Gestern haben wir mit gearbeitet Isolationswaldeine Methode zur Anomalieerkennung.
Heute schauen wir uns einen anderen Algorithmus an, der das gleiche Ziel hat. Aber im Gegensatz zu Isolation Forest ist dies der Fall nicht Bäume bauen.
Er wird LOF oder Native Outlier Issue genannt.
Menschen fassen LOF oft mit einem Satz zusammen: Liegt dieser Punkt in einer Area mit einer geringeren Dichte als seine Nachbarn?
Dieser Satz ist tatsächlich schwierig zu verstehen. Ich habe lange damit gekämpft.
Es gibt jedoch einen Teil, der sofort leicht zu verstehen ist:
und wir werden sehen, dass es zum entscheidenden Punkt wird:
Es gibt eine Vorstellung von Nachbarn.
Und sobald wir über Nachbarn reden,
Wir kehren natürlich zu zurück Distanzbasierte Modelle.
Wir erklären diesen Algorithmus in 3 Schritten.
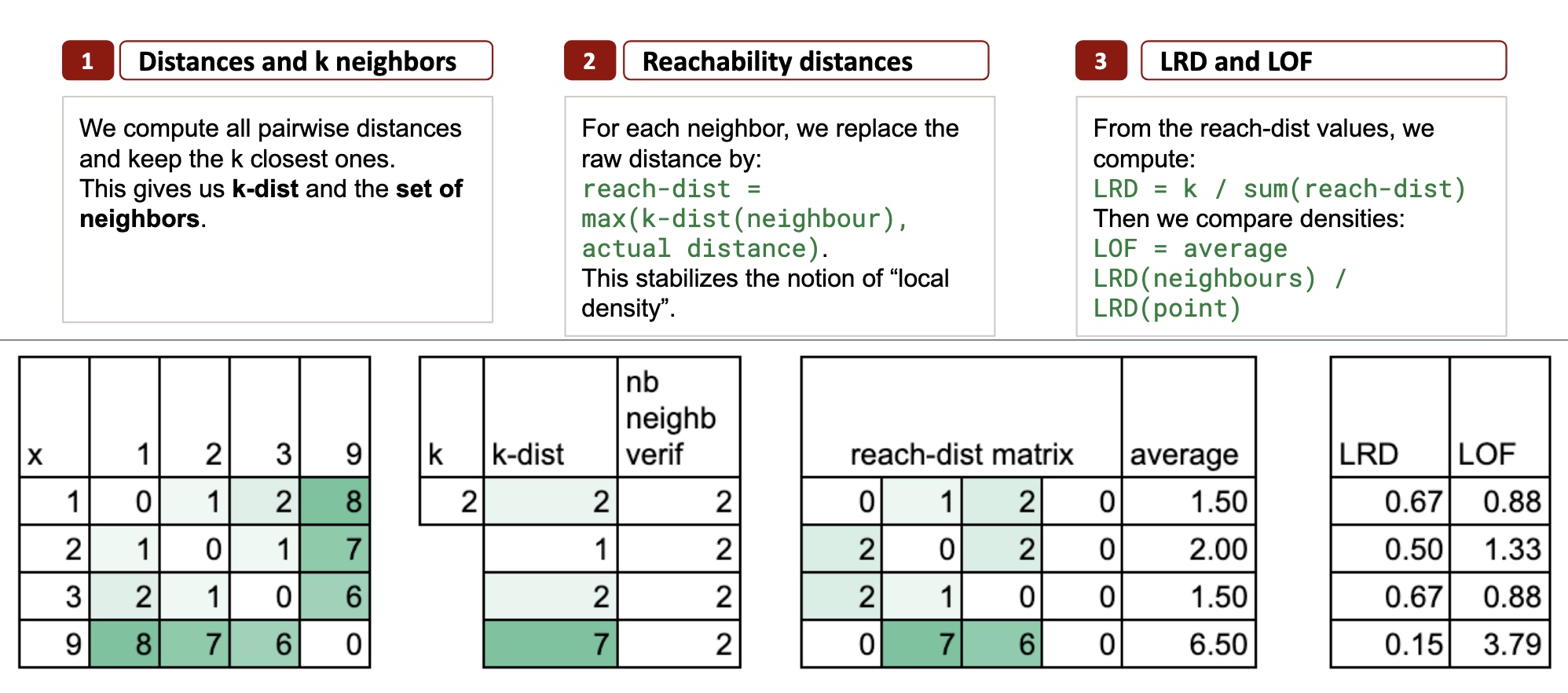
Der Einfachheit halber verwenden wir erneut diesen Datensatz:
1, 2, 3, 9
Erinnern Sie sich, dass ich das Urheberrecht an diesem Datensatz besitze? Wir haben damit Isolation Forest gemacht, und wir werden wieder LOF damit machen. Und wir können die beiden Ergebnisse auch vergleichen.

Schritt 1 – okay Nachbarn und k-Abstand
LOF beginnt mit etwas extrem Einfachem:
Schauen Sie sich die Abstände zwischen den Punkten an.
Finden Sie dann die okay nächsten Nachbarn jedes Punktes.
Nehmen wir okay = 2nur um die Dinge minimal zu halten.
Nächste Nachbarn für jeden Punkt
- Punkt 1 → Nachbarn: 2 und 3
- Punkt 2 → Nachbarn: 1 und 3
- Punkt 3 → Nachbarn: 2 und 1
- Punkt 9 → Nachbarn: 3 und 2
Schon jetzt zeichnet sich eine klare Struktur ab:
- 1, 2 und 3 bilden einen dichten Cluster
- 9 lebt allein, weit weg von den anderen
Der k-Abstand: ein lokaler Radius
Der k-Abstand ist einfach der größte Abstand zwischen den okay nächsten Nachbarn.
Und das ist tatsächlich so der entscheidende Punkt.
Denn diese einzelne Zahl sagt Ihnen etwas ganz Konkretes:
der lokale Radius um den Punkt.
Wenn der k-Abstand klein ist, liegt der Punkt in einem dichten Bereich.
Wenn der k-Abstand groß ist, liegt der Punkt in einem dünn besetzten Bereich.
Mit nur dieser einen Maßnahme haben Sie bereits ein erstes Sign der „Isolation“.
Hier verwenden wir die Idee von „okay nächsten Nachbarn“, was uns natürlich daran erinnert k-NN (der Klassifikator oder Regressor).
Der Kontext ist hier ein anderer, aber die Berechnung ist genau die gleiche.
Und wenn Sie darüber nachdenken k-bedeutetvermischen Sie sie nicht:
Das „okay“ in k-means hat nichts mit dem „okay“ hier zu tun.
Die k-Distanzberechnung
Für Punkt 1die beiden nächsten Nachbarn sind 2 Und 3 (Abstände 1 und 2), additionally k-Abstand(1) = 2.
Für Punkt 2Nachbarn sind 1 Und 3 (beide im Abstand 1), additionally k-Abstand(2) = 1.
Für Punkt 3 sind die beiden nächsten Nachbarn 1 und 2 (Abstände 2 und 1), additionally k-Abstand(3) = 2.
Für Punkt 9Nachbarn sind 3 Und 2 (6 und 7), additionally k-Abstand(9) = 7. Das ist riesig im Vergleich zu allen anderen.
In Excel können wir eine paarweise Abstandsmatrix erstellen, um den k-Abstand für jeden Punkt zu erhalten.

Schritt 2 – Erreichbarkeitsentfernungen
Für diesen Schritt definiere ich hier einfach die Berechnungen und wende die Formeln in Excel an. Denn ehrlich gesagt ist es mir nie gelungen, die Ergebnisse wirklich intuitiv zu erklären.
Was ist additionally „Erreichbarkeitsdistanz“?
Für einen Punkt p und einen Nachbarn o definieren wir diese Erreichbarkeitsentfernung als:
erreichen-dist(p, o) = max(k-dist(o), Abstand(p, o))
Warum das Most nehmen?
Der Zweck der Erreichbarkeitsentfernung ist um den Dichtevergleich zu stabilisieren.
Wenn der Nachbar o in einer sehr dichten Area lebt (kleiner k-Abstand), dann wollen wir keinen unrealistisch kleinen Abstand zulassen.
Insbesondere zu Punkt 2:
- Abstand zu 1 = 1, aber k-distance(1) = 2 → erreichen-dist(2, 1) = 2
- Abstand zu 3 = 1, aber k-distance(3) = 2 → erreichen-dist(2, 3) = 2
Beide Nachbarn erzwingen die Erreichbarkeitsdistanz nach oben.
In Excel behalten wir ein Matrixformat bei, um die Erreichbarkeitsentfernungen anzuzeigen: ein Punkt im Vergleich zu allen anderen.

Durchschnittliche Erreichbarkeitsdistanz
Für jeden Punkt können wir nun den Durchschnittswert berechnen, der uns sagt: Wie weit muss ich im Durchschnitt fahren, um meine Nachbarschaft zu erreichen?
Und jetzt fällt Ihnen etwas auf: Punkt 2 hat eine größere durchschnittliche Erreichbarkeitsentfernung als Punkt 1 und 3.
Das ist für mich nicht so intuitiv!
Schritt 3 – LRD und der LOF-Rating
Der letzte Schritt ist eine Artwork „Normalisierung“, um einen Anomaliewert zu ermitteln.
Zuerst definieren wir die LRD (Native Reachability Density), die einfach der Kehrwert der durchschnittlichen Erreichbarkeitsentfernung ist.
Und der endgültige LOF-Rating wird wie folgt berechnet:

LOF vergleicht additionally die Dichte eines Punktes mit der Dichte seiner Nachbarn.
Interpretation:
- Wenn LRD(p) ≈ LRD (Nachbarn), dann ist LOF ≈ 1
- Wenn LRD(p) viel ist kleinerdann LOF >> 1. Additionally liegt p in einem dünn besetzten Bereich
- Wenn LRD(p) viel ist größer → LOF < 1. p liegt additionally in einer sehr dichten Tasche.
Ich habe auch eine Model mit mehr Entwicklungen und kürzeren Formeln erstellt.

Verstehen, was „Anomalie“ in unbeaufsichtigten Modellen bedeutet
In unbeaufsichtigtes Lernenes gibt keine Grundwahrheit. Und genau hier kann es knifflig werden.
Wir haben keine Etiketten.
Wir haben nicht die „richtige Antwort“.
Wir haben nur die Struktur der Daten.
Nehmen Sie diese kleine Probe:
1, 2, 3, 7, 8, 12
(Ich habe auch das Urheberrecht daran.)
Welche davon fühlt sich, wenn man es intuitiv betrachtet, wie eine Anomalie an?
Persönlich würde ich sagen 12.
Schauen wir uns nun die Ergebnisse an. Laut LOF ist der Ausreißer 7.
(Und Sie können sehen, dass wir bei der k-Entfernung sagen würden, dass dies der Fall ist 12.)

Jetzt können wir vergleichen Isolationswald Und LOF nebeneinander.
Hyperlinks mit dem Datensatz 1, 2, 3, 9beide Methoden stimmen überein:
9 ist der klare Ausreißer.
Isolation Forest gibt ihm die niedrigste Punktzahl,
und LOF gibt ihm den höchsten LOF-Wert.
Wenn wir genauer hinschauen, gibt es für Isolation Forest: 1, 2 und 3 keine Unterschiede in der Punktzahl. Und LOF gibt eine höhere Punktzahl für 2. Das ist uns bereits aufgefallen.
Mit dem Datensatz 1, 2, 3, 7, 8, 12die Geschichte ändert sich.
- Isolationswald weist darauf hin 12 als der isolierteste Punkt.
Das entspricht der Instinct: 12 ist bei weitem nicht jeder. - LOFjedoch Highlights 7 stattdessen.

Wer hat additionally Recht?
Das ist schwer zu sagen.
In der Praxis müssen wir uns zunächst mit den Geschäftsteams darauf einigen was „Anomalie“ eigentlich bedeutet im Zusammenhang mit unseren Daten.
Denn beim unbeaufsichtigten Lernen gibt es keine einzige Wahrheit.
Es gibt nur die Definition von „Anomalie“, die jeder Algorithmus verwendet.
Deshalb ist es äußerst wichtig zu verstehen
wie der Algorithmus funktioniertund welche Artwork von Anomalien es erkennen soll.
Nur dann können Sie entscheiden, ob LOF, Okay-Distance oder Isolation Forest für Ihre spezifische Scenario die richtige Wahl ist.
Und das ist die ganze Botschaft des unbeaufsichtigten Lernens:
Verschiedene Algorithmen betrachten die Daten unterschiedlich.
Es gibt keinen „echten“ Ausreißer.
Nur die Definition, was ein Ausreißer für jedes Modell bedeutet.
Aus diesem Grund verstehen Sie, wie der Algorithmus funktioniert
wichtiger ist als das daraus resultierende Endergebnis.
Abschluss
LOF und Isolation Forest erkennen beide Anomalien, betrachten die Daten jedoch aus völlig unterschiedlichen Blickwinkeln.
- k-Abstand erfasst, wie weit ein Punkt zurücklegen muss, um seine Nachbarn zu finden.
- LOF vergleicht lokale Dichten.
- Isolationswald Isoliert Punkte mithilfe zufälliger Teilungen.
Und sogar weiter sehr einfache Datensätzediese Methoden können unterschiedlich sein.
Ein Algorithmus markiert möglicherweise einen Punkt als Ausreißer, während ein anderer einen völlig anderen hervorhebt.
Und das ist die Kernbotschaft:
Beim unbeaufsichtigten Lernen gibt es keinen „wahren“ Ausreißer.
Jeder Algorithmus definiert Anomalien nach seiner eigenen Logik.
Deshalb Verständnis Wie Eine Methode funktioniert, ist wichtiger als die Zahl, die sie produziert.
Nur dann können Sie den richtigen Algorithmus für die richtige Scenario auswählen und die Ergebnisse sicher interpretieren.