
Bild von Autor | Leinwand
# Einführung
Traditionelles Debuggen mit print() Oder Protokollierung funktioniert, aber es ist langsam und klobig mit LLMs. Phoenix bietet eine Zeitleisteansicht aller Schritt-, Aufforderungs- und Antwortinspektion, Fehlererkennung mit Wiederholungen, Sichtbarkeit in Latenz und Kosten sowie ein vollständiges visuelles Verständnis Ihrer App. Phoenix von Arize AI ist ein leistungsstarkes Open-Supply-Beobachtungs- und -verfolgungswerkzeug, das speziell für LLM-Anwendungen entwickelt wurde. Es hilft Ihnen, alles in Ihren LLM -Pipelines visuell zu überwachen, zu debuggen und zu verfolgen. In diesem Artikel gehen wir durch das, was Phoenix tut und warum es wichtig ist, wie man Phoenix Schritt für Schritt in Langchain integriert und wie man Spuren in der UI von Phoenix visualisiert.
# Was ist Phoenix?
Phoenix ist ein Open-Supply-Beobachtbarkeits- und Debugging-Instrument für Großsprachmodellanwendungen. Es erfasst detaillierte Telemetriedaten aus Ihren LLM -Workflows, einschließlich Eingabeaufforderungen, Antworten, Latenz, Fehlern und Werkzeugen, und präsentiert diese Informationen in einem intuitiven interaktiven Dashboard. Mit Phoenix können Entwickler zutiefst verstehen, wie sich ihre LLM -Pipelines im System verhalten, Probleme mit schnellen Ausgaben identifizieren und debuggen, Leistungs Engpässe analysieren, mit Token und zugehörigen Kosten überwachen und alle Fehler/Wiederholungslogik während der Ausführungsphase verfolgen. Es unterstützt konsistente Integrationen mit beliebten Frameworks wie Langchain und Llamaindex und bietet auch OpenTelemetry -Unterstützung für maßgeschneiderte Setups.
# Schritt-für-Schritt-Setup
// 1. Installieren der erforderlichen Bibliotheken
Stellen Sie sicher, dass Sie Python 3.8+ haben und die Abhängigkeiten installieren:
pip set up arize-phoenix langchain langchain-together openinference-instrumentation-langchain langchain-community// 2. Starten Sie Phoenix
Fügen Sie diese Zeile hinzu, um das Phoenix -Dashboard zu starten:
import phoenix as px
px.launch_app()Dies startet ein lokales Armaturenbrett bei http: // localhost: 6006.
// 3.. Erstellen der Langchain -Pipeline mit Phoenix -Rückruf
Lassen Sie uns Phoenix anhand eines Anwendungsfalls verstehen. Wir bauen einen einfachen Langchain-Chatbot. Jetzt wollen wir:
- Debuggen, wenn die Eingabeaufforderung funktioniert
- Überwachen Sie, wie lange das Modell dauert, um zu reagieren
- Verfolgen Sie die Einlaufstruktur, die Modellverwendung und die Ausgänge
- Sehen Sie all dies visuell an, anstatt alles manuell zu protokollieren
// Schritt 1: Starten Sie das Phoenix -Dashboard im Hintergrund
import threading
import phoenix as px
# Launch Phoenix app regionally (entry at http://localhost:6006)
def run_phoenix():
px.launch_app()
threading.Thread(goal=run_phoenix, daemon=True).begin()// Schritt 2: Registrieren Sie Phoenix mit Opentelemetry & Instrument Langchain
from phoenix.otel import register
from openinference.instrumentation.langchain import LangChainInstrumentor
# Register OpenTelemetry tracer
tracer_provider = register()
# Instrument LangChain with Phoenix
LangChainInstrumentor().instrument(tracer_provider=tracer_provider)// Schritt 3: Initialisieren Sie die LLM (zusammen API)
from langchain_together import Collectively
llm = Collectively(
mannequin="meta-llama/Llama-3-8b-chat-hf",
temperature=0.7,
max_tokens=256,
together_api_key="your-api-key", # Change along with your precise API key
)Bitte vergessen Sie nicht, den „Your-api-Key“ durch Ihren tatsächlichen zusammen.ai-API-Schlüssel zu ersetzen. Sie können es mit diesem erhalten Hyperlink.
// Schritt 4: Definieren Sie die Eingabeaufforderung Vorlage
from langchain.prompts import ChatPromptTemplate
immediate = ChatPromptTemplate.from_messages((
("system", "You're a useful assistant."),
("human", "{query}"),
))// Schritt 5: Kombinieren Sie Eingabeaufforderung und Modell in eine Kette
// Schritt 6: Stellen Sie mehrere Fragen und drucken Antworten
questions = (
"What's the capital of France?",
"Who found gravity?",
"Give me a motivational quote about perseverance.",
"Clarify photosynthesis in a single sentence.",
"What's the pace of sunshine?",
)
print("Phoenix working at http://localhost:6006n")
for q in questions:
print(f" Query: {q}")
response = chain.invoke({"query": q})
print(" Reply:", response, "n")// Schritt 7: Halten Sie die App für die Überwachung am Leben
strive:
whereas True:
go
besides KeyboardInterrupt:
print(" Exiting.")# Verständnis von Phoenix -Spuren und Metriken
Bevor wir die Ausgabe sehen, sollten wir zuerst Phoenix -Metriken verstehen. Sie müssen zuerst verstehen, welche Spuren und Spans sind:
Verfolgen: Jede Spur stellt einen vollständigen Lauf Ihrer LLM -Pipeline dar. Zum Beispiel wie jede Frage wie „Was ist die Hauptstadt Frankreichs?“ erzeugt eine neue Spur.
Spannweiten: Jede Spur ist von mehreren Spannweiten gemischt, die jeweils eine Stufe in Ihrer Kette darstellen:
- ChatpromptTemplate.Format: Eingabeaufforderung Formatierung
- Togetherll.invoke: LLM Name
- Alle benutzerdefinierten Komponenten, die Sie hinzufügen
Metriken professional Spur gezeigt
| Metrisch | Bedeutung & Wichtigkeit |
|---|---|
| Latenz (MS) |
Misst die Gesamtzeit für die vollständige LLM-Kettenausführung, einschließlich formeller Formatierung, LLM-Antwort und Nachbearbeitung. Hilft bei der Identifizierung von Leistungsengpassungen und Debugugs langsamer Antworten. |
| Eingangs -Token |
Anzahl der an das Modell gesendeten Token. Wichtig für die Überwachung der Eingangsgröße und zur Kontrolle der API-Kosten, da die meisten Nutzungen auf Token basieren. |
| Ausgangstoken |
Anzahl der vom Modell generierten Token. Nützlich zum Verständnis von Ausführlichkeit, Reaktionsqualität und Kostenauswirkungen. |
| Schnellvorlage |
Zeigt die vollständige Eingabeaufforderung mit eingefügten Variablen an. Hilft zu bestätigen, ob die Eingabeaufforderungen strukturiert und korrekt ausgefüllt sind. |
| Eingangs- / Ausgabetext |
Zeigt sowohl die Benutzereingabe als auch die Antwort des Modells an. Nützlich zur Überprüfung der Interaktionsqualität und zum Erkennen von Halluzinationen oder falschen Antworten. |
| Spannweiten |
Verbreitet die Zeit, die von jedem Schritt benötigt wird (z. B. sofortige Erstellung oder Modellaufruf). Hilft bei der Identifizierung von Leistungs Engpässen in der Kette. |
| Kettenname |
Gibt an, zu welchem Teil der Pipeline eine Spannweite gehört (z. B., z. B. |
| Tags / Metadaten |
Zusätzliche Informationen wie Modellname, Temperatur usw. Nützlich für die Filterung, den Vergleich der Ergebnisse und die Analyse der Parameteraufprall. |
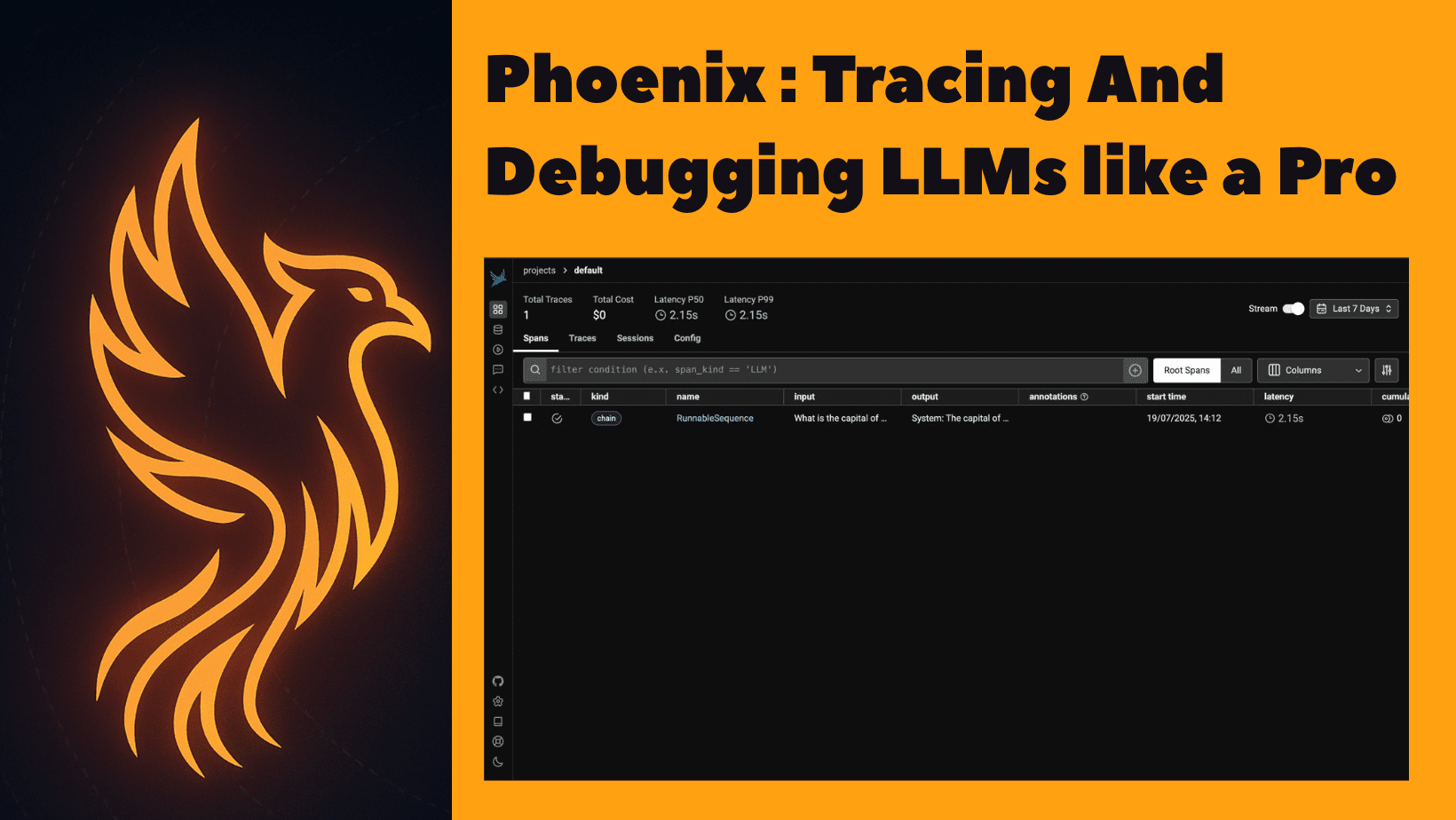
Jetzt besuchen Sie http: // localhost: 6006 Um das Phoenix -Dashboard anzuzeigen. Sie werden so etwas sehen wie:

Öffnen Sie die erste Spur, um seine Particulars anzuzeigen.

# Einpacken
Um es abzuschließen, macht es Arize Phoenix unglaublich einfach, Ihre LLM -Anwendungen zu debuggen, zu verfolgen und zu überwachen. Sie müssen nicht erraten, was schief gelaufen ist oder durch Protokolle graben. Alles ist genau richtig: Aufforderungen, Antworten, Timings und mehr. Es hilft Ihnen, Probleme zu erkennen, die Leistung zu verstehen und einfach bessere KI -Erlebnisse mit viel weniger Stress aufzubauen.
Kanwal Mehreen ist ein Ingenieur für maschinelles Lernen und technischer Schriftsteller mit einer tiefgreifenden Leidenschaft für die Datenwissenschaft und die Schnittstelle von KI mit Medizin. Sie hat das eBook „Produktivität mit Chatgpt maximieren“. Als Google -Era -Gelehrte 2022 für APAC setzt sie sich für Vielfalt und akademische Exzellenz ein. Sie wird auch als Teradata -Vielfalt in Tech Scholar, MITACS Globalink Analysis Scholar und Harvard Wecode Scholar anerkannt. Kanwal ist ein leidenschaftlicher Verfechter der Veränderung, nachdem er Femcodes gegründet hat, um Frauen in STEM -Bereichen zu stärken.