

Bild vom Autor
# Einführung in das Experiment
Die Optimierung von Hyperparametern wird oft als Wundermittel für maschinelles Lernen angepriesen. Das Versprechen ist einfach: Passen Sie ein paar Stunden lang einige Parameter an, führen Sie eine Rastersuche durch und beobachten Sie, wie die Leistung Ihres Modells steigt.
Aber funktioniert es tatsächlich in der Praxis?

Bild vom Autor
Wir haben diese Prämisse anhand von Leistungsdaten portugiesischer Schüler mithilfe von vier verschiedenen Klassifikatoren und einer strengen statistischen Validierung getestet. Unser Ansatz nutzte verschachtelte Kreuzvalidierung (CV), robuste Vorverarbeitungs-Pipelines und statistische Signifikanztests – und das alles.
Das Ergebnis? Die Leistung sank um 0,0005. Das ist richtig – durch das Tuning wurden die Ergebnisse tatsächlich etwas schlechter, obwohl der Unterschied statistisch nicht signifikant conflict.
Dies ist jedoch keine Misserfolgsgeschichte. Es ist etwas Wertvolleres: ein Beweis dafür, dass Standardeinstellungen in vielen Fällen bemerkenswert intestine funktionieren. Manchmal ist es am besten zu wissen, wann man mit dem Tuning aufhört und sich auf andere Dinge konzentriert.
Möchten Sie das vollständige Experiment sehen? Schauen Sie sich das an Komplettes Jupyter-Pocket book mit sämtlichem Code und Analysen.
# Einrichten des Datensatzes

Bild vom Autor
Wir haben den Datensatz von verwendet StrataScratch’s Projekt „Studierende Leistungsanalyse“. Es enthält Aufzeichnungen für 649 Schüler mit 30 Merkmalen zu Demografie, familiärem Hintergrund, sozialen Faktoren und schulbezogenen Informationen. Das Ziel bestand darin, vorherzusagen, ob die Schüler ihre Abschlussnote in Portugiesisch bestehen (eine Punktzahl von ≥ 10).
Eine entscheidende Entscheidung bei diesem Aufbau conflict der Ausschluss der Klassen G1 und G2. Dabei handelt es sich um Noten der ersten und zweiten Unterrichtsstunde, die 0,83–0,92 mit der Abschlussnote G3 korrelieren. Ihre Einbeziehung macht die Vorhersage trivial einfach und macht den Zweck des Experiments zunichte. Wir wollten herausfinden, was den Erfolg über die vorherige Leistung im selben Kurs hinaus vorhersagt.
Wir haben das genutzt Pandas Bibliothek zum Laden und Vorbereiten der Daten:
# Load and put together knowledge
df = pd.read_csv('student-por.csv', sep=';')
# Create go/fail goal (grade >= 10)
PASS_THRESHOLD = 10
y = (df('G3') >= PASS_THRESHOLD).astype(int)
# Exclude G1, G2, G3 to stop knowledge leakage
features_to_exclude = ('G1', 'G2', 'G3')
X = df.drop(columns=features_to_exclude)Die Klassenverteilung ergab, dass 100 Schüler durchfielen (15,4 %), während 549 bestanden (84,6 %). Da die Daten unausgeglichen sind, haben wir die Optimierung eher auf den F1-Rating als auf einfache Genauigkeit ausgerichtet.
# Bewertung der Klassifikatoren
Wir haben vier Klassifikatoren ausgewählt, die unterschiedliche Lernansätze repräsentieren:

Bild vom Autor
Jedes Modell wurde zunächst mit Standardparametern betrieben, gefolgt von einer Optimierung per Rastersuche mit 5-fachem CV.
# Etablierung einer robusten Methodik
Viele Tutorials zum maschinellen Lernen zeigen beeindruckende Optimierungsergebnisse, da sie wichtige Validierungsschritte überspringen. Wir haben einen hohen Commonplace eingehalten, um sicherzustellen, dass unsere Ergebnisse zuverlässig sind.
Unsere Methodik umfasste:
- Kein Datenverlust: Die gesamte Vorverarbeitung wurde innerhalb von Pipelines durchgeführt und passte nur auf Trainingsdaten
- Verschachtelte Kreuzvalidierung: Wir haben eine innere Schleife zur Optimierung der Hyperparameter und eine äußere Schleife zur endgültigen Auswertung verwendet
- Angemessene Zug-/Testaufteilung: Wir haben eine 80/20-Aufteilung mit Schichtung verwendet und den Testsatz bis zum Ende getrennt gehalten (d. h. kein „Peeking“).
- Statistische Validierung: Wir haben uns beworben McNemars Check um zu überprüfen, ob die Leistungsunterschiede statistisch signifikant waren
- Metrikauswahl: Wir haben dem F1-Rating für unausgeglichene Klassen Vorrang vor der Genauigkeit gegeben
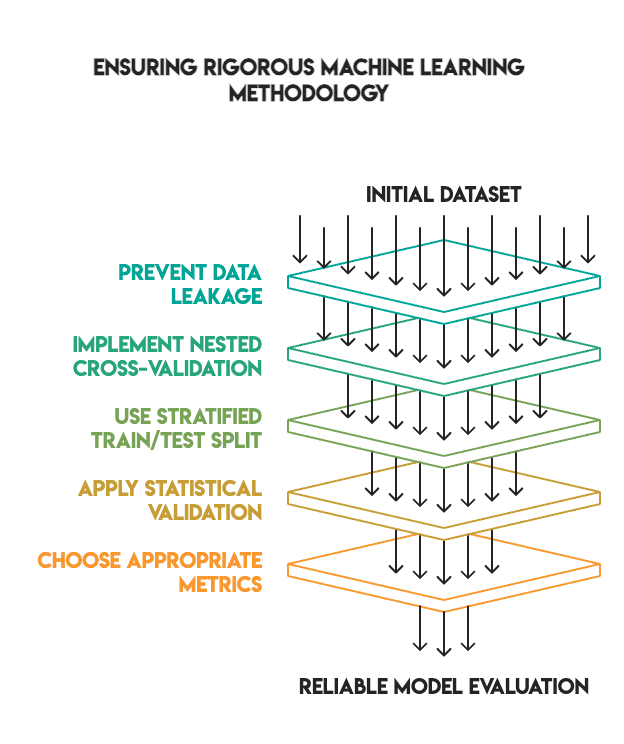
Bild vom Autor
Die Pipelinestruktur conflict wie folgt:
# Preprocessing pipeline - match solely on coaching folds
numeric_transformer = Pipeline((
('imputer', SimpleImputer(technique='median')),
('scaler', StandardScaler())
))
categorical_transformer = Pipeline((
('imputer', SimpleImputer(technique='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
))
# Mix transformers
from sklearn.compose import ColumnTransformer
preprocessor = ColumnTransformer(transformers=(
('num', numeric_transformer, X.select_dtypes(embrace=('int64', 'float64')).columns),
('cat', categorical_transformer, X.select_dtypes(embrace=('object')).columns)
))
# Full pipeline with mannequin
pipeline = Pipeline((
('preprocessor', preprocessor),
('classifier', mannequin)
))# Analyse der Ergebnisse
Nach Abschluss des Tuning-Prozesses waren die Ergebnisse überraschend:
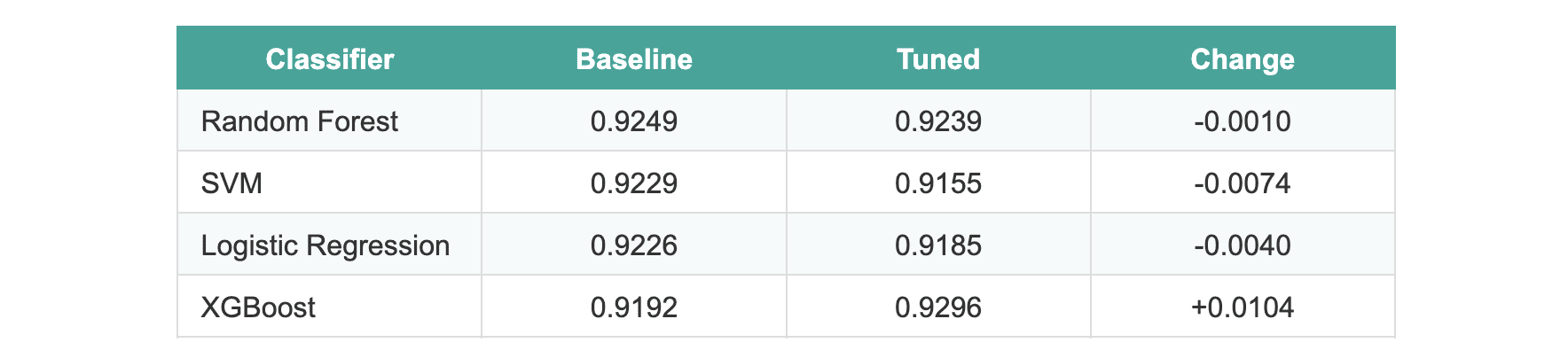
Die durchschnittliche Verbesserung über alle Modelle hinweg betrug -0,0005.
Drei Modelle schnitten nach dem Tuning tatsächlich etwas schlechter ab. XGBoost zeigte eine Verbesserung von etwa 1 %, was vielversprechend erschien, bis wir statistische Checks anwendeten. Bei der Auswertung mit dem Maintain-out-Testsatz zeigte keines der Modelle statistisch signifikante Unterschiede.
Wir sind gerannt McNemars Check Vergleich der beiden leistungsstärksten Modelle (Random Forest versus XGBoost). Der p-Wert betrug 1,0, was keinen signifikanten Unterschied zwischen der Standardversion und der optimierten Model bedeutet.
# Erklären, warum die Optimierung fehlgeschlagen ist

Bild vom Autor
Mehrere Faktoren erklären diese Ergebnisse:
- Starke Ausfälle. scikit-lernen und XGBoost werden mit hochoptimierten Standardparametern ausgeliefert. Bibliotheksverwalter haben diese Werte im Laufe der Jahre verfeinert, um sicherzustellen, dass sie in einer Vielzahl von Datensätzen effektiv funktionieren.
- Begrenztes Sign. Nach dem Entfernen der G1- und G2-Bewertungen (die zu Datenlecks geführt hätten) hatten die verbleibenden Funktionen eine geringere Vorhersagekraft. Es conflict einfach nicht mehr genug Sign vorhanden, um die Hyperparameteroptimierung auszunutzen.
- Kleine Datensatzgröße. Da nur 649 Proben in Trainingsfalten aufgeteilt waren, lagen für die Rastersuche nicht genügend Daten vor, um wirklich aussagekräftige Muster zu identifizieren. Die Rastersuche erfordert umfangreiche Daten, um zuverlässig zwischen verschiedenen Parametersätzen unterscheiden zu können.
- Leistungsobergrenze. Die meisten Basismodelle erzielten bereits Werte zwischen 92 und 93 % F1. Der Spielraum für Verbesserungen ist natürlich begrenzt, ohne bessere Funktionen oder mehr Daten einzuführen.
- Strenge Methodik. Wenn Sie Datenlecks beseitigen und verschachtelte CVs verwenden, verschwinden die überhöhten Verbesserungen, die häufig bei unsachgemäßer Validierung auftreten.
# Aus den Ergebnissen lernen
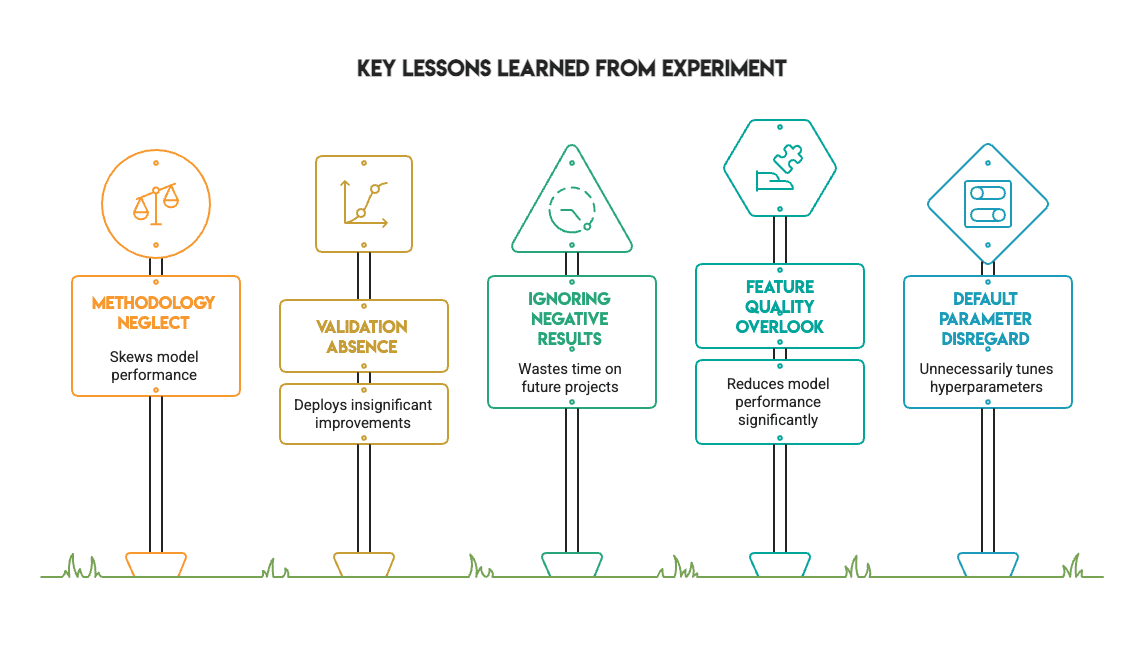
Bild vom Autor
Dieses Experiment bietet jedem Praktiker mehrere wertvolle Lektionen:
- Methodik ist wichtiger als Metriken. Das Beheben von Datenlecks und die Verwendung einer ordnungsgemäßen Validierung verändern das Ergebnis eines Experiments. Die beeindruckenden Ergebnisse, die durch eine unsachgemäße Validierung erzielt werden, verschwinden, wenn der Prozess korrekt gehandhabt wird.
- Eine statistische Validierung ist unerlässlich. Ohne den Check von McNemar hätten wir XGBoost möglicherweise fälschlicherweise basierend auf einer nominellen Verbesserung von 1 % eingesetzt. Der Check ergab, dass es sich lediglich um Lärm handelte.
- Adverse Ergebnisse haben einen immensen Wert. Nicht jedes Experiment muss eine huge Verbesserung zeigen. Zu wissen, wann eine Optimierung nicht hilft, spart Zeit bei zukünftigen Projekten und ist ein Zeichen für einen ausgereiften Arbeitsablauf.
- Commonplace-Hyperparameter werden unterschätzt. Für Standarddatensätze sind häufig Standardwerte ausreichend. Gehen Sie nicht davon aus, dass Sie jeden Parameter von Anfang an anpassen müssen.
# Zusammenfassung der Ergebnisse
Wir haben versucht, die Modellleistung durch umfassende Optimierung der Hyperparameter zu steigern, indem wir die Greatest Practices der Branche befolgten und statistische Validierung auf vier verschiedene Modelle anwendeten.
Das Ergebnis: keine statistisch signifikante Verbesserung.

Bild vom Autor
Das ist *kein* Fehler. Stattdessen stellt es ehrliche Ergebnisse dar, die es Ihnen ermöglichen, in der realen Projektarbeit bessere Entscheidungen zu treffen. Es sagt Ihnen, wann Sie mit der Optimierung der Hyperparameter aufhören und wann Sie sich auf andere kritische Aspekte wie Datenqualität, Function-Engineering oder das Sammeln zusätzlicher Stichproben konzentrieren müssen.
Beim maschinellen Lernen geht es nicht darum, auf irgendeine Weise die höchstmögliche Zahl zu erreichen; Es geht darum, Modelle zu bauen, denen Sie vertrauen können. Dieses Vertrauen beruht auf dem methodischen Prozess, der zur Erstellung des Modells verwendet wurde, und nicht auf der Jagd nach geringfügigen Gewinnen. Die schwierigste Fähigkeit beim maschinellen Lernen besteht darin, zu wissen, wann man aufhören muss.
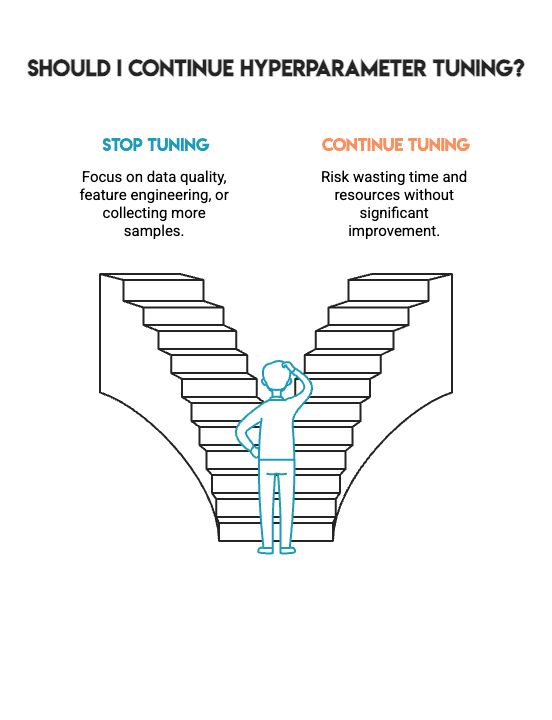
Bild vom Autor
Nate Rosidi ist Datenwissenschaftler und in der Produktstrategie tätig. Er ist außerdem außerordentlicher Professor für Analytik und Gründer von StrataScratch, einer Plattform, die Datenwissenschaftlern hilft, sich mit echten Interviewfragen von Prime-Unternehmen auf ihre Interviews vorzubereiten. Nate schreibt über die neuesten Traits auf dem Karrieremarkt, gibt Ratschläge zu Vorstellungsgesprächen, stellt Information-Science-Projekte vor und behandelt alles rund um SQL.