Intro
In diesem Projekt geht es darum, bessere Null-Shot zu bekommen Einstufung von Bildern und Textual content unter Verwendung von CV/LLM-Modellen, ohne Zeit und Geldgeist im Coaching zu verbringen oder Modelle in Folge neu zu leiten. Es verwendet eine neuartige Technik zur Dimensionalitätsreduktion bei Einbettungen und bestimmt Klassen mit dem paarigen Vergleich des Turnierstils. Dies führte zu einer Erhöhung der Textual content-/Bildvereinbarung von 61% auf 89% für einen 50k -Datensatz über 13 Klassen.
https://github.com/doc1000/pairwise_classification
Wo Sie es verwenden werden
Die praktische Anwendung befindet sich in groß angelegter Klassensuche, bei der die Geschwindigkeit der Inferenz wichtig ist und Modellkostenausgaben ein Downside sind. Es ist auch nützlich, um Fehler in Ihrem Annotationsprozess zu finden – Fehlklassifizierungen in einer großen Datenbank.
Ergebnisse
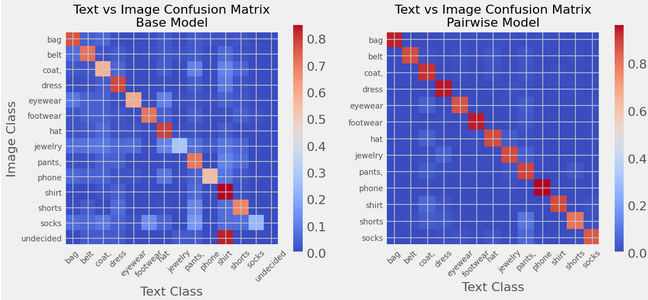
Die gewichtete F1 -Punktzahl, in der die Vereinbarung über die Textual content- und Bildklasse verglichen wurde, stieg für ~ 50.000 Elemente in 13 Klassen von 61% auf 88%. Eine visuelle Inspektion validierte auch die Ergebnisse.
| F1_score (gewichtet) | Basismodell | paarweise |
| Multiclas | 0,613 | 0,889 |
| Binär | 0,661 | 0,645 |

Hyperlinks: Foundation, Volleinbettung, Argmax auf Kosinusähnlichkeitsmodell
Recht
Bild des Autors
Methode: paarweise Vergleich der Kosinus-Ähnlichkeit von Einbettungsunterdimensionen, die durch mittlere Bewertung bestimmt werden
Ein einfacher Weg zur Vektorklassifizierung besteht darin, Bild-/Textual content -Einbettungen mit Klassenbettdings mithilfe von Cosinus -Ähnlichkeit zu vergleichen. Es ist relativ schnell und erfordert minimaler Gemeinkosten. Sie können auch ein Klassifizierungsmodell für die Einbettung (logistische Regressionen, Bäume, SVM) ausführen und die Klasse ohne weitere Einbettungen abzielen.
Mein Ansatz battle es, die Merkmalsgröße in den Einbettungen zu verringern, die feststellen, welche Merkmalsverteilungen zwischen zwei Klassen wesentlich unterschiedlich waren, und somit mit weniger Rauschen Informationen beigesteuert. Für Bewertungsfunktionen habe ich eine Varianzableitung verwendet, die zwei Verteilungen umfasst, die ich als Kreuzvarianz bezeichne (mehr unten). Ich habe dies verwendet, um wichtige Dimensionen für die Kategorie „Kleidung“ (ein-VS-The Relaxation) zu erhalten und unter Verwendung der Unterfunktionen erneut klassifiziert, die eine gewisse Verbesserung der Modellleistung zeigten. Der Sub-Characteristic-Vergleich zeigte jedoch bessere Ergebnisse beim Vergleich von Klassen paarweise (eins gegenüber einem/Kopf an Kopf). Ganz für Bilder und Textual content baute ich eine Array-weite ‚Turnierstil-Klammer mit paarweisen Vergleiche, bis eine endgültige Klasse für jedes Factor bestimmt wurde. Es ist ziemlich effizient. Ich habe dann die Vereinbarung zwischen den Textual content- und Bildklassifizierungen erzielt.
Verwenden von Cross -Varianz, kombinierte spezifische Characteristic -Auswahl und paarweise Turnierzuweisung.

Ich verwende eine Produktbilddatenbank, die mit vorbereiteten Clip-Einbettungen leicht verfügbar battle (danke SQID (unten zitiert. Dieser Datensatz wird unter der MIT -Lizenz veröffentlicht), Amzn (Unten zitiert. Dieser Datensatz ist unter Apache -Lizenz 2.0 lizenziert) und zielt auf die Kleidungsbilder ab, da ich diesen Effekt zum ersten Mal gesehen habe (danke DS -Crew bei Nordstrom). Der Datensatz wurde von 150K -Elementen/Bildern/Beschreibungen auf ~ 50K -Kleidungsstücke unter Verwendung von Null -Shot -Klassifizierung und dann die erweiterte Klassifizierung auf der Grundlage gezielter Unterarrays eingegrenzt.

Teststatistik: Quervarianz
Dies ist eine Methode, um zu bestimmen, wie unterschiedlich die Verteilung für zwei verschiedene Klassen ist, wenn sie auf eine einzelne Merkmal/Dimension abzielen. Es ist ein Maß für die kombinierte durchschnittliche Varianz, wenn jedes Factor beider Verteilungen in die andere Verteilung fallen gelassen wird. Es handelt sich um eine Erweiterung der Mathematik der Varianz/Standardabweichung, jedoch zwischen zwei Verteilungen (die unterschiedlich groß sind). Ich habe es noch nicht gesehen, obwohl es unter einem anderen Spitznamen aufgeführt sein kann.
Kreuzvarianz:

Ähnlich wie bei der Varianz, mit Ausnahme der Summierung beider Verteilungen und einer Differenz jedes Wertes anstelle des Mittelwerts der einzelnen Verteilung. Wenn Sie dieselbe Verteilung wie A und B eingeben, liefert es die gleichen Ergebnisse wie Varianz.
Dies vereinfacht:

Dies entspricht der alternativen Definition der Varianz (dem Mittelwert der Quadrate abzüglich des Quadrats des Mittelwerts) für eine einzige Verteilung, wenn die Verteilungen I und J gleich sind. Die Verwendung dieser Model ist massiv schneller und Speicher effizienter als der Versuch, die Arrays direkt zu übertragen. Ich werde den Beweis vorlegen und in einem anderen Artikel detaillierter eingehen. Kreuzabweichung (ς) ist die quadratische Wurzel von undefinierter.
Um Funktionen zu erzielen, verwende ich ein Verhältnis. Der Zähler ist eine Kreuzvarianz. Der Nenner ist das Produkt von IJ, wie der Nenner der Pearson -Korrelation. Dann nehme ich die Wurzel (ich könnte genauso leicht eine Kreuzvarianz verwenden, die direkter mit der Kovarianz verglichen würde, aber ich habe festgestellt, dass das Verhältnis mit Cross Dev kompakter und interpretierbarer ist).

Ich interpretiere dies als die erhöhte kombinierte Standardabweichung, wenn Sie Klassen für jedes Factor ausgetauscht haben. Eine große Zahl bedeutet, dass die Funktionsverteilung für die beiden Klassen wahrscheinlich sehr unterschiedlich ist.

Bild des Autors
Dies ist ein alternativer mittlerer Unterschied KS_test; Bayes’sche 2distische Assessments und die Entfernung von Frechet -Inception sind Alternativen. Ich magazine die Eleganz und Neuheit von Cross Var. Ich werde wahrscheinlich nachverfolgen, indem ich andere Unterscheidungsmerkmale betrachte. Ich sollte beachten, dass die Bestimmung der Verteilungsunterschiede für ein normalisiertes Merkmal mit insgesamtem Durchschnitt 0 und SD = 1 seine eigene Herausforderung ist.
Unterdimensionen: Dimensionalitätsreduzierung des Einbettungsraums zur Klassifizierung
Wenn Sie versuchen, eine zu finden besondere Benötigen Sie die gesamte Einbettung für ein Bild? Ist Farbe oder ob etwas ein Hemd oder ein Paar Hosen in einem schmalen Abschnitt der Einbettung ist? Wenn ich nach einem Hemd suche, ist es mir nicht unbedingt wichtig, ob es blau oder rot ist. Deshalb schaue ich mir nur die Dimensionen an, die ‚Hemd „definieren und die Dimensionen wegwerfen, die Farbe definieren.

Bild des Autors
Ich nehme eine dimensionale Einbettung (n, 768) ein und verengung es auf näher an 100 Dimensionen, die für ein bestimmtes Klassenpaar tatsächlich von Bedeutung sind. Warum? Da die Kosinus -Ähnlichkeitsmetrik (Cosim) durch das Lärm der relativ unwichtigen Merkmale beeinflusst wird. Die Einbettung enthält eine enorme Menge an Informationen, von denen Sie sich in einem Klassifizierungsproblem einfach nicht interessieren. Rauschen Sie das Rauschen los und das Sign wird stärker: Cosim erhöht sich mit der Beseitigung der „unwichtigen“ Dimensionen.

Bild des Autors
Für paarweise Vergleiche teilen erste Elemente in Klassen unter Verwendung einer Commonplace -Cosinus -Ähnlichkeit auf, die auf die vollständige Einbettung angewendet wird. Ich schließe einige Elemente aus, die sehr niedrig an der Annahme sind, dass die Modellkenntnis für diese Elemente gering ist (Cosim -Grenze). Ich schließe auch Elemente aus, die eine geringe Differenzierung zwischen den beiden Klassen (Cosim Diff) aufweisen. Das Ergebnis sind zwei Verteilungen, auf denen wichtige Dimensionen extrahieren können, die den „wahren“ Unterschied zwischen den Klassifizierungen definieren sollten:

Bild des Autors
Array paarweise Turnierklassifizierung
Eine globale Klassenzuweisung aus paarweisen Vergleichen herauszuholen, erfordert einige Gedanken. Sie können die angegebene Aufgabe annehmen und genau diese Klasse mit allen anderen vergleichen. Wenn die erste Aufgabe gute Fähigkeiten enthielt, sollte dies intestine funktionieren. Wenn jedoch mehrere different Klassen überlegen sind, stoßen Sie in Schwierigkeiten. Ein kartesischer Ansatz, bei dem Sie alle Vs vergleicht, würde Sie dorthin bringen, aber schnell groß werden. Ich entschied mich für eine Array-Extensive-Turnierklasse mit paarweisen Vergleiche.

Dies enthält log_2 (#Lessons) -Runden und die Gesamtzahl der Vergleiche bei Summation_round (Combo (#-Klasse in Runde)*n_items) über einige bestimmte Merkmale. Ich habe die Reihenfolge der „Groups“ in jeder Runde randomisiert, sodass die Vergleiche jedes Mal nicht gleich sind. Es hat ein Match -Up -Risiko, kommt aber schnell zu einem Gewinner. Es ist für eine Reihe von Vergleiche in jeder Runde erstellt, anstatt über Gegenstände zu iterieren.
Wertung
Schließlich habe ich den Prozess bewertet, indem ich feststellte, ob die Klassifizierung aus Textual content und Bildern übereinstimmt. Solange die Verteilung nicht stark in Richtung einer „Commonplace“ -Klasse übergewichtig ist (nicht), sollte dies eine gute Einschätzung sein, ob der Prozess echte Informationen aus den Einbettungen herauszieht.
Ich habe mir die gewichtete F1 -Punktzahl angesehen, in der die Klassen mit dem Bild mit der Textbeschreibung verglichen wurden. Die Annahme, desto besser ist die Einstufung, desto wahrscheinlicher ist die Klassifizierung. Für meinen Datensatz von ~ 50K-Bildern und Textbeschreibungen von Kleidung mit 13 Klassen stieg die Startbewertung des einfachen Vollmettierungs-Cosinus-Ähnlichkeitsmodells von 42% auf 55% für das Subfeatur-Cosim, auf 89% für das paarweise Modell mit Unterfunktionen. Eine visuelle Inspektion validierte auch die Ergebnisse. Die Binärklassifizierung battle nicht das Hauptziel-es battle größtenteils, ein Untersegment der Daten zu erhalten, um dann die Multi-Klasse-Boosting zu testen.
| Basismodell | paarweise | |
| Multiclas | 0,613 | 0,889 |
| Binär | 0,661 | 0,645 |

Bild des Autors

Bild vom Autor verwenden Code von NILS Flaschel
Letzte Gedanken…
Dies kann eine gute Methode sein, um Fehler in großen Untergruppen mit kommentierten Daten zu finden oder keine Schusskennzeichnung durchzuführen, ohne dass die zusätzliche GPU -Zeit für Feinabstimmungen und Trainingszeiten eingestellt werden. Es führt einige neuartige Bewertungen und Ansätze ein, aber der Gesamtprozess ist nicht übermäßig kompliziert oder CPU/GPU/Speicherintensiv.
Nachfolger wird es auf andere Bild-/Textdatensätze sowie an kommentierte/kategorisierte Bild- oder Textdatensätze angewendet, um festzustellen, ob die Bewertung gesteigert wird. Darüber hinaus wäre es interessant zu bestimmen, ob sich der Anstieg der Klassifizierung von Zero Shot für diesen Datensatz erheblich ändert, wenn:
- Andere Bewertungsmetriken werden anstelle des Querabweichungsverhältnisses verwendet
- Einbettungen für vollständige Merkmale werden durch gezielte Merkmale ersetzt
- Das paarweise Turnier wird durch einen anderen Ansatz ersetzt
Ich hoffe, Sie finden es nützlich.
Zitate
@article{reddy2022shopping,title={Procuring Queries Dataset: A Giant-Scale {ESCI} Benchmark for Bettering Product Search},creator={Chandan Ok. Reddy and Lluís Màrquez and Fran Valero and Nikhil Rao and Hugo Zaragoza and Sambaran Bandyopadhyay and Arnab Biswas and Anlu Xing and Karthik Subbian}, Jahr = {2022}, ePrint = {2206.06588}, archiveprefix = {arxiv}}
Procuring-Abfragen Bilddatensatz (SQID): Ein im Bild angereicherter Esci-Datensatz zum Erkunden Multimodales Lernen In Product Search, M. Al Ghossein, CW Chen, J. Tang