Randomisierte Experimente (z. B. A/B-Assessments, RCTs) sind großartig. Ein einfaches Experiment mit Behandlung vs. Kontrolle, bei dem alle Einheiten die gleiche Wahrscheinlichkeit haben, einer Behandlung zugeteilt zu werden, stellt sicher, dass der Erhalt der Behandlung nicht systematisch mit beobachteten oder unbeobachteten Eigenschaften der Versuchseinheiten korreliert. Es wird Unterschiede geben, z. B. bei den mittleren Kovariaten zwischen Behandlung und Kontrolle, aber diese werden bereits bei der standardmäßigen statistischen Inferenz über die Auswirkungen der Behandlung berücksichtigt.
Bei der Randomisierung kann jedoch etwas schiefgehen. Dies ist oft als eine Artwork latenter Nichteinhaltung oder Abnutzung verständlich. Einige Einheiten werden der Behandlung zugewiesen, aber etwas nachgelagertes überschreibt dies und die ursprüngliche Zuweisung geht verloren (eine Artwork latenter Nichteinhaltung). Oder wenn diese Nichtübereinstimmung erkannt wird, löscht etwas nachgelagertes diese Beobachtungen aus den Daten. Oder vielleicht führt die Behandlung dazu, dass Einheiten (z. B. Benutzer einer App) das Programm sofort beenden (z. B. wenn die App abstürzt) und diese Einheit wird nicht als dem Experiment ausgesetzt protokolliert.
Additionally Es ist intestine zu überprüfen, ob einige wichtige Zusammenfassungen der Aufgaben unter der angenommenen Randomisierung nicht extrem unplausibel sind. Wir können beispielsweise einen gemeinsamen Take a look at auf Unterschiede in den Kovariaten vor der Behandlung durchführen. Oder – und das ist besonders nützlich, wenn uns eine oder viele Kovariaten fehlen – wir können einfach testen, ob die Anzahl der Einheiten in jeder Behandlung mit unserer geplanten (z. B. Bernoulli(1/2)) Randomisierung übereinstimmt; in der Technologiebranche wird dies manchmal als „Pattern Ratio Mismatch“-Take a look at (SRM) bezeichnet.
Diese Artwork von Problemen kommt recht häufig vor. Sie entstehen zumeist durch das strömende Eintreffen von Randomisierungseinheiten an dem Punkt, an dem die Behandlung angewendet wird. In Fällen, in denen Benutzer nicht angemeldet sind, ist dies unvermeidlich. In Fällen, in denen es ein Universum von Benutzerkonten gibt, kann es immer noch eine Sackgasse sein, sie alle zufällig den Behandlungen zuzuweisen und diese als analytische Stichprobe zu verwenden: Die meisten dieser Benutzer hätten den Teil des Dienstes, in dem die Behandlung angewendet wird, nie berührt. Stattdessen ist es daher üblich, die Protokollierung der Exposition gegenüber dem Experiment auszulösen und nur diese Stichprobe von Benutzern zu analysieren (die weniger als 1 % aller Benutzer ausmachen kann); die Verwendung dieser Artwork von „Auslösung“ oder Expositionsprotokollierung ist sehr verbreitet, kann aber auch diese Probleme mit sich bringen. Eine Analyse von Experimenten mit mehreren Produkten bei Microsoft ergab beispielsweise, dass Bei etwa 6 % dieser Experimente stimmten die Stichprobenverhältnisse nicht überein (bei p<0,0005).
Hier ist ein weiteres Beispiel für Randomisierungsprobleme – mit öffentlichen Daten.
Upworthy-Forschungsarchiv
Nathan Matias, Kevin Munger, Marianne Aubin Le Quere und Charles Ebersole arbeiteten mit Upworthy zusammen, um ein Datensatz von über 15.000 Experimenten mit insgesamt über 150.000 Behandlungen. Jedes dieser Experimente verändert die Überschrift oder das Bild, das mit einem Artikel auf Upworthy verknüpft ist, wie es beim Anzeigen eines anderen Schwerpunktartikels angezeigt wird; das Ergebnis sind dann Klicks auf diese Überschriften. Sie erinnern sich vielleicht an Upworthy als einen der wichtigsten Innovatoren im Bereich „Clickbait“ und insbesondere Clickbait mit einer bestimmten ideologischen Ausrichtung.
Was mir an der Artwork und Weise, wie diese Daten veröffentlicht wurden, wirklich gefällt, ist, dass sie zunächst nur eine Teilmenge der Experimente als explorativen Datensatz zur Verfügung gestellt haben. So konnten die Forscher erste Analysen dieser Daten durchführen und dann Analysen und/oder Vorhersagen für die verbleibenden Daten vorab registrieren. Für mich hat dies hilfreich verdeutlicht, dass der beste Weg, einen Datensatz als öffentliches Intestine bereitzustellen, manchmal nicht darin besteht, ihn auf einmal bereitzustellen, sondern die Artwork und Weise seiner Veröffentlichung zu strukturieren.
Randomisierungsprobleme
Es gab einige Probleme mit der Randomisierung der Behandlungen in den veröffentlichten Daten. Insbesondere wies mich Garrett Johnson darauf hin, dass oft zu viele oder zu wenige Zuschauer einer der Behandlungen (additionally SRMs) zugewiesen wurden. Im Jahr 2021 bin ich dem noch etwas näher nachgegangen. (Die folgende Analyse basiert auf den 4.869 Experimenten im explorativen Datensatz mit mindestens 1.000 Beobachtungen.)
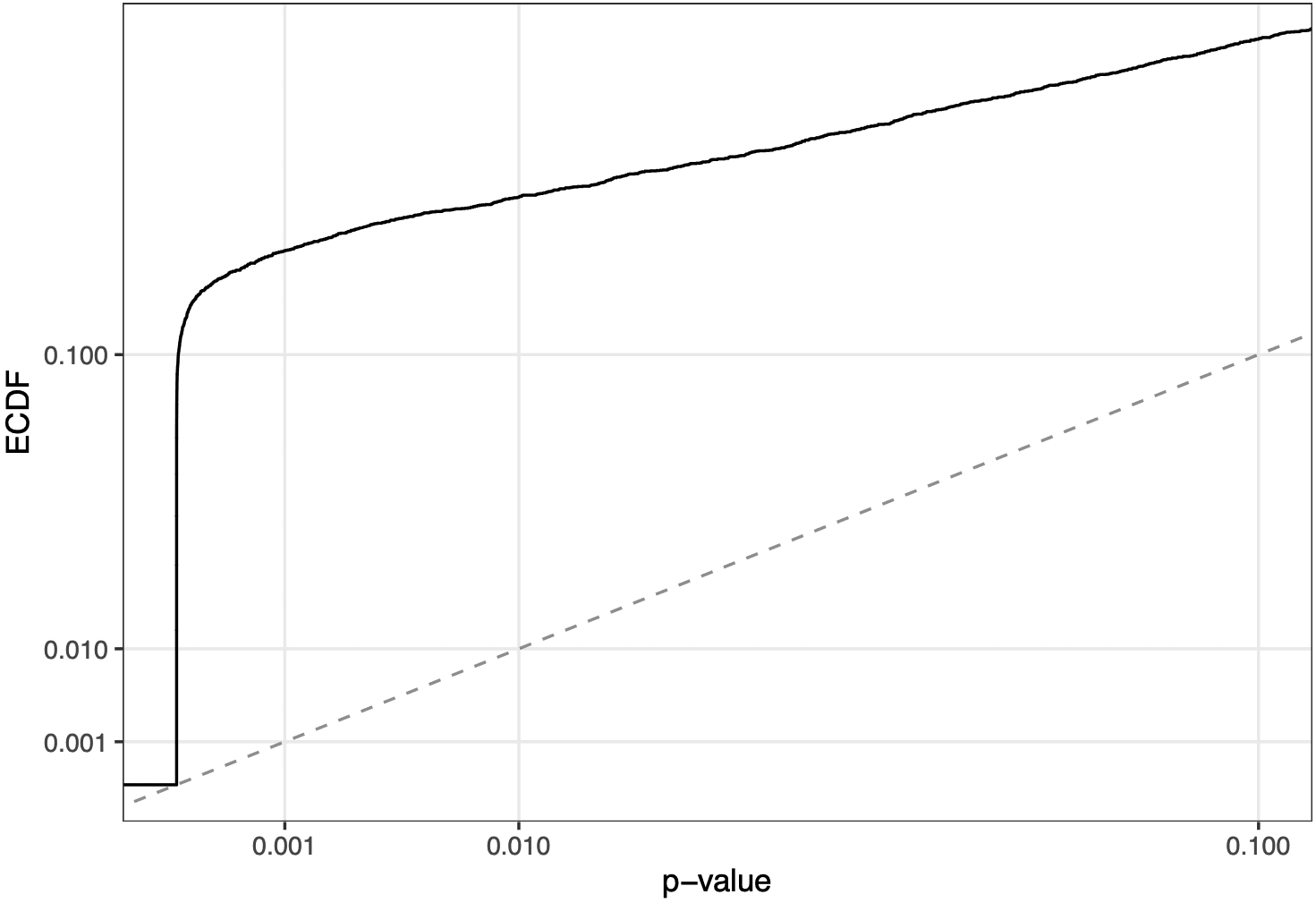
Wenn Sie für den Anteil in jeder Behandlung einen Chi-Quadrat-Take a look at durchführen, erhalten Sie eine p-Wert-Verteilung, die wie folgt aussieht, wenn Sie den interessanten Teil vergrößern:
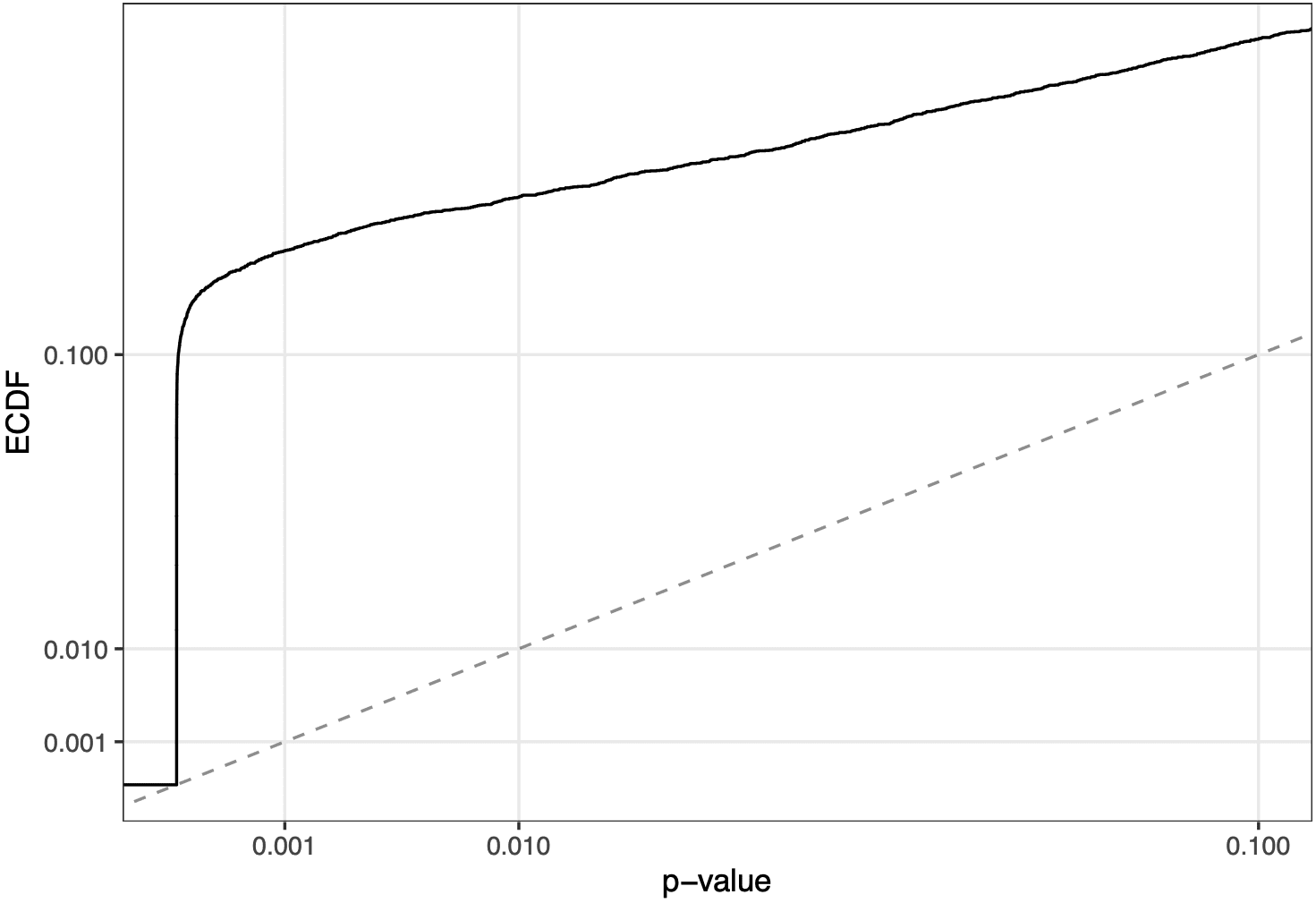
Das heißt, es gibt viel zu viele kleine p-Werte im Vergleich zur Gleichverteilung – oder, praktischer ausgedrückt, es gibt viele Experimente, die nicht die richtige Anzahl an Beobachtungen unter jeder Bedingung zu haben scheinen. Einige weitere Analysen deuteten darauf hin, dass diese „schlechten“ SRM-Experimente besonders häufig bei Experimenten auftraten, die in einem bestimmten Zeitraum durchgeführt wurden:
Aber es struggle schwer, genaue Angaben dazu zu machen, warum das so struggle.
Additionally kontaktierte ich 2022 Nathan Matias und Kevin Munger. Sie nahmen die Sache sehr ernst, aber da sie diese Experimente nicht durchgeführt oder die Werkzeuge dafür gebaut hatten, struggle es für sie schwierig, das Drawback zu untersuchen.
Nun, letzte Woche haben sie die Ergebnisse öffentlich bekannt gegeben ihrer Untersuchung. Sie vermuten, dass dieses Drawback durch Caching verursacht wurde, wodurch nachfolgenden Besuchern einer bestimmten zentralen Artikelseite möglicherweise die gleichen Überschriften für andere Artikel angezeigt wurden. Dies würde eine seltsame Artwork von autokorrelierter Randomisierung erzeugen. Vielleicht könnten Punktschätzungen immer noch unvoreingenommen und konsistent sein, aber Schlussfolgerungen, die auf der Annahme einer unabhängigen Randomisierung basieren, könnten falsch sein.
Ich persönlich bin bei einem von mir untersuchten Experiment noch nie auf diese Artwork von Caching-Drawback gestoßen. Es können andere Caching-Probleme auftreten, z. B. wenn eine neue Behandlung mehr Cache-Fehler verursacht, was die Dinge möglicherweise so verlangsamt, dass einige Protokollierungen nicht stattfinden. Dies ist additionally möglicherweise eine nützliche Ergänzung zu einer Menagerie von Zufalls-Teufeln. (Einige dieser Probleme werden in dieses Papier und andere.)
Sie identifizieren einen bestimmten Zeitraum, in dem dieses Drawback gebündelt auftritt: 25. Juni 2013 bis 10. Januar 2014.
Im Vorfeld ihrer Ankündigung kontaktierten Nathan und seine Kollegen die verschiedenen Groups, die Forschungsergebnisse mit dieser erstaunlichen Sammlung von Experimenten veröffentlicht haben. Wenn man die Daten aus dem Zeitraum mit diesem besonders starken Überschuss an SRMs ausschließt (22 % der Experimente), haben sich die Kernergebnisse dieser Groups im Allgemeinen nicht allzu sehr verändert, was additionally positiv ist.
Bleibende Probleme?
Ich habe mir den gesamten Datensatz der Experimente noch einmal angesehen. Wenn man den Zeitraum außer Acht lässt, in dem das Drawback konzentriert ist, gibt es immer noch zu viele SRMs. 113 der Experimente außerhalb dieses Zeitraums haben SRM-p-Werte < 0,001. Das sind 0,45 % bei einem 95-%-Konfidenzintervall von (0,37 %, 0,54 %), additionally handelt es sich hier eindeutig um einen Überschuss solcher unausgewogener Experimente (verglichen mit erwarteten 0,1 % unter dem Nullwert) – wenn auch viel, viel weniger als im schlechten Zeitraum (als dieser Wert bei ~2/3 liegt). Das Drawback ist vor dem akuten Zeitraum schlimmer als danach, was Sinn ergibt, wenn das Workforce eine Grundursache behoben hat:
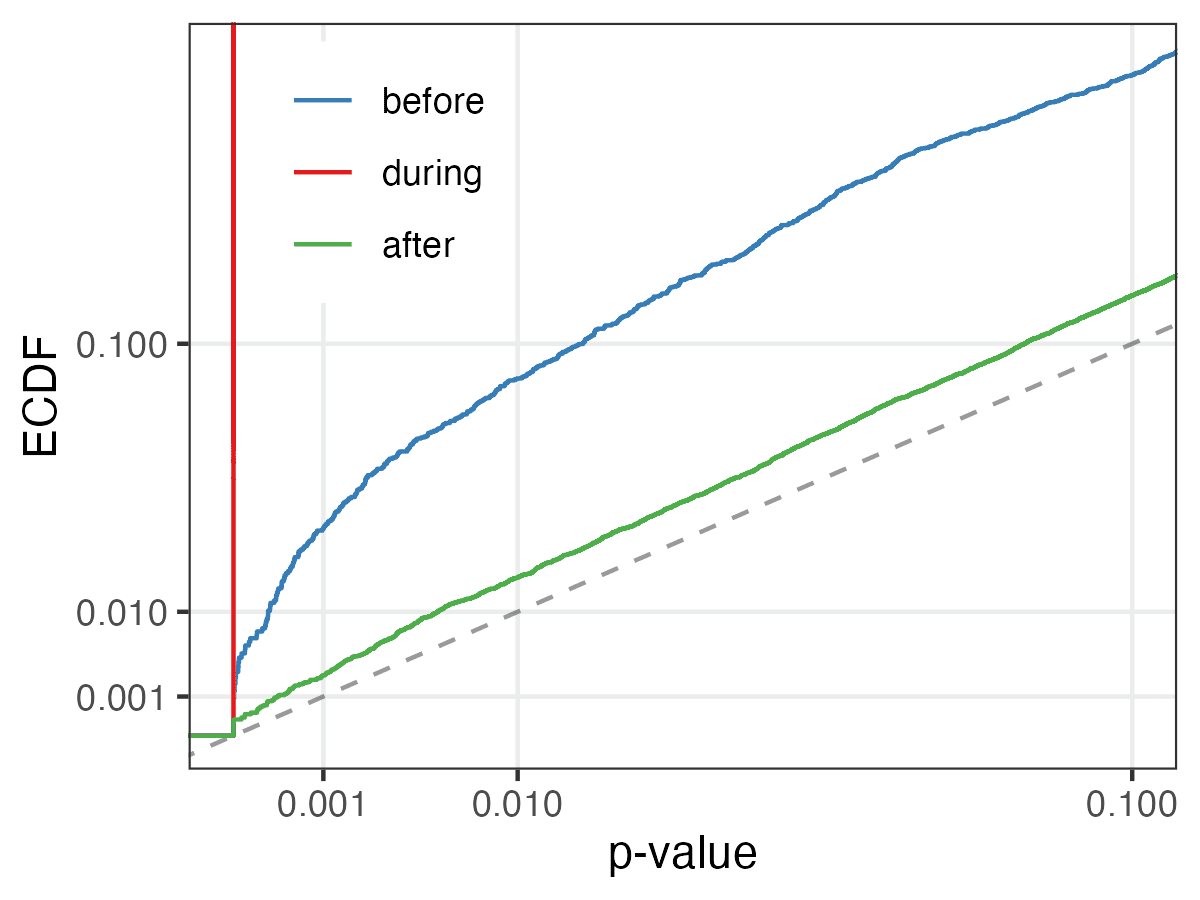
Wenn nur etwa ein halbes Prozent der verbleibenden Experimente Probleme aufweisen, sind viele Verwendungen dieser Daten wahrscheinlich nicht betroffen. Schließlich hatte das Entfernen von 22 % der Experimente keine großen Auswirkungen auf die Schlussfolgerungen anderer Arbeiten. Allerdings wissen wir natürlich nicht unbedingt, ob wir alle Verstöße gegen die Nullhypothese einer erfolgreichen Randomisierung erkennen können – einschließlich einiger, die die Ergebnisse dieses Experiments ungültig machen könnten. Aber insgesamt denke ich, dass wir im Vergleich dazu, diese Assessments nicht durchgeführt zu haben, vielleicht mehr Grund haben, den verbleibenden Experimenten zu vertrauen – insbesondere denen nach der akuten Part.
Ich hoffe, dass dies eine interessante Fallstudie ist, die weiter veranschaulicht, wie weit verbreitet und problematisch Randomisierungsprobleme sein können. Und vielleicht habe ich bald ein weiteres Beispiel.
(Dieser Beitrag stammt von Dean Eckles. Da dieser Beitrag Praktiken in der Internetbranche diskutiert, stelle ich fest, dass meine Angaben damit verbundene finanzielle Interessen beinhalten und dass ich an der Entwicklung und dem Bau einiger dieser Experimentiersysteme beteiligt struggle.)