblog ein Projekt ansehen, das dieses Framework verwendet.
BetriebssystemEMN
Ein weiteres beliebtes Framework in der Welt der Datenwissenschaft. Die Idee hier ist, die komplexen Probleme in 5 Schritte zu unterteilen und sie Schritt für Schritt zu lösen. Die 5 Schritte von OSEMN (ausgesprochen „Superior“) sind:
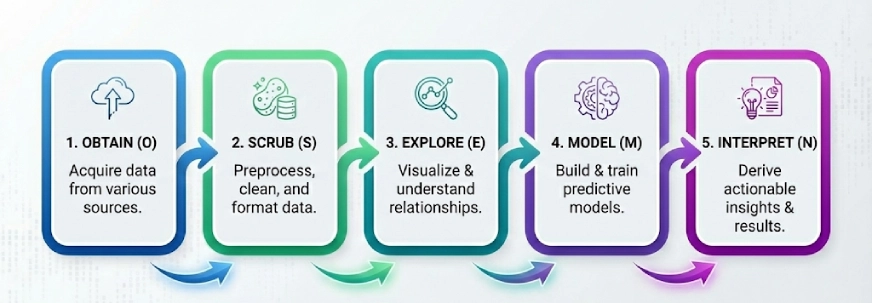
- Erhalten
- Schrubben
- Erkunden
- Modell
- Interpretieren
Hinweis: Das „N“ in „OSEMN“ ist das N in iNterpret.
Wir folgen diesen 5 logischen Schritten, um die Daten zu „beschaffen“, sie zu „säubern“ oder vorzuverarbeiten, dann die Daten zu „erkunden“, indem wir Visualisierungen verwenden und die Beziehungen zwischen den Daten verstehen, und dann „modellieren“ wir die Daten, um die Eingaben zur Vorhersage der Ausgaben zu verwenden. Abschließend „interpretieren“ wir die Ergebnisse und finden umsetzbare Erkenntnisse.
KDD
KDD oder Information Discovery in Databases besteht aus mehreren Prozessen, die darauf abzielen, Rohdaten in Wissenserkennung umzuwandeln. Hier sind die Schritte in diesem Rahmen:

- Auswahl
- Vorverarbeitung
- Transformation
- Information Mining
- Interpretation/Bewertung
Es ist erwähnenswert, dass die Leute KDD als Information Mining bezeichnen, aber Information Mining ist der spezifische Schritt, bei dem Algorithmen verwendet werden, um Muster zu finden. KDD hingegen deckt den gesamten Lebenszyklus von Anfang bis Ende ab.
SEMMA
Dieser Rahmen legt mehr Wert auf die Modellentwicklung. Das SEMMA ergibt sich aus den logischen Schritten im Rahmenwerk:
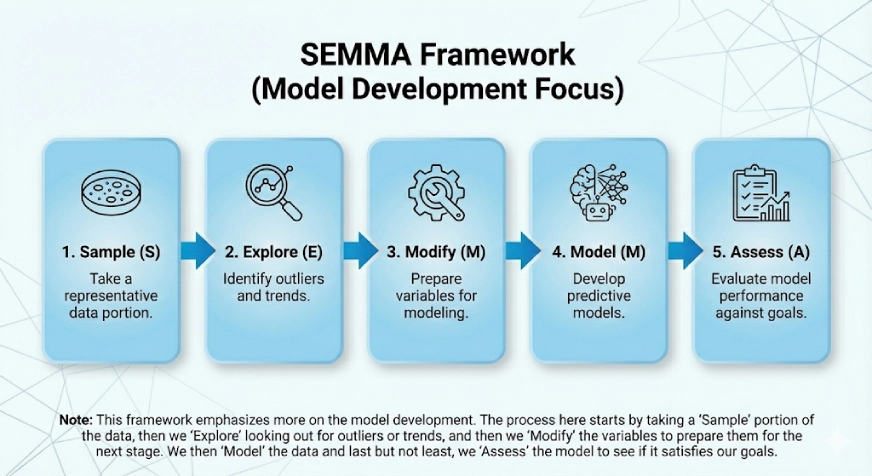
- Probe
- Erkunden
- Ändern
- Modell
- Bewerten
Der Prozess hier beginnt damit, dass wir einen „Stichproben“-Teil der Daten nehmen, dann „erkunden“ und nach Ausreißern oder Developments Ausschau halten, und dann „modifizieren“ wir die Variablen, um sie für die nächste Stufe vorzubereiten. Anschließend „modellieren“ wir die Daten und zu guter Letzt „bewerten“ wir das Modell, um zu sehen, ob es unsere Ziele erfüllt.
Gängige Praktiken, die verbessert werden müssen
Die Verbesserung dieser Praktiken ist entscheidend für die Aufrechterhaltung eines sauberen und skalierbaren Techniques Datenwissenschaft Projektstruktur, insbesondere wenn Projekte an Größe und Komplexität zunehmen.
1. Das Drawback mit „Pfaden“
Absolute Pfade wie pd.read_csv („C:/Benutzer/Title/Downloads/information.csv“) werden häufig fest codiert. Dies ist beim Testen auf Jupyter Pocket book in Ordnung, aber wenn es im eigentlichen Projekt verwendet wird, wird der Code für alle anderen beschädigt.
Die Lösung: Verwenden Sie immer relative Pfade mit Hilfe von Bibliotheken wie „os“ oder „pathlib“. Alternativ können Sie die Pfade auch in einer Konfigurationsdatei hinzufügen (zum Beispiel: DATA_DIR=/dwelling/ubuntu/path).
2. Das vollgestopfte Jupyter-Notizbuch
Manchmal verwenden Benutzer ein einzelnes Jupyter-Notizbuch mit mehr als 100 Zellen, das Importe, EDA, Bereinigung, Modellierung und Visualisierung enthält. Dies würde einen Check oder eine Versionskontrolle unmöglich machen.
Die Lösung: Verwenden Sie Jupyter Notebooks nur zur Erkundung und bleiben Sie zur Automatisierung bei Python-Skripten. Sobald eine Reinigungsfunktion funktioniert, fügen Sie sie einer src/processing.py-Datei hinzu und können sie dann in das Pocket book importieren. Dies sorgt für mehr Modularität und Wiederverwendbarkeit und vereinfacht außerdem das Testen und Verstehen des Notebooks erheblich.
3. Versionieren Sie den Code, nicht die Daten
Git kann beim Umgang mit großen CSV-Dateien Schwierigkeiten haben. Die Leute da draußen pushen oft Daten an GitHub, was viel Zeit in Anspruch nehmen und auch andere Komplikationen verursachen kann.
Die Lösung: Erwähnen und verwenden Sie die Datenversionskontrolle (kurz DVC). Es ist wie Git, nur für Daten.
4. Keine README-Datei für das Projekt bereitstellen
Ein Repository kann großartigen Code enthalten, aber ohne Anweisungen zum Installieren von Abhängigkeiten oder zum Ausführen der Skripte kann es chaotisch sein.
Die Lösung: Stellen Sie sicher, dass Sie immer eine gute README.md erstellen, die Informationen darüber enthält, wie Sie die Umgebung einrichten, wo und wie Sie die Daten erhalten, wie Sie das Modell ausführen und andere wichtige Skripte.
Aufbau eines Kundenabwanderungsvorhersagesystems (Beispielprojekt)
Jetzt habe ich mit dem CRISP-DM-Framework ein Beispielprojekt mit dem Namen „System zur Vorhersage der Kundenabwanderung“, lassen Sie uns den gesamten Prozess und die Schritte verstehen, indem wir sie genauer betrachten.
Hier ist der GitHub-Hyperlink des Vertretersository.
Notiz: Dies ist ein Beispielprojekt, das dazu dient, zu verstehen, wie das Framework implementiert und ein Standardverfahren befolgt wird.
CRISP-DM Schritt für Schritt anwenden
- Geschäftsverständnis: Hier müssen wir definieren, was wir eigentlich lösen wollen. In unserem Fall geht es darum, Kunden zu erkennen, die wahrscheinlich abwandern. Wir setzen klare Ziele für das System, eine Genauigkeit von über 85 % und einen Rückruf von über 80 %, und das Geschäftsziel besteht darin, die Kunden zu binden.
- Datenverständnis In unserem Fall der Datensatz zur Kundenabwanderung von Telekommunikationsunternehmen. Wir müssen uns die deskriptiven Statistiken ansehen, die Datenqualität überprüfen, nach fehlenden Werten suchen (und darüber nachdenken, wie wir damit umgehen können), außerdem müssen wir sehen, wie die Zielvariable verteilt ist, und schließlich müssen wir die Korrelationen zwischen den Variablen untersuchen, um zu sehen, welche Merkmale wichtig sind.
- Datenvorbereitung: Dieser Schritt kann einige Zeit dauern, muss aber sorgfältig durchgeführt werden. Hier bereinigen wir die chaotischen Daten, kümmern uns um die fehlenden Werte und Ausreißer, erstellen bei Bedarf neue Options, kodieren die kategorialen Variablen, teilen den Datensatz in Coaching (70 %), Validierung (15 %) und Check (15 %) auf und normalisieren schließlich die Options für unsere Modelle.
- Modellieren: In diesem entscheidenden Schritt beginnen wir mit einem einfachen Modell oder einer Basislinie (in unserem Fall die logistische Regression) und experimentieren dann mit anderen Modellen wie Random Forest und XGBoost, um unsere Geschäftsziele zu erreichen. Anschließend optimieren wir die Hyperparameter.
- Auswertung: Hier finden wir heraus, welches Modell für uns am besten funktioniert und unsere Geschäftsziele erreicht. In unserem Fall müssen wir uns die Präzision, den Rückruf, die F1-Scores, die ROC-AUC-Kurven und die Verwirrungsmatrix ansehen. Dieser Schritt hilft uns, das endgültige Modell für unser Ziel auszuwählen.
- Einsatz: Hier beginnen wir tatsächlich mit der Verwendung des Modells. Hier können wir FastAPI oder andere Alternativen verwenden, es zur Skalierbarkeit mit Docker containerisieren und eine Überwachung für Verfolgungszwecke einrichten.
Die Verwendung eines Schritt-für-Schritt-Prozesses trägt eindeutig dazu bei, einen klaren Weg zum Projekt zu schaffen. Auch während der Projektentwicklung können Sie Fortschrittstracker nutzen, und die Versionskontrollen von GitHub können sicherlich hilfreich sein. Die Datenvorbereitung erfordert eine sorgfältige Pflege, da bei richtiger Durchführung nicht viele Überarbeitungen erforderlich sind. Wenn nach der Bereitstellung ein Drawback auftritt, kann dieses durch Zurückkehren zur Modellierungsphase behoben werden.
Abschluss
Wie bereits zu Beginn des Blogs erwähnt, sind organisierte Arbeitsabläufe und Projektstrukturen nicht nur „nice-to-have“, sondern ein Muss. Mit CRISP-DM, OSEMN, KDD oder SEMMA sorgt ein schrittweiser Prozess dafür, dass Projekte klar und reproduzierbar bleiben. Vergessen Sie auch nicht, relative Pfade zu verwenden, Jupyter-Notizbücher zur Erkundung aufzubewahren und immer eine gute README.md zu erstellen. Denken Sie immer daran, dass die Entwicklung ein iterativer Prozess ist und ein klar strukturierter Rahmen für Ihre Projekte Ihre Reise erleichtern wird.
Häufig gestellte Fragen
A. Reproduzierbarkeit in der Datenwissenschaft bedeutet, dass man mit demselben Datensatz, demselben Code und denselben Konfigurationseinstellungen dieselben Ergebnisse erzielen kann. Ein reproduzierbares Projekt stellt sicher, dass Experimente im Laufe der Zeit überprüft, debuggt und verbessert werden können. Es erleichtert auch die Zusammenarbeit, da andere Teammitglieder das Projekt ohne Inkonsistenzen aufgrund von Umgebungs- oder Datenunterschieden ausführen können.
A. Modelldrift tritt auf, wenn die Leistung eines maschinellen Lernmodells nachlässt, weil sich reale Daten im Laufe der Zeit ändern. Dies kann aufgrund von Änderungen im Nutzerverhalten, den Marktbedingungen oder der Datenverteilung passieren. Die Überwachung auf Modelldrift ist in Produktionssystemen unerlässlich, um sicherzustellen, dass Modelle genau und zuverlässig bleiben und auf die Geschäftsziele ausgerichtet sind.
A. Eine virtuelle Umgebung isoliert Projektabhängigkeiten und verhindert Konflikte zwischen verschiedenen Bibliotheksversionen. Da Information-Science-Projekte häufig auf bestimmten Versionen von Python-Paketen basieren, sorgt die Verwendung virtueller Umgebungen für konsistente Ergebnisse auf allen Maschinen und im Laufe der Zeit. Dies ist entscheidend für die Reproduzierbarkeit, Bereitstellung und Zusammenarbeit in realen Information-Science-Workflows.
A. Eine Datenpipeline besteht aus einer Reihe automatisierter Schritte, die Daten aus Rohquellen in ein modellfähiges Format verschieben. Es umfasst typischerweise die Datenaufnahme, -bereinigung, -transformation und -speicherung.
Leidenschaftlich für Technologie und Innovation, Absolvent des Vellore Institute of Know-how. Derzeit arbeite ich als Information Science Trainee mit Schwerpunkt auf Information Science. Großes Interesse an Deep Studying und generativer KI, begierig darauf, modernste Techniken zu erforschen, um komplexe Probleme zu lösen und wirkungsvolle Lösungen zu schaffen.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.