
Nach einem Jahrzehnt Erfahrung in der Analytik bin ich fest davon überzeugt, dass Beobachtbarkeit und Auswertung für jede LLM-Anwendung, die in der Produktion läuft, von wesentlicher Bedeutung sind. Überwachung und Metriken sind nicht nur nette Dinge. Sie stellen sicher, dass Ihr Produkt wie erwartet funktioniert und dass jedes neue Replace Sie tatsächlich in die richtige Richtung bringt.
In diesem Artikel möchte ich meine Erfahrungen mit den Beobachtbarkeits- und Auswertungsfunktionen des NeMo Agent Toolkit (NAT) teilen. Falls Sie es nicht gelesen haben mein vorheriger Artikel Zum Thema NAT hier eine kurze Auffrischung: NAT ist Nvidias Framework zum Erstellen produktionsbereiter LLM-Anwendungen. Betrachten Sie es als den Klebstoff, der LLMs, Instruments und Arbeitsabläufe verbindet und gleichzeitig Bereitstellungs- und Observability-Optionen bietet.
Mithilfe von NAT haben wir einen Happiness Agent entwickelt, der in der Lage ist, differenzierte Fragen zu beantworten die Daten des World Happiness-Berichts und Durchführung von Berechnungen basierend auf realen Metriken. Unser Schwerpunkt lag auf dem Aufbau von Agentenflüssen, der Integration von Agenten aus anderen Frameworks als Instruments (in unserem Beispiel ein LangGraph-basierter Rechneragent) und der Bereitstellung der Anwendung sowohl als REST-API als auch als benutzerfreundliche Schnittstelle.
In diesem Artikel gehe ich auf meine Lieblingsthemen ein: Beobachtbarkeit und Bewertungen. Denn wie heißt es so schön: Was man nicht misst, kann man nicht verbessern. Additionally, ohne weitere Umschweife, lasst uns einsteigen.
Beobachtbarkeit
Beginnen wir mit der Beobachtbarkeit – der Fähigkeit, zu verfolgen, was in Ihrer Anwendung passiert, einschließlich aller Zwischenschritte, verwendeten Instruments, Zeitabläufe und Token-Nutzung. Das NeMo Agent Toolkit lässt sich in eine Vielzahl von Observability-Instruments wie Phoenix, W&B Weave und Catalyst integrieren. Sie können jederzeit die neueste Liste der unterstützten Frameworks einsehen die Dokumentation.
Für diesen Artikel probieren wir Phoenix aus. Phönix ist eine Open-Supply-Plattform zur Verfolgung und Bewertung von LLMs. Bevor wir es verwenden können, müssen wir zunächst das Plugin installieren.
uv pip set up arize-phoenix
uv pip set up "nvidia-nat(phoenix)"Als nächstes können wir den Phoenix-Server starten.
phoenix serverSobald es läuft, ist der Suchdienst unter verfügbar http://localhost:6006/v1/traces. An dieser Stelle sehen Sie ein Standardprojekt, da wir noch keine Daten gesendet haben.
Da der Phoenix-Server nun läuft, wollen wir sehen, wie wir ihn verwenden können. Da NAT auf der YAML-Konfiguration basiert, müssen wir unserer Konfiguration lediglich einen Telemetrieabschnitt hinzufügen. Die Konfiguration und die vollständige Agentenimplementierung finden Sie unter GitHub. Wenn Sie mehr über das NAT-Framework erfahren möchten, schauen Sie hier mein vorheriger Artikel.
basic:
telemetry:
tracing:
phoenix:
_type: phoenix
endpoint: http://localhost:6006/v1/traces
undertaking: happiness_reportWenn dies erledigt ist, können wir unseren Agenten betreiben.
export ANTHROPIC_API_KEY=<your_key>
supply .venv_nat_uv/bin/activate
cd happiness_v3
uv pip set up -e .
cd ..
nat run
--config_file happiness_v3/src/happiness_v3/configs/config.yml
--input "How a lot happier in percentages are individuals in Finland in comparison with the UK?"Lassen Sie uns noch ein paar Abfragen durchführen, um zu sehen, welche Artwork von Daten Phoenix verfolgen kann.
nat run
--config_file happiness_v3/src/happiness_v3/configs/config.yml
--input "Are individuals general getting happier over time?"
nat run
--config_file happiness_v3/src/happiness_v3/configs/config.yml
--input "Is Switzerland on the primary place?"
nat run
--config_file happiness_v3/src/happiness_v3/configs/config.yml
--input "What's the important contibutor to the happiness in the UK?"
nat run
--config_file happiness_v3/src/happiness_v3/configs/config.yml
--input "Are individuals in France happier than in Germany?"Nachdem Sie diese Abfragen ausgeführt haben, werden Sie ein neues Projekt in Phoenix bemerken (happiness_reportwie wir in der Konfiguration definiert haben) zusammen mit allen LLM-Aufrufen, die wir gerade durchgeführt haben. Dadurch haben Sie einen klaren Überblick darüber, was unter der Haube passiert.
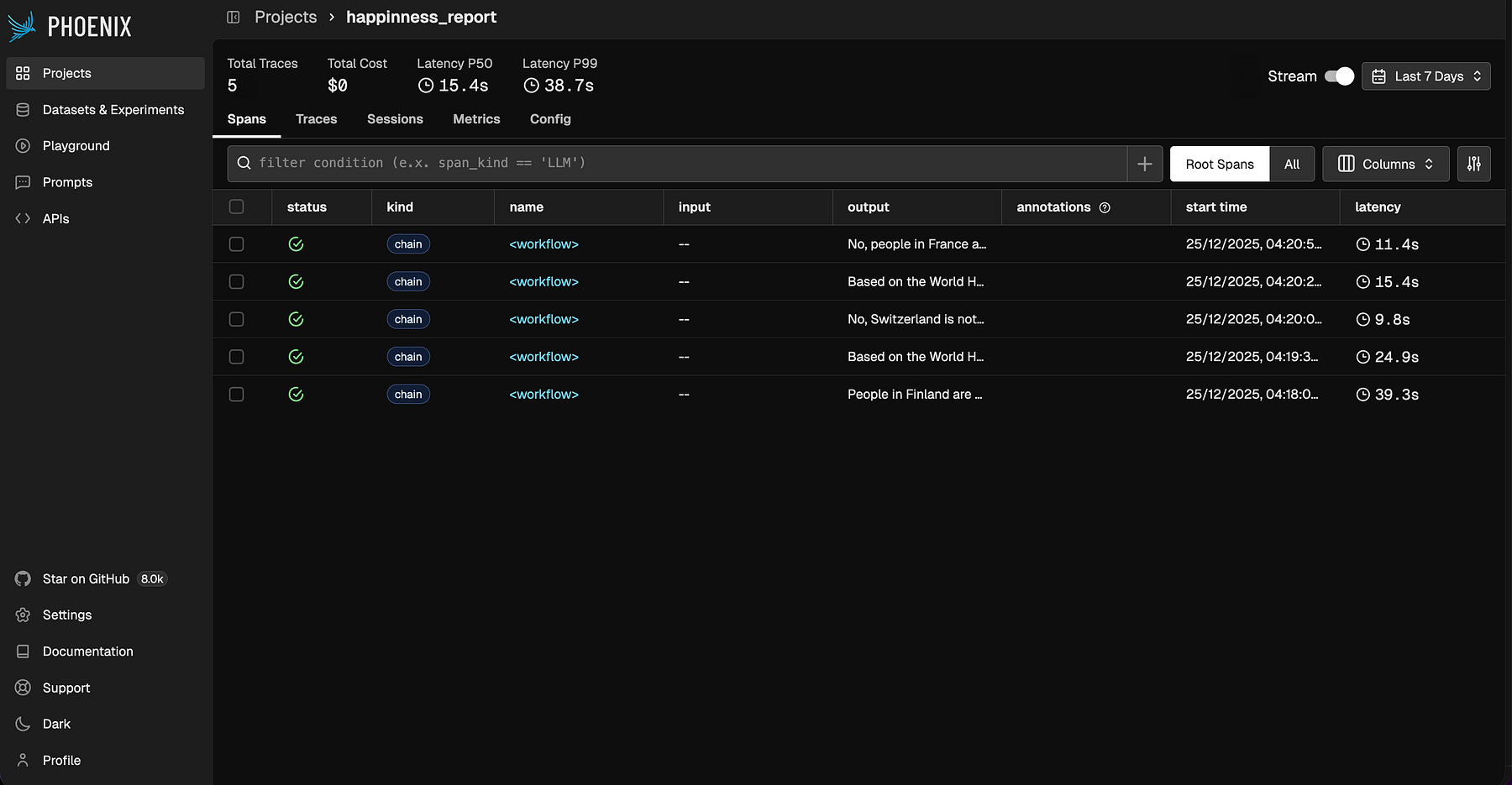
Wir können eine der Abfragen vergrößern, z „Werden die Menschen mit der Zeit insgesamt glücklicher?“

Diese Abfrage dauert ziemlich lange (ca. 25 Sekunden), da sie fünf Software-Aufrufe professional Jahr erfordert. Wenn wir viele ähnliche Fragen zu allgemeinen Traits erwarten, kann es sinnvoll sein, unserem Agenten ein neues Software zur Verfügung zu stellen, mit dem er zusammenfassende Statistiken auf einmal berechnen kann.
Genau hier kommt die Beobachtbarkeit zum Tragen: Indem sie Engpässe und Ineffizienzen aufdeckt, hilft sie Ihnen, Kosten zu senken und den Benutzern ein reibungsloseres Erlebnis zu bieten.
Bewertungen
Bei der Beobachtbarkeit geht es darum, zu verfolgen, wie Ihre Anwendung in der Produktion funktioniert. Diese Informationen sind hilfreich, reichen jedoch nicht aus, um zu sagen, ob die Qualität der Antworten intestine genug ist oder ob eine neue Model eine bessere Leistung erbringt. Um solche Fragen zu beantworten, brauchen wir Auswertungen. Glücklicherweise ist das mit dem NeMo Agent Toolkit möglich helfen uns auch mit Evals.
Lassen Sie uns zunächst einen kleinen Satz an Auswertungen zusammenstellen. Wir müssen nur drei Felder angeben: ID, Frage und Antwort.
(
{
"id": "1",
"query": "In what nation was the happiness rating highest in 2021?",
"reply": "Finland"
},
{
"id": "2",
"query": "What contributed most to the happiness rating in 2024?",
"reply": "Social Help"
},
{
"id": "3",
"query": "How UK's rank modified from 2019 to 2024?",
"reply": "The UK's rank dropped from thirteenth in 2019 to twenty third in 2024."
},
{
"id": "4",
"query": "Are individuals in France happier than in Germany primarily based on the most recent report?",
"reply": "No, Germany is at twenty second place in 2024 whereas France is at thirty third place."
},
{
"id": "5",
"query": "How a lot in percents are individuals in Poland happier in 2024 in comparison with 2019?",
"reply": "Happiness in Poland elevated by 7.9% from 2019 to 2024. It was 6.1863 in 2019 and 6.6730 in 2024."
}
)Als Nächstes müssen wir unsere YAML-Konfiguration aktualisieren, um zu definieren, wo die Bewertungsergebnisse gespeichert werden und wo der Bewertungsdatensatz zu finden ist. Ich habe eine eigene eingerichtet eval_llm zu Evaluierungszwecken, um die Lösung modular zu halten, und ich verwende Sonnet 4.5 dafür.
# Analysis configuration
eval:
basic:
output:
dir: ./tmp/nat/happiness_v3/eval/evals/
cleanup: false
dataset:
_type: json
file_path: src/happiness_v3/information/evals.json
evaluators:
answer_accuracy:
_type: ragas
metric: AnswerAccuracy
llm_name: eval_llm
groundedness:
_type: ragas
metric: ResponseGroundedness
llm_name: eval_llm
trajectory_accuracy:
_type: trajectory
llm_name: eval_llmIch habe hier mehrere Bewerter definiert. Wir werden uns auf Antwortgenauigkeit und Antworterdetheit konzentrieren Ragas (ein Open-Supply-Framework zur Finish-to-Finish-Bewertung von LLM-Workflows) sowie zur Trajektorienbewertung. Lassen Sie uns sie aufschlüsseln.
Antwortgenauigkeit misst, wie intestine die Reaktion eines Modells mit einer Referenzgrundwahrheit übereinstimmt. Es verwendet zwei „LLM-as-a-Choose“-Eingabeaufforderungen, die jeweils eine Bewertung von 0, 2 oder 4 zurückgeben. Diese Bewertungen werden dann in eine (0,1)-Skala umgewandelt und gemittelt. Höhere Werte weisen darauf hin, dass die Antwort des Modells weitgehend mit der Referenz übereinstimmt.
- 0 → Die Antwort ist ungenau oder nicht zum Thema gehörend.
- 2 → Antwort stimmt teilweise überein,
- 4 → Antwort stimmt genau überein.
Reaktionsgeerdetheit wertet aus, ob eine Antwort von den abgerufenen Kontexten unterstützt wird. Das heißt, ob jeder Anspruch (vollständig oder teilweise) in den bereitgestellten Daten zu finden ist. Dies funktioniert ähnlich wie die Antwortgenauigkeit, wobei zwei unterschiedliche „LLM-as-a-Choose“-Eingabeaufforderungen mit Bewertungen von 0, 1 oder 2 verwendet werden, die dann auf eine Skala (0,1) normiert werden.
- 0 → Überhaupt nicht geerdet,
- 1 → Teilweise geerdet,
- 2 → Vollständig geerdet.
Flugbahnbewertung Verfolgt die vom LLM ausgeführten Zwischenschritte und Toolaufrufe und hilft so, den Argumentationsprozess zu überwachen. Ein LLM-Richter bewertet die durch den Arbeitsablauf erzeugte Flugbahn unter Berücksichtigung der bei der Ausführung verwendeten Werkzeuge. Es wird ein Gleitkommawert zwischen 0 und 1 zurückgegeben, wobei 1 eine perfekte Flugbahn darstellt.
Lassen Sie uns Auswertungen durchführen, um zu sehen, wie es in der Praxis funktioniert.
nat eval --config_file src/happiness_v3/configs/config.ymlAls Ergebnis der Ausführung der Auswertungen erhalten wir mehrere Dateien in dem zuvor angegebenen Ausgabeverzeichnis. Eines der nützlichsten ist workflow_output.json. Diese Datei enthält Ausführungsergebnisse für jedes Beispiel in unserem Bewertungssatz, einschließlich der ursprünglichen Frage, der vom LLM generierten Antwort, der erwarteten Antwort und einer detaillierten Aufschlüsselung aller Zwischenschritte. Mithilfe dieser Datei können Sie nachvollziehen, wie das System jeweils funktionierte.
Hier ist ein gekürztes Beispiel für das erste Beispiel.
{
"id": 1,
"query": "In what nation was the happiness rating highest in 2021?",
"reply": "Finland",
"generated_answer": "Finland had the very best happiness rating in 2021 with a rating of seven.821.",
"intermediate_steps": (...),
"expected_intermediate_steps": ()
}Für Antwortgenauigkeit und Antworterdung haben wir die höchstmögliche Punktzahl erreicht (durchschnittlich 1,0 von 1,0), was immer wieder schön zu sehen ist. Hier ist die zurückgegebene Datei.
{
"average_score": 1.0,
"eval_output_items": (
{
"id": 1,
"rating": 1.0,
"reasoning": {
"user_input": "In what nation was the happiness rating highest in 2021?",
"reference": "Finland",
"response": "Finland had the very best happiness rating in 2021 with a rating of seven.821.",
"retrieved_contexts": (...)
}
},
{
"id": 2,
"rating": 1.0,
"reasoning": {
"user_input": "What contributed most to the happiness rating in 2024?",
"reference": "Social Help",
"response": "In 2024, **Social Help** contributed most to the happiness rating, with a median affect of 1.333 factors. This was adopted very intently by **GDP per capita** with an affect of 1.319 factors. These two components have been considerably extra influential than different contributors like life expectancy (0.551), freedom (0.749), generosity (0.113), and perceptions of corruption (0.147). This means that having robust social connections and relationships, together with financial prosperity, have been the first drivers of happiness throughout international locations in 2024.",
"retrieved_contexts": (...)
}
},
{
"id": 3,
"rating": 1.0,
"reasoning": {
"user_input": "How UK's rank modified from 2019 to 2024?",
"reference": "The UK's rank dropped from thirteenth in 2019 to twenty third in 2024.",
"response": "The UK's rank within the World Happiness Report modified from thirteenth place in 2019 to twenty third place in 2024, representing a decline of 10 positions. The happiness rating additionally decreased from 7.1645 in 2019 to six.7280 in 2024.",
"retrieved_contexts": (...)
}
},
{
"id": 4,
"rating": 1.0,
"reasoning": {
"user_input": "Are individuals in France happier than in Germany primarily based on the most recent report?",
"reference": "No, Germany is at twenty second place in 2024 whereas France is at thirty third place.",
"response": "Based mostly on the most recent 2024 World Happiness Report, individuals in Germany are happier than individuals in France. Germany has a happiness rating of 6.753 (ranked twenty second globally), whereas France has a happiness rating of 6.593 (ranked thirty third globally). The distinction is 0.16 factors in Germany's favor.",
"retrieved_contexts": (...)
}
},
{
"id": 5,
"rating": 1.0,
"reasoning": {
"user_input": "How a lot in percents are individuals in Poland happier in 2024 in comparison with 2019?",
"reference": "Happiness in Poland elevated by 7.9% from 2019 to 2024. It was 6.1863 in 2019 and 6.6730 in 2024.",
"response": "Folks in Poland are roughly 7.87% happier in 2024 in comparison with 2019. The happiness rating elevated from 6.1863 in 2019 to six.6730 in 2024, representing a rise of 0.4867 factors or about 7.87%.",
"retrieved_contexts": (...)
}
}
)
}Bei der Flugbahnbewertung erreichten wir einen Durchschnittswert von 0,95. Um zu verstehen, wo das Modell zu kurz kam, schauen wir uns ein nicht ideales Beispiel an. Bei der fünften Frage stellte der Richter richtig fest, dass der Agent einen suboptimalen Weg eingeschlagen hatte: Es waren 8 Schritte erforderlich, um zur endgültigen Antwort zu gelangen, obwohl das gleiche Ergebnis in 4–5 Schritten hätte erreicht werden können. Als Ergebnis erhielt diese Flugbahn eine Bewertung von 0,75 von 1,0.
Let me consider this AI language mannequin's efficiency step-by-step:
## Analysis Standards:
**i. Is the ultimate reply useful?**
Sure, the ultimate reply is evident, correct, and straight addresses the query.
It gives each the proportion enhance (7.87%) and explains the underlying
information (happiness scores from 6.1863 to six.6730). The reply is well-formatted
and simple to know.
**ii. Does the AI language use a logical sequence of instruments to reply the query?**
Sure, the sequence is logical:
1. Question nation statistics for Poland
2. Retrieve the information exhibiting happiness scores for a number of years together with
2019 and 2024
3. Use a calculator to compute the proportion enhance
4. Formulate the ultimate reply
This can be a wise strategy to the issue.
**iii. Does the AI language mannequin use the instruments in a useful means?**
Sure, the instruments are used appropriately:
- The `country_stats` software efficiently retrieved the related happiness information
- The `calculator_agent` appropriately computed the proportion enhance utilizing
the correct components
- The Python analysis software carried out the precise calculation precisely
**iv. Does the AI language mannequin use too many steps to reply the query?**
That is the place there's some inefficiency. The mannequin makes use of 8 steps whole, which
contains some redundancy:
- Steps 4-7 seem to contain a number of calls to calculate the identical share
(the calculator_agent is invoked, which then calls Claude Opus, which calls
evaluate_python, and returns via the chain)
- Step 7 appears to repeat what was already performed in steps 4-6
Whereas the reply is right, there's pointless duplication. The calculation
may have been performed extra effectively in 4-5 steps as a substitute of 8.
**v. Are the suitable instruments used to reply the query?**
Sure, the instruments chosen are acceptable:
- `country_stats` was the correct software to get happiness information for Poland
- `calculator_agent` was acceptable for computing the proportion change
- The underlying `evaluate_python` software appropriately carried out the mathematical
calculation
## Abstract:
The mannequin efficiently answered the query with correct information and proper
calculations. The logical move was sound, and acceptable instruments have been chosen.
Nonetheless, there was some inefficiency within the execution with redundant steps
within the calculation section.Betrachtet man die Begründung, so stellt sich heraus, dass es sich um eine überraschend umfassende Bewertung des gesamten LLM-Workflows handelt. Besonders wertvoll ist, dass es sofort einsatzbereit ist und keine Floor-Reality-Daten erfordert. Ich würde Ihnen auf jeden Fall empfehlen, diese Auswertung für Ihre Bewerbungen zu verwenden.
Vergleich verschiedener Versionen
Besonders aussagekräftig sind Auswertungen, wenn Sie verschiedene Versionen Ihrer Anwendung vergleichen müssen. Stellen Sie sich ein Group vor, das sich auf die Kostenoptimierung konzentriert und einen Wechsel vom teureren System in Betracht zieht sonnet Modell zu haiku. Mit NAT dauert die Änderung des Modells weniger als eine Minute, aber ohne Qualitätsvalidierung wäre es riskant. Genau hier glänzen Bewertungen.
Für diesen Vergleich stellen wir auch ein weiteres Observability-Software vor: W&B Weave. Es bietet besonders praktische Visualisierungen und direkte Vergleiche zwischen verschiedenen Versionen Ihres Workflows.
Um zu beginnen, müssen Sie sich anmelden der W&B-Web site und erhalten Sie einen API-Schlüssel. W&B ist frei für persönliche Projekte zu verwenden.
export WANDB_API_KEY=<your key>Als nächstes installieren Sie die erforderlichen Pakete und Plugins.
uv pip set up wandb weave
uv pip set up "nvidia-nat(weave)"Wir müssen auch unsere YAML-Konfiguration aktualisieren. Dazu gehört das Hinzufügen von Weave zum Telemetrieabschnitt und die Einführung eines Workflow-Alias, damit wir klar zwischen verschiedenen Versionen der Anwendung unterscheiden können.
basic:
telemetry:
tracing:
phoenix:
_type: phoenix
endpoint: http://localhost:6006/v1/traces
undertaking: happiness_report
weave: # specified Weave
_type: weave
undertaking: "nat-simple"
eval:
basic:
workflow_alias: "nat-simple-sonnet-4-5" # added alias
output:
dir: ./.tmp/nat/happiness_v3/eval/evals/
cleanup: false
dataset:
_type: json
file_path: src/happiness_v3/information/evals.json
evaluators:
answer_accuracy:
_type: ragas
metric: AnswerAccuracy
llm_name: chat_llm
groundedness:
_type: ragas
metric: ResponseGroundedness
llm_name: chat_llm
trajectory_accuracy:
_type: trajectory
llm_name: chat_llmFür die haiku Model, die ich erstellt habe eine separate Konfiguration wo beides chat_llm Und calculator_llm verwenden haiku anstatt sonnet.
Jetzt können wir Auswertungen für beide Versionen durchführen.
nat eval --config_file src/happiness_v3/configs/config.yml
nat eval --config_file src/happiness_v3/configs/config_simple.ymlSobald die Bewertungen abgeschlossen sind, können wir zur W&B-Oberfläche gehen und einen umfassenden Vergleichsbericht einsehen. Die Visualisierung des Radardiagramms gefällt mir sehr intestine, da sie Kompromisse sofort deutlich macht.
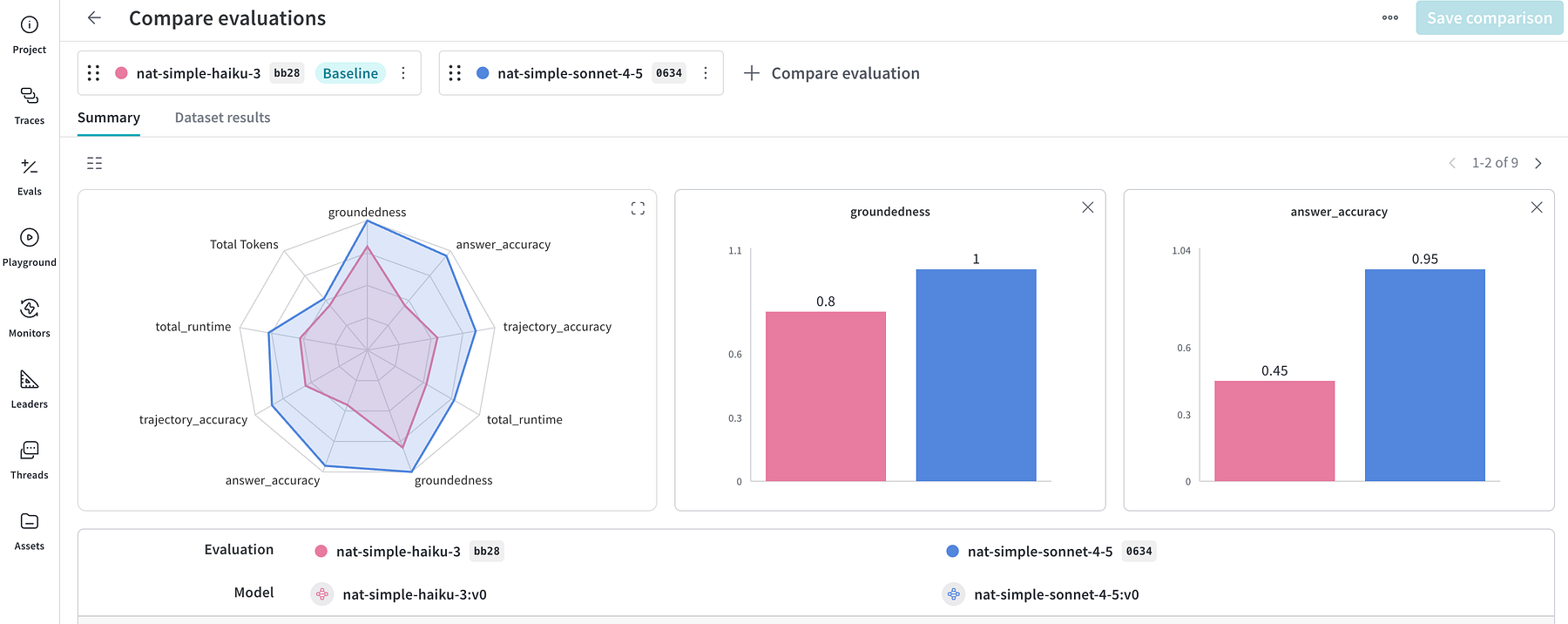

Mit sonnetbeobachten wir eine höhere Token-Nutzung (und höhere Kosten professional Token) sowie langsamere Antwortzeiten (24,8 Sekunden im Vergleich zu 16,9 Sekunden für haiku). Trotz der deutlichen Geschwindigkeits- und Kostenvorteile würde ich jedoch keinen Modellwechsel empfehlen. Der Qualitätsabfall ist zu groß: Die Flugbahngenauigkeit sinkt von 0,85 auf 0,55 und die Antwortgenauigkeit sinkt von 0,95 auf 0,45. In diesem Fall haben uns die Bewertungen dabei geholfen, eine Beeinträchtigung der Benutzererfahrung im Streben nach Kostenoptimierung zu vermeiden.
Die vollständige Implementierung finden Sie auf GitHub.
Zusammenfassung
In diesem Artikel haben wir die Beobachtbarkeits- und Auswertungsmöglichkeiten des NeMo Agent Toolkits untersucht.
- Wir haben mit zwei Observability-Instruments (Phoenix und W&B Weave) gearbeitet, die sich beide nahtlos in NAT integrieren und es uns ermöglichen, zu protokollieren, was in unserem System in der Produktion passiert, sowie Auswertungsergebnisse zu erfassen.
- Außerdem haben wir erklärt, wie man Auswertungen in NAT konfiguriert, und mit W&B Weave die Leistung zweier verschiedener Versionen derselben Anwendung verglichen. Dies machte es einfach, über Kompromisse zwischen Kosten, Latenz und Antwortqualität nachzudenken.
Das NeMo Agent Toolkit liefert solide, produktionsreife Lösungen für Beobachtbarkeit und Auswertungen – grundlegende Bestandteile jeder ernsthaften LLM-Anwendung. Das Herausragende für mich warfare jedoch W&B Weave, dessen Bewertungsvisualisierungen den Vergleich von Modellen und Kompromisse bemerkenswert einfach machen.
Vielen Dank fürs Lesen. Ich hoffe, dieser Artikel warfare aufschlussreich. Erinnern Sie sich an Einsteins Rat: „Wichtig ist, nicht mit dem Hinterfragen aufzuhören. Neugier hat ihre eigene Daseinsberechtigung.“ Möge Ihre Neugier Sie zu Ihrer nächsten großen Erkenntnis führen.
Referenz
Dieser Artikel ist inspiriert von „Nvidias NeMo Agent Toolkit: Agenten zuverlässig machen“ Kurzkurs von DeepLearning.AI.