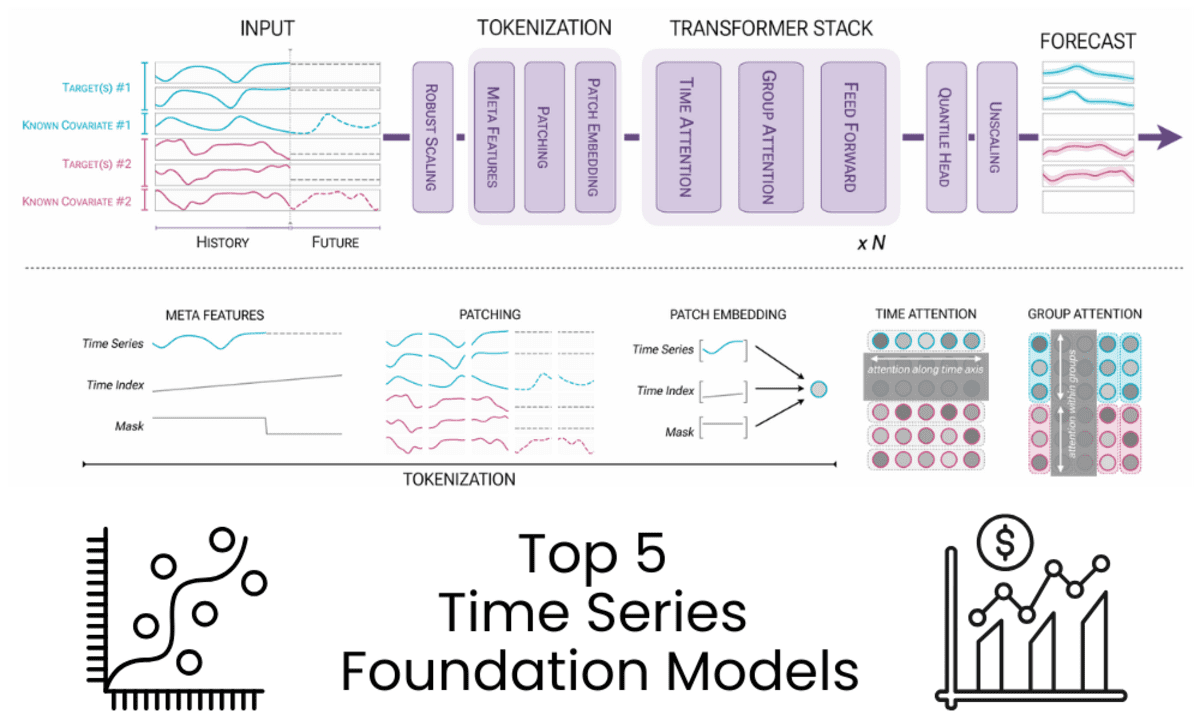
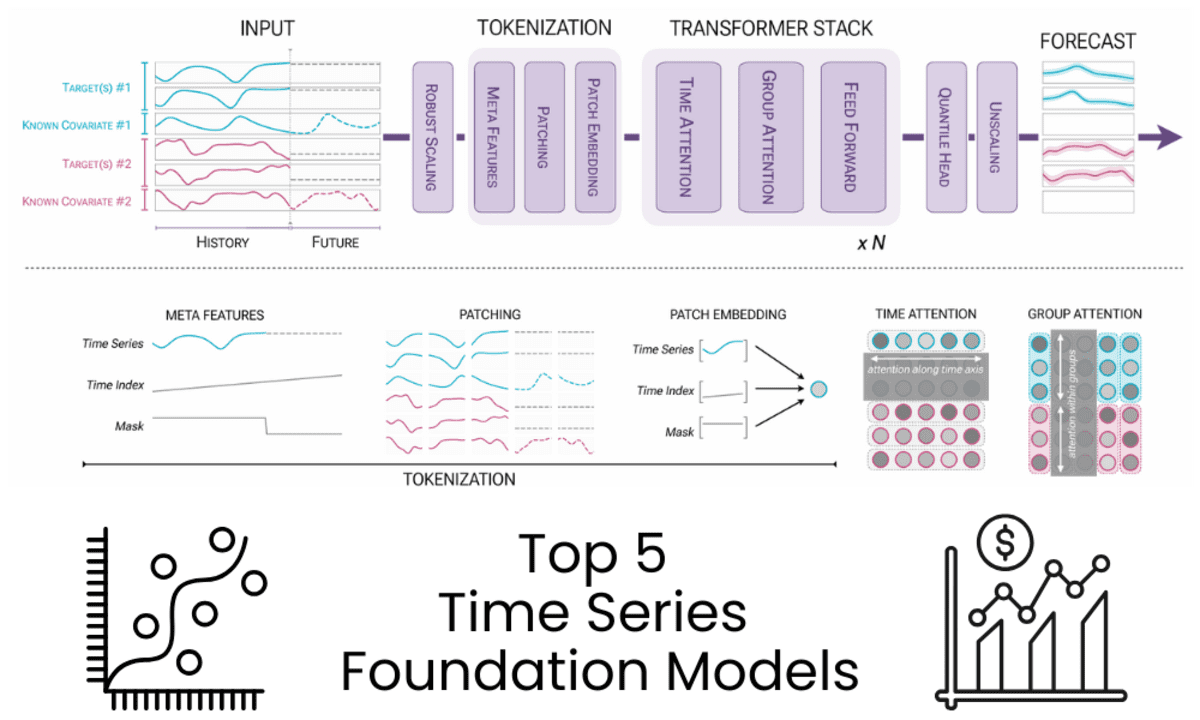
Bild vom Autor | Diagramm von Chronos-2: Von der univariaten zur universellen Prognose
# Einführung
Basis-Modelle begannen nicht mit ChatGPT. Lange bevor große Sprachmodelle populär wurden, trieben vorab trainierte Modelle bereits den Fortschritt in der Computervision und der Verarbeitung natürlicher Sprache voran, einschließlich Bildsegmentierung, Klassifizierung und Textverständnis.
Derselbe Ansatz verändert nun die Zeitreihenvorhersage. Anstatt für jeden Datensatz ein separates Modell zu erstellen und zu optimieren, werden Zeitreihen-Grundlagenmodelle anhand großer und vielfältiger Sammlungen zeitlicher Daten vorab trainiert. Sie können eine starke Zero-Shot-Prognoseleistung über Domänen, Häufigkeiten und Horizonte hinweg liefern und passen oft zu Deep-Studying-Modellen, die stundenlanges Coaching erfordern und nur historische Daten als Eingabe verwenden.
Wenn Sie sich immer noch hauptsächlich auf klassische statistische Methoden oder Deep-Studying-Modelle mit einzelnen Datensätzen verlassen, verpassen Sie möglicherweise einen großen Wandel in der Artwork und Weise, wie Prognosesysteme aufgebaut sind.
In diesem Tutorial überprüfen wir fünf Zeitreihen-Grundlagenmodelle, die auf der Grundlage von Leistung, Beliebtheit, gemessen an Hugging Face-Downloads, und praktischer Benutzerfreundlichkeit ausgewählt wurden.
# 1. Chronos-2
Chronos-2 ist ein 120-M-Parameter-Encoder-basiertes Zeitreihen-Basismodell, das für Zero-Shot-Prognosen entwickelt wurde. Es unterstützt univariate, multivariate und kovariate Prognosen in einer einzigen Architektur und liefert genaue mehrstufige probabilistische Prognosen ohne aufgabenspezifische Schulung.
Hauptmerkmale:
- Nur-Encoder-Architektur, inspiriert von T5
- Zero-Shot-Prognose mit Quantil-Ausgaben
- Native Unterstützung für vergangene und bekannte zukünftige Kovariaten
- Lange Kontextlänge bis zu 8.192 und Prognosehorizont bis zu 1.024
- Effiziente CPU- und GPU-Inferenz mit hohem Durchsatz
Anwendungsfälle:
- Groß angelegte Prognosen über viele verwandte Zeitreihen hinweg
- Kovariatengesteuerte Prognosen wie Nachfrage, Energie und Preise
- Schnelle Prototypenerstellung und Produktionsbereitstellung ohne Modellschulung
Beste Anwendungsfälle:
- Produktionsprognosesysteme
- Forschung und Benchmarking
- Komplexe multivariate Prognose mit Kovariaten
# 2. TiRex
TiRex ist ein vorab trainiertes Zeitreihen-Prognosemodell mit 35 Millionen Parametern, das auf xLSTM basiert und für Zero-Shot-Prognosen sowohl über lange als auch kurze Zeithorizonte konzipiert ist. Es kann genaue Prognosen erstellen, ohne dass eine Schulung zu aufgabenspezifischen Daten erforderlich ist, und liefert sowohl punktuelle als auch probabilistische Vorhersagen sofort einsatzbereit.
Hauptmerkmale:
- Vorab trainierte xLSTM-basierte Architektur
- Zero-Shot-Prognose ohne datensatzspezifisches Coaching
- Punktvorhersagen und quantilbasierte Unsicherheitsschätzungen
- Starke Leistung sowohl bei den Benchmarks für lange als auch kurze Horizonte
- Optionale CUDA-Beschleunigung für Hochleistungs-GPU-Inferenz
Anwendungsfälle:
- Zero-Shot-Prognose für neue oder unbekannte Zeitreihendatensätze
- Lang- und kurzfristige Prognosen in den Bereichen Finanzen, Energie und Betrieb
- Schnelles Benchmarking und Bereitstellung ohne Modellschulung
# 3. TimesFM
TimesFM ist ein vorab trainiertes Zeitreihen-Basismodell, das von Google Analysis für Zero-Shot-Prognosen entwickelt wurde. Der offene Checkpoint timesfm-2.0-500m ist ein reines Decoder-Modell, das für univariate Prognosen entwickelt wurde und lange historische Kontexte und versatile Prognosehorizonte ohne aufgabenspezifisches Coaching unterstützt.
Hauptmerkmale:
- Nur-Decoder-Basis-Modell mit einem 500M-Parameter-Kontrollpunkt
- Zero-Shot-Prognose für univariate Zeitreihen
- Kontextlänge bis zu 2.048 Zeitpunkte, mit Unterstützung über die Trainingsgrenzen hinaus
- Versatile Prognosehorizonte mit optionalen Häufigkeitsindikatoren
- Optimiert für schnelle Punktvorhersagen im großen Maßstab
Anwendungsfälle:
- Groß angelegte univariate Prognosen für verschiedene Datensätze
- Langfristige Prognosen für Betriebs- und Infrastrukturdaten
- Schnelles Experimentieren und Benchmarking ohne Modelltraining
# 4. IBM Granite TTM R2
Granite-TimeSeries-TTM-R2 ist eine Familie kompakter, vorab trainierter Zeitreihen-Basismodelle, die von IBM Analysis unter dem TinyTimeMixers (TTM)-Framework entwickelt wurden. Diese für multivariate Prognosen konzipierten Modelle erzielen trotz Modellgrößen von nur 1 Million Parametern eine starke Zero-Shot- und Fence-Shot-Leistung, wodurch sie sowohl für die Forschung als auch für Umgebungen mit eingeschränkten Ressourcen geeignet sind.
Hauptmerkmale:
- Winzige vorab trainierte Modelle ab 1 Mio. Parametern
- Starke multivariate Zero-Shot- und Fence-Shot-Prognoseleistung
- Fokussierte Modelle, die auf bestimmte Kontexte und Prognoselängen zugeschnitten sind
- Schnelle Inferenz und Feinabstimmung auf einer einzelnen GPU oder CPU
- Unterstützung für exogene Variablen und statische kategoriale Merkmale
Anwendungsfälle:
- Multivariate Prognose in ressourcenarmen oder Edge-Umgebungen
- Zero-Shot-Grundlinien mit optionaler leichter Feinabstimmung
- Schnelle Bereitstellung für Betriebsprognosen mit begrenzten Daten
# 5. Toto Open Base 1
Toto-Open-Base-1.0 ist ein reines Decoder-Zeitreihen-Grundmodell, das für multivariate Vorhersagen in Beobachtbarkeits- und Überwachungsumgebungen entwickelt wurde. Es ist für hochdimensionale, spärliche und instationäre Daten optimiert und liefert eine starke Zero-Shot-Leistung bei groß angelegten Benchmarks wie GIFT-Eval und BOOM.
Hauptmerkmale:
- Nur-Decoder-Transformer für versatile Kontext- und Vorhersagelängen
- Zero-Shot-Prognose ohne Feinabstimmung
- Effizienter Umgang mit hochdimensionalen multivariaten Daten
- Probabilistische Prognosen unter Verwendung eines Scholar-T-Mischungsmodells
- Vorab trainiert anhand von über zwei Billionen Zeitreihen-Datenpunkten
Anwendungsfälle:
- Prognose von Beobachtbarkeits- und Überwachungsmetriken
- Hochdimensionale System- und Infrastrukturtelemetrie
- Zero-Shot-Prognose für großräumige, instationäre Zeitreihen
Zusammenfassung
In der folgenden Tabelle werden die Kernmerkmale der besprochenen Zeitreihen-Basismodelle verglichen, wobei der Schwerpunkt auf Modellgröße, Architektur und Prognosefähigkeiten liegt.
| Modell | Parameter | Architektur | Prognosetyp | Schlüsselstärken |
|---|---|---|---|---|
| Chronos-2 | 120M | Nur Encoder | Univariat, multivariat, probabilistisch | Starke Nullpunktgenauigkeit, langer Kontext und Horizont, hoher Inferenzdurchsatz |
| TiRex | 35M | xLSTM-basiert | Univariat, probabilistisch | Leichtes Modell mit starker Kurz- und Langstreckenleistung |
| TimesFM | 500M | Nur Decoder | Univariate Punktvorhersagen | Bewältigt lange Kontexte und versatile Horizonte im großen Maßstab |
| Granite TimeSeries TTM-R2 | 1M – klein | Fokussierte vorab trainierte Modelle | Multivariate Punktvorhersagen | Extrem kompakt, schnelle Inferenz, starke Null- und Wenig-Schuss-Ergebnisse |
| Toto Open Base 1 | 151M | Nur Decoder | Multivariat, probabilistisch | Optimiert für hochdimensionale, instationäre Beobachtbarkeitsdaten |
Abid Ali Awan (@1abidaliawan) ist ein zertifizierter Datenwissenschaftler, der gerne Modelle für maschinelles Lernen erstellt. Derzeit konzentriert er sich auf die Erstellung von Inhalten und das Schreiben technischer Blogs zu maschinellem Lernen und Datenwissenschaftstechnologien. Abid verfügt über einen Grasp-Abschluss in Technologiemanagement und einen Bachelor-Abschluss in Telekommunikationstechnik. Seine Imaginative and prescient ist es, ein KI-Produkt mithilfe eines graphischen neuronalen Netzwerks für Schüler mit psychischen Erkrankungen zu entwickeln.