. Was für ein Geschenk für die Gesellschaft das ist. Wenn es Google Developments nicht gäbe, wie hätten wir das jemals wissen sollen? In den 2000er Jahren wurden mehr Disney-Filme veröffentlicht, was zu weniger Scheidungen im Vereinigten Königreich führte. Oder das Das Trinken von Coca-Cola ist ein unbekanntes Mittel gegen Katzenkratzer.
Second, verwirre ich wieder Korrelation vs. Kausalität?
Wenn Sie lieber zuschauen als lesen möchten, können Sie dies hier tun:
Google Developments ist eines der am häufigsten verwendeten Instruments zur Analyse menschlichen Verhaltens in großem Maßstab. Journalisten nutzen es. Datenwissenschaftler nutzen es. Ganze Papiere sind darauf aufgebaut. Es gibt jedoch eine grundlegende Eigenschaft der Google Developments-Daten, die einen Missbrauch sehr leicht macht, insbesondere wenn Sie mit Zeitreihen arbeiten oder versuchen, Modelle zu erstellen, und die meisten Menschen bemerken nie, dass sie dies tun.
Alle Diagramme und Screenshots wurden vom Autor erstellt, sofern nicht anders angegeben.
Das Downside mit Google Developments-Daten
Google veröffentlicht eigentlich keine Zahlen zum Suchvolumen. Diese Informationen bringen ihnen Geld ein, und es gibt keine Möglichkeit, sie anderen Menschen zur Monetarisierung zugänglich zu machen. Aber was sie uns geben, ist eine Möglichkeit, eine Zeitreihe zu sehen, um Veränderungen in der Suche von Menschen nach einem bestimmten Begriff zu verstehen, und das tun sie, indem sie uns eine geben normalisierter Datensatz.
Dies scheint kein Downside zu sein, bis Sie versuchen, maschinelles Lernen damit durchzuführen. Denn wenn es darum geht, eine Maschine dazu zu bringen, etwas zu lernen, müssen wir ihr viele Daten zur Verfügung stellen.
Meine ursprüngliche Idee warfare, ein Zeitfenster von fünf Jahren zu nehmen, aber ich habe sofort ein Downside: Je größer das Zeitfenster, desto weniger granular sind die Daten. Ich konnte fünf Jahre lang keine täglichen Daten erhalten, und obwohl ich dann dachte: „Nehmen Sie einfach den maximalen Zeitraum, für den Sie tägliche Daten erhalten können, und verschieben Sie dieses Fenster“, warfare das auch ein Downside. Denn hier habe ich den wahren Schrecken entdeckt Normalisierung:
Unabhängig davon, welchen Zeitraum ich verwende oder welchen einzelnen Suchbegriff ich verwende, wird der Datenpunkt mit der höchsten Anzahl an Suchanfragen sofort auf 100 gesetzt. Das bedeutet, dass sich die Bedeutung von 100 mit jedem Fenster, das ich verwende, ändert.
Dieser gesamte Beitrag existiert aus diesem Grund.
Google Developments-Grundlagen
Ich weiß nicht, ob Sie es verwendet haben Google Developments Aber wenn nicht, werde ich es Ihnen erklären, damit wir dem Kern des Issues auf den Grund gehen können.
Additionally werde ich nach dem Wort „Motivation“ suchen und es wird standardmäßig auf das Vereinigte Königreich zurückgegriffen, weil ich dort herkomme, und auf den vergangenen Tag. Wir haben eine schöne Grafik, die zeigt, wie oft Leute in den letzten 24 Stunden nach dem Wort „Motivation“ gesucht haben.

Ich liebe das, weil man wirklich deutlich sehen kann, dass die Leute hauptsächlich auf der Suche nach Motivation sind während des Arbeitstages, Niemand sucht danach, während der größte Teil des Landes schläft, und es gibt definitiv ein paar Kinder, die etwas Ermutigung für ihre Hausaufgaben brauchen. Ich habe keine Erklärung für die nächtlichen Durchsuchungen, aber ich schätze, das sind Leute, die nicht bereit sind, morgen wieder zur Arbeit zu gehen.
Nun, das ist schön, aber während achtminütige Inkremente über 24 Stunden uns schöne 180 Datenpunkte zur Verfügung stellen, Die meisten davon sind tatsächlich Null und ich weiß nicht, ob die letzten 24 Stunden im Vergleich zum Relaxation des Jahres sehr demotivierend waren oder ob heute der höchste BIP-Beitrag des Jahres vorliegt Ich werde das Fenster vergrößern ein bisschen.
Sobald wir auf eine Woche umsteigen, fällt Ihnen als Erstes auf, dass die Daten viel weniger granular sind. Wir haben eine Woche lang Daten, aber jetzt sind es nur noch stündliche Daten, und ich habe immer noch das gleiche Kernproblem, nichts zu wissen wie repräsentativ diese Woche ist.
Ich kann weiter herauszoomen. 30 Tage, 90 Tage. An jedem Punkt verlieren wir an Granularität und haben nicht annähernd so viele Datenpunkte wie in den letzten 24 Stunden. Wenn ich ein echtes Modell baue, reicht das nicht aus. Ich muss groß rauskommen.
Und wenn ich fünf Jahre auswähle, stoßen wir auf das Downside, das dieses ganze Video motiviert hat (entschuldigen Sie das Wortspiel, das warfare unbeabsichtigt): Ich kann keine täglichen Daten erhalten. Und warum liegt der heutige Wert nicht mehr bei 100?

Hierin liegt das eigentliche Downside mit den Google-Developments-Daten
Wie ich bereits erwähnt habe, sind die Daten von Google Developments normalisiert. Das heißt, egal welchen Zeitraum ich verwende oder welchen einzelnen Suchbegriff ich verwende, der Datenpunkt mit der höchsten Anzahl an Suchanfragen wird sofort auf 100 gesetzt. Alle anderen Punkte werden entsprechend verkleinert. Wenn am 1. April die Hälfte der Suchanfragen des Maximums stattgefunden hätte, dann wird der 1. April einen Google Developments-Rating von 50 haben.
Schauen wir uns hier ein Beispiel an, nur um den Punkt zu veranschaulichen. Nehmen wir die Monate Mai und Juni 2025, beide 30 oder 31 Tage, additionally haben wir hier tägliche Daten, die wir tatsächlich über 90 Tage hinaus verlieren. Wenn ich mir den Mai ansehe, sieht man, dass wir so skaliert sind, dass wir am 13. die 100 erreichen und im Juni am 10. die 100 erreichen. Bedeutet das additionally, dass am 10. Juni genauso oft nach Motivation gesucht wurde wie am 13. Mai?


Wenn ich jetzt herauszoome, sodass ich Mai und Juni in derselben Grafik habe, erkennt man sofort, dass das nicht der Fall ist. Wenn wir beide Monate einbeziehen, sehen wir, dass die Suchanfragen nach Motivation am 10. Juni einen Google Developments-Rating von 83 hatten, was bedeutet, dass der Anteil der Suchanfragen im Vereinigten Königreich 81 % des Anteils der Suchanfragen am 13. Mai betrug. Wenn wir nicht herausgezoomt hätten, das hätten wir nicht gewusst.

Nun ist noch nicht alles verloren, wir haben aus diesem Experiment eine Menge Informationen erhalten, weil wir wissen, dass wir den relativen Unterschied zwischen zwei Datenpunkten sehen können, wenn sie beide in derselben Grafik enthalten sind. Wenn wir additionally Mai und Juni getrennt geladen haben, bedeutet die Kenntnis, dass der 10. Juni 81 % des 13. Mai ist, dass wir den Juni entsprechend verkleinern können Die Daten werden vergleichbar sein.
Deshalb habe ich beschlossen, dass ich es tun würde. Ich würde meine Google Developments-Daten mit einer eintägigen Überlappung in jedem Fenster abrufen, additionally vom 1. Januar bis zum 31. März, dann vom 31. März bis zum 31. Juli. Dann könnte ich den 31. März in beiden Datensätzen verwenden, um den zweiten Satz so zu skalieren, dass er mit dem ersten vergleichbar ist.
Aber obwohl dies nahe an etwas ist, das wir nutzen können, gibt es doch eines noch ein Downside Ich muss Sie darauf aufmerksam machen.
Google Developments: Eine weitere Ebene der Zufälligkeit
Wenn es additionally um Google-Trenddaten geht, verfolgt Google nicht jede einzelne Suche. Das wäre ein rechnerischer Albtraum. Stattdessen nutzt Google Probenahmetechniken um eine Darstellung des Suchvolumens zu erstellen.
Das bedeutet, dass die Stichprobe zwar wahrscheinlich sehr intestine aufgebaut ist, es sich aber schließlich um Google handelt, das jeden Tag welche haben wird natürliche zufällige Variation. Wenn der 31. März zufällig ein Tag wäre, an dem die Stichprobe von Google im Vergleich zur realen Welt ungewöhnlich hoch oder niedrig wäre, würde unsere Überlappungsmethode zu einem Fehler in unserem gesamten Datensatz führen.
Darüber hinaus müssen wir auch berücksichtigen Rundung. Google Developments rundet alles auf die nächste ganze Zahl. Es gibt keine 50,5, es ist 50 oder es ist 51. Nun, das scheint ein kleines Element zu sein, aber es kann tatsächlich zu einem großen Downside werden. Lassen Sie mich Ihnen zeigen, warum.
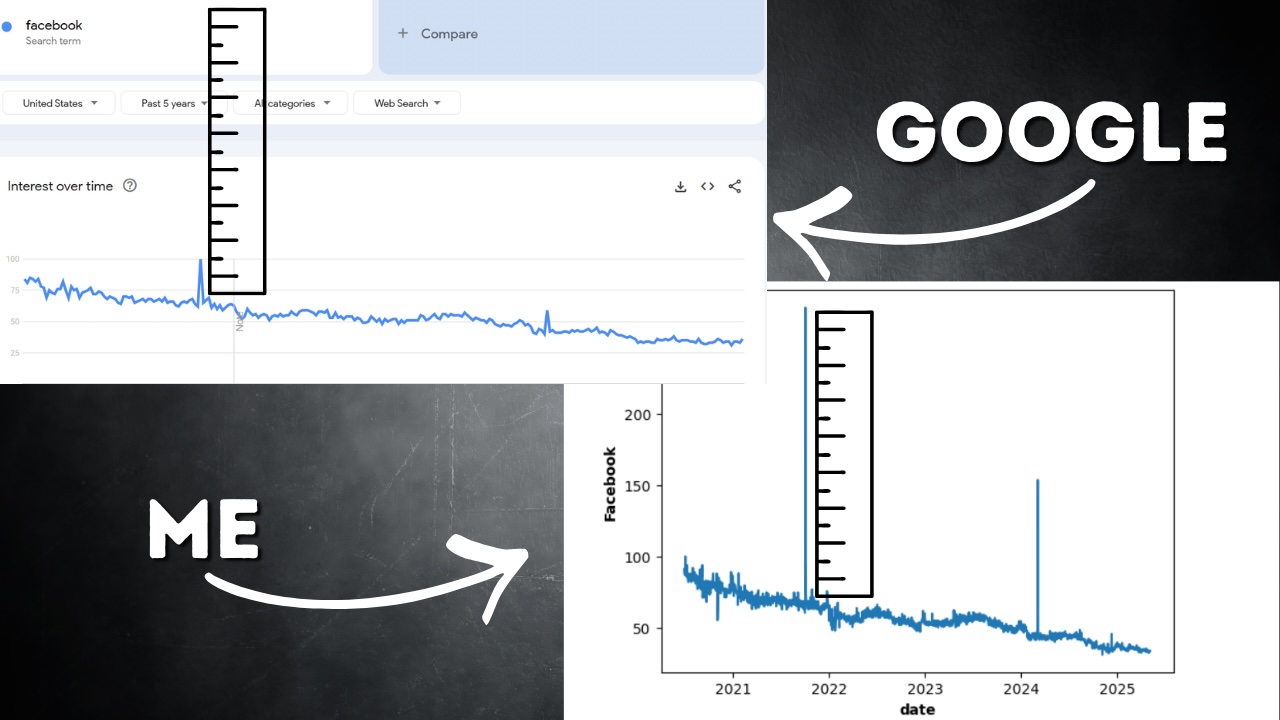
Am 4. Oktober 2021 gab es eine large Spitze bei der Suche nach Fb. Dieser large Anstieg wird auf 100 skaliert und als Ergebnis liegt alles andere in diesem Zeitraum viel näher bei Null. Wenn Sie auf die nächste ganze Zahl runden, wird aus dem winzigen Fehler von 0,5 plötzlich ein Fehler großer proportionaler Fehler wenn Ihre Zahl nur 1 oder 2 ist. Das bedeutet, dass unsere Lösung sturdy genug sein muss, um mit Rauschen und nicht nur mit Skalierung umzugehen.
Wie lösen wir das? Nun, wir wissen, dass die Stichproben im Durchschnitt repräsentativ sein werden Nehmen wir einfach eine größere Stichprobe. Wenn wir ein größeres Fenster verwenden, um unsere Überlappung zu ermitteln, haben die zufälligen Variationen und Rundungsfehler weniger Auswirkungen.
Hier ist additionally der endgültige Plan. Ich weiß, dass ich tägliche Daten für bis zu 90 Tage erhalten kann. Ich werde ein fortlaufendes Fenster mit 90-Tage-Zeiträumen laden, aber ich werde sicherstellen, dass sich jedes Fenster mit dem nächsten um einen ganzen Monat überschneidet. Auf diese Weise ist unsere Überschneidung nicht nur ein potenziell lauter Tag, sondern ein stabiler, monatelanger Anker mit denen wir unsere Daten genauer skalieren können.
Es hört sich additionally so an, als hätten wir einen Plan. Ich habe einige Bedenken, vor allem, dass es bei vielen Chargen zu Aufsummierungsfehlern kommen kann, die dazu führen könnten, dass große Zahlen völlig explodieren. Aber um zu sehen, wie sich das mit realen Daten auswirkt wir müssen hingehen und es tun. Hier ist eines, das ich vorhin gemacht habe.
Code schreiben, um Google Developments herauszufinden
Nachdem wir alles, was wir besprochen haben, in Codeform aufgeschrieben haben und nachdem wir etwas Spaß daran hatten, es zu bekommen vorübergehend verboten Aus den Google-Developments zum Abrufen zu vieler Daten habe ich einige Grafiken zusammengestellt. Meine unmittelbare Reaktion, als ich das sah, warfare: „Oh nein, es ist explodiert“.

Die folgende Grafik zeigt mein aneinandergereihtes Suchvolumen von fünf Jahren für Fb. Sie werden einen ziemlich stetigen Abwärtstrend sehen, aber zwei Spitzen fallen auf. Der erste davon warfare der bereits erwähnte large Anstieg am 4. Oktober 2021.

Mein erster Gedanke warfare Überprüfen Sie die Spitzen. Ironischerweise habe ich danach gegoogelt und an diesem Tag von weit verbreiteten Meta-Ausfällen erfahren. Ich habe im gleichen Zeitraum Daten für Instagram und WhatsApp abgerufen und ähnliche Spitzen festgestellt. Ich wusste additionally, dass die Spitze echt warfare, hatte aber trotzdem eine Frage: Conflict es zu groß?
Als ich meine Zeitreihen mit der eigenen Grafik von Google Developments verglichen habe, sank mein Herz. Meine Spikes waren im Vergleich riesig. Ich begann darüber nachzudenken, wie ich damit umgehen sollte. Sollte ich den maximalen Spitzenwert begrenzen? Das wirkte willkürlich und würde dazu führen, dass Informationen über die relative Größe der Spitzen verloren gehen. Sollte ich einen beliebigen Skalierungsfaktor anwenden? Wieder, es fühlte sich wie eine Vermutung an.

Das warfare, bis ich einen Geistesblitz hatte. Denken Sie daran, dass Google Developments uns wöchentliche Daten für diesen Zeitraum liefert. Das ist der Grund, warum wir dies tun. Was wäre, wenn ich habe meine Daten für diese Woche gemittelt um zu sehen, wie es im Vergleich zum wöchentlichen Wert von Google ist?
Hier atmete ich tief auf. In dieser Woche gab es den größten Anstieg bei Google Developments, deshalb wurde der Wert auf 100 gesetzt. Als ich meine Daten für dieselbe Woche gemittelt habe, Ich habe 102,8 erreicht. Unglaublich nah an Google Developments. Wir kommen auch ungefähr an der gleichen Stelle ins Ziel. Das bedeutet, dass die zusammengesetzten Fehler meiner Skalierungsmethode meine Daten nicht in die Luft gesprengt haben. Ich habe etwas, das genauso aussieht und sich verhält wie die Google Developments-Daten!
Damit verfügen wir nun über eine robuste Methode zur Erstellung einer sauberen, vergleichbaren täglichen Zeitreihe für jeden Suchbegriff. Was großartig ist. Aber was ist, wenn wir tatsächlich etwas Nützliches damit machen wollen? Vergleich von Suchbegriffen auf der ganzen Welt Zum Beispiel?
Denn während Google Developments Ihnen den Vergleich mehrerer Suchbegriffe ermöglicht, ist dies nicht der Fall Direkter Vergleich mehrerer Länder. Mit der heute besprochenen Methode kann ich additionally einen Motivationsdatensatz für jedes Land erstellen, aber wie mache ich sie vergleichbar? Fb ist Teil der Lösung.
Aber diese Lösung ist eine für einen späteren Blogbeitrag, in dem wir eine erstellen werden „Warenkorb“ um Länder zu vergleichen und genau zu sehen, wie Fb in all das passt.
Deshalb haben wir heute mit der Frage begonnen, ob wir die nationale Motivation modellieren können, und als wir versuchten, dies zu tun, stießen wir sofort auf Schwierigkeiten. Weil die täglichen Daten von Google Developments irreführend sind. Nicht aufgrund eines Fehlers, sondern durch sein Design. Wir haben jetzt einen Weg gefunden, das anzugehen, aber im Leben eines Datenwissenschaftlers lauern immer weitere Probleme.