
Ubers Fähigkeit, schnelle, zuverlässige Fahrten anzubieten, hängt von der Fähigkeit ab, die Nachfrage vorherzusagen. Dies bedeutet, vorherzusagen, wann und wo Menschen Fahrten wollen, oft zu einem Stadtblock und der Zeit, zu der sie sie erwarten könnten. Dieses Balancegesetz beruht auf komplexen Systemen für maschinelles Lernen (ML), die große Datenmengen in Echtzeit einnehmen und den Markt anpassen, um das Gleichgewicht aufrechtzuerhalten. Lassen Sie uns verstehen, wie Uber ML für die Nachfragevorhersage anwendet und warum es für ihr Geschäft von entscheidender Bedeutung ist.
Warum ist die Nachfragevorhersage wichtig?

Hier sind einige der Gründe, warum die Nachfrageprognose so wichtig ist:
- Market -Gleichgewicht: Die Bedarfsvorhersage hilft Uber dabei, das Gleichgewicht zwischen Fahrern und Fahrern zu etablieren, um die Wartezeiten zu minimieren und die Fahrereinnahmen zu maximieren.
- Dynamisch preisgünstiger Marktplatz: Wenn Sie die Nachfrage genau prognostizieren können, können Sie Uber wissen, wie viele Fahrer sie für eine Überspannungspreise benötigen und gleichzeitig sicherstellen, dass bei einer Erhöhung der Nachfrage genügend verfügbar ist.
- Ressourcen maximieren: Die Nachfragevorhersage wird verwendet, um alles von On-line -Marketingausgaben über Anreize der Treiber bis zur Bereitstellung von {Hardware} zu informieren.
Datenquellen und externe Signale
Uber nutzt Modelle für Nachfrage-für-Forged-Modelle, die auf reichlichen Mengen an historischen Daten und Echtzeitsignalen basieren. Die Geschichte besteht aus Auslöseprotokollen (wann, wo, wie viele usw.), Versorgungsmaßnahmen (wie viele Treiber sind verfügbar?) Und Funktionen, die aus den Fahrer- und Treiber -Apps abgeleitet sind. Das Unternehmen betrachtet Occasions als wichtige Ereignisse als Echtzeitsignale. Externe Faktoren sind entscheidend, einschließlich Kalender von Feiertagen/Großveranstaltungen, Wettervorhersagen, weltweit und lokalen Nachrichten, Störungen des öffentlichen Transits, lokalen Sportspiele und eingehenden Flugankömmlingen, die die Nachfrage beeinflussen können.
Als Uber -Staaten„Ereignisse wie Silvester treten nur ein paar Mal im Jahrzehnt auf. Die Prognose dieser Anforderungen beruht daher auf exogenen Variablen, Wetter, Bevölkerungswachstum oder Veränderungen für Advertising and marketing/Anreize, die die Nachfrage erheblich beeinflussen können”.
Schlüsseldatenfunktionen
Die wichtigsten Merkmale der Daten sind:
- Zeitliche Merkmale: Tageszeit, Wochentag, Saison (z. B. Wochentage gegen Wochenenden, Feiertage. Uber beobachtet tägliche/wöchentliche Muster (z. B. Wochenendabende sind geschäftiger) und Feiertagsspitzen.
- Ortsspezifisch: Die historische Fahrt zählt in bestimmten Stadtteilen oder Gitterzellen, historischer Treiber zählt in bestimmten Bereichen. Uber prognostiziert hauptsächlich die Nachfrage der geografischen Area (entweder mit Zonen oder mit hexagonalen Gittern), um die Nachfragestürme vor Ort zu bewerten.
- Externe Signale: Wetter, Flugpläne, Veranstaltungen (Konzerte/Sport), Nachrichten oder Streiks auf städtischer Ebene. Um beispielsweise die Nachfrage nach Flughafen prognostiziert, nutzt Uber Flugankömmlinge und das Wetter als Prognosevariablen.
- App -Engagement: Die Echtzeit-Systeme von Uber überwachen die App-Engagement (dh wie viele Benutzer ihre App geöffnet haben) als Hauptindikator für die Nachfrage.
- Eindeutige Datenpunkte: Energetic App -Benutzer, neue Anmeldungen, die Proxys für die gesamte Plattformnutzung sind.
Zusammengenommen können Ubers Modelle komplexe Muster lernen. In einem Weblog von Uber Engineering über excessive Veranstaltungen wird beschrieben, dass die Einnahme eines neuronalen Netzwerks und das Coaching mit Funktionen auf Stadtebene (dh, welche Ausflüge derzeit durchgeführt werden, wie viele Benutzer registriert sind), zusammen mit exogenen Signalen (dh, was das Wetter ist, was sind die Feiertage), damit er große Spikes vorhersagen kann.
Dies erzeugt einen reichhaltigen Characteristic -Raum, der in der Lage ist, regelmäßige Saisonalität zu erfassen und gleichzeitig unregelmäßige Schocks zu berücksichtigen.
Techniken für maschinelles Lernen in der Praxis
Uber verwendet eine Kombination klassischer Statistiken, maschinelles Lernenund tiefes Lernen, die Nachfrage vorherzusagen. Führen Sie nun die Zeitreihenanalyse und die Regression in einem Uber -Datensatz durch. Sie können den Datensatz verwenden Hier.
Schritt 1: Zeitreihenanalyse
Uber nutzt Zeitreihenmodelle, um ein Verständnis von Developments und Saisonalität in Fahranfragen zu entwickeln und historische Daten zu analysieren, um die Nachfrage auf bestimmte Zeiträume zuzuordnen. Dies ermöglicht das Unternehmen, sich auf den Anstieg vorzubereiten, das es erwarten kann, z. B. eine Wochentags -Hauptverkehrszeit oder eine besondere Veranstaltung.
import matplotlib.pyplot as plt
# Depend rides per day
daily_rides = df.groupby('date')('trip_status').rely()
plt.determine(figsize=(16,6))
daily_rides.plot()
plt.title('Each day Uber Rides')
plt.ylabel('Variety of rides')
plt.xlabel('Date')
plt.grid(True)
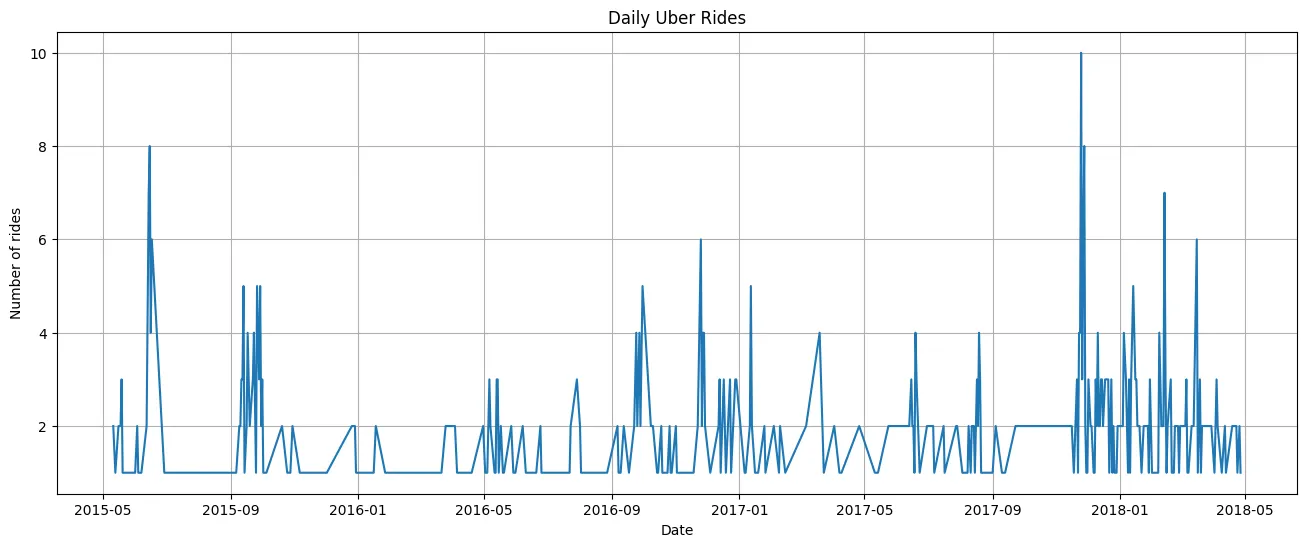
plt.present()Diese Code gruppiert Uber -Journey -Daten nach Datum, zählt die Anzahl der Reisen jeden Tag und zählt dann diese täglichen Zeilen als Zeilendiagramm, um die Developments der Fahrvolumen im Laufe der Zeit anzuzeigen.
Ausgabe:
Schritt 2: Regressionsalgorithmen
Die Regressionsanalyse ist eine weitere nützliche Analysetechnik, mit der Uber beurteilt werden kann, wie die Nachfrage und die Preisgestaltung von Fahren durch verschiedene Eingabefaktoren beeinflusst werden können, einschließlich Wetter, Verkehr und lokale Ereignisse. Mit diesen Modellen kann Uber bestimmen.
plt.determine(figsize=(10, 6))
plt.plot(y_test.values, label="Precise Value")
plt.plot(y_pred, label="Predicted Value")
plt.title('Precise vs. Predicted Uber Fare (USD)')
plt.xlabel('Take a look at Pattern Index')
plt.ylabel('Value (USD)')
plt.legend()
plt.grid(True)
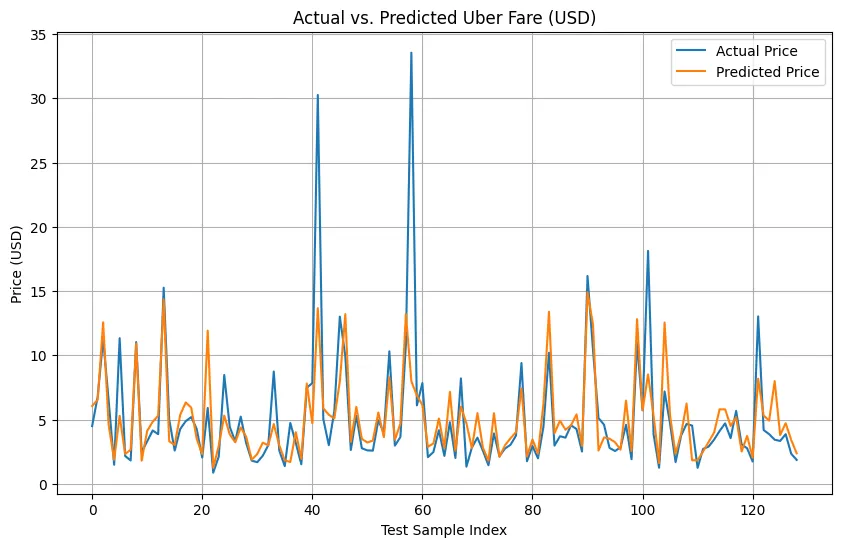
plt.present()Dieser Code stellt die tatsächlichen Uber -Tarife aus Ihren Testdaten mit den von Ihrem Modell vorhergesagten Tarifen auf, sodass Sie vergleichen können, wie intestine das Modell visuell ausgeführt wurde.
Ausgabe:
Schritt 3: Deep Studying (Neuronale Netze)
Uber hat Deepeta implementiert, im Grunde genommen mit einem künstlichen neuronalen Netzwerk, das in einem großen Datensatz mit Eingabefaktoren wie Koordinaten aus GPS sowie früheren Fahrverläufen und Echtzeitverkehrseingaben geschult wurde. Dadurch können Sie die Zeitleiste einer bevorstehenden Taxifahrt und potenziellen Anstiegsvorschriften aufgrund ihrer Algorithmen vorhersagen, die Muster aus mehreren Datensorten erfassen.

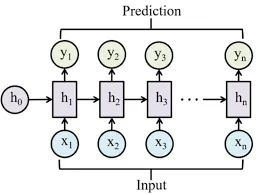
Schritt 4: wiederkehrende neuronale Netzwerke (RNNs)
RNNs sind besonders nützlich für Zeitreihendaten, bei denen sie frühere Developments sowie Echtzeitdaten einnehmen und diese Informationen einbeziehen, um die zukünftige Nachfrage vorherzusagen. Die Vorhersage der Nachfrage ist im Allgemeinen ein fortlaufender Prozess, der eine effektive Beteiligung in Echtzeit erfordert.
Schritt 5: Echtzeit-Datenverarbeitung
Uber erfasst, kombiniert und integriert immer Echtzeitdaten, die für den Standort der Fahrer, Fahreranforderungen und Verkehrsinformationen in ihre ML-Modelle related sind. Bei der Echtzeitverarbeitung kann Uber anstelle eines einmaligen Datenverarbeitungsansatzes kontinuierlich Suggestions in ihre Modelle geben. Diese Modelle können sofort auf sich ändernde Bedingungen und Echtzeitinformationen reagieren.
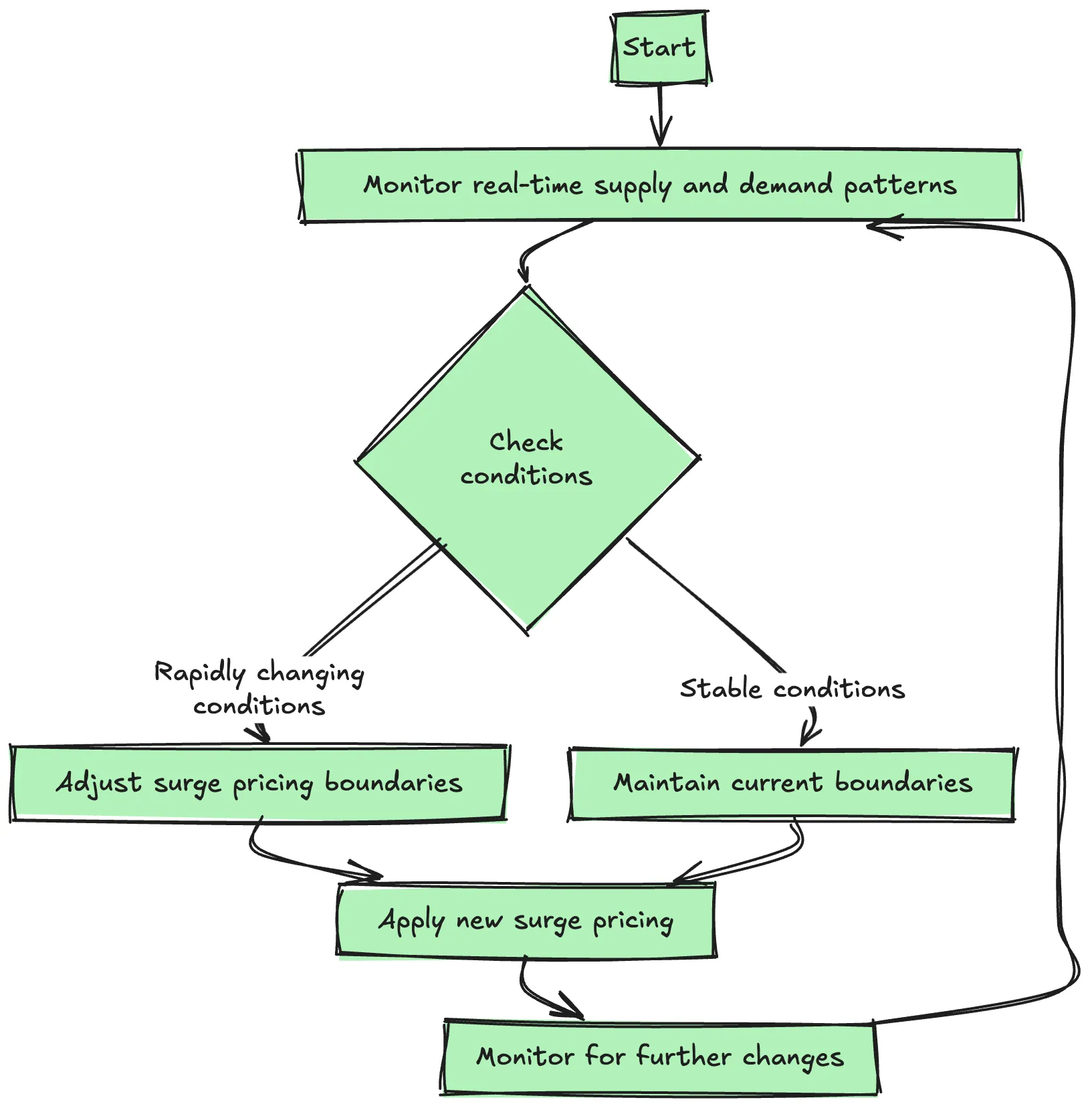
Schritt 6: Clustering -Algorithmen
Diese Techniken werden verwendet, um Muster für die Nachfrage an bestimmten Orten und Zeiten zu ermitteln, wodurch die Uber -Infrastruktur mit der allgemeinen Nachfrage mit Angebot übereinstimmt und Nachfragespitzen aus der Vergangenheit vorhersagt.
Schritt 7: Kontinuierliche Modellverbesserung
Uber kann ihre Modelle kontinuierlich verbessern, basierend auf dem Suggestions von dem, was tatsächlich passiert ist. Uber kann einen evidenzbasierten Ansatz entwickeln, in dem die Nachfrage mit der tatsächlich tatsächlich auftretenden Nachfrage verglichen wird, wobei potenzielle Störfaktoren und kontinuierliche Betriebsänderungen berücksichtigt werden.
Sie können auf den vollständigen Code von zugreifen Das Colab Pocket book.
Wie funktioniert der Prozess?
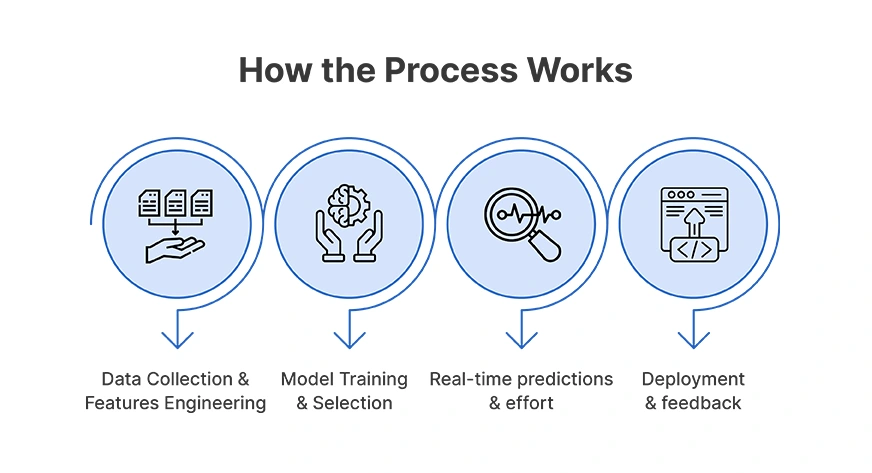
So funktioniert dieser gesamte Prozess:
- Datenerfassung und Funktionen Engineering: Historische und Echtzeitdaten aggregieren und beseitigen. Ingenieurfunktionen wie Tages-, Wetter- und Veranstaltungsflaggen.
- Modelltraining & Auswahl: Erforschen Sie mehrere Algorithmen (statistisch, ML, Deep Studying), um das beste für jede Stadt oder Area zu finden.
- Echtzeit-Vorhersagen und Anstrengungen: Erstellen Sie kontinuierlich Modelle, um neue Daten zu konsumieren, um die Prognosen zu aktualisieren. Da wir uns mit Unsicherheit befassen, ist es wichtig, sowohl Punktvorhersagen als auch Konfidenzintervalle zu generieren.
- Bereitstellung und Suggestions: Bereitstellen von Modellen im Maßstab mithilfe eines verteilten Computerframeworks. Verfeinern Sie Modelle mithilfe der tatsächlichen Ergebnisse und neuen Daten.
Herausforderungen
Hier sind einige der Herausforderungen, um Vorhersagemodelle zu fordern:
- Räumlich-zeitliche Komplexität: Die Nachfrage variiert stark von Zeit und Ort und erfordert sehr körnige, skalierbare Modelle.
- Datensparalität für excessive Ereignisse: Begrenzte Daten für seltene Ereignisse erschweren es, genau zu modellieren.
- Externe Unvorhersehbarkeit: Ungeplante Ereignisse wie plötzliche Wetteränderungen können selbst die besten Programme stören.
Wirkliche Auswirkungen
Hier sind einige der Auswirkungen des Nachfragevorhersagealgorithmus:
- Treiberzuweisung: Uber kann die Fahrer auf die Straße in hochdarstellende Gebiete leiten (als beizulegende Zeitwerte bezeichnet), sie dort vor dem Auftritt des Anstiegs dorthin senden und die Leerlaufzeit der Fahrer verkürzen und gleichzeitig den Service für die Fahrer verbessern.
- Überspannungspreis: Bedarfsvorhersagen werden mit der Dehydration der Nachfrage kombiniert, wobei automatisch dynamische Preise ausgelöst werden, die das Angebots-/Nachfrage -Gleichgewicht erleichtert und gleichzeitig sicherstellt, dass immer ein zuverlässiger Service für die Fahrer zur Verfügung steht.
- Ereignisvorhersage: Spezialisierte Prognosen können basierend auf großen Ereignissen oder negativem Wetter ausgelöst werden, das bei der Ressourcenzuweisung und -marketing beiträgt.
- Custom des Lernens: Die ML-Systeme von Uber lernen aus jeder Fahrt und stimmen Sie die Vorhersagen für genauere Empfehlungen weiter ab.
Abschluss
Die Nachfragevorhersage von Uber ist ein Beispiel für modernes maschinelles Lernen in Aktion-durch das Mischen historischer Developments, Echtzeitdaten und anspruchsvollen Algorithmen hält Uber nicht nur den Marktplatz reibungslos, sondern bietet auch Fahrern und Fahrern ein nahtloses Erlebnis. Dieses Engagement für Vorhersageanalysen ist Teil dessen, warum Uber weiterhin den Experience-Hagel-Raum leitet.
Häufig gestellte Fragen
A. Uber verwendet statistische Modelle, ML und Deep Studying, um die Nachfrage unter Verwendung historischer Daten, Echtzeiteingaben und externen Signalen wie Wetter oder Ereignissen zu prognostizieren.
A. Hauptdaten umfassen Reiseprotokolle, App -Aktivität, Wetter, Ereignisse, Flugankömmlinge und lokale Störungen.
A. Es sorgt für den Guthaben des Marktplatzes, verringert die Wartezeiten des Fahrers, steigert die Fahrereinnahmen und informiert die Preisgestaltung und die Ressourcenzuweisung.
Datenwissenschaftler | AWS Licensed Options Architect | KI & ML Innovator
Als Datenwissenschaftler bei Analytics Vidhya spezialisiere ich mich auf maschinelles Lernen, Deep Studying und KI-gesteuerte Lösungen, die NLP-, Pc-Imaginative and prescient- und Cloud-Technologien nutzen, um skalierbare Anwendungen zu erstellen.
Mit einem B.Tech in Informatik (Information Science) aus VIT- und Zertifizierungen wie AWS Licensed Options Architect und TensorFlow umfasst meine Arbeit generative KI, Anomalie -Erkennung, falsche Nachrichtenerkennung und Emotionserkennung. Ich bemühe mich, intelligente Systeme zu entwickeln, die die Zukunft der KI prägen.
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.