Der Begriff „KI-Agent„ist derzeit eine der beliebtesten. Sie entstanden nach dem LLM-Hype, als die Leute erkannten, dass die neuesten LLM-Fähigkeiten beeindruckend sind, sie aber nur Aufgaben ausführen können, für die sie ausdrücklich geschult wurden. In diesem Sinne verfügen normale LLMs nicht über Werkzeuge, die es ihnen ermöglichen würden, etwas zu tun, das außerhalb ihres Wissensbereichs liegt.
LAPPEN
Um dieses Downside anzugehen, Retrieval-Augmented Era (RAG) wurde später eingeführt, um zusätzlichen Kontext aus externen Datenquellen abzurufen und in die Eingabeaufforderung einzufügen, sodass der LLM mehr Kontext erkennt. Man kann grob sagen, dass RAG das LLM kenntnisreicher gemacht hat, aber bei komplexeren Problemen scheiterte der LLM + RAG-Ansatz immer noch, wenn der Lösungspfad nicht im Voraus bekannt conflict.

Agenten
Agenten sind ein bemerkenswertes Konzept, das auf LLMs basiert, die einführen Zustand, EntscheidungsfindungUnd Erinnerung. Man kann sich Agenten als eine Reihe vordefinierter Instruments vorstellen, mit denen Ergebnisse analysiert und zur späteren Verwendung im Speicher gespeichert werden, bevor die endgültige Antwort erstellt wird.
LangGraph
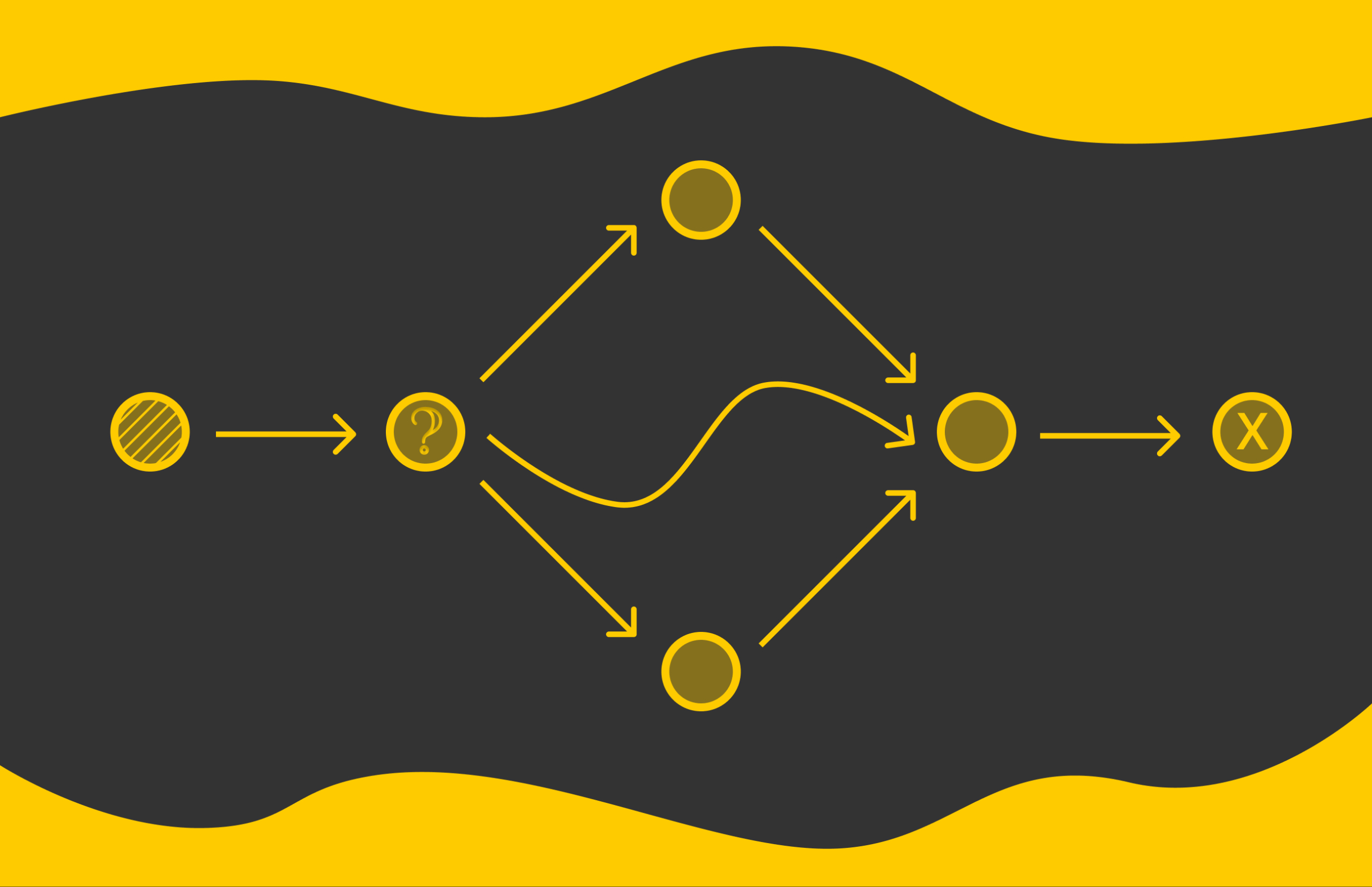
LangGraph ist ein beliebtes Framework zum Erstellen von Agenten. Wie der Title schon sagt, werden Agenten mithilfe von Diagrammen mit Knoten und Kanten konstruiert.
Knoten stellen den Standing des Agenten dar, der sich im Laufe der Zeit entwickelt. Kanten definieren den Kontrollfluss, indem sie Übergangsregeln und -bedingungen zwischen Knoten festlegen.
Um LangGraph in der Praxis besser zu verstehen, gehen wir ein detailliertes Beispiel durch. Auch wenn LangGraph für das folgende Downside zu ausführlich erscheint, hat es bei komplexen Problemen mit großen Diagrammen in der Regel einen viel größeren Einfluss.
Zuerst müssen wir die notwendigen Bibliotheken installieren.
langgraph==1.0.5
langchain-community==0.4.1
jupyter==1.1.1
pocket book==7.5.1
langchain(openai)Anschließend importieren wir die notwendigen Module.
import os
from dotenv import load_dotenvimport json
import random
from pydantic import BaseModel
from typing import Non-compulsory, Record, Dict, Anyfrom langgraph.graph import StateGraph, START, END
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from langchain.chat_models import init_chat_model
from langchain.instruments import instrumentfrom IPython.show import Picture, showWir müssten auch eine erstellen .env Datei und fügen Sie eine hinzu OPENAI_API_KEY Dort:
OPENAI_API_KEY=...Dann, mit load_dotenv()können wir die Umgebungsvariablen in das System laden.
load_dotenv()Zusätzliche Funktionen
Die folgende Funktion wird für uns nützlich sein, um konstruierte Diagramme visuell anzuzeigen.
def display_graph(graph):
return show(Picture(graph.get_graph().draw_mermaid_png()))Agent
Lassen Sie uns einen Agenten basierend auf GPT-5-nano mit einem einfachen Befehl initialisieren:
llm = init_chat_model("openai:gpt-5-nano")Zustand
In unserem Beispiel werden wir einen Agenten konstruieren, der Fragen zum Thema Fußball beantworten kann. Sein Denkprozess wird auf abgerufenen Statistiken über Spieler basieren.
Dazu müssen wir einen Zustand definieren. In unserem Fall handelt es sich um eine Entität, die alle Informationen enthält, die ein LLM über einen Spieler benötigt. Um einen Zustand zu definieren, müssen wir eine Klasse schreiben, von der er erbt pydantic.BaseModel:
class PlayerState(BaseModel):
query: str
selected_tools: Non-compulsory(Record(str)) = None
identify: Non-compulsory(str) = None
membership: Non-compulsory(str) = None
nation: Non-compulsory(str) = None
quantity: Non-compulsory(int) = None
score: Non-compulsory(int) = None
objectives: Non-compulsory(Record(int)) = None
minutes_played: Non-compulsory(Record(int)) = None
abstract: Non-compulsory(str) = NoneBeim Wechseln zwischen LangGraph-Knoten verwendet jeder Knoten als Eingabe eine Instanz von PlayerState das gibt an, wie der Zustand verarbeitet werden soll. Unsere Aufgabe wird es sein, zu definieren, wie genau dieser Zustand verarbeitet wird.
Werkzeuge
Zunächst definieren wir einige der Instruments, die ein Agent verwenden kann. A Werkzeug kann man sich grob als eine zusätzliche Funktion vorstellen, die ein Agent aufrufen kann, um die Informationen abzurufen, die zur Beantwortung der Frage eines Benutzers erforderlich sind.
Um ein Werkzeug zu definieren, müssen wir eine Funktion mit a schreiben @Werkzeug Dekorateur. Es ist wichtig, eindeutige Parameternamen und Funktionsdokumentzeichenfolgen zu verwenden, da der Agent diese berücksichtigt, wenn er basierend auf dem Eingabekontext entscheidet, ob das Instrument aufgerufen werden soll.
Um unsere Beispiele zu vereinfachen, verwenden wir Scheindaten anstelle von echten Daten, die aus externen Quellen abgerufen werden, was normalerweise bei Produktionsanwendungen der Fall ist.
Im ersten Instrument geben wir Informationen über den Verein und das Land eines Spielers namentlich zurück.
@instrument
def fetch_player_information_tool(identify: str):
"""Accommodates details about the soccer membership of a participant and its nation"""
knowledge = {
'Haaland': {
'membership': 'Manchester Metropolis',
'nation': 'Norway'
},
'Kane': {
'membership': 'Bayern',
'nation': 'England'
},
'Lautaro': {
'membership': 'Inter',
'nation': 'Argentina'
},
'Ronaldo': {
'membership': 'Al-Nassr',
'nation': 'Portugal'
}
}
if identify in knowledge:
print(f"Returning participant data: {knowledge(identify)}")
return knowledge(identify)
else:
return {
'membership': 'unknown',
'nation': 'unknown'
}
def fetch_player_information(state: PlayerState):
return fetch_player_information_tool.invoke({'identify': state.identify})Sie fragen sich vielleicht, warum wir ein Werkzeug in eine andere Funktion einfügen, was wie Überentwicklung erscheint. Tatsächlich haben diese beiden Funktionen unterschiedliche Verantwortlichkeiten.
Die Funktion fetch_player_information() akzeptiert einen Zustand als Parameter und ist mit dem LangGraph-Framework kompatibel. Es extrahiert das Namensfeld und ruft ein Instrument auf, das auf Parameterebene arbeitet.
Es bietet eine klare Trennung der Anliegen und ermöglicht die einfache Wiederverwendung desselben Instruments über mehrere Diagrammknoten hinweg.
Dann haben wir eine analoge Funktion, die die Trikotnummer eines Spielers abruft:
@instrument
def fetch_player_jersey_number_tool(identify: str):
"Returns participant jersey quantity"
knowledge = {
'Haaland': 9,
'Kane': 9,
'Lautaro': 10,
'Ronaldo': 7
}
if identify in knowledge:
print(f"Returning participant quantity: {knowledge(identify)}")
return {'quantity': knowledge(identify)}
else:
return {'quantity': 0}
def fetch_player_jersey_number(state: PlayerState):
return fetch_player_jersey_tool.invoke({'identify': state.identify})Für das dritte Instrument rufen wir die FIFA-Bewertung des Spielers ab:
@instrument
def fetch_player_rating_tool(identify: str):
"Returns participant score within the FIFA"
knowledge = {
'Haaland': 92,
'Kane': 89,
'Lautaro': 88,
'Ronaldo': 90
}
if identify in knowledge:
print(f"Returning score knowledge: {knowledge(identify)}")
return {'score': knowledge(identify)}
else:
return {'score': 0}
def fetch_player_rating(state: PlayerState):
return fetch_player_rating_tool.invoke({'identify': state.identify})Lassen Sie uns nun mehrere weitere Graphknotenfunktionen schreiben, die externe Daten abrufen. Wir werden sie nicht wie bisher als Werkzeuge bezeichnen, was bedeutet, dass der Agent nicht entscheidet, ob er sie anruft oder nicht.
def retrieve_goals(state: PlayerState):
identify = state.identify
knowledge = {
'Haaland': (25, 40, 28, 33, 36),
'Kane': (33, 37, 41, 38, 29),
'Lautaro': (19, 25, 27, 24, 25),
'Ronaldo': (27, 32, 28, 30, 36)
}
if identify in knowledge:
return {'objectives': knowledge(identify)}
else:
return {'objectives': (0)}Hier ist ein Diagrammknoten, der die Anzahl der gespielten Minuten der letzten Saisons abruft.
def retrieve_minutes_played(state: PlayerState):
identify = state.identify
knowledge = {
'Haaland': (2108, 3102, 3156, 2617, 2758),
'Kane': (2924, 2850, 3133, 2784, 2680),
'Lautaro': (2445, 2498, 2519, 2773),
'Ronaldo': (3001, 2560, 2804, 2487, 2771)
}
if identify in knowledge:
return {'minutes_played': knowledge(identify)}
else:
return {'minutes_played': (0)}Unten befindet sich ein Knoten, der den Namen eines Spielers aus einer Benutzerfrage extrahiert.
def extract_name(state: PlayerState):
query = state.query
immediate = f"""
You're a soccer identify extractor assistant.
Your purpose is to simply extract a surname of a footballer within the following query.
Consumer query: {query}
You need to simply output a string containing one phrase - footballer surname.
"""
response = llm.invoke((HumanMessage(content material=immediate))).content material
print(f"Participant identify: ", response)
return {'identify': response}Jetzt ist die Zeit gekommen, in der es interessant wird. Erinnern Sie sich an die drei Instruments, die wir oben definiert haben? Dank ihnen können wir jetzt einen Planer erstellen, der den Agenten auffordert, basierend auf dem Kontext der Scenario ein bestimmtes aufzurufendes Instrument auszuwählen:
def planner(state: PlayerState):
query = state.query
immediate = f"""
You're a soccer participant abstract assistant.
You might have the next instruments accessible: ('fetch_player_jersey_number', 'fetch_player_information', 'fetch_player_rating')
Consumer query: {query}
Resolve which instruments are required to reply.
Return a JSON checklist of instrument names, e.g. ('fetch_player_jersey_number', 'fetch_rating')
"""
response = llm.invoke((HumanMessage(content material=immediate))).content material
strive:
selected_tools = json.hundreds(response)
besides:
selected_tools = ()
return {'selected_tools': selected_tools}In unserem Fall bitten wir den Agenten, eine Zusammenfassung eines Fußballspielers zu erstellen. Es entscheidet selbstständig, welches Instrument aufgerufen wird, um zusätzliche Daten abzurufen. Docstrings unter Instruments spielen eine wichtige Rolle: Sie versorgen den Agenten mit zusätzlichem Kontext zu den Instruments.
Unten sehen Sie unseren letzten Diagrammknoten, der mehrere aus den vorherigen Schritten abgerufene Felder übernimmt und den LLM aufruft, um eine endgültige Zusammenfassung zu erstellen.
def write_summary(state: PlayerState):
query = state.query
knowledge = {
'identify': state.identify,
'nation': state.nation,
'quantity': state.quantity,
'score': state.score,
'objectives': state.objectives,
'minutes_played': state.minutes_played,
}
immediate = f"""
You're a soccer reporter assistant.
Given the next knowledge and statistics of the soccer participant, you'll have to create a markdown abstract of that participant.
Participant knowledge:
{json.dumps(knowledge, indent=4)}
The markdown abstract has to incorporate the next data:
- Participant full identify (if solely first identify or final identify is supplied, attempt to guess the total identify)
- Participant nation (additionally add flag emoji)
- Participant quantity (additionally add the quantity within the emoji(-s) type)
- FIFA score
- Complete variety of objectives in final 3 seasons
- Common variety of minutes required to attain one purpose
- Response to the person query: {query}
"""
response = llm.invoke((HumanMessage(content material=immediate))).content material
return {"abstract": response}Graphenkonstruktion
Wir haben jetzt alle Elemente, um ein Diagramm zu erstellen. Zuerst initialisieren wir den Graphen mit StateGraph Konstrukteur. Dann fügen wir diesem Diagramm nacheinander Knoten hinzu, indem wir verwenden add_node() Verfahren. Es benötigt zwei Parameter: eine Zeichenfolge, die verwendet wird, um dem Knoten einen Namen zuzuweisen, und eine aufrufbare Funktion, die dem Knoten zugeordnet ist und als einzigen Parameter einen Diagrammstatus verwendet.
graph_builder = StateGraph(PlayerState)
graph_builder.add_node('extract_name', extract_name)
graph_builder.add_node('planner', planner)
graph_builder.add_node('fetch_player_jersey_number', fetch_player_jersey_number)
graph_builder.add_node('fetch_player_information', fetch_player_information)
graph_builder.add_node('fetch_player_rating', fetch_player_rating)
graph_builder.add_node('retrieve_goals', retrieve_goals)
graph_builder.add_node('retrieve_minutes_played', retrieve_minutes_played)
graph_builder.add_node('write_summary', write_summary)Im Second besteht unser Diagramm nur aus Knoten. Wir müssen Kanten hinzufügen. Die Kanten in LangGraph werden über das ausgerichtet und hinzugefügt add_edge() Methode, die die Namen der Begin- und Endknoten angibt.
Das Einzige, was wir berücksichtigen müssen, ist der Planer, der sich etwas anders als andere Knoten verhält. Wie oben gezeigt, kann es zurückgegeben werden ausgewählte_tools Feld, das 0 bis 3 Ausgabeknoten enthält.
Dafür müssen wir das verwenden add_conditional_edges() Methode mit drei Parametern:
- Der Title des Planerknotens;
- Eine aufrufbare Funktion, die einen LangGraph-Knoten nimmt und eine Liste von Zeichenfolgen zurückgibt, die die Liste der Knotennamen angibt, sollte aufgerufen werden;
- Ein Wörterbuch, das Zeichenfolgen vom zweiten Parameter zu Knotennamen zuordnet.
In unserem Fall definieren wir die route_tools() Knoten, um einfach die zurückzugeben state.selected_tools Feld als Ergebnis einer Planerfunktion.
def route_tools(state: PlayerState):
return state.selected_tools or ()Dann können wir Knoten konstruieren:
graph_builder.add_edge(START, 'extract_name')
graph_builder.add_edge('extract_name', 'planner')
graph_builder.add_conditional_edges(
'planner',
route_tools,
{
'fetch_player_jersey_number': 'fetch_player_jersey_number',
'fetch_player_information': 'fetch_player_information',
'fetch_player_rating': 'fetch_player_rating'
}
)
graph_builder.add_edge('fetch_player_jersey_number', 'retrieve_goals')
graph_builder.add_edge('fetch_player_information', 'retrieve_goals')
graph_builder.add_edge('fetch_player_rating', 'retrieve_goals')
graph_builder.add_edge('retrieve_goals', 'retrieve_minutes_played')
graph_builder.add_edge('retrieve_minutes_played', 'write_summary')
graph_builder.add_edge('write_summary', END)START und END sind LangGraph-Konstanten, die zum Definieren der Begin- und Endpunkte des Diagramms verwendet werden.
Der letzte Schritt besteht darin, das Diagramm zu kompilieren. Wir können es optionally available mit der oben definierten Hilfsfunktion visualisieren.
graph = graph_builder.compile()
display_graph(graph)
Beispiel
Jetzt können wir endlich unsere Grafik verwenden! Dazu können wir die Methode „invoke“ verwenden und ein Wörterbuch übergeben, das das Fragefeld mit einer benutzerdefinierten Benutzerfrage enthält:
end result = graph.invoke({
'query': 'Will Haaland be capable of win the FIFA World Cup for Norway in 2026 based mostly on his latest efficiency and stats?'
})Und hier ist ein Beispielergebnis, das wir erhalten können!
{'query': 'Will Haaland be capable of win the FIFA World Cup for Norway in 2026 based mostly on his latest efficiency and stats?',
'selected_tools': ('fetch_player_information', 'fetch_player_rating'),
'identify': 'Haaland',
'membership': 'Manchester Metropolis',
'nation': 'Norway',
'score': 92,
'objectives': (25, 40, 28, 33, 36),
'minutes_played': (2108, 3102, 3156, 2617, 2758),
'abstract': '- Full identify: Erling Haalandn- Nation: Norway 🇳🇴n- Quantity: N/A
- FIFA score: 92n- Complete objectives in final 3 seasons: 97 (28 + 33 + 36)n- Common minutes per purpose (final 3 seasons): 87.95 minutes per goaln- Will Haaland win the FIFA World Cup for Norway in 2026 based mostly on latest efficiency and stats?n - Brief reply: Not assured. Haaland stays among the many world’s prime forwards (92 score, elite purpose output), and he might be a key issue for Norway. Nonetheless, World Cup success is a workforce achievement depending on Norway’s total squad high quality, depth, techniques, accidents, and event context. Based mostly on statistics alone, he strengthens Norway’s possibilities, however a World Cup title in 2026 can't be predicted with certainty.'}Das Tolle daran ist, dass wir den gesamten Zustand des Diagramms beobachten und die Instruments analysieren können, die der Agent ausgewählt hat, um die endgültige Antwort zu generieren. Die abschließende Zusammenfassung sieht großartig aus!
Abschluss
In diesem Artikel haben wir KI-Agenten untersucht, die ein neues Kapitel für LLMs aufgeschlagen haben. Ausgestattet mit modernsten Werkzeugen und Entscheidungssystemen verfügen wir nun über ein viel größeres Potenzial, komplexe Aufgaben zu lösen.
Ein Beispiel, das wir in diesem Artikel gesehen haben, führte uns in LangGraph ein – eines der beliebtesten Frameworks für die Erstellung von Agenten. Seine Einfachheit und Eleganz ermöglichen den Aufbau komplexer Entscheidungsketten. Während LangGraph für unser einfaches Beispiel übertrieben erscheinen magazine, ist es für größere Projekte, bei denen Zustands- und Diagrammstrukturen viel komplexer sind, äußerst nützlich.
Ressourcen
Alle Bilder stammen, sofern nicht anders angegeben, vom Autor.