

Bild vom Autor
# Einführung
Es scheint, als ob quick jede Woche ein neues Modell behauptet, auf dem neuesten Stand der Technik zu sein und bestehende KI-Modelle in allen Benchmarks übertrifft.
Ich erhalte bei meinem Vollzeitjob innerhalb weniger Wochen nach der Veröffentlichung kostenlosen Zugang zu den neuesten KI-Modellen. Normalerweise schenke ich dem Hype keine große Beachtung und verwende einfach das Modell, das vom System automatisch ausgewählt wird.
Ich kenne jedoch Entwickler und Freunde, die Software program mit KI erstellen möchten, die in die Produktion überführt werden kann. Da diese Initiativen aus eigenen Mitteln finanziert werden, besteht ihre Herausforderung darin, das beste Modell für die Aufgabe zu finden. Sie wollen Kosten und Zuverlässigkeit in Einklang bringen.
Aus diesem Grund beschloss ich nach der Veröffentlichung von GPT-5.2, einen Praxistest durchzuführen, um herauszufinden, ob dieses Modell den Hype wert struggle und ob es wirklich besser als die Konkurrenz struggle.
Konkret habe ich mich entschieden, die Flaggschiff-Modelle der einzelnen Anbieter zu testen: Claude Opus 4.5 (Anthropics leistungsfähigstes Modell), GPT-5.2 Professional (Das neueste erweiterte Argumentationsmodell von OpenAI) und DeepSeek V3.2 (eine der neuesten Open-Supply-Alternativen).
Um diese Modelle auf die Probe zu stellen, habe ich beschlossen, sie mit einer einzigen Eingabeaufforderung ein spielbares Tetris-Spiel erstellen zu lassen.
Dies waren die Kennzahlen, anhand derer ich den Erfolg jedes Modells bewertete:
| Kriterien | Beschreibung |
|---|---|
| Erster Versuch erfolgreich | Hat das Modell mit nur einer Eingabeaufforderung funktionierenden Code geliefert? Mehrere Debug-Iterationen führen mit der Zeit zu höheren Kosten, weshalb diese Metrik gewählt wurde. |
| Vollständigkeit der Funktionen | Wurden alle in der Eingabeaufforderung erwähnten Funktionen vom Modell eingebaut oder wurde etwas übersehen? |
| Spielbarkeit | Conflict das Spiel über die technische Umsetzung hinaus tatsächlich flüssig zu spielen? Oder gab es Probleme, die zu Reibungsverlusten bei der Benutzererfahrung führten? |
| Kosteneffizienz | Wie viel hat es gekostet, produktionsreifen Code zu erhalten? |
# Die Aufforderung
Hier ist die Eingabeaufforderung, die ich in jedes KI-Modell eingegeben habe:
Erstellen Sie ein voll funktionsfähiges Tetris-Spiel als einzelne HTML-Datei, die ich direkt in meinem Browser öffnen kann.
Anforderungen:
SPIELMECHANIK:
– Alle 7 Tetris-Teiletypen
– Reibungslose Rotation der Teile mit Kollisionserkennung gegen Wandstöße
– Die Teile sollten automatisch fallen. Die Geschwindigkeit wird schrittweise erhöht, wenn die Punktzahl des Benutzers steigt
– Linienräumung mit visueller Animation
– Vorschaufeld „Nächstes Stück“.
– Sport-Over-Erkennung, wenn Teile die Spitze erreichenSTEUERUNG:
– Pfeiltasten: Nach hyperlinks/rechts zum Bewegen, nach unten zum schnelleren Absinken, nach oben zum Drehen
– Contact-Steuerung für Mobilgeräte: Zum Bewegen nach hyperlinks/rechts wischen, zum Ablegen nach unten wischen, zum Drehen tippen
– Leertaste zum Anhalten/Aufheben der Pause
– Geben Sie die Style ein, um nach dem Ende des Spiels neu zu startenVISUELLES DESIGN:
– Verlaufsfarben für jeden Stücktyp
– Reibungslose Animationen, wenn sich Teile bewegen und Linien klar werden
– Saubere Benutzeroberfläche mit abgerundeten Ecken
– Aktualisieren Sie die Ergebnisse in Echtzeit
– Füllstandsanzeige
– Sport-Over-Bildschirm mit Endergebnis und Neustart-StyleGAMEPLAY-ERFAHRUNG UND POLNISCH:
– Reibungsloses 60-fps-Gameplay
– Partikeleffekte beim Löschen von Linien (non-obligatory, aber beeindruckend)
– Erhöhen Sie die Punktzahl basierend auf der Anzahl der gleichzeitig gelöschten Zeilen
– Rasterhintergrund
– Responsives DesignMachen Sie es optisch aufpoliert und sorgen Sie für ein angenehmes Spielerlebnis. Der Code sollte sauber und intestine organisiert sein.
# Die Ergebnisse
// 1. Claude Opus 4.5
Das Opus 4.5-Modell hat genau das gebaut, was ich verlangt habe.
Die Benutzeroberfläche struggle sauber und die Anweisungen wurden deutlich auf dem Bildschirm angezeigt. Alle Steuerelemente reagierten und das Spiel machte Spaß.
Das Gameplay verlief so reibungslos, dass ich tatsächlich eine ganze Weile spielte und vom Testen der anderen Modelle abgelenkt wurde.
Außerdem benötigte Opus 4.5 weniger als 2 Minuten, um mir dieses funktionierende Spiel zur Verfügung zu stellen, was mich beim ersten Versuch beeindruckte.
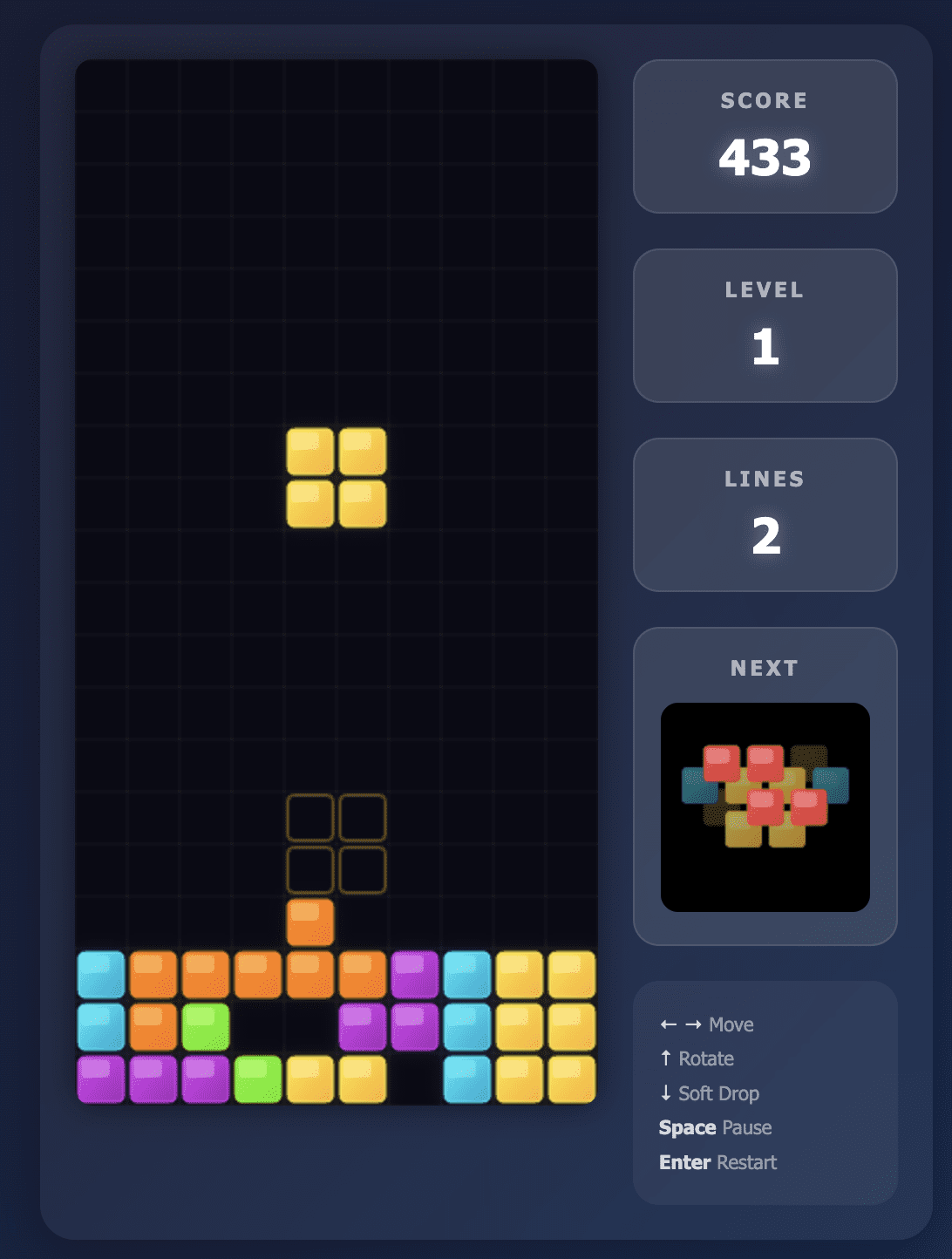
Tetris-Spiel, erstellt von Opus 4.5
// 2. GPT-5.2 Professional
GPT-5.2 Professional ist das neueste Modell von OpenAI mit erweiterter Argumentation. Zum Kontext verfügt GPT-5.2 über drei Ebenen: Prompt, Pondering und Professional. Zum Zeitpunkt des Schreibens dieses Artikels ist GPT-5.2 Professional das intelligenteste Modell und bietet erweiterte Denk- und Argumentationsfunktionen.
Es ist außerdem 4x teurer als Opus 4.5.
Es gab einen großen Hype um dieses Modell, was dazu führte, dass ich hohe Erwartungen hatte.
Leider struggle ich von dem Spiel, das dieses Modell hervorgebracht hat, nicht begeistert.
Beim ersten Versuch produzierte GPT-5.2 Professional ein Tetris-Spiel mit einem Layoutfehler. Die unteren Reihen des Spiels befanden sich außerhalb des Ansichtsfensters und ich konnte nicht sehen, wo die Figuren landeten.
Dadurch wurde das Spiel unspielbar, wie im Screenshot unten gezeigt:
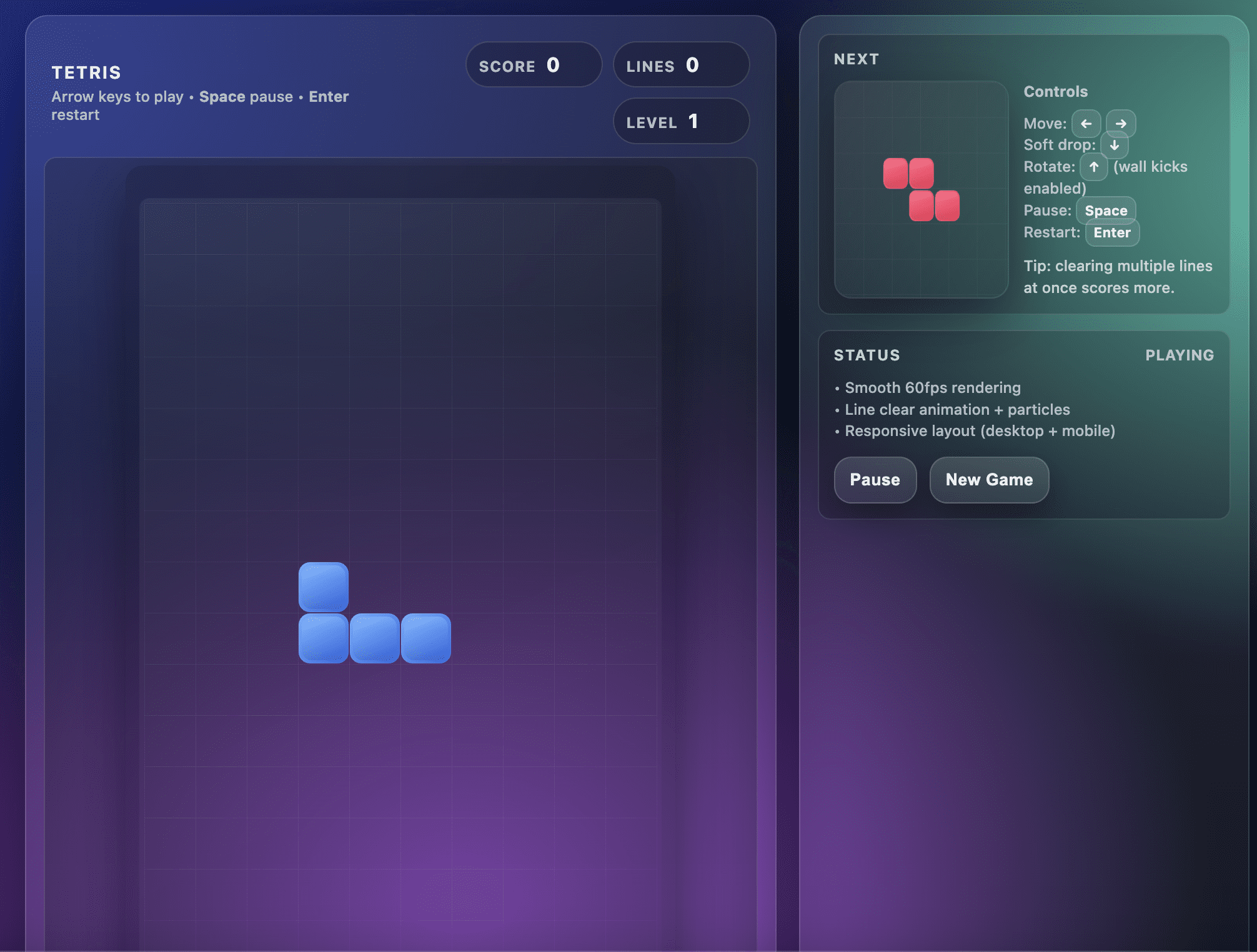
Tetris-Spiel, erstellt von GPT-5.2
Dieser Fehler hat mich besonders überrascht, da das Modell etwa 6 Minuten brauchte, um diesen Code zu erzeugen.
Ich beschloss, es mit dieser Folgeaufforderung noch einmal zu versuchen, um das Downside mit dem Ansichtsfenster zu beheben:
Das Spiel funktioniert, aber es gibt einen Fehler. Die unteren Reihen des Tetris-Bretts werden am unteren Bildschirmrand abgeschnitten. Ich kann die Teile nicht sehen, wenn sie landen und die Leinwand über das sichtbare Ansichtsfenster hinausragt.
Bitte beheben Sie das Downside durch:
1. Stellen Sie sicher, dass das gesamte Spielbrett in das Ansichtsfenster passt
2. Richtige Zentrierung hinzufügen, damit die gesamte Platine sichtbar istDas Spiel sollte auf den Bildschirm passen und alle Zeilen sichtbar sein.
Nach der Folgeaufforderung produzierte das GPT-5.2 Professional-Modell ein funktionsfähiges Spiel, wie im folgenden Screenshot zu sehen ist:

Tetris zweiter Versuch von GPT-5.2
Allerdings struggle das Spiel nicht so flüssig wie beim Opus 4.5-Modell.
Wenn ich den „Abwärts“-Pfeil drückte, um das Teil fallen zu lassen, stürzte das nächste Teil manchmal sofort mit hoher Geschwindigkeit ab, sodass ich nicht genug Zeit hatte, darüber nachzudenken, wie ich es positionieren sollte.
Das Spiel struggle letztendlich nur spielbar, wenn ich jedes Teil einzeln fallen ließ, was nicht das beste Erlebnis struggle.
(Hinweis: Ich habe auch das GPT-5.2-Standardmodell ausprobiert, das beim ersten Versuch einen ähnlichen fehlerhaften Code erzeugte.)
// 3. DeepSeek V3.2
DeepSeeks erster Versuch, dieses Spiel zu entwickeln, hatte zwei Probleme:
- Die Teile begannen zu verschwinden, als sie den unteren Bildschirmrand erreichten.
- Der „Abwärts“-Pfeil, der zum schnelleren Ablegen der Spielsteine verwendet wird, führte letztendlich dazu, dass die gesamte Webseite gescrollt wurde, anstatt nur die Spielsteine zu verschieben.
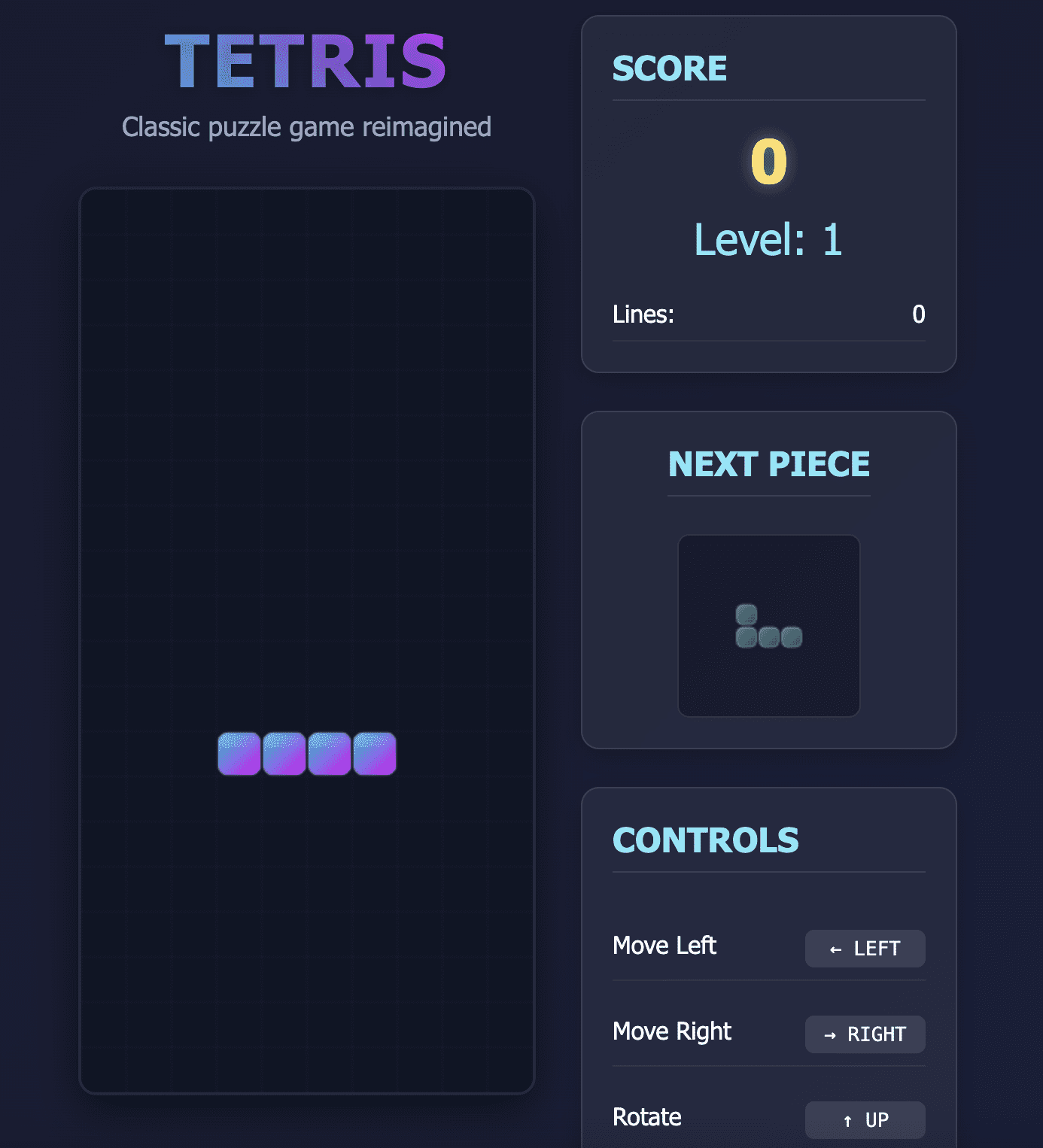
Tetris-Spiel, erstellt von DeepSeek V3.2
Ich habe das Modell erneut aufgefordert, dieses Downside zu beheben, und die Spielsteuerung funktionierte schließlich ordnungsgemäß.
Einige Teile verschwanden jedoch noch vor ihrer Landung. Dies machte das Spiel auch nach der zweiten Iteration völlig unspielbar.
Ich bin sicher, dass dieses Downside mit zwei bis drei weiteren Eingabeaufforderungen behoben werden kann, und angesichts der niedrigen Preise von DeepSeek könnten Sie sich mehr als 10 Debugging-Runden leisten und trotzdem weniger als einen erfolgreichen Opus 4.5-Versuch ausgeben.
# Zusammenfassung: GPT-5.2 vs. Opus 4.5 vs. DeepSeek 3.2
// Kostenaufschlüsselung
Hier ein Kostenvergleich zwischen den drei Modellen:
| Modell | Eingabe (professional 1 Mio. Token) | Ausgabe (professional 1 Mio. Token) |
|---|---|---|
| DeepSeek V3.2 | 0,27 $ | 1,10 $ |
| GPT-5.2 | 1,75 $ | 14,00 $ |
| Claude Opus 4.5 | 5,00 $ | 25,00 $ |
| GPT-5.2 Professional | 21,00 $ | 84,00 $ |
DeepSeek V3.2 ist die günstigste Different, Sie können die Gewichte des Modells auch kostenlos herunterladen und auf Ihrer eigenen Infrastruktur ausführen.
GPT-5.2 ist quick siebenmal teurer als DeepSeek V3.2, gefolgt von Opus 4.5 und GPT-5.2 Professional.
Für diese spezielle Aufgabe (Erstellung eines Tetris-Spiels) haben wir etwa 1.000 Eingabe-Tokens und 3.500 Ausgabe-Tokens verbraucht.
Für jede weitere Iteration schätzen wir 1.500 zusätzliche Token professional zusätzlicher Runde. Hier sind die Gesamtkosten, die professional Modell anfallen:
| Modell | Gesamtkosten | Ergebnis |
|---|---|---|
| DeepSeek V3.2 | ~0,005 $ | Das Spiel ist nicht spielbar |
| GPT-5.2 | ~0,07 $ | Spielbar, aber schlechte Benutzererfahrung |
| Claude Opus 4.5 | ~0,09 $ | Spielbar und gute Benutzererfahrung |
| GPT-5.2 Professional | ~0,41 $ | Spielbar, aber schlechte Benutzererfahrung |
# Imbissbuden
Basierend auf meiner Erfahrung beim Aufbau dieses Spiels, Für alltägliche Codierungsaufgaben würde ich beim Opus 4.5-Modell bleiben.
Obwohl GPT-5.2 günstiger als Opus 4.5 ist, würde ich es persönlich nicht zum Codieren verwenden, da die Iterationen, die erforderlich sind, um das gleiche Ergebnis zu erzielen, wahrscheinlich zu demselben Geldaufwand führen würden.
DeepSeek V3.2 ist jedoch weitaus günstiger als die anderen Modelle auf dieser Liste.
Wenn Sie ein Entwickler mit begrenztem Finances sind und Zeit für das Debuggen übrig haben, sparen Sie am Ende trotzdem Geld, selbst wenn Sie mehr als 10 Versuche brauchen, um funktionierenden Code zu erhalten.
Ich struggle überrascht, dass GPT 5.2 Professional beim ersten Versuch kein funktionierendes Spiel erstellen konnte, da es etwa 6 Minuten zum Nachdenken brauchte, bevor man auf den fehlerhaften Code kam. Schließlich ist dies das Flaggschiffmodell von OpenAI, und Tetris sollte eine relativ einfache Aufgabe sein.
Die Stärken von GPT-5.2 Professional liegen jedoch in der mathematischen und wissenschaftlichen Forschung und es ist speziell für Probleme konzipiert, die nicht auf der Mustererkennung aus Trainingsdaten beruhen. Möglicherweise ist dieses Modell für einfache, alltägliche Codierungsaufgaben überentwickelt und sollte stattdessen verwendet werden, wenn etwas Komplexes erstellt wird, das eine neuartige Architektur erfordert.
Die praktische Erkenntnis aus diesem Experiment:
- Opus 4.5 schneidet bei alltäglichen Codierungsaufgaben am besten ab.
- DeepSeek V3.2 ist eine preisgünstige Different, die eine angemessene Ausgabe liefert, obwohl einige Debugging-Aufwände erforderlich sind, um das gewünschte Ergebnis zu erzielen.
- GPT-5.2 (Commonplace) schnitt nicht so intestine ab wie Opus 4.5, wohingegen GPT-5.2 (Professional) wahrscheinlich besser für komplexe Überlegungen geeignet ist als schnelle Codierungsaufgaben wie diese.
Fühlen Sie sich frei, diesen Check mit der Aufforderung, die ich oben geteilt habe, zu wiederholen, und viel Spaß beim Codieren!
 
 
Natassha Selvaraj ist ein autodidaktischer Datenwissenschaftler mit einer Leidenschaft für das Schreiben. Natassha schreibt über alles, was mit Datenwissenschaft zu tun hat, eine wahre Meisterin aller Datenthemen. Sie können sich mit ihr verbinden LinkedIn oder schau sie dir an YouTube-Kanal.