

Bild vom Autor
# Einführung
Täglich zeichnen Kundendienstzentren Tausende von Gesprächen auf. In diesen Audiodateien verbergen sich Goldminen an Informationen. Sind die Kunden zufrieden? Welche Probleme werden am häufigsten erwähnt? Wie verändern sich Emotionen während eines Anrufs?
Die manuelle Analyse dieser Aufzeichnungen ist eine Herausforderung. Mit moderner künstlicher Intelligenz (KI) können wir jedoch Anrufe automatisch transkribieren, Emotionen erkennen und wiederkehrende Themen extrahieren – alles offline und mit Open-Supply-Instruments.
In diesem Artikel werde ich Sie durch ein komplettes Projekt zur Analyse der Kundenstimmung führen. Sie erfahren, wie Sie:
- Audiodateien in Textual content umwandeln mit Flüstern
- Erkennen von Gefühlen (positiv, negativ, impartial) und Emotionen (Frustration, Zufriedenheit, Dringlichkeit)
- Themen automatisch extrahieren mit BERThema
- Ergebnisse in einem interaktiven Dashboard anzeigen
Das Beste daran ist, dass alles lokal läuft. Ihre sensiblen Kundendaten verlassen niemals Ihr Gerät.
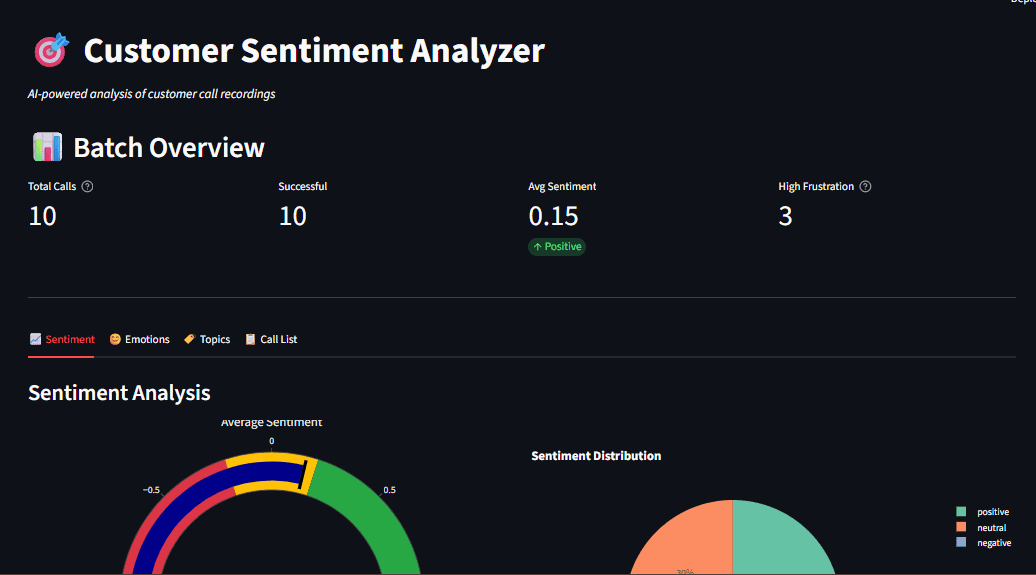
Abb. 1: Dashboard-Übersicht mit Stimmungsanzeige, Emotionsradar und Themenverteilung
# Verstehen, warum lokale KI für Kundendaten wichtig ist
Cloudbasierte KI-Dienste wie OpenAIs API sind leistungsstark, bringen jedoch Bedenken mit sich, beispielsweise hinsichtlich des Datenschutzes, da Kundenanrufe oft persönliche Informationen enthalten; hohe Kosten, bei denen Sie einen Preis professional API-Aufruf zahlen, der sich bei großen Volumina schnell summiert; und Abhängigkeit von Web-Gebührenbeschränkungen. Durch die lokale Ausführung ist es einfacher, die Anforderungen an die Datenresidenz zu erfüllen.
Dieses lokale KI-Sprach-zu-Textual content-Tutorial behält alles auf Ihrer {Hardware}. Modelle werden einmal heruntergeladen und laufen dauerhaft offline.
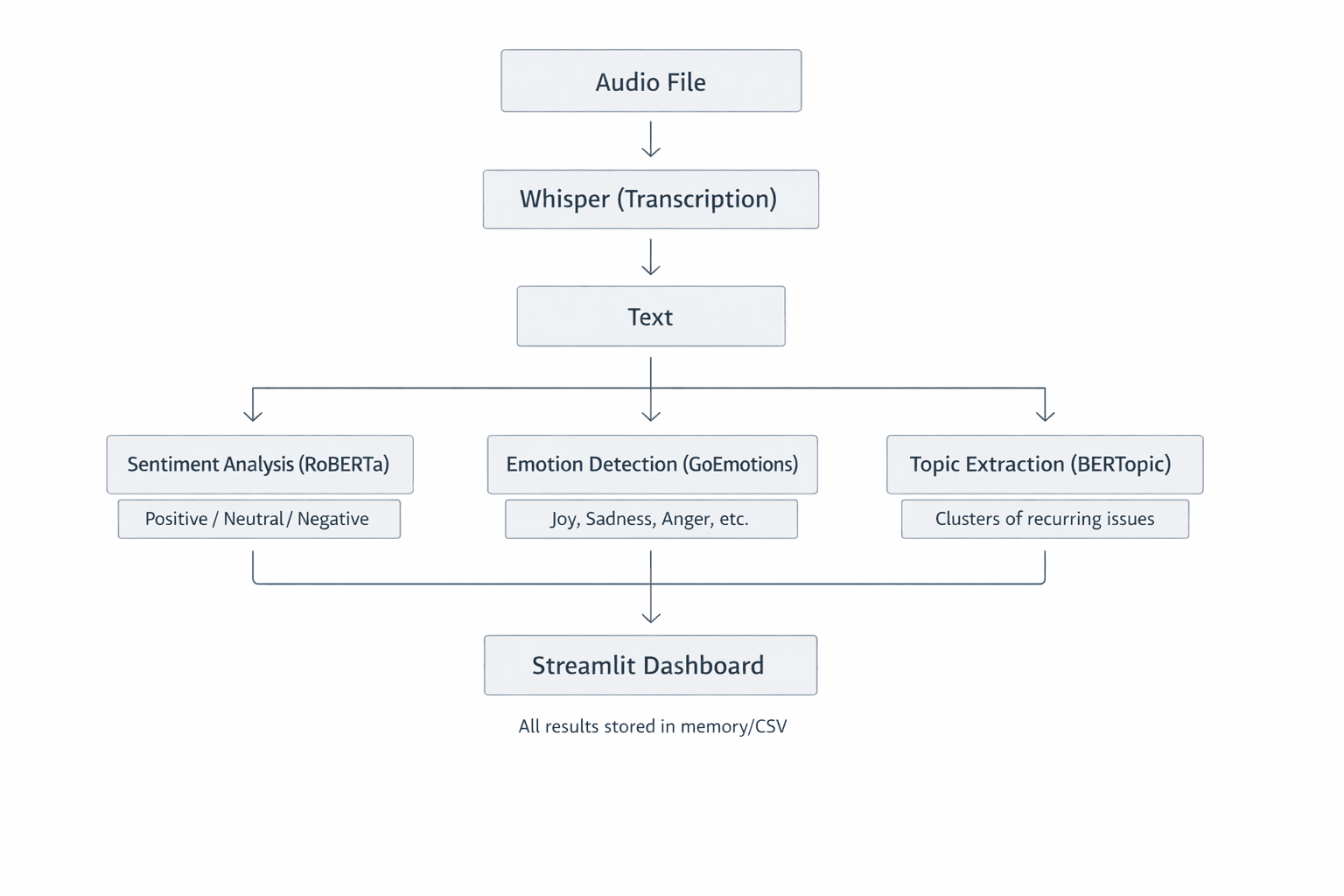
Abb. 2: Übersicht über die Systemarchitektur, die zeigt, wie jede Komponente eine Aufgabe intestine bewältigt. Durch diesen modularen Aufbau ist das System leicht zu verstehen, zu testen und zu erweitern
// Voraussetzungen
Bevor Sie beginnen, stellen Sie sicher, dass Sie über Folgendes verfügen:
- Python 3.9+ ist auf Ihrem Pc installiert.
- Das hättest du tun sollen FFmpeg für die Audioverarbeitung installiert.
- Sie sollten über grundlegende Kenntnisse mit Python und den Konzepten des maschinellen Lernens verfügen.
- Für KI-Modelle benötigen Sie etwa 2 GB Speicherplatz.
// Einrichten Ihres Projekts
Klonen Sie das Repository und richten Sie Ihre Umgebung ein:
git clone https://github.com/zenUnicorn/Buyer-Sentiment-analyzer.gitErstellen Sie eine virtuelle Umgebung:
Aktivieren (Home windows):
Aktivieren (Mac/Linux):
Abhängigkeiten installieren:
pip set up -r necessities.txtBeim ersten Durchlauf werden KI-Modelle heruntergeladen (~1,5 GB insgesamt). Danach funktioniert alles offline.
Abb. 3: Terminal zeigt erfolgreiche Set up
# Audio mit Whisper transkribieren
Im Kundenstimmungsanalysator besteht der erste Schritt darin, gesprochene Wörter aus Anrufaufzeichnungen in Textual content umzuwandeln. Dies geschieht mit Whisper, einem von entwickelten automatischen Spracherkennungssystem (ASR). OpenAI. Schauen wir uns an, wie es funktioniert, warum es eine gute Wahl ist und wie wir es im Projekt verwenden.
Whisper ist ein Transformer-basiertes Encoder-Decoder-Modell, das auf 680.000 Stunden mehrsprachigem Audio trainiert wurde. Wenn Sie ihm eine Audiodatei zuführen, geschieht Folgendes:
- Neuabtastung des Audiosignals auf 16-kHz-Mono
- Erzeugt ein Mel-Spektrogramm – eine visuelle Darstellung der Frequenzen im Zeitverlauf – das als Foto des Klangs dient
- Teilt das Spektrogramm in 30-Sekunden-Fenster auf
- Leitet jedes Fenster durch einen Encoder, der versteckte Darstellungen erstellt
- Übersetzt diese Darstellungen Wort für Wort (oder Unterwort) in Textual content-Tokens
Stellen Sie sich das Mel-Spektrogramm als die Artwork und Weise vor, wie Maschinen Geräusche „sehen“. Die x-Achse stellt die Zeit dar, die y-Achse stellt die Frequenz dar und die Farbintensität zeigt die Lautstärke. Das Ergebnis ist ein hochpräzises Transkript, auch bei Hintergrundgeräuschen oder Akzenten.
Code-Implementierung
Hier ist die Kernlogik der Transkription:
import whisper
class AudioTranscriber:
def __init__(self, model_size="base"):
self.mannequin = whisper.load_model(model_size)
def transcribe_audio(self, audio_path):
outcome = self.mannequin.transcribe(
str(audio_path),
word_timestamps=True,
condition_on_previous_text=True
)
return {
"textual content": outcome("textual content"),
"segments": outcome("segments"),
"language": outcome("language")
}Der model_size Der Parameter steuert die Genauigkeit im Verhältnis zur Geschwindigkeit.
| Modell | Parameter | Geschwindigkeit | Am besten für |
|---|---|---|---|
| winzig | 39M | Am schnellsten | Schneller Check |
| Base | 74M | Schnell | Entwicklung |
| klein | 244M | Medium | Produktion |
| groß | 1550M | Langsam | Maximale Genauigkeit |
Für die meisten Anwendungsfälle gilt: base oder small bietet die beste Steadiness.
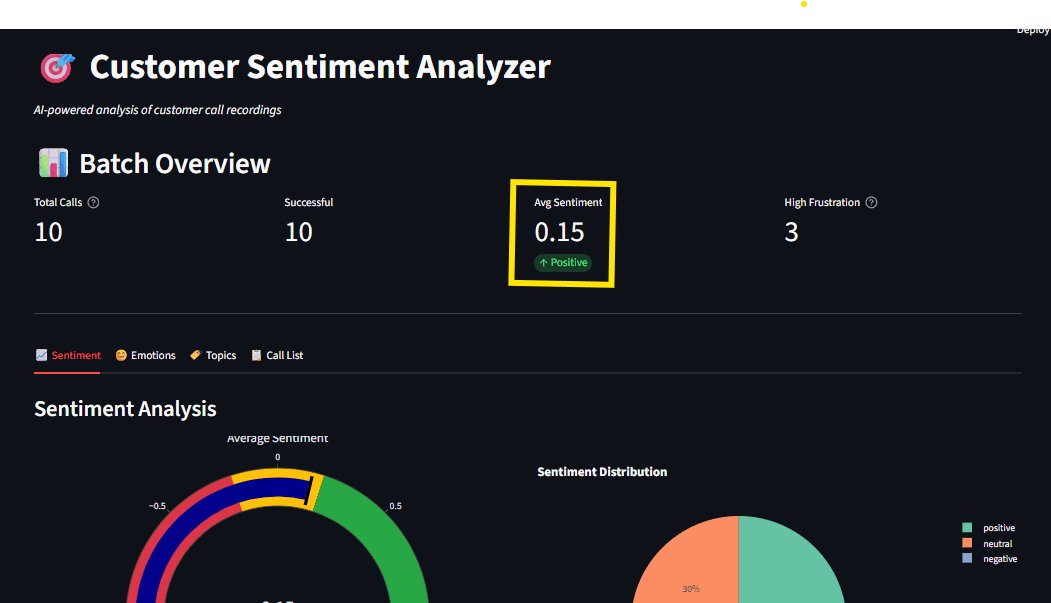
Abb. 4: Transkriptionsausgabe mit zeitgestempelten Segmenten
# Stimmungsanalyse mit Transformern
Mit extrahiertem Textual content analysieren wir die Stimmung mithilfe von Umarmende Gesichtstransformatoren. Wir verwenden CardiffNLPs RoBERTa Modell, trainiert auf Social-Media-Textual content, das sich perfekt für gesprächige Kundenanrufe eignet.
// Vergleich von Gefühl und Emotion
Die Stimmungsanalyse klassifiziert Texte als positiv, impartial oder negativ. Wir verwenden ein fein abgestimmtes RoBERTa-Modell, weil es den Kontext besser versteht als ein einfaches Key phrase-Matching.
Das Transkript wird tokenisiert und durch einen Transformer geleitet. Die letzte Ebene verwendet eine Softmax-Aktivierung, die Wahrscheinlichkeiten ausgibt, die sich auf 1 summieren. Wenn beispielsweise positiv 0,85, impartial 0,10 und negativ 0,05 ist, ist die Gesamtstimmung positiv.
- Gefühl: Gesamtpolarität (positiv, negativ oder impartial) zur Beantwortung der Frage: „Ist das intestine oder schlecht?“
- Emotion: Spezifische Gefühle (Wut, Freude, Angst) als Antwort auf die Frage: „Was genau fühlen sie?“
Wir erkennen beides für einen vollständigen Einblick.
// Code-Implementierung für die Stimmungsanalyse
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch.nn.purposeful as F
class SentimentAnalyzer:
def __init__(self):
model_name = "cardiffnlp/twitter-roberta-base-sentiment-latest"
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.mannequin = AutoModelForSequenceClassification.from_pretrained(model_name)
def analyze(self, textual content):
inputs = self.tokenizer(textual content, return_tensors="pt", truncation=True)
outputs = self.mannequin(**inputs)
possibilities = F.softmax(outputs.logits, dim=1)
labels = ("adverse", "impartial", "constructive")
scores = {label: float(prob) for label, prob in zip(labels, possibilities(0))}
return {
"label": max(scores, key=scores.get),
"scores": scores,
"compound": scores("constructive") - scores("adverse")
}Der compound Die Bewertung reicht von -1 (sehr negativ) bis +1 (sehr positiv), sodass sich Stimmungstrends im Zeitverlauf leicht verfolgen lassen.
// Warum einfache Lexikonmethoden vermeiden?
Traditionelle Ansätze wie VADER Zähle constructive und adverse Wörter. Allerdings fehlt ihnen oft der Kontext:
- „Das ist nicht intestine.“ Lexicon sieht „intestine“ als positiv an.
- Ein Transformator versteht Negation („nicht“) als negativ.
Transformatoren verstehen Beziehungen zwischen Wörtern und machen sie so für reale Texte weitaus genauer.
# Extrahieren von Themen mit BERTopic
Es ist nützlich, die Stimmung zu kennen, aber worüber reden Kunden? BERThema erkennt automatisch Themen im Textual content, ohne dass Sie sie vorab definieren müssen.
// So funktioniert BERTopic
- Einbettungen: Konvertieren Sie jedes Transkript mithilfe von in einen Vektor Satztransformatoren
- Dimensionsreduzierung: UMAP komprimiert diese Vektoren in einen niedrigdimensionalen Raum
- Clustering: HDBSCAN gruppiert ähnliche Transkripte
- Themenvertretung: Extrahieren Sie für jeden Cluster die relevantesten Wörter mit c-TF-IDF
Das Ergebnis ist eine Reihe von Themen wie „Abrechnungsprobleme“, „technischer Assist“ oder „Produktfeedback“. Im Gegensatz zu älteren Methoden wie Latente Dirichlet-Zuordnung (LDA)BERTopic versteht semantische Bedeutung. „Versandverzögerung“ und „verspätete Lieferung“ kommen zusammen, weil sie dieselbe Bedeutung haben.
Code-Implementierung
Aus matters.py:
from bertopic import BERTopic
class TopicExtractor:
def __init__(self):
self.mannequin = BERTopic(
embedding_model="all-MiniLM-L6-v2",
min_topic_size=2,
verbose=True
)
def extract_topics(self, paperwork):
matters, possibilities = self.mannequin.fit_transform(paperwork)
topic_info = self.mannequin.get_topic_info()
topic_keywords = {
topic_id: self.mannequin.get_topic(topic_id)(:5)
for topic_id in set(matters) if topic_id != -1
}
return {
"assignments": matters,
"key phrases": topic_keywords,
"distribution": topic_info
}Notiz: Für die Themenextraktion sind mehrere Dokumente (mindestens 5–10) erforderlich, um sinnvolle Muster zu finden. Einzelne Anrufe werden mithilfe des angepassten Modells analysiert.
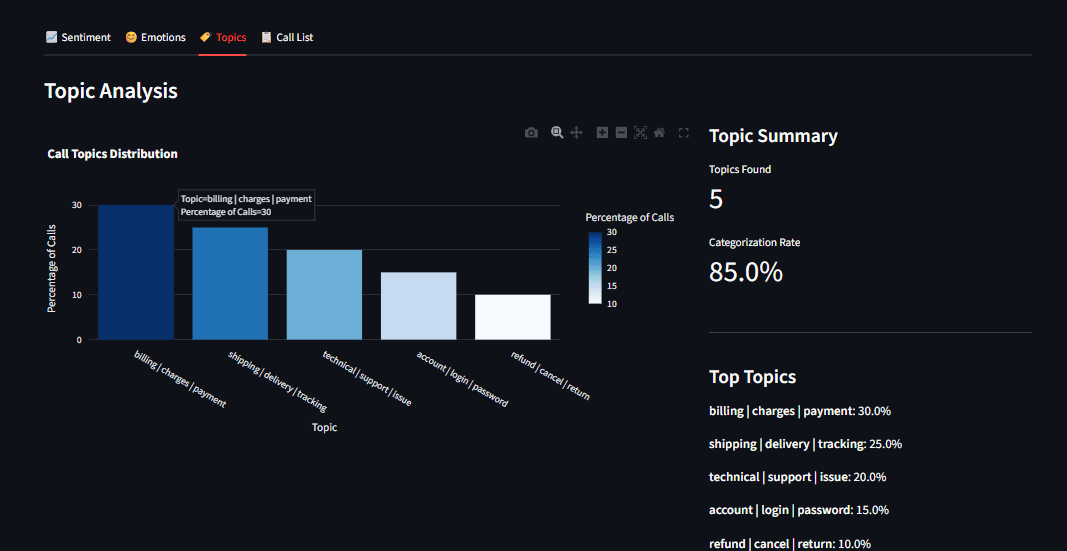
Abb. 5: Balkendiagramm zur Themenverteilung mit den Kategorien Abrechnung, Versand und technischer Assist
# Erstellen eines interaktiven Dashboards mit Streamlit
Rohdaten sind schwer zu verarbeiten. Wir haben eine gebaut Streamlit Armaturenbrett (app.py), mit dem Geschäftsanwender Ergebnisse erkunden können. Streamlit verwandelt Python-Skripte mit minimalem Code in Webanwendungen. Unser Dashboard bietet:
- Add-Schnittstelle für Audiodateien
- Echtzeitverarbeitung mit Fortschrittsanzeigen
- Interaktive Visualisierungen mit Plotly
- Drilldown-Funktion zur Untersuchung einzelner Anrufe
// Code-Implementierung für die Dashboard-Struktur
import streamlit as st
def principal():
st.title("Buyer Sentiment Analyzer")
uploaded_files = st.file_uploader(
"Add Audio Information",
sort=("mp3", "wav"),
accept_multiple_files=True
)
if uploaded_files and st.button("Analyze"):
with st.spinner("Processing..."):
outcomes = pipeline.process_batch(uploaded_files)
# Show outcomes
col1, col2 = st.columns(2)
with col1:
st.plotly_chart(create_sentiment_gauge(outcomes))
with col2:
st.plotly_chart(create_emotion_radar(outcomes))Streamlits Caching @st.cache_resource stellt sicher, dass Modelle einmal geladen werden und über Interaktionen hinweg bestehen bleiben, was für eine reaktionsfähige Benutzererfahrung von entscheidender Bedeutung ist.
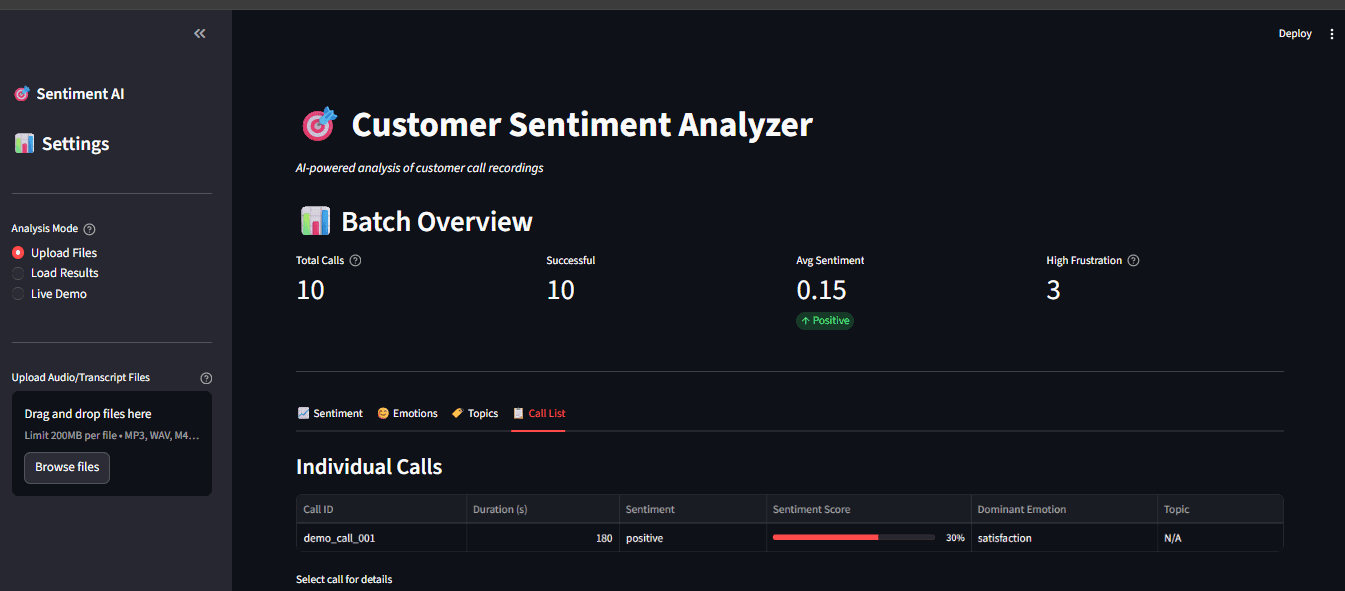
Abb. 7: Vollständiges Dashboard mit Seitenleistenoptionen und mehreren Visualisierungsregisterkarten
// Hauptmerkmale
- Audio hochladen (oder Beispieltranskripte zum Testen verwenden)
- Transkript mit Stimmungshervorhebungen anzeigen
- Zeitleiste der Emotionen (wenn der Anruf lang genug ist)
- Themenvisualisierung mit interaktiven Plotly-Diagrammen
// Caching für Leistung
Streamlit führt das Skript bei jeder Interaktion erneut aus. Um die Wiederaufbereitung schwerer Modelle zu vermeiden, verwenden wir @st.cache_resource:
@st.cache_resource
def load_models():
return CallProcessor()
processor = load_models()// Echtzeitverarbeitung
Wenn ein Benutzer eine Datei hochlädt, zeigen wir während der Verarbeitung einen Spinner an und zeigen dann sofort die Ergebnisse an:
if uploaded_file:
with st.spinner("Transcribing and analyzing..."):
outcome = processor.process_file(uploaded_file)
st.success("Performed!")
st.write(outcome("textual content"))
st.metric("Sentiment", outcome("sentiment")("label"))# Wiederholung praktischer Lektionen
Audioverarbeitung: Von der Wellenform zum Textual content
Die Magie von Whisper liegt in der Umwandlung des Mel-Spektrogramms. Das menschliche Gehör ist logarithmisch, das heißt, wir können tiefe Frequenzen besser erkennen als hohe. Die Mel-Skala ahmt dies nach, sodass das Modell eher wie ein Mensch „hört“. Das Spektrogramm ist im Wesentlichen ein 2D-Bild (Zeit vs. Frequenz), das der Transformer-Encoder ähnlich wie einen Bildausschnitt verarbeitet. Aus diesem Grund kommt Whisper intestine mit lauten Audiosignalen zurecht; es sieht das ganze Bild.
// Transformatorausgänge: Softmax vs. Sigmoid
- Softmax (Stimmung): Erzwingt die Summe der Wahrscheinlichkeiten zu 1. Dies ist preferrred für sich gegenseitig ausschließende Klassen, da ein Satz normalerweise nicht sowohl positiv als auch negativ ist.
- Sigmoid (Emotionen): Behandelt jede Klasse unabhängig. Ein Satz kann gleichzeitig freudig und überraschend sein. Sigmoid ermöglicht diese Überlappung.
Die Auswahl der richtigen Aktivierung ist für Ihre Problemdomäne von entscheidender Bedeutung.
// Erkenntnisse mit Visualisierung vermitteln
Ein gutes Dashboard kann mehr als nur Zahlen anzeigen; es erzählt eine Geschichte. Plotly-Diagramme sind interaktiv; Benutzer können mit der Maus darüber fahren, um Particulars anzuzeigen, in Zeitbereiche hineinzoomen und auf Legenden klicken, um zwischen Datenreihen umzuschalten. Dadurch werden Rohanalysen in umsetzbare Erkenntnisse umgewandelt.
// Ausführen der Anwendung
Um die Anwendung auszuführen, befolgen Sie die Schritte vom Anfang dieses Artikels. Testen Sie die Sentiment- und Emotionsanalyse ohne Audiodateien:
Dadurch wird Beispieltext durch die NLP-Modelle (Pure Language Processing) geführt und die Ergebnisse im Terminal angezeigt.
Analysieren Sie eine einzelne Aufnahme:
python principal.py --audio path/to/name.mp3Stapelverarbeitung eines Verzeichnisses:
python principal.py --batch information/audio/Für das vollständige interaktive Erlebnis:
python principal.py --dashboardOffen http://localhost:8501 in Ihrem Browser.
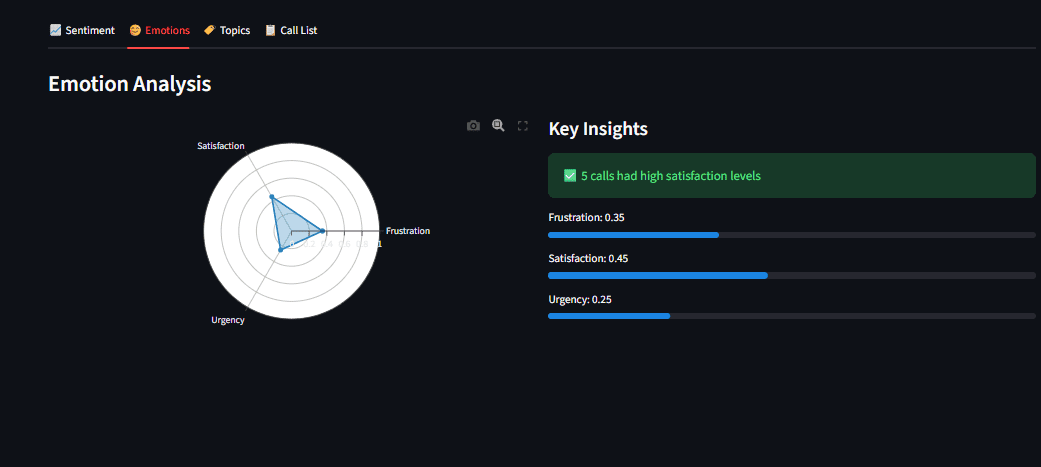
Abb. 8: Terminalausgabe, die eine erfolgreiche Analyse mit Sentiment-Scores zeigt
# Abschluss
Wir haben ein vollständiges, offlinefähiges System aufgebaut, das Kundenanrufe transkribiert, Stimmungen und Emotionen analysiert und wiederkehrende Themen extrahiert – alles mit Open-Supply-Instruments. Dies ist eine produktionsreife Grundlage für:
- Kundensupportteams identifizieren Schwachstellen
- Produktmanager sammeln Suggestions in großem Umfang
- Qualitätssicherung, Überwachung der Agentenleistung
Das Beste daran? Alles läuft lokal, respektiert die Privatsphäre der Benutzer und eliminiert API-Kosten.
Der vollständige Code ist auf GitHub verfügbar: Eine KI, die die Kundenstimmung analysiert. Klonen Sie das Repository, folgen Sie diesem lokalen KI-Sprach-zu-Textual content-Tutorial und beginnen Sie noch heute damit, Erkenntnisse aus Ihren Kundenanrufen zu gewinnen.
Shittu Olumid ist ein Software program-Ingenieur und technischer Autor, der sich leidenschaftlich dafür einsetzt, modernste Technologien zu nutzen, um fesselnde Erzählungen zu erschaffen, mit einem scharfen Blick fürs Element und einem Gespür für die Vereinfachung komplexer Konzepte. Sie können Shittu auch auf finden Twitter.