Einführung
Anwendungen, die auf Giant Language Fashions (LLMs) basieren, erfordern die Integration mit externen Diensten, beispielsweise die Integration mit Google Kalender zum Einrichten von Besprechungen oder die Integration mit PostgreSQL, um Zugriff auf einige Daten zu erhalten.
Funktionsaufruf
Ursprünglich wurden diese Arten von Integrationen durch Funktionsaufrufe implementiert: Wir erstellten einige spezielle Funktionen, die von einem LLM über bestimmte Token aufgerufen werden können (LLM generierte einige spezielle Token zum Aufrufen der Funktion gemäß den von uns definierten Mustern), Analyse und Ausführung. Damit es funktioniert, haben wir für jedes der Instruments Autorisierungs- und API-Aufrufmethoden implementiert. Wichtig conflict, dass wir alle Anweisungen für den Aufruf dieser Instruments verwalten und die interne Logik dieser Funktionen einschließlich Normal- oder benutzerspezifischer Parameter erstellen mussten. Doch der Hype um „KI“ erforderte schnelle, manchmal brutale Lösungen, um Schritt zu halten, und so wurden MCPs von der Firma Anthropic eingeführt.
MCPs
MCP steht für Mannequin Context Protocol und ist heute eine Standardmethode zur Bereitstellung von Instruments für die meisten Agenten-Pipelines. MCPs verwalten grundsätzlich sowohl Integrationsfunktionen als auch LLM-Anweisungen zur Verwendung von Instruments. An dieser Stelle mögen einige argumentieren, dass Fähigkeiten und Codeausführung, die kürzlich auch von Anthropic eingeführt wurden, MCPs getötet haben, aber tatsächlich neigen diese Funktionen auch dazu, MCPs für die Integration und Befehlsverwaltung zu verwenden (Codeausführung mit MCP – Anthropic). Fähigkeiten und Codeausführung konzentrieren sich auf das Kontextmanagementproblem und die Device-Orchestrierung, das ist ein anderes Drawback als das, was MCPs sind konzentriert.
MCPs bieten eine Standardmethode zur Integration verschiedener Dienste (Instruments) in LLMs und stellen außerdem Anweisungen bereit, die LLMs zum Aufrufen der Instruments verwenden. Allerdings gibt es hier ein paar Probleme:
- Das aktuelle Modellkontextprotokoll geht davon aus, dass alle Werkzeugaufrufparameter dem LLM zugänglich gemacht werden und alle ihre Werte vom LLM generiert werden sollen. Das bedeutet beispielsweise, dass der LLM einen Benutzer-ID-Wert generieren muss, wenn der Funktionsaufruf dies erfordert. Das ist ein Mehraufwand, da das System und die Anwendung den Benutzer-ID-Wert kennen, ohne dass LLM ihn generieren muss. Darüber hinaus müssen wir ihn an die Eingabeaufforderung senden, um LLM über den Benutzer-ID-Wert zu informieren (in FastMCP gibt es einen Ansatz zum „Ausblenden von Argumenten“) gofastmcp das sich speziell auf dieses Drawback konzentriert, aber ich habe es in der ursprünglichen MCP-Implementierung von Anthropic nicht gesehen).
- Keine sofort einsatzbereite Kontrolle über Anweisungen. MCPs stellen eine Beschreibung für jedes Device und eine Beschreibung für jedes Argument eines Instruments bereit, sodass diese Werte in den Agentenpipelines einfach blind als LLM-API-Aufrufparameter verwendet werden. Und die Beschreibung wird von den einzelnen MCP-Serverentwicklern bereitgestellt.
Systemaufforderung und Instruments
Wenn Sie LLMs aufrufen, stellen Sie dem LLM-Aufruf normalerweise Instruments als API-Aufrufparameter zur Verfügung. Der Wert dieses Parameters wird von der list_tools-Funktion des MCP abgerufen, die das JSON-Schema für die vorhandenen Instruments zurückgibt.
Gleichzeitig wird dieser „Instruments“-Parameter verwendet, um der Systemeingabeaufforderung des Modells zusätzliche Informationen hinzuzufügen. Zum Beispiel hat das Qwen3-VL-Modell chat_template Das verwaltet das Einfügen von Werkzeugen in die Systemaufforderung auf folgende Weise:
“...You might be supplied with perform signatures inside <instruments></instruments> XML tags:n<instruments>" }}n {%- for software in instruments %}n {{- "n" }}n { tojson }n {%- endfor %}...”Die Werkzeugbeschreibungen landen additionally in der Systemeingabeaufforderung des LLM, das Sie aufrufen.
Das erste Drawback wird tatsächlich teilweise durch den erwähnten Ansatz „Argumente ausblenden“ von FastMCP gelöst, aber ich habe dennoch einige Lösungen gesehen, bei denen Werte wie „Benutzer-ID“ an die Systemeingabeaufforderung des Modells gesendet wurden, um sie beim Aufrufen des Instruments zu verwenden – es ist aus technischer Sicht einfach schneller und viel einfacher zu implementieren (eigentlich ist keine technische Planung erforderlich, um sie einfach an die Systemeingabeaufforderung zu stellen und sich auf ein LLM zu verlassen, um sie zu verwenden). Hier konzentriere ich mich additionally auf das zweite Drawback.
Gleichzeitig lasse ich die Probleme beiseite, die mit Unmengen von MCPs auf dem Markt verbunden sind – einige von ihnen funktionieren nicht, andere haben Werkzeugbeschreibungen generiert, die für das Modell verwirrend sein können. Das Drawback, auf das ich mich hier konzentriere, sind nicht standardisierte Instruments und ihre Parameterbeschreibungen, die der Grund dafür sein können, dass sich LLMs mit einigen Instruments schlecht verhalten.
Anstelle des Fazits zum Einleitungsteil:
Wenn Ihre Agent-LLM-gestützte Pipeline mit den Ihnen zur Verfügung stehenden Instruments ausfällt, können Sie Folgendes tun:
- Wählen Sie einfach eine leistungsfähigere, modernere und teurere LLM-API.
- Überprüfen Sie Ihre Werkzeuge und die Anweisungen insgesamt noch einmal.
Beides kann funktionieren. Treffen Sie Ihre Entscheidung oder bitten Sie Ihren KI-Assistenten, eine Entscheidung für Sie zu treffen …
Formaler Teil der Arbeit – Forschung
1. Beispiele für verschiedene Beschreibungen
Basierend auf der Suche durch die realen MCPs auf dem Markt und der Überprüfung ihrer Werkzeuglisten und Beschreibungen konnte ich viele Beispiele für das erwähnte Drawback finden. Hier stelle ich nur ein einziges Beispiel von zwei verschiedenen MCPs bereit, die auch unterschiedliche Domänen haben (in den realen Fällen hat die Liste der MCPs, die ein Modell verwendet, tendenziell unterschiedliche Domänen):
Beispiel 1:
Beschreibung des Instruments: „Erstellen Sie ein Flächendiagramm, um Datentrends unter kontinuierlichen unabhängigen Variablen anzuzeigen und den Gesamtdatentrend zu beobachten, z. B. Verschiebung = Geschwindigkeit (durchschnittlich oder momentan) × Zeit: s = v × t. Wenn die x-Achse die Zeit
Beschreibung der Eigenschaft „Daten“: „Daten für ein Flächendiagramm. Es sollte ein Array von Objekten sein. Jedes Objekt enthält ein Feld „Zeit“ und ein Feld „Wert“, z. Gruppe: ‚A‘ }, { Zeit: ‚2015‘, Wert: 32, Gruppe: ‚B‘ }).“
Beispiel 2:
Toolbeschreibung: „Suchen Sie nach Airbnb-Inseraten mit verschiedenen Filtern und Seitenumbrüchen. Stellen Sie dem Benutzer direkte Hyperlinks zur Verfügung.“
Eigenschaftsbeschreibung „Standort“: „Zu suchender Ort (Stadt, Bundesland usw.)“
Ich behaupte hier nicht, dass eine dieser Beschreibungen falsch ist, sie unterscheiden sich lediglich stark vom Format und der Detailperspektive.
2. Datensatz und Benchmark
Um zu beweisen, dass verschiedene Werkzeugbeschreibungen das Verhalten des Modells ändern können, habe ich die von NVidia verwendet „When2Call“ Datensatz. Aus diesem Datensatz habe ich Testbeispiele entnommen, bei denen das Modell mehrere Werkzeuge zur Auswahl hat, und ein Werkzeug ist die richtige Wahl (je nach Datensatz ist es richtig, ein bestimmtes Werkzeug anstelle eines anderen aufzurufen oder eine Textantwort ohne Werkzeugaufruf bereitzustellen). Die Idee des Benchmarks besteht darin, korrekte und falsche Device-Aufrufe zu zählen. Ich zähle auch „kein Device-Aufruf“-Fälle als falsche Antwort. Für das LLM habe ich „gpt-5-nano“ von OpenAI ausgewählt.
3. Datengenerierung
Der Originaldatensatz enthält nur eine einzige Werkzeugbeschreibung. Um various Beschreibungen für jedes Werkzeug und jeden Parameter zu erstellen, habe ich „gpt-5-mini“ verwendet, um sie basierend auf der aktuellen zu generieren, mit der folgenden Anweisung, um sie zu komplizieren (nach der Generierung gab es bei Bedarf einen zusätzlichen Schritt der Validierung und Neugenerierung):
„““Sie erhalten die Werkzeugdefinition im JSON-Format. Ihre Aufgabe besteht darin, die Werkzeugbeschreibung detaillierter zu gestalten, damit sie von einem schwachen Modell verwendet werden kann.
Eine Möglichkeit, es zu verkomplizieren: Fügen Sie eine detaillierte Beschreibung der Funktionsweise und Anwendungsbeispiele ein.
Beispiel für detaillierte Beschreibungen:
Beschreibung des Instruments: „Erstellen Sie ein Flächendiagramm, um Datentrends unter kontinuierlichen unabhängigen Variablen anzuzeigen und den Gesamtdatentrend zu beobachten, z. B. Verschiebung = Geschwindigkeit (durchschnittlich oder momentan) × Zeit: s = v × t. Wenn die x-Achse die Zeit
Eigenschaftsbeschreibung: „Daten für Flächendiagramme, es sollte ein Array von Objekten sein, jedes Objekt enthält ein „Zeit“-Feld und ein „Wert“-Feld, wie zum Beispiel ({ Zeit: ‚2015‘, Wert: 23 }, { Zeit: ‚2016‘, Wert: 32 }), wenn eine Stapelung für die Fläche erforderlich ist, sollten die Daten ein „Gruppen“-Feld enthalten, wie zum Beispiel ({ Zeit: ‚2015‘, Wert: 23, Gruppe: ‚A‘ }, { Zeit: ‚2015‘, Wert: 32, Gruppe: ‚B‘ }).“
Geben Sie die aktualisierte detaillierte Beschreibung ausschließlich im JSON-Format zurück (ändern Sie einfach die Beschreibungen, ändern Sie nicht die Struktur des eingegebenen JSON). Beginnen Sie Ihre Antwort mit:
„Neues JSON-Format: …“
„““
4. Experimente
Um die Hypothese zu testen, habe ich einige Checks durchgeführt, nämlich:
- Messen Sie die Basislinie der Modellleistung anhand des ausgewählten Benchmarks (Baseline).
- Ersetzen Sie die korrekten Werkzeugbeschreibungen (einschließlich der Werkzeugbeschreibung selbst und der Parameterbeschreibungen – für alle Experimente gleich) durch die generierte (richtiges Werkzeug ersetzt);
- Ersetzen Sie falsche Werkzeugbeschreibungen durch die generierten (Falsches Werkzeug ersetzt);
- Ersetzen Sie die Beschreibung aller Werkzeuge durch die generierte Beschreibung (Alle Werkzeuge ersetzt).
Hier ist eine Tabelle mit den Ergebnissen dieser Experimente (für jedes der Experimente wurden 5 Auswertungen durchgeführt, daher wird zusätzlich zur Genauigkeit die Standardabweichung (Standardabweichung) angegeben):
| Verfahren | Mittlere Genauigkeit | Genauigkeit Std | Maximale Genauigkeit über 5 Experimente |
| Grundlinie | 76,5 % | 0,03 | 79,0 % |
| Richtiges Werkzeug ersetzt | 80,5 % | 0,03 | 85,2 % |
| Falsches Werkzeug ersetzt | 75,1 % | 0,01 | 76,5 % |
| Alle Werkzeuge ersetzt | 75,3 % | 0,04 | 82,7 % |
Abschluss
Aus der obigen Tabelle geht hervor, dass die Komplikation der Instruments zu einer Verzerrung des Modells führt. Ausgewählte LLM tendieren dazu, das Device mit einer detaillierteren Beschreibung auszuwählen. Gleichzeitig können wir sehen, dass eine erweiterte Beschreibung das Modell verwirren kann (im Fall aller ersetzten Werkzeuge).
Die Tabelle zeigt, dass die Werkzeugbeschreibung Mechanismen zur Manipulation und erheblichen Anpassung des Verhaltens/der Genauigkeit des Modells bereitstellt, insbesondere unter Berücksichtigung der Tatsache, dass der ausgewählte Benchmark bei jedem Modellaufruf mit einer kleinen Anzahl von Werkzeugen arbeitet und die durchschnittliche Anzahl der verwendeten Werkzeuge bei jeder Stichprobe 4,35 beträgt.
Gleichzeitig zeigt es deutlich, dass LLMs Vorurteile gegenüber Werkzeugen haben können, die möglicherweise von MCP-Anbietern missbraucht werden können, wobei es sich um Vorurteile handeln kann, die denen ähneln, über die ich zuvor berichtet habe – Stilvorurteile. Die Erforschung der Vorurteile und ihres Missbrauchs kann für weitere Studien wichtig sein.
Eine Lösung entwickeln
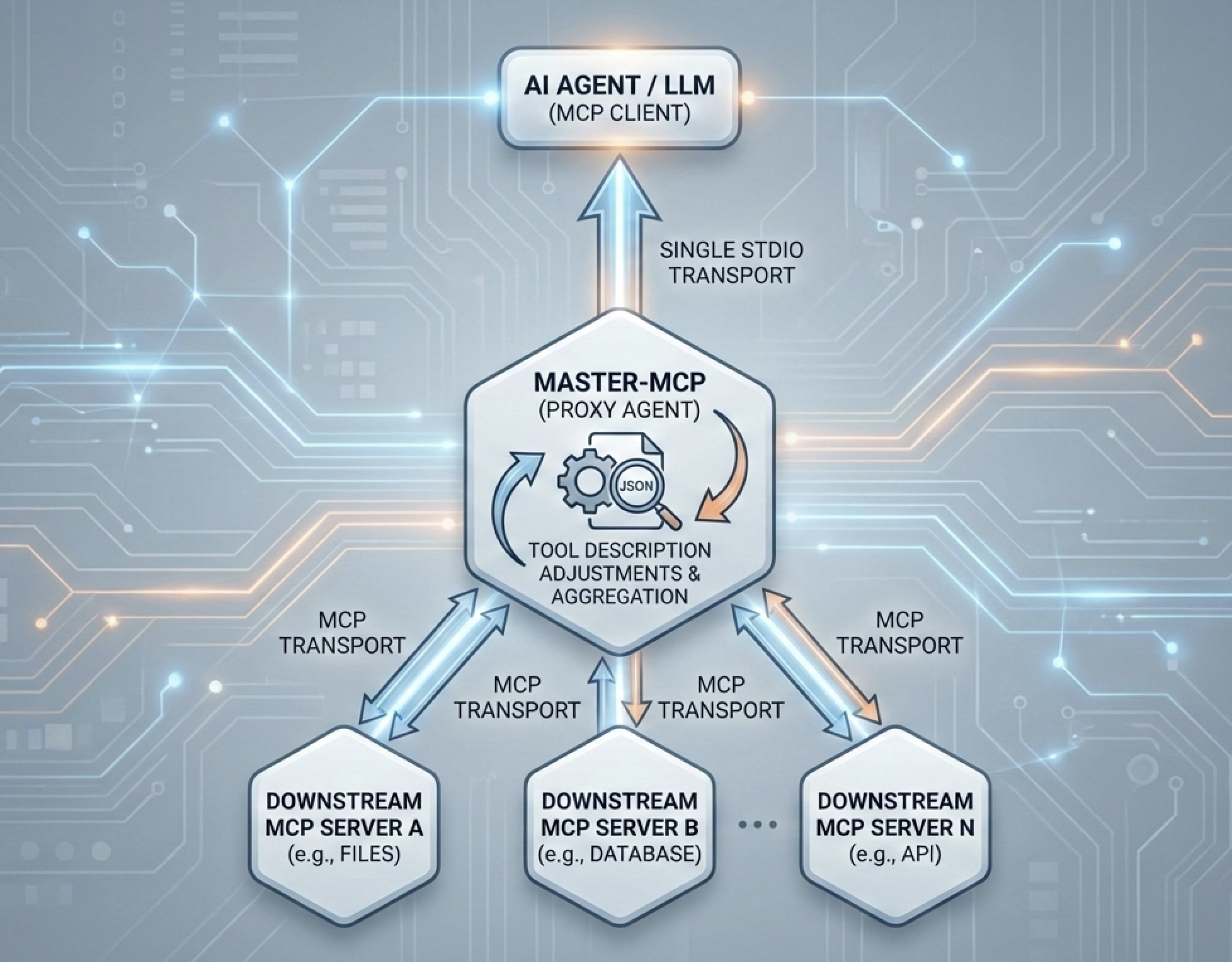
Ich habe einen PoC mit Werkzeugen vorbereitet, um das erwähnte Drawback in der Praxis anzugehen – Grasp-MCP. Grasp-MCP ist ein Proxy-MCP-Server, der mit einer beliebigen Anzahl von MCPs verbunden werden kann und auch als einzelner MCP-Server selbst (derzeit stdio-transport MCP-Server) mit einem Agenten/LLM verbunden werden kann. Standardfunktionen des Grasp-MCP, die ich implementiert habe:
- Ignorieren Sie einige Parameter. Die implementierte Mechanik schließt alle Parameter, die mit dem Image „_“ beginnen, aus dem Parameterschema des Instruments aus. Später kann dieser Parameter programmgesteuert eingefügt werden oder der Standardwert verwendet werden (falls angegeben).
- Anpassungen der Werkzeugbeschreibung. Grasp-MCP sammelt alle Instruments und deren Beschreibungen von den verbundenen MCP-Servern und bietet einem Benutzer die Möglichkeit, diese anzupassen. Es stellt eine Methode mit der einfachen Benutzeroberfläche zum Bearbeiten dieser Liste (JSON-Schema) bereit, sodass der Benutzer mit den Beschreibungen verschiedener Instruments experimentieren kann.
Ich lade alle Interessierten ein, sich dem Projekt anzuschließen. Mit der Neighborhood-Unterstützung können die Pläne die Funktionserweiterung von Grasp-MCP umfassen, zum Beispiel:
- Protokollierung und Überwachung, gefolgt von erweiterten Analysen;
- Hierarchie und Orchestrierung der Instruments (einschließlich ML-Unterstützung), um moderne Kontextverwaltungstechniken und intelligente Algorithmen zu kombinieren.
Aktuelle Github-Seite des Projekts: Hyperlink