
In diesem Artikel erfahren Sie, wie Sie mit FastAPI ein trainiertes maschinelles Lernmodell hinter eine saubere, intestine validierte HTTP-API packen, vom Coaching über lokale Exams bis hin zur grundlegenden Produktionshärtung.
Zu den Themen, die wir behandeln werden, gehören:
- Trainieren, Speichern und Laden einer Scikit-Study-Pipeline zur Inferenz
- Erstellen einer FastAPI-App mit strenger Eingabevalidierung über Pydantic
- Offenlegen, Testen und Härten eines Vorhersageendpunkts mit Integritätsprüfungen
Lassen Sie uns diese Techniken erkunden.

Der Leitfaden für Praktiker des maschinellen Lernens zur Modellbereitstellung mit FastAPI
Bild vom Autor
Wenn Sie ein Modell für maschinelles Lernen trainiert haben, stellt sich häufig die Frage: „Wie nutzen wir es eigentlich?“ Hier stecken viele Praktiker des maschinellen Lernens fest. Nicht weil die Bereitstellung schwierig ist, sondern weil sie oft schlecht erklärt wird. Bei der Bereitstellung geht es nicht um das Hochladen einer .pkl Datei und hoffe, dass es funktioniert. Es bedeutet lediglich, dass ein anderes System Daten an Ihr Modell senden und Vorhersagen zurückerhalten kann. Der einfachste Weg, dies zu tun, besteht darin, Ihr Modell hinter eine API zu stellen. FastAPI vereinfacht diesen Vorgang. Es verbindet maschinelles Lernen und Backend-Entwicklung auf saubere Weise. Es ist schnell und bietet eine automatische API-Dokumentation Swagger-Benutzeroberflächevalidiert Eingabedaten für Sie und sorgt dafür, dass der Code einfach zu lesen und zu warten ist. Wenn Sie bereits Python verwenden, ist die Arbeit mit FastAPI eine Selbstverständlichkeit.
In diesem Artikel erfahren Sie Schritt für Schritt, wie Sie ein Modell für maschinelles Lernen mithilfe von FastAPI bereitstellen. Insbesondere lernen Sie:
- So trainieren, speichern und laden Sie ein Modell für maschinelles Lernen
- So erstellen Sie eine FastAPI-App und definieren gültige Eingaben
- So erstellen und testen Sie einen Vorhersageendpunkt lokal
- So fügen Sie grundlegende Produktionsfunktionen wie Integritätsprüfungen und Abhängigkeiten hinzu
Fangen wir an!
Schritt 1: Trainieren und Speichern des Modells
Der erste Schritt besteht darin, Ihr maschinelles Lernmodell zu trainieren. Ich trainiere ein Modell, um herauszufinden, wie sich unterschiedliche Hausmerkmale auf den Endpreis auswirken. Sie können jedes Modell verwenden. Erstellen Sie eine Datei mit dem Namen train_model.py:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
Import Pandas als pd aus sklearn.lineares_modell Import LineareRegression aus sklearn.Pipeline Import Pipeline aus sklearn.Vorverarbeitung Import StandardScaler Import joblib # Beispieltrainingsdaten Daten = pd.Datenrahmen({ „Zimmer“: (2, 3, 4, 5, 3, 4), „Alter“: (20, 15, 10, 5, 12, 7), „Distanz“: (10, 8, 5, 3, 6, 4), „Preis“: (100, 150, 200, 280, 180, 250) }) X = Daten((„Zimmer“, „Alter“, „Distanz“)) j = Daten(„Preis“) # Pipeline = Vorverarbeitung + Modell Pipeline = Pipeline(( („Skalierer“, StandardScaler()), („Modell“, LineareRegression()) )) Pipeline.match(X, j) |
Nach dem Coaching müssen Sie das Modell speichern.
|
# Speichern Sie die gesamte Pipeline joblib.entsorgen(Pipeline, „house_price_model.joblib“) |
Führen Sie nun die folgende Zeile im Terminal aus:
Sie verfügen nun über ein trainiertes Modell und eine Vorverarbeitungspipeline, die sicher gespeichert sind.
Schritt 2: Erstellen einer FastAPI-App
Das ist einfacher als Sie denken. Erstellen Sie eine Datei mit dem Namen fundamental.py:
|
aus Fastapi Import FastAPI aus pydantisch Import Basismodell Import joblib App = FastAPI(Titel=„API zur Vorhersage von Immobilienpreisen“) # Modell einmal beim Begin laden Modell = joblib.laden(„house_price_model.joblib“) |
Ihr Modell ist jetzt:
- Einmal geladen
- In Erinnerung behalten
- Bereit, Vorhersagen zu treffen
Dies ist bereits besser als die meisten Einsteigerbereitstellungen.
Schritt 3: Definieren, welche Eingaben Ihr Modell erwartet
Hier scheitern viele Bereitstellungen. Ihr Modell akzeptiert „JSON“ nicht. Es akzeptiert Zahlen in einer bestimmten Struktur. FastAPI verwendet Pydantic, um dies sauber durchzusetzen.
Sie fragen sich vielleicht, was Pydantic ist: Pydantisch ist eine Datenvalidierungsbibliothek, die FastAPI verwendet, um sicherzustellen, dass die von Ihrer API empfangenen Eingaben genau den Erwartungen Ihres Modells entsprechen. Es prüft automatisch Datentypen, erforderliche Felder und Formate, bevor die Anfrage Ihr Modell erreicht.
|
Klasse Hauseingabe(Basismodell): Zimmer: int Alter: schweben Distanz: schweben |
Dies erledigt zwei Dinge für Sie:
- Validiert eingehende Daten
- Dokumentiert Ihre API automatisch
Dies stellt sicher, dass keine Frage mehr gestellt wird: „Warum stürzt mein Modell ab?“ Überraschungen.
Schritt 4: Erstellen des Vorhersageendpunkts
Jetzt müssen Sie Ihr Modell nutzbar machen, indem Sie einen Vorhersageendpunkt erstellen.
|
@App.Publish(„/vorhersagen“) def vorhersage_preis(Daten: Hauseingabe): Merkmale = (( Daten.Zimmer, Daten.Alter, Daten.Distanz ))
Vorhersage = Modell.vorhersagen(Merkmale)
zurückkehren { „predicted_price“: runden(Vorhersage(0), 2) } |
Das ist Ihr bereitgestelltes Modell. Sie können jetzt eine POST-Anfrage senden und Vorhersagen zurückerhalten.
Schritt 5: Lokales Ausführen Ihrer API
Führen Sie diesen Befehl in Ihrem Terminal aus:
|
Uvicorn hauptsächlich:App —neu laden |
Öffnen Sie Ihren Browser und gehen Sie zu:
|
http://127.0.0.1:8000/docs |
Sie werden sehen:
Wenn Sie nicht wissen, was es bedeutet, sehen Sie im Grunde Folgendes:
- Interaktive API-Dokumente
- Ein Formular zum Testen Ihres Modells
- Echtzeitvalidierung
Schritt 6: Testen mit echtem Enter
Um es auszuprobieren, klicken Sie auf den folgenden Pfeil:
![]()
Klicken Sie anschließend auf „Ausprobieren“.
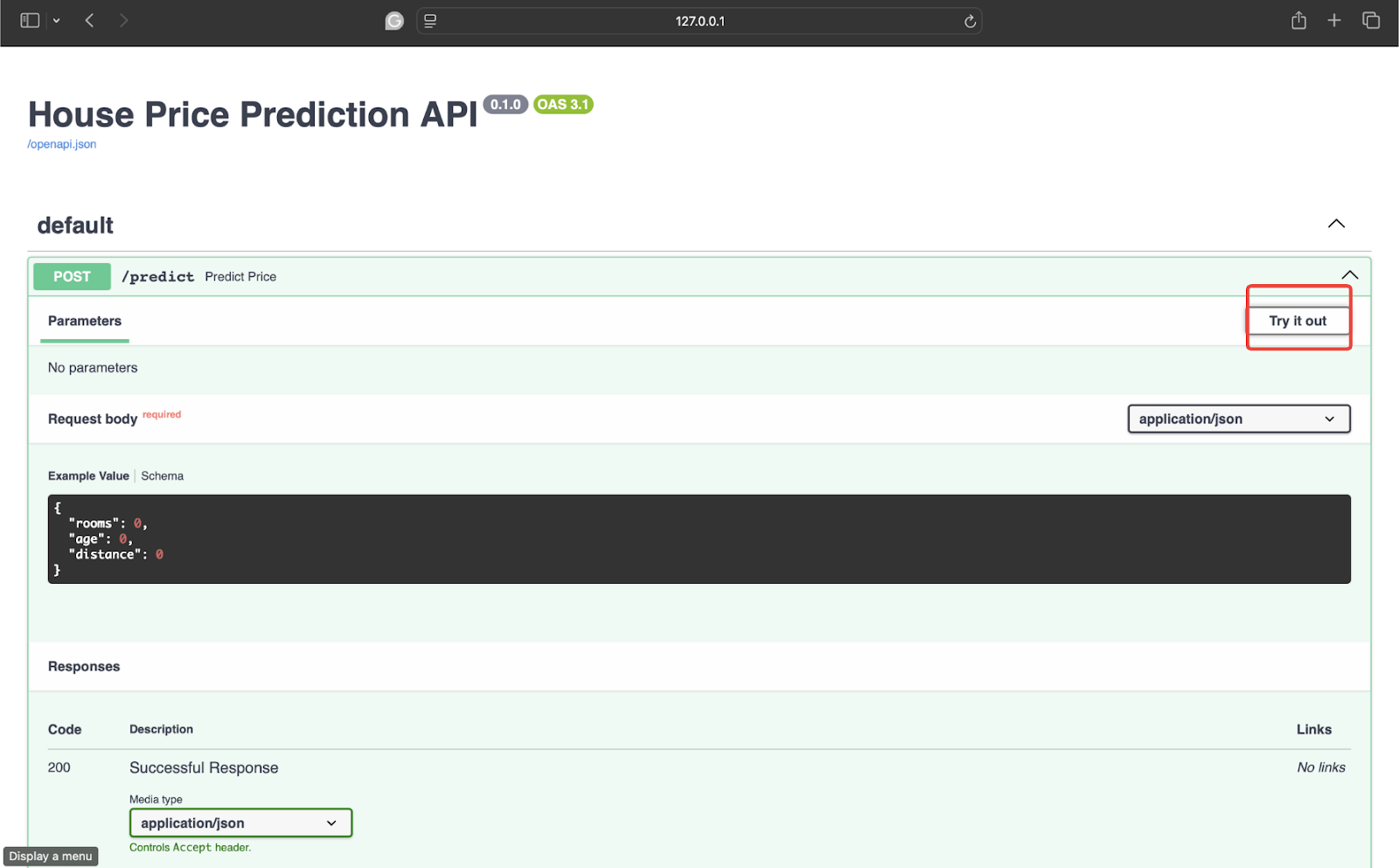
Testen Sie es nun mit einigen Daten. Ich verwende die folgenden Werte:
|
{ „Zimmer“: 4, „Alter“: 8, „Distanz“: 5 } |
Klicken Sie nun auf Ausführen, um die Antwort zu erhalten.

Die Antwort lautet:
|
{ „predicted_price“: 246,67 } |
Ihr Modell akzeptiert jetzt echte Daten, gibt Vorhersagen zurück und ist bereit für die Integration in Apps, Web sites oder andere Dienste.
Schritt 7: Hinzufügen eines Gesundheitschecks
Sie benötigen Kubernetes nicht am ersten Tag, aber bedenken Sie Folgendes:
- Fehlerbehandlung (falsche Eingaben passieren)
- Protokollierungsvorhersagen
- Versionierung Ihrer Modelle (/v1/predict)
- Endpunkt für die Integritätsprüfung
Zum Beispiel:
|
@App.erhalten(„/Gesundheit“) def Gesundheit(): zurückkehren {„Standing“: „OK“} |
Einfache Dinge wie diese sind wichtiger als eine ausgefallene Infrastruktur.
Schritt 8: Hinzufügen einer „Necessities.txt“-Datei
Dieser Schritt sieht klein aus, ist aber eines der Dinge, die Ihnen später im Stillen Stunden ersparen. Ihre FastAPI-App läuft möglicherweise perfekt auf Ihrem Laptop, aber Bereitstellungsumgebungen wissen nicht, welche Bibliotheken Sie verwendet haben, es sei denn, Sie teilen es ihnen mit. Genau das ist es necessities.txt ist für. Es handelt sich um eine einfache Liste von Abhängigkeiten, die Ihr Projekt ausführen muss. Erstellen Sie eine Datei mit dem Namen Anforderungen.txt und füge hinzu:
|
Fastapi Uvicorn Scikit–lernen Pandas joblib |
Wenn nun jemand dieses Projekt einrichten muss, muss er nur die folgende Zeile ausführen:
|
Pip installieren –R Anforderungen.txt |
Dies gewährleistet einen reibungslosen Ablauf des Projekts ohne fehlende Pakete. Die Gesamtstruktur des Projekts sieht in etwa so aus:
|
Projekt/ │ ├── train_model.py ├── hauptsächlich.py ├── house_price_model.joblib ├── Anforderungen.txt |
Abschluss
Ihr Modell ist erst dann wertvoll, wenn jemand es verwenden kann. FastAPI macht Sie nicht zum Backend-Ingenieur – es beseitigt lediglich die Reibung zwischen Ihrem Modell und der realen Welt. Und sobald Sie Ihr erstes Modell bereitstellen, denken Sie nicht mehr wie „jemand, der Modelle trainiert“, sondern denken wie ein Praktiker, der Lösungen liefert. Bitte vergessen Sie nicht, dies zu überprüfen FastAPI-Dokumentation.