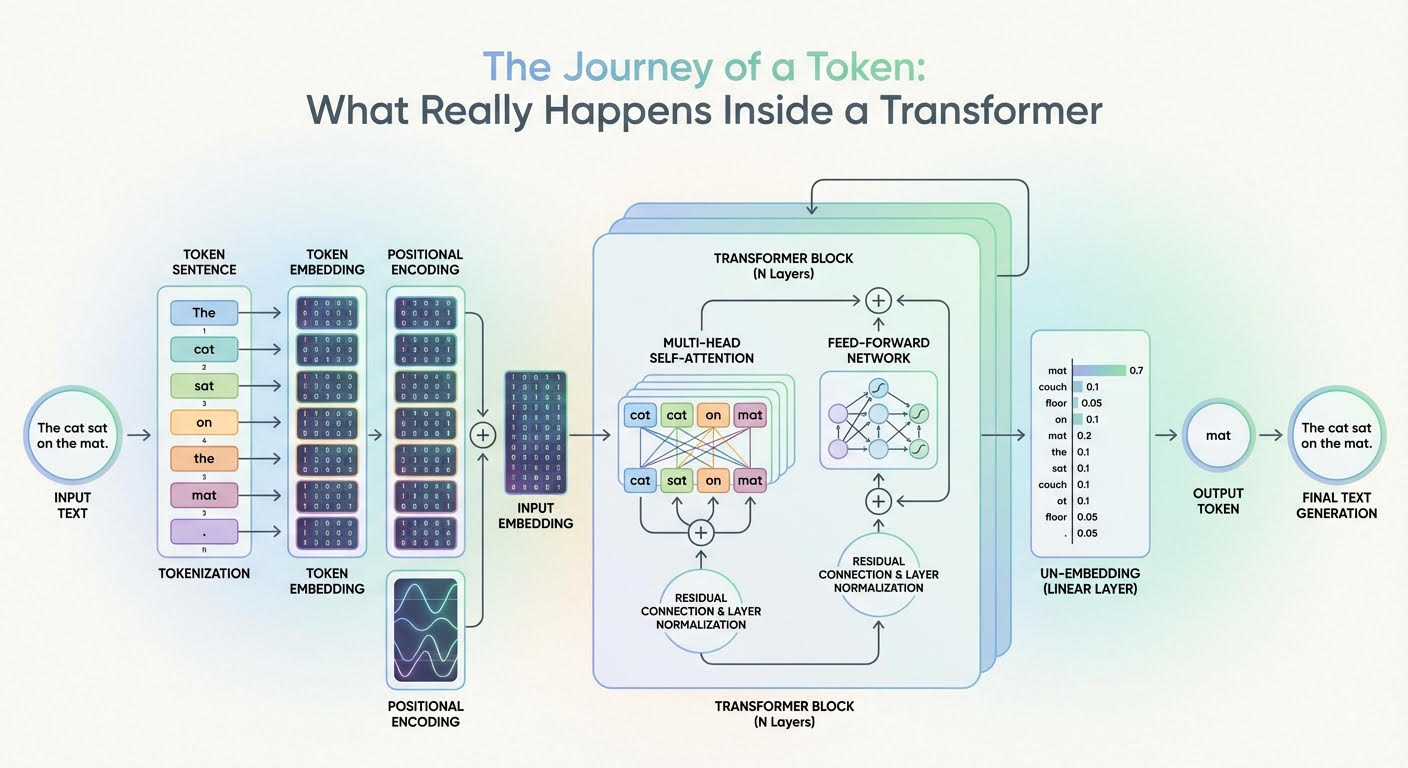
In diesem Artikel erfahren Sie, wie ein Transformator Eingabe-Tokens in kontextbezogene Darstellungen und letztendlich in Wahrscheinlichkeiten für das nächste Token umwandelt.
Zu den Themen, die wir behandeln werden, gehören:
- Wie Tokenisierung, Einbettungen und Positionsinformationen Eingaben vorbereiten
- Welche mehrköpfigen Aufmerksamkeits- und Feed-Ahead-Netzwerke innerhalb jeder Schicht beitragen?
- Wie die endgültige Projektion und Softmax Wahrscheinlichkeiten für das nächste Token erzeugen
Lasst uns unsere Reise beginnen.
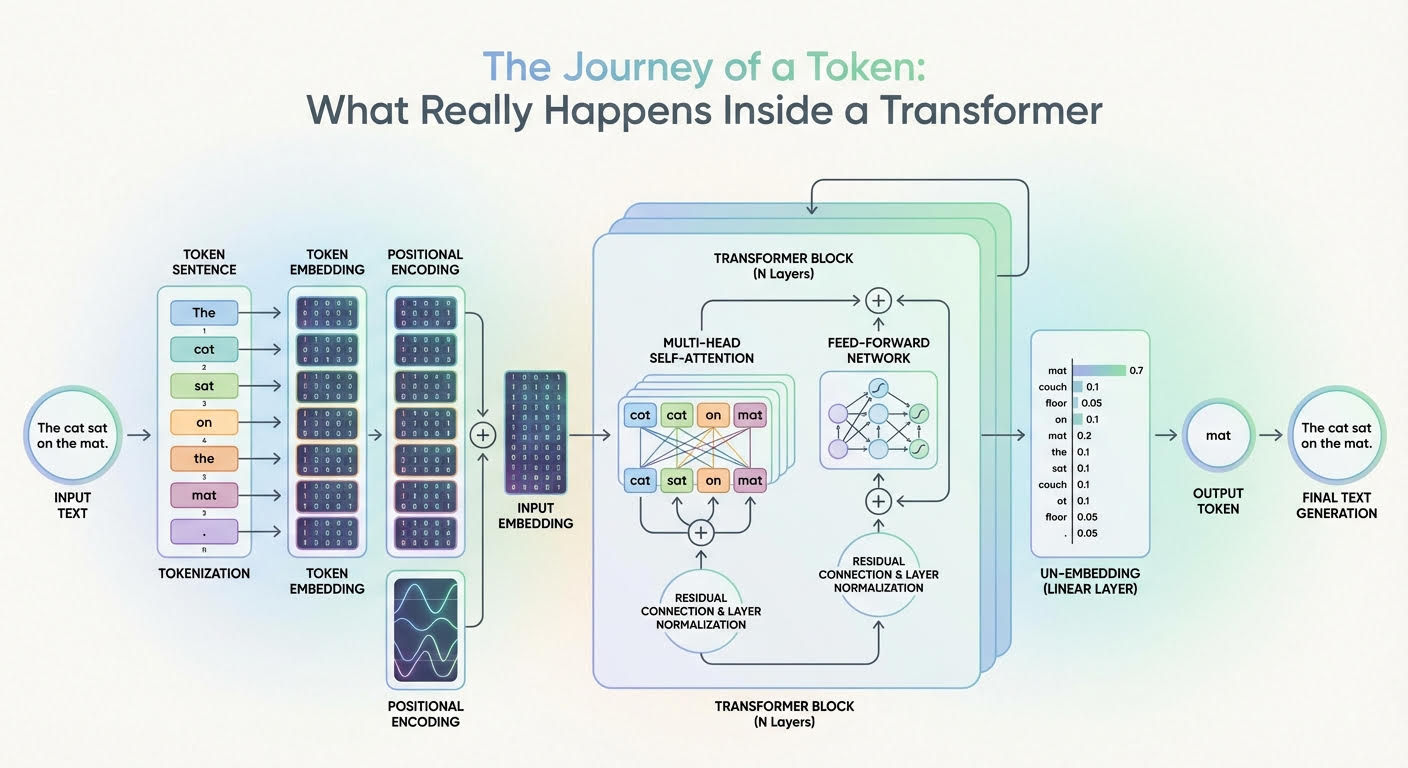
Die Reise eines Tokens: Was wirklich in einem Transformator passiert (zum Vergrößern anklicken)
Bild vom Herausgeber
Die Reise beginnt
Große Sprachmodelle (LLMs) basieren auf der Transformer-Architektur, einem komplexen tiefen neuronalen Netzwerk, dessen Eingabe eine Folge von Token-Einbettungen ist. Nach einem tiefgreifenden Prozess – der wie eine Parade zahlreicher gestapelter Aufmerksamkeits- und Feed-Ahead-Transformationen aussieht – wird eine Wahrscheinlichkeitsverteilung ausgegeben, die angibt, welches Token als nächstes als Teil der Modellantwort generiert werden soll. Aber wie lässt sich dieser Weg von Eingaben zu Ausgaben für einen einzelnen Token in der Eingabesequenz erklären?
In diesem Artikel erfahren Sie, was innerhalb eines Transformer-Modells – der Architektur hinter LLMs – auf Token-Ebene passiert. Mit anderen Worten, wir werden sehen, wie Eingabe-Tokens oder Teile einer Eingabetextsequenz in generierte Textausgaben umgewandelt werden, und die Gründe für die Änderungen und Transformationen, die innerhalb des Transformators stattfinden.
Die Beschreibung dieser Reise durch ein Transformer-Modell orientiert sich am obigen Diagramm, das eine generische Transformer-Architektur zeigt und zeigt, wie Informationen durch sie fließen und sich entwickeln.
Einstieg in den Transformer: Vom Roheingabetext zur Eingabeeinbettung
Bevor wir in die Tiefen des Transformer-Modells vordringen, werden bereits einige Transformationen an der Texteingabe vorgenommen, vor allem, damit sie in einer Type dargestellt werden, die für die internen Schichten des Transformers vollständig verständlich ist.
Tokenisierung
Der Tokenizer ist eine algorithmische Komponente, die typischerweise in Symbiose mit dem Transformatormodell des LLM arbeitet. Es nimmt die Rohtextsequenz, z. B. die Benutzeraufforderung, und teilt sie in diskrete Token (häufig Teilworteinheiten oder Bytes, manchmal ganze Wörter) auf, wobei jedes Token in der Quellsprache einem Bezeichner zugeordnet wird ich.
Token-Einbettungen
Es gibt eine erlernte Einbettungstabelle E mit Type |V| × d (Wortschatzgröße durch Einbettungsdimension). Nachschlagen der Bezeichner für eine Längenfolge n ergibt eine Einbettungsmatrix X mit Type n × d. Das heißt, jeder Token-Bezeichner wird einem zugeordnet D-dimensionaler Einbettungsvektor, der eine Reihe von bildet X. Zwei Einbettungsvektoren sind einander ähnlich, wenn sie mit Token verknüpft sind, die ähnliche Bedeutungen haben, z. B. König und Kaiser oder umgekehrt. Wichtig ist, dass zu diesem Zeitpunkt jede Token-Einbettung semantische und lexikalische Informationen für dieses einzelne Token enthält, ohne Informationen über den Relaxation der Sequenz einzubeziehen (zumindest noch nicht).
Positionskodierung
Vor dem vollständigen Eintritt in die Kernteile des Transformators ist es notwendig, in jeden Token-Einbettungsvektor einzuschleusen – additionally in jede Zeile der Einbettungsmatrix X – Informationen über die Place dieses Tokens in der Sequenz. Dies wird auch als Einfügen von Positionsinformationen bezeichnet und erfolgt typischerweise mit trigonometrischen Funktionen wie Sinus und Cosinus, obwohl es auch Techniken gibt, die auf erlernten Positionseinbettungen basieren. Eine nahezu restliche Komponente wird zum vorherigen Einbettungsvektor summiert e_t mit einem Token verknüpft, wie folgt:
(
x_t^{(0)} = e_t + p_{textual content{pos}}
mit p_pos
Jetzt ist es an der Zeit, in die Tiefen des Transformators vorzudringen und zu sehen, was darin passiert!
Tief im Inneren des Transformators: Von der Eingabeeinbettung zu Ausgabewahrscheinlichkeiten
Lassen Sie uns erklären, was mit jedem „angereicherten“ Einzel-Token-Einbettungsvektor passiert, wenn er eine Transformatorschicht durchläuft, und dann herauszoomen, um zu beschreiben, was im gesamten Schichtstapel passiert.
Die Formel
(
h_t^{(0)} = x_t^{(0)}
)
wird verwendet, um die Darstellung eines Tokens auf Ebene 0 (der ersten Ebene) zu bezeichnen, während wir allgemeiner verwenden werden ht(l) um die Einbettungsdarstellung des Tokens auf der Ebene zu bezeichnen l.
Mehrköpfige Aufmerksamkeit
Die erste Hauptkomponente innerhalb jeder replizierten Schicht des Transformators ist die vielköpfige Aufmerksamkeit. Dies ist wohl die einflussreichste Komponente in der gesamten Architektur, wenn es darum geht, viele aussagekräftige Informationen über seine Rolle in der gesamten Sequenz und seine Beziehungen zu anderen Token im Textual content zu identifizieren und in die Darstellung jedes Tokens zu integrieren, sei es syntaktische, semantische oder jede andere Artwork von sprachlicher Beziehung. Mehrere Köpfe in diesem sogenannten Aufmerksamkeitsmechanismus sind jeweils darauf spezialisiert, verschiedene sprachliche Aspekte und Muster im Token und der gesamten Sequenz, zu der es gehört, gleichzeitig zu erfassen.
Das Ergebnis einer Tokendarstellung ht(l) (mit eingefügten Positionsinformationen a priorinicht vergessen!) Das Durchlaufen dieser mehrköpfigen Aufmerksamkeit innerhalb einer Ebene ist eine kontextangereicherte oder kontextbewusste Token-Repräsentation. Durch die Verwendung von Restverbindungen und Schichtnormalisierungen über die Transformatorschicht hinweg werden neu generierte Vektoren zu stabilisierten Mischungen ihrer eigenen vorherigen Darstellungen und der mehrköpfigen Aufmerksamkeitsausgabe. Dies trägt dazu bei, die Kohärenz während des gesamten Prozesses zu verbessern, der wiederholt über Schichten hinweg angewendet wird.
Feed-Ahead-Neuronales Netzwerk
Als nächstes kommt etwas relativ weniger Komplexes: ein paar Feed-Ahead-Neuronales Netzwerk (FFN)-Schichten. Dabei kann es sich beispielsweise um mehrschichtige Perzeptrone (MLPs) professional Token handeln, deren Ziel es ist, die Token-Funktionen, die nach und nach erlernt werden, weiter zu transformieren und zu verfeinern.
Der Hauptunterschied zwischen der Aufmerksamkeitsphase und dieser besteht darin, dass Aufmerksamkeit in jeder Token-Darstellung Kontextinformationen aus allen Token mischt und integriert, der FFN-Schritt jedoch unabhängig auf jedem Token angewendet wird und die bereits integrierten Kontextmuster verfeinert, um daraus nützliches „Wissen“ zu gewinnen. Diese Schichten werden auch durch Restverbindungen und Schichtnormalisierungen ergänzt, und als Ergebnis dieses Prozesses haben wir am Ende einer Transformatorschicht eine aktualisierte Darstellung ht(l+1) Dies wird zur Eingabe für die nächste Transformatorschicht und gelangt so in einen weiteren mehrköpfigen Aufmerksamkeitsblock.
Der gesamte Prozess wird so oft wiederholt, wie in unserer Architektur definierte gestapelte Schichten vorhanden sind, wodurch die Token-Einbettung nach und nach mit immer mehr übergeordneten, abstrakten und weitreichenden sprachlichen Informationen hinter diesen scheinbar nicht entzifferbaren Zahlen bereichert wird.
Endziel
Was passiert additionally ganz am Ende? Oben im Stapel erhalten wir nach Durchlaufen der letzten replizierten Transformatorschicht eine endgültige Token-Darstellung ht*(L) (Wo t* bezeichnet die aktuelle Vorhersageposition), die durch a projiziert wird lineare Ausgabeschicht gefolgt von a Softmax.
Die lineare Schicht erzeugt nicht normalisierte Werte, die als „ Protokolleund der Softmax wandelt diese Logits in Wahrscheinlichkeiten für das nächste Token um.
Berechnung der Protokolle:
(
textual content{logits}_j = W_{textual content{vocab}, j} cdot h_{t^*}^{(L)} + b_j
)
Anwenden von Softmax zur Berechnung normalisierter Wahrscheinlichkeiten:
(
textual content{softmax}(textual content{logits})_j = frac{exp(textual content{logits}_j)}{sum_{ok} exp(textual content{logits}_k)}
)
Verwendung von Softmax-Ausgaben als Subsequent-Token-Wahrscheinlichkeiten:
(
P(textual content{token} = j) = textual content{softmax}(textual content{logits})_j
)
Diese Wahrscheinlichkeiten werden für alle möglichen Token im Vokabular berechnet. Anschließend wird der nächste vom LLM zu generierende Token ausgewählt – häufig der mit der höchsten Wahrscheinlichkeit, obwohl auch auf Stichproben basierende Decodierungsstrategien üblich sind.
Das Ende der Reise
In diesem Artikel wurde mit einem sanften Maß an technischen Particulars eine Reise durch die Transformer-Architektur unternommen, um ein allgemeines Verständnis dafür zu vermitteln, was mit dem Textual content passiert, der einem LLM – dem bekanntesten Modell, das auf einer Transformer-Architektur basiert – bereitgestellt wird, und wie dieser Textual content innerhalb des Modells auf Token-Ebene verarbeitet und transformiert wird, um schließlich in die Ausgabe eines Modells zu gelangen: das nächste zu generierende Wort.
Wir hoffen, dass Sie unsere gemeinsame Reise genossen haben und freuen uns auf die Gelegenheit, in naher Zukunft eine weitere Reise anzutreten.