dass lineare Modelle … nun ja, steif sein können. Haben Sie sich jemals ein Streudiagramm angesehen und festgestellt, dass eine gerade Linie einfach nicht ausreicht? Wir waren alle dort.
Daten aus der realen Welt sind immer eine Herausforderung. Meistens hat man das Gefühl, dass die Ausnahme die Regel ist. Die Daten, die Sie in Ihrem Job erhalten, haben nichts mit den wunderschönen linearen Datensätzen zu tun, die wir während unserer jahrelangen Ausbildung an der Akademie verwendet haben.
Sie betrachten beispielsweise etwas wie „Energiebedarf vs. Temperatur“. Es ist keine Linie; es ist eine Kurve. Normalerweise besteht unser erster Instinkt darin, zur polynomialen Regression zu greifen. Aber das ist eine Falle!
Wenn Sie jemals gesehen haben, wie eine Modellkurve an den Rändern Ihres Diagramms wild wird, sind Sie Zeuge des „Runge-Phänomen.„Hochgradige Polynome sind wie ein Kleinkind mit einem Buntstift, da sie zu flexibel sind und keine Disziplin haben.
Deshalb zeige ich Ihnen diese Possibility namens Splines. Sie sind eine nette Lösung: flexibler als eine Linie, aber weitaus disziplinierter als ein Polynom.
Splines sind mathematische Funktionen, die durch Polynome definiert werden und zum Glätten einer Kurve verwendet werden.
Anstatt zu versuchen, eine komplexe Gleichung an Ihren gesamten Datensatz anzupassen, unterteilen Sie die Daten an den aufgerufenen Punkten in Segmente Knoten. Jedes Phase erhält sein eigenes einfaches Polynom und alle sind so glatt zusammengefügt, dass man nicht einmal die Nähte sehen kann.
Das Drawback mit Polynomen
Stellen Sie sich vor, wir haben einen nichtlinearen Development und wenden ein Polynom an x² oder x³ dazu. Vor Ort sieht es in Ordnung aus, aber wenn wir uns die Ränder Ihrer Daten ansehen, stellt sich heraus, dass die Kurve weit daneben verläuft. Entsprechend Runges Phänomen (2), Bei Polynomen höheren Grades besteht das Drawback, dass ein seltsamer Datenpunkt an einem Ende die gesamte Kurve am anderen Ende aus dem Gleichgewicht bringen kann.

Warum Splines die „genau richtige“ Wahl sind
Splines versuchen nicht, eine riesige Gleichung an alles anzupassen. Stattdessen unterteilen sie Ihre Daten mithilfe sogenannter Punkte in Segmente Knoten. Wir haben einige Vorteile der Verwendung von Knoten.
- Lokale Steuerung: Was in einem Phase passiert, bleibt in diesem Phase. Da diese Blöcke lokal sind, beeinträchtigt ein seltsamer Datenpunkt an einem Ende Ihres Diagramms nicht die Anpassung am anderen Ende.
- Glätte: Sie verwenden „B-Splines“ (Foundation-Splines), um sicherzustellen, dass die Kurve dort, wo sich die Segmente treffen, vollkommen glatt ist.
- Stabilität: Im Gegensatz zu Polynomen geraten sie an den Grenzen nicht ins Wanken.
OK. Genug geredet, jetzt implementieren wir diese Lösung.
Umsetzung mit Scikit-Study
Scikit-Learns SplineTransformer ist hierfür die erste Wahl. Es verwandelt ein einzelnes numerisches Merkmal in mehrere Grundfunktionen mit deren Hilfe ein einfaches lineares Modell dann komplexe, nichtlineare Formen lernen kann.
Lassen Sie uns einige Module importieren.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import SplineTransformer
from sklearn.linear_model import Ridge
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import GridSearchCVAls nächstes erstellen wir einige gekrümmte oszillierende Daten.
# 1. Create some 'wiggly' artificial knowledge (e.g., seasonal gross sales)
rng = np.random.RandomState(42)
X = np.type(rng.rand(100, 1) * 10, axis=0)
y = np.sin(X).ravel() + rng.regular(0, 0.1, X.form(0))
# Plot the information
plt.determine(figsize=(12, 5))
plt.scatter(X, y, colour='grey', alpha=0.5, label='Information')
plt.legend()
plt.title("Information")
plt.present()
OK. Jetzt erstellen wir eine Pipeline, die das ausführt SplineTranformer mit den Standardeinstellungen, gefolgt von einer Ridge-Regression.
# 2. Construct a pipeline: Splines + Linear Mannequin
# n_knots=5 (default) creates 4 segments; diploma=3 makes it a cubic spline
mannequin = make_pipeline(
SplineTransformer(n_knots=5, diploma=3),
Ridge(alpha=0.1)
)Als nächstes werden wir die Anzahl der Knoten für unser Modell anpassen. Wir verwenden GridSearchCV um mehrere Versionen des Modells auszuführen und verschiedene Knotenzahlen zu testen, bis diejenige gefunden wird, die auf unseren Daten am besten abschneidet.
# We tune 'n_knots' to search out the very best tune
param_grid = {'splinetransformer__n_knots': vary(3, 12)}
grid = GridSearchCV(mannequin, param_grid, cv=5)
grid.match(X, y)
print(f"Greatest knot depend: {grid.best_params_('splinetransformer__n_knots')}")Greatest knot depend: 8Dann trainieren wir unser Spline-Modell mit dem neu beste Knotenzahl, Vorhersagen und Plotten der Daten. Lassen Sie uns mit dieser kurzen Aufschlüsselung auch verstehen, was wir hier tun SplineTransformer Klassenargumente:
n_knots: Anzahl der Gelenke in der Kurve. Je mehr Sie haben, desto flexibler wird die Kurve.diploma: Dies definiert die „Glätte“ der Segmente. Es bezieht sich auf den Grad des Polynoms, das zwischen Knoten verwendet wird (1 ist eine Linie; 2 ist glatter; 3 ist die Standardeinstellung).knots: Das sagt man dem Modell Wo um die Gelenke zu platzieren. Zum Beispiel,uniformunterteilt die Kurve in gleiche Räume, während das Quantil dort mehr Knoten zuweist, wo die Daten dichter sind.- Tipp: Verwenden
'quantile'wenn Ihre Daten geclustert sind.
- Tipp: Verwenden
extrapolation: Teilt dem Modell mit, was es tun soll, wenn es auf Daten trifft draußen die Reichweite, die es während des Trainings gesehen hat.- Tipp: verwenden
'periodic'für zyklische Daten wie Kalender oder Uhr.
- Tipp: verwenden
include_bias: Ob eine „Bias“-Spalte (eine Spalte mit allen Einsen) eingefügt werden soll. Wenn Sie a verwendenLinearRegressionoderRidgeWenn Sie später in Ihrer Pipeline ein Modell erstellen möchten, verfügen diese Modelle normalerweise über ein eigenes Modellfit_intercept=Truesodass Sie dies oft auf einstellen könnenFalseRedundanz zu vermeiden.
# 2. Construct the optimized Spline
mannequin = make_pipeline(
SplineTransformer(n_knots=8,
diploma=3,
knots= 'uniform',
extrapolation='fixed',
include_bias=False),
Ridge(alpha=0.1)
).match(X, y)
# 3. Predict and Visualize
y_plot = mannequin.predict(X)
# Plot
plt.determine(figsize=(12, 5))
plt.scatter(X, y, colour='grey', alpha=0.5, label='Information')
plt.plot(X, y_plot, colour='teal', linewidth=3, label='Spline Mannequin')
plt.plot(X, y_plot_10, colour='purple', linewidth=2, label='Polynomial Match (Diploma 20)')
plt.legend()
plt.title("Splines: Versatile but Disciplined")
plt.present()Hier ist das Ergebnis. Mit Splines haben wir eine bessere Kontrolle und ein glatteres Modell, wodurch das Drawback an den Enden umgangen wird.
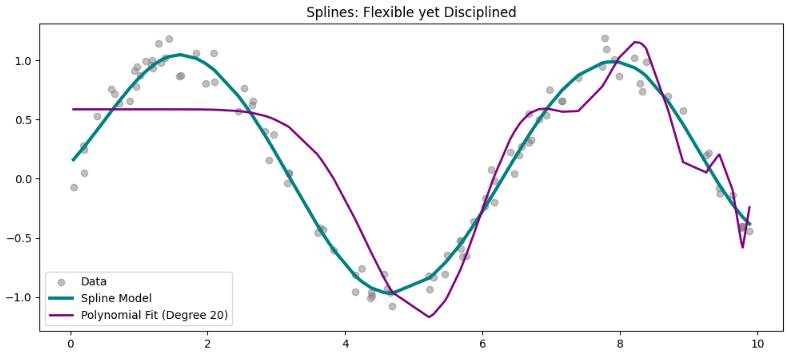
Wir vergleichen ein Polynommodell von diploma=20 mit dem Spline-Modell. Man kann argumentieren, dass niedrigere Grade eine viel bessere Modellierung dieser Daten ermöglichen, und sie wären richtig. Ich habe bis zum 13. Grad getestet und es passt intestine zu diesem Datensatz.
Doch genau darum geht es in diesem Artikel. Wenn das Modell nicht so intestine zu den Daten passt und wir den Grad des Polynoms weiter erhöhen müssen, werden wir mit Sicherheit in die State of affairs geraten wilde Kanten Drawback.
Anwendungen aus dem wirklichen Leben
Wo würden Sie das eigentlich geschäftlich nutzen?
- Zeitreihenzyklen: Verwenden
extrapolation='periodic'für Merkmale wie „Tagesstunde“ oder „Monat des Jahres“. Dadurch wird sichergestellt, dass das Modell weiß, dass 23:59 Uhr direkt neben 00:01 Uhr liegt. Mit diesem Argument sagen wir dasSplineTransformerdass sich das Ende unseres Zyklus (Stunde 23) umschließen und auf den Anfang (Stunde 0) treffen sollte. Somit stellt der Spline sicher, dass Steigung und Wert am Ende des Tages perfekt mit dem Beginn des nächsten Tages übereinstimmen. - Dosis-Wirkungs-Verhältnis in der Medizin: Modellieren, wie sich ein Medikament auf einen Patienten auswirkt. Die meisten Medikamente folgen einer nichtlinearen Kurve, bei der sich der Nutzen schließlich einpendelt (Sättigung) oder, schlimmer noch, in Toxizität umschlägt. Splines sind hier der „Goldstandard“, da sie diese komplexen biologischen Veränderungen abbilden können, ohne die Daten in eine starre Kind zu zwingen.
- Einkommen vs. Erfahrung: Das Gehalt steigt oft früh schnell an und erreicht dann ein Plateau; Splines erfassen diese „Kurve“ perfekt.
Bevor Sie gehen
Wir haben hier viel besprochen, von der Frage, warum Polynome eine „wilde“ Wahl sein können, bis hin zur Frage, wie periodische Splines die Mitternachtslücke lösen. Hier ist eine kurze Zusammenfassung, die Sie in Ihrer Gesäßtasche aufbewahren sollten:
- Die goldene Regel: Verwenden Sie Splines, wenn eine gerade Linie zu einfach ist, ein Polynom höheren Grades jedoch zu oszillieren und zu überpassen beginnt.
- Knoten sind der Schlüssel: Knoten sind die „Gelenke“ Ihres Modells. Die richtige Nummer finden über
GridSearchCVist der Unterschied zwischen einer glatten Kurve und einem gezackten Durcheinander. - Periodische Leistung: Für jede Funktion, die zyklisch läuft (Stunden, Tage, Monate), verwenden Sie
extrapolation='periodic'. Dadurch wird sichergestellt, dass das Modell versteht, dass das Ende des Zyklus perfekt in den Anfang übergeht. - Characteristic Engineering > Komplexe Modelle: Oftmals ein einfaches
RidgeRegression kombiniert mitSplineTransformerübertrifft ein komplexes „Black-Field“-Modell und bleibt Ihrem Chef viel einfacher zu erklären.
Wenn Ihnen dieser Inhalt gefallen hat, finden Sie auf meiner Web site mehr über meine Arbeit und meine Kontakte.
GitHub-Repository
Hier ist der vollständige Code dieser Übung und ein paar Extras.
https://github.com/gurezende/Finding out/blob/grasp/Python/sklearn/SplineTransformer.ipynb
Referenzen
(1. SplineTransformer-Dokumentation) https://scikit-learn.org/steady/modules/generated/sklearn.preprocessing.SplineTransformer.html
(2. Runges Phänomen) https://en.wikipedia.org/wiki/Rungepercent27s_phenomenon
(3. Pipeline-Dokumente erstellen) https://scikit-learn.org/steady/modules/generated/sklearn.pipeline.make_pipeline.html