
https://www.youtube.com/watch?v=c8fk6l1kvxq
In diesem Projektleitwechsel werden wir untersuchen, wie Sie mit großen Datensätzen effizient arbeiten, indem wir Begin -up -Investitionsdaten von Crunchbase analysieren. Durch die Optimierung des Speicherverbrauchs und die Nutzung von SQLite werden wir Erkenntnisse über Spendenbeschaffung aufdecken, während wir Techniken lernen, die auf reale Datenherausforderungen skalieren.
Die Arbeit mit großen Datensätzen ist eine häufige Herausforderung bei der Datenanalyse. Wenn Ihr Datensatz die Speicherkapazität Ihres Computer systems überschreitet, benötigen Sie intelligente Strategien, um die Daten effektiv zu verarbeiten und zu analysieren. Dieses Projekt zeigt praktische Techniken zur Behandlung mittel- bis großer Datensätze, die jeder Datenfachmann kennen sollte.
In diesem Tutorial arbeiten wir in einer selbst auferlegten Einschränkung von 10 MB Speicher-einem Lehrgerät, das die Herausforderungen simuliert, denen Sie mit wirklich massiven Datensätzen stehen werden. Am Ende haben Sie einen 57-MB-Datensatz in eine optimierte Datenbank umgewandelt, die für die Blitzanalyse bereit ist.
Was du lernen wirst
Am Ende dieses Tutorials werden Sie wissen, wie man:
- Verarbeiten Sie große CSV -Dateien in Stücken, um Speicherfehler zu vermeiden
- Identifizieren und entfernen Sie unnötige Spalten, um die Datensatzgröße zu reduzieren
- Konvertieren Sie Datentypen in speichereffizientere Alternativen
- Laden Sie optimierte Daten in SQLite für eine effiziente Abfrage
- Kombinieren Sie Pandas und SQL für leistungsstarke Datenanalyse -Workflows
- Diagnose von Codierungsproblemen und Behandeln von Nicht-UTF-8-Dateien
- Erstellen Sie Visualisierungen aus aggregierten Datenbankabfragen
Bevor Sie beginnen: Vorabstrukturierung
Folgen Sie diese vorbereitenden Schritte, um das Beste aus diesem Projekt zu machen:
-
Überprüfen Sie das Projekt
Greifen Sie auf das Projekt zu und machen Sie sich mit den Zielen und Struktur vertraut: Analyse von Startup -Spendenaktionen.
-
Greifen Sie auf das Lösungsnotizbuch zu
Sie können es hier anzeigen und herunterladen, um zu sehen, was wir behandeln werden: Lösungsnotizbuch
-
Bereiten Sie Ihre Umgebung vor
- Wenn Sie die DataQuest -Plattform verwenden, ist für Sie bereits alles eingerichtet
- Wenn Sie vor Ort arbeiten, stellen Sie sicher, dass Sie Python mit pandas und sqlite3 installiert haben
- Laden Sie den Datensatz von herunter Github (Oktober 2013 Crunchbase -Daten)
-
Voraussetzungen
- Bequem mit Python -Grundlagen (Schleifen, Wörterbücher, Datentypen)
- Grundlegende Vertrautheit mit Pandas DataFrames
- Einige SQL -Wissen sind hilfreich, aber nicht erforderlich
Neu im Markdown? Wir empfehlen, die Grundlagen zu lernen, um Header zu formatieren und Ihrem Jupyter Pocket book: Markdown -Handbuch einen Kontext hinzuzufügen.
Einrichten Ihrer Umgebung
Beginnen wir mit dem Importieren von Pandas und dem Verständnis der bevorstehenden Herausforderung:
import pandas as pd
Bevor wir mit unserem Datensatz arbeiten, lassen Sie uns unsere Einschränkung verstehen. Wir simulieren ein Szenario, in dem wir nur 10 MB Speicher für unsere Analyse zur Verfügung haben. Während diese spezifische Grenze für Unterrichtszwecke künstlich ist, gelten die Techniken, die wir lernen, direkt für reale Situationen mit Datensätzen mit Millionen von Zeilen.
Lern Perception: Als ich als Datenanalyst anfing, versuchte ich, einen 100.000-Reihen-Datensatz auf meinem lokalen Pc zu laden, und es stürzte ab. Ich battle blind, weil ich nichts über Optimierungstechniken wusste. Zu verstehen, was einen großen Speicherverbrauch verursacht und wie Sie damit umgehen können, sind wertvolle Fähigkeiten, die Ihnen unzählige Stunden der Frustration ersparen.
Laden des Datensatzes mit Chunking
Unsere erste Herausforderung: Die CSV-Datei ist nicht UTF-8 codiert. Lassen Sie uns das richtig umgehen:
# This may not work - let's have a look at the error
df = pd.read_csv('crunchbase-investments.csv')
Wenn Sie dies versuchen, erhalten Sie eine UnicodeDecodeError. Dies ist unsere erste Lektion in der Arbeit mit realen Daten: Es ist oft chaotisch!
# Let's use chunking with correct encoding
chunk_iter = pd.read_csv('crunchbase-investments.csv',
chunksize=5000,
encoding='Latin-1')
Lerneinblick: Latin-1 ist eine gute Fallback-Kodierung, wenn UTF-8 fehlschlägt. Denken Sie an Codierung wie Sprachen-wenn Ihr Pc Englisch (UTF-8) erwartet, aber spanisch wird (Latin-1), muss er wissen, wie man übersetzt wird. Der Codierungsparameter sagt nur, welche „Sprache“ zu erwarten ist.
Lassen Sie uns nun herausfinden, wie groß unser Datensatz ist:
cb_length = ()
# Rely rows throughout all chunks
for chunk in chunk_iter:
cb_length.append(len(chunk))
total_rows = sum(cb_length)
print(f"Whole rows in dataset: {total_rows}")
Whole rows in dataset: 52870
Optimierungsmöglichkeiten identifizieren
Fehlende Werte finden
Spalten mit vielen fehlenden Werten sind Hauptkandidaten für die Entfernung:
# Re-initialize the chunk iterator (it is exhausted after one move)
chunk_iter = pd.read_csv('crunchbase-investments.csv',
chunksize=5000,
encoding='Latin-1')
mv_list = ()
for chunk in chunk_iter:
if not mv_list: # First chunk - get column names
columns = chunk.columns
print("Columns in dataset:")
print(columns.sort_values())
mv_list.append(chunk.isnull().sum())
# Mix lacking worth counts throughout all chunks
combined_mv_vc = pd.concat(mv_list)
unique_combined_mv_vc = combined_mv_vc.groupby(combined_mv_vc.index).sum()
print("nMissing values by column:")
print(unique_combined_mv_vc.sort_values(ascending=False))
Columns in dataset:
Index(('company_category_code', 'company_city', 'company_country_code',
'company_name', 'company_permalink', 'company_region',
'company_state_code', 'funded_at', 'funded_month', 'funded_quarter',
'funded_year', 'funding_round_type', 'investor_category_code',
'investor_city', 'investor_country_code', 'investor_name',
'investor_permalink', 'investor_region', 'investor_state_code',
'raised_amount_usd'),
dtype='object')
Lacking values by column:
investor_category_code 50427
investor_state_code 16809
investor_city 12480
investor_country_code 12001
raised_amount_usd 3599
...
Erkenntnis lernen: die
investor_category_codeDie Spalte hat 50.427 fehlende Werte von 52.870 Gesamtzeilen. Das fehlt über 95%! Diese Spalte bietet praktisch keinen Wert und ist ein perfekter Kandidat für das Entfernen. Wenn eine Spalte mehr als 75% ihrer Werte fehlt, ist es normalerweise sicher, sie vollständig fallen zu lassen.
Analyse des Speicherverbrauchs
Lassen Sie uns sehen, welche Spalten den größten Speicher verbrauchen:
chunk_iter = pd.read_csv('crunchbase-investments.csv',
chunksize=5000,
encoding='Latin-1')
counter = 0
series_memory_fp = pd.Collection(dtype='float64')
for chunk in chunk_iter:
if counter == 0:
series_memory_fp = chunk.memory_usage(deep=True)
else:
series_memory_fp += chunk.memory_usage(deep=True)
counter += 1
# Drop the index reminiscence calculation
series_memory_fp_before = series_memory_fp.drop('Index').sort_values()
print("Reminiscence utilization by column (bytes):")
print(series_memory_fp_before)
# Whole reminiscence in megabytes
total_memory_mb = series_memory_fp_before.sum() / (1024 * 1024)
print(f"nTotal reminiscence utilization: {total_memory_mb:.2f} MB")
Reminiscence utilization by column (bytes):
funded_year 422960
raised_amount_usd 422960
investor_category_code 622424
...
investor_permalink 4980548
dtype: int64
Whole reminiscence utilization: 56.99 MB
Unser Datensatz verwendet quick 57 MB, was unsere 10 -MB -Einschränkung weit überschreitet! Die Permalink Columns (URLs) sind die größten Speicherschweine, sodass sie großartige Kandidaten aus unserem Datenrahmen entfernen können.
Implementierung von Optimierungsstrategien
Unnötige Spalten fallen lassen
Lassen Sie uns basierend auf unserer Analyse Spalten entfernen, die unserer Analyse nicht helfen:
# Columns to drop
drop_cols = ('investor_permalink', # URL - not wanted for evaluation
'company_permalink', # URL - not wanted for evaluation
'investor_category_code', # 95% lacking values
'funded_month', # Redundant - now we have funded_at
'funded_quarter', # Redundant - now we have funded_at
'funded_year') # Redundant - now we have funded_at
# Get columns to maintain
chunk = pd.read_csv('crunchbase-investments.csv', nrows=1, encoding='Latin-1')
keep_cols = chunk.columns.drop(drop_cols)
print("Columns we're protecting:")
print(keep_cols.tolist())
Erkenntnis lernen: Beachten Sie, wie wir nur fallen
investor_category_codeUnter den Spalten mit fehlenden Daten. Obwohlinvestor_cityAnwesendinvestor_state_codeUndinvestor_country_codeAuch fehlende Werte enthalten, sie überschritten den 75% igen Schwellenwert nicht und wurden für potenzielle zukünftige Erkenntnisse beibehalten.
Außerdem lassen wir die Spalten von Monat, Quartal und Jahr fallen, obwohl sie Daten haben. Dies folgt dem Programmierprinzip „Wiederholen Sie sich nicht“ (trocken). Da haben wir das volle Datum in funded_atWir können bei Bedarf Monat, Quartal oder Jahr später extrahieren. Dies spart uns erheblichem Speicher, ohne Informationen zu verlieren.
Identifizierung von Datentypoptimierungsmöglichkeiten
Überprüfen Sie, welche Spalten in effizientere Datentypen konvertiert werden können:
# Analyze knowledge varieties throughout chunks
col_types = {}
chunk_iter = pd.read_csv('crunchbase-investments.csv',
chunksize=5000,
encoding='Latin-1',
usecols=keep_cols)
for chunk in chunk_iter:
for col in chunk.columns:
if col not in col_types:
col_types(col) = (str(chunk.dtypes(col)))
else:
col_types(col).append(str(chunk.dtypes(col)))
# Get distinctive varieties per column
uniq_col_types = {}
for ok, v in col_types.gadgets():
uniq_col_types(ok) = set(col_types(ok))
print("Information varieties by column:")
for col, varieties in uniq_col_types.gadgets():
print(f"{col}: {varieties}")
Lassen Sie uns nun die eindeutigen Wertzahlen überprüfen, um kategoriale Kandidaten zu identifizieren:
unique_values = {}
chunk_iter = pd.read_csv('crunchbase-investments.csv',
chunksize=5000,
encoding='Latin-1',
usecols=keep_cols)
for chunk in chunk_iter:
for col in chunk.columns:
if col not in unique_values:
unique_values(col) = set()
unique_values(col).replace(chunk(col).distinctive())
print("Distinctive worth counts:")
for col, unique_vals in unique_values.gadgets():
print(f"{col}: {len(unique_vals)} distinctive values")
Distinctive worth counts:
company_name: 11574 distinctive values
company_category_code: 44 distinctive values
company_country_code: 3 distinctive values
company_state_code: 51 distinctive values
...
funding_round_type: 10 distinctive values
Lernerkenntnis: Jede Spalte mit weniger als 100 eindeutigen Werten ist ein guter Kandidat für die
classDatentyp. Kategorien sind unglaublich speichereffizient für wiederholte Zeichenfolgenwerte. Stellen Sie sich es wie ein Wörterbuch vor, das „USA“ 10.000 Mal speichert. Pandas speichert es einmal und verwendet eine Referenznummer.
Optimierungen anwenden
Laden wir unsere Daten mit allen angewandten Optimierungen:
Hinweis: Wir konvertieren funded_at zu einem datetime datentyp mit dem pd.read_csv Optionaler Parameter parse_dates
# Outline categorical columns
col_types = {
'company_category_code': 'class',
'funding_round_type': 'class',
'investor_state_code': 'class',
'investor_country_code': 'class'
}
# Load with optimizations
chunk_iter = pd.read_csv('crunchbase-investments.csv',
chunksize=5000,
encoding='Latin-1',
usecols=keep_cols,
dtype=col_types,
parse_dates=('funded_at'))
# Calculate new reminiscence utilization
counter = 0
series_memory_fp_after = pd.Collection(dtype='float64')
for chunk in chunk_iter:
if counter == 0:
series_memory_fp_after = chunk.memory_usage(deep=True)
else:
series_memory_fp_after += chunk.memory_usage(deep=True)
counter += 1
series_memory_fp_after = series_memory_fp_after.drop('Index')
total_memory_after = series_memory_fp_after.sum() / (1024 * 1024)
print(f"Reminiscence utilization earlier than optimization: 56.99 MB")
print(f"Reminiscence utilization after optimization: {total_memory_after:.2f} MB")
print(f"Discount: {((56.99 - total_memory_after) / 56.99 * 100):.1f}%")
Reminiscence utilization earlier than optimization: 56.99 MB
Reminiscence utilization after optimization: 26.84 MB
Discount: 52.9%
Wir haben unsere Gedächtnisnutzung um mehr als die Hälfte gesetzt!
Laden in SQLite
Laden wir nun unsere optimierten Daten in eine SQLite -Datenbank für eine effiziente Abfrage:
import sqlite3
# Create database connection
conn = sqlite3.join('crunchbase.db')
# Load knowledge in chunks and insert into database
chunk_iter = pd.read_csv('crunchbase-investments.csv',
chunksize=5000,
encoding='Latin-1',
usecols=keep_cols,
dtype=col_types,
parse_dates=('funded_at'))
for chunk in chunk_iter:
chunk.to_sql("investments", conn, if_exists='append', index=False)
# Confirm the desk was created
cursor = conn.cursor()
cursor.execute("SELECT title FROM sqlite_master WHERE kind='desk';")
tables = cursor.fetchall()
print(f"Tables in database: {(t(0) for t in tables)}")
# Preview the information
cursor.execute("SELECT * FROM investments LIMIT 5;")
print("nFirst 5 rows:")
for row in cursor.fetchall():
print(row)
Lerner Perception: SQLite ist perfekt für diesen Anwendungsfall, da wir uns, sobald sich unsere Daten in der Datenbank befinden, keine Sorgen mehr über Speicherbeschränkungen machen müssen. SQL -Abfragen sind unglaublich schnell und effizient, insbesondere für Aggregationsoperationen. Was komplexe PANDAS -Operationen mit Chunking erfordern würde, kann in einer einzelnen SQL -Abfrage durchgeführt werden.
Analyse der Daten
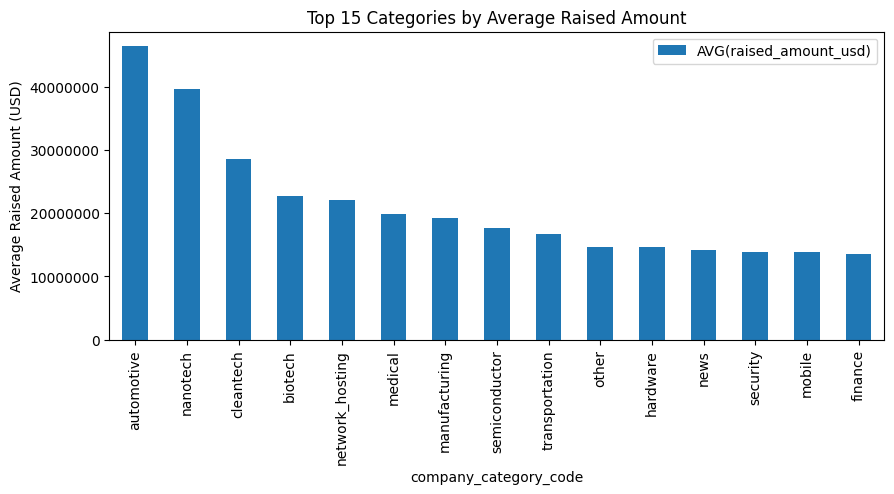
Beantworten wir eine Geschäftsfrage: Welche Unternehmenskategorien von Unternehmen ziehen durchschnittlich die meisten Investitionen an?
# Use pandas to learn SQL outcomes straight right into a DataFrame
question = """
SELECT company_category_code,
AVG(raised_amount_usd) as avg_raised
FROM investments
WHERE raised_amount_usd IS NOT NULL -- Exclude nulls for correct common
GROUP BY company_category_code
ORDER BY avg_raised DESC;
"""
df_results = pd.read_sql(question, conn)
# Visualize high 15 classes
top_n = 15
ax = df_results.head(top_n).set_index('company_category_code').plot(
sort='bar',
figsize=(10, 6),
title=f'High {top_n} Classes by Common Funding Quantity',
ylabel='Common Funding (USD)',
legend=False
)
# Format y-axis to point out precise numbers as an alternative of scientific notation
ax.ticklabel_format(model='plain', axis='y')
plt.tight_layout()
plt.present()
Wichtige Take -Aways und nächste Schritte
Durch dieses Projekt haben wir wichtige Techniken zum Umgang mit großen Datensätzen gelernt:
- Das Chunking verhindert Speicherfehler: Verarbeiten Sie Daten in überschaubaren Teilen, wenn der vollständige Datensatz den Speicher überschreitet
- Datentypoptimierung ist wichtig: Die Konvertierung in Kategorien und geeignete numerische Typen können den Speicher um 50% oder mehr reduzieren
- Entfernen Sie redundante Säulen: Speichern Sie nicht die gleichen Informationen auf verschiedene Arten
- SQLite ermöglicht eine schnelle Analyse: Einmal optimiert und geladen, komplexe Abfragen in Sekunden
- Codierungsprobleme sind häufig: Reale Daten sind oft nicht UTF-8; Kennen Sie Ihre Alternativen
Weitere Projekte zu versuchen
Wir haben einige andere Projekte zur Walkthrough -Tutorials, die Sie auch genießen können:
Hausaufgaben Herausforderungen
Um Ihr Verständnis zu vertiefen, erweitern Sie dieses Projekt mit:
- Weitere Optimierung: Kannst du konvertieren?
raised_amount_usdvon float64 bis float32 oder kleiner? Testen Sie, ob dies eine angemessene Präzision beibehält. - Erweiterte Analysefragen:
- Welchen Anteil der Gesamtfinanzierung erhielten die High 10% der Unternehmen?
- Welche Anleger haben insgesamt am meisten Geld beigetragen?
- Welche Finanzierungsrunden (Saatgut, Serie A usw.) sind am häufigsten?
- Gibt es saisonale Finanzierungsmuster? (Hinweis: Verwenden Sie die
funded_atSpalte)
- Datenqualität: Untersuchen Sie, warum der ursprüngliche CSV nicht UTF-8 ist codiert. Können und beheben Sie die problematischen Charaktere?
Persönliche Reflexion: Als jemand, der von der Unterrichtsmathematik zur Datenanalyse überging, erinnere ich mich, dass ich durch Gedächtnisfragen und Codierungsfehler eingeschüchtert wurde. Aber diese Herausforderungen haben mich gelehrt, dass reale Daten chaotisch sind, und das Lernen, diese Unordnung zu bewältigen, trennt gute Analysten von großen. Jede Optimierungstechnik, die Sie lernen, macht Sie in der Lage, größere und interessantere Datensätze zu bekämpfen.
Dieses Projekt zeigt, dass Sie mit den richtigen Techniken Datensätze analysieren können, die viel größer sind als Ihr verfügbarer Speicher. Unabhängig davon, ob Sie mit Startupdaten, Kundenaufzeichnungen oder Sensor -Lesungen arbeiten, werden Sie diese Optimierungsstrategien während Ihrer Datenkarriere intestine bedienen.
Wenn Sie neu in Pandas sind und die Chunking -Konzepte herausfordernd gefunden haben, beginnen Sie mit unserer Verarbeitung großer Datensätze in Pandas Kurs. Für diejenigen, die bereit sind, tiefer in Information Engineering einzutauchen, lesen Sie unsere Daten Engineering Weg.
Viel Spaß bei der Analyse!